") 不懂AI數(shù)據(jù)挖掘?清華人工智能中心權(quán)威報(bào)告帶你深入解讀!
不懂AI數(shù)據(jù)挖掘?清華人工智能中心權(quán)威報(bào)告帶你深入解讀!
在數(shù)據(jù)爆炸的時(shí)代里,如何利用手中數(shù)據(jù)資源提高行業(yè)效率、提高行業(yè)質(zhì)量,成為了眾多企業(yè)決策者所關(guān)注的問(wèn)題,數(shù)據(jù)挖掘也逐漸成為當(dāng)下的熱門(mén)研究領(lǐng)域之一,受到了谷歌、亞馬遜、阿里、百度等科技巨頭的追捧。
本文為大家推薦來(lái)自清華大學(xué)人工智能研究院、北京智源人工智能研究院、清華-工程院知識(shí)智能聯(lián)合研究中心聯(lián)合推出的人工智能數(shù)據(jù)挖掘報(bào)告,詳細(xì)解讀了數(shù)據(jù)挖掘技術(shù)應(yīng)用領(lǐng)域、研究概念、算法實(shí)現(xiàn)、與發(fā)展趨勢(shì)。數(shù)據(jù)挖掘與KDD
數(shù)據(jù)挖掘(Data Mining),是指從大量的數(shù)據(jù)中自動(dòng)搜索隱藏于其中的有著特殊關(guān)系性的數(shù)據(jù)和信息,并將其轉(zhuǎn)化為計(jì)算機(jī)可處理的結(jié)構(gòu)化表示。
目前數(shù)據(jù)挖掘的主要功能包括概念描述、關(guān)聯(lián)分析、分類(lèi)、聚類(lèi)和偏差檢測(cè)等,用于描述對(duì)象內(nèi)涵、概括對(duì)象特征、發(fā)現(xiàn)數(shù)據(jù)規(guī)律、檢測(cè)異常數(shù)據(jù)等。
一般來(lái)說(shuō),數(shù)據(jù)挖掘過(guò)程有五個(gè)步驟:確定挖掘目的、數(shù)據(jù)準(zhǔn)備、進(jìn)行數(shù)據(jù)挖掘、結(jié)果分析、知識(shí)的同化。
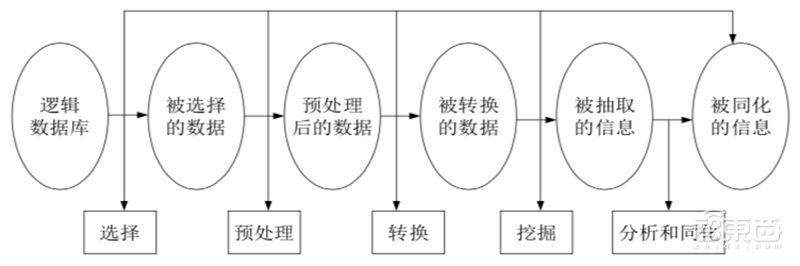
▲數(shù)據(jù)挖掘過(guò)程基本步驟
(一)確定挖掘目的
認(rèn)清數(shù)據(jù)挖掘的目的是數(shù)據(jù)挖掘的重要一步。挖掘的最后結(jié)果是不可預(yù)測(cè)的,但要探索的問(wèn)題應(yīng)是有預(yù)見(jiàn)的。
(二)數(shù)據(jù)準(zhǔn)備
數(shù)據(jù)準(zhǔn)備又分為三個(gè)階段:
1、數(shù)據(jù)的選擇:搜索所有與目標(biāo)對(duì)象有關(guān)的內(nèi)部和外部數(shù)據(jù)信息,并從中選擇出適用于數(shù)據(jù)挖掘應(yīng)用的數(shù)據(jù);
2、數(shù)據(jù)的預(yù)處理:研究數(shù)據(jù)的質(zhì)量,為進(jìn)一步的分析做準(zhǔn)備,并確定將要進(jìn)行的挖掘操作的類(lèi)型;
3、數(shù)據(jù)的轉(zhuǎn)換:將數(shù)據(jù)轉(zhuǎn)換成一個(gè)分析模型。這個(gè)分析模型是針對(duì)挖掘算法建立的。建立一個(gè)真正適合挖掘算法的分析模型是數(shù)據(jù)挖掘成功的關(guān)鍵。
(三)進(jìn)行數(shù)據(jù)挖掘
對(duì)得到的經(jīng)過(guò)轉(zhuǎn)換的數(shù)據(jù)進(jìn)行挖掘。
(四)結(jié)果分析
解釋并評(píng)估結(jié)果,其使用的分析方法一般應(yīng)視數(shù)據(jù)挖掘操作而定,通常會(huì)用到可視化技術(shù)。
(五)知識(shí)的同化
將分析所得到的知識(shí)集成到所要應(yīng)用的地方去。

▲數(shù)據(jù)挖掘的分類(lèi)表
如上圖所示,數(shù)據(jù)挖掘有多種分類(lèi)方式,可以按照挖掘的數(shù)據(jù)庫(kù)類(lèi)型、挖掘的知識(shí)類(lèi)型、挖掘所用的技術(shù)類(lèi)型進(jìn)行分類(lèi)。
同時(shí),數(shù)據(jù)挖掘也可以按照行業(yè)應(yīng)用來(lái)進(jìn)行分類(lèi),比如生物醫(yī)學(xué)、交通、金融等行業(yè)都有其獨(dú)特的數(shù)據(jù)挖掘方法,不能做到用同一個(gè)數(shù)據(jù)挖掘技術(shù)應(yīng)用到各個(gè)行業(yè)領(lǐng)域。
數(shù)據(jù)挖掘是知識(shí)發(fā)現(xiàn)(KDD)的一個(gè)關(guān)鍵步驟。1989年8月,Gregory I. Piatetsky- Shapiro等人在美國(guó)底特律的國(guó)際人工智能聯(lián)合會(huì)議(IJCAI)上召開(kāi)了一個(gè)專(zhuān)題討論會(huì)(workshop),首次提出了知識(shí)發(fā)現(xiàn)(Knowledge Discovery in Database,KDD)這一概念。
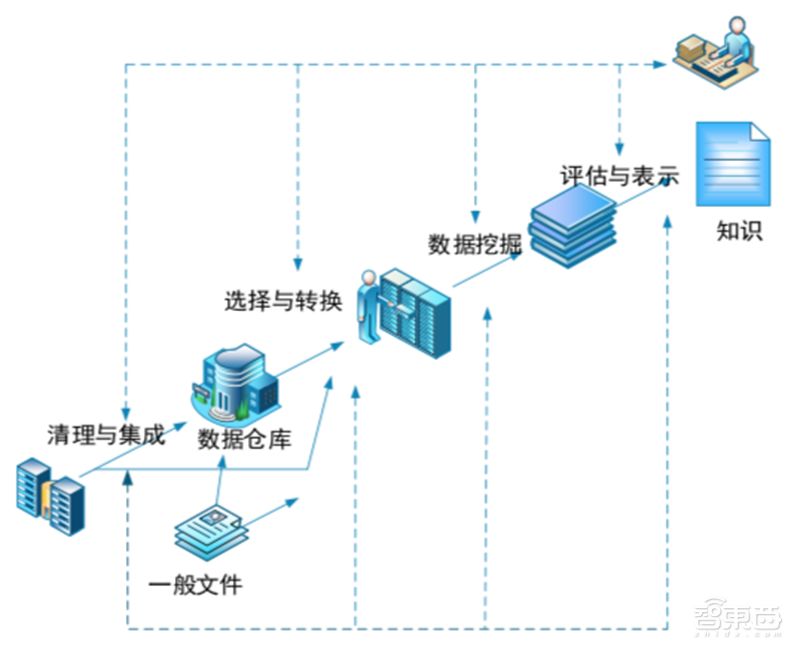
▲數(shù)據(jù)挖掘是知識(shí)發(fā)現(xiàn)的過(guò)程之一
KDD涉及數(shù)據(jù)庫(kù)、機(jī)器學(xué)習(xí)、統(tǒng)計(jì)學(xué)、模式識(shí)別、數(shù)據(jù)可視化、高性能計(jì)算、知識(shí)獲取、神經(jīng)網(wǎng)絡(luò)、信息檢索等眾多學(xué)科和技術(shù)的集成,再后來(lái)的30年間KDD逐漸形成了一個(gè)獨(dú)立、蓬勃發(fā)展的交叉研究領(lǐng)域。
早期比較有影響力的發(fā)現(xiàn)算法有:IBM的Rakesh Agrawal的關(guān)聯(lián)算法、UIUC大學(xué)韓家煒(Jiawei Han)教授等人的FP Tree算法、澳大利亞的John Ross Quinlan教授的分類(lèi)算法、密西根州立大學(xué)Erick Goodman的遺傳算法等等。
目前,數(shù)據(jù)挖掘已經(jīng)引起國(guó)際、國(guó)內(nèi)工業(yè)界的廣泛關(guān)注,IBM、谷歌、亞馬遜、微軟、Facebook、阿里巴巴、騰訊、百度等都在數(shù)據(jù)挖掘研究方面進(jìn)行了應(yīng)用與理論研究。

國(guó)際知識(shí)發(fā)現(xiàn)與數(shù)據(jù)挖掘大會(huì)(ACM SIGKDD Conference on Knowledge Discovery and Data Mining,簡(jiǎn)稱(chēng)SIGKDD)是數(shù)據(jù)挖掘領(lǐng)域的頂級(jí)國(guó)際會(huì)議,由ACM的數(shù)據(jù)挖掘及知識(shí)發(fā)現(xiàn)專(zhuān)委會(huì)負(fù)責(zé)協(xié)調(diào)籌辦,會(huì)議內(nèi)容涵蓋數(shù)據(jù)挖掘的基礎(chǔ)理論、算法和實(shí)際應(yīng)用。
數(shù)據(jù)挖掘源于商業(yè)的直接需求
數(shù)據(jù)挖掘技術(shù)從一開(kāi)始就是面向應(yīng)用的,源于商業(yè)的直接需求。目前數(shù)據(jù)挖掘在零售、旅游、物流、醫(yī)學(xué)等領(lǐng)域都有所應(yīng)用,可以大大提高行業(yè)效率和行業(yè)質(zhì)量。
舉個(gè)例子,零售是數(shù)據(jù)挖掘的主要應(yīng)用領(lǐng)域之一。這是因?yàn)橛捎跅l形碼技術(shù)的發(fā)展使得前端收款機(jī)系統(tǒng)可以收集大量售貨、顧客購(gòu)買(mǎi)歷史記錄、貨物進(jìn)出狀況、消費(fèi)與服務(wù)記錄等數(shù)據(jù)。
數(shù)據(jù)挖掘技術(shù)有助于識(shí)別顧客購(gòu)買(mǎi)行為,發(fā)現(xiàn)顧客購(gòu)買(mǎi)模式和趨勢(shì),改進(jìn)服務(wù)質(zhì)量,取得更高的顧客保持力和滿意程度,減少零售業(yè)成本。
同時(shí),同一顧客在不同時(shí)期購(gòu)買(mǎi)的商品數(shù)據(jù)可以分組為序列,序列模式挖掘可用于分析顧客的消費(fèi)或忠誠(chéng)度的變化,據(jù)此對(duì)價(jià)格和商品的花樣加以調(diào)整和更新,以便留住老客戶,吸引新客戶。
與此同時(shí),社交網(wǎng)絡(luò)也是數(shù)據(jù)挖掘研究中的熱門(mén)領(lǐng)域,比如新浪微博就是擁有海量數(shù)據(jù)的資訊平臺(tái)。
截止到2017年12月,新郎微博已擁有接近4億活躍用戶,內(nèi)容存量超千億,“大V”的一舉一動(dòng)和社會(huì)熱點(diǎn)話題都會(huì)引起大量的評(píng)論與轉(zhuǎn)發(fā),掀起一股“數(shù)據(jù)風(fēng)暴”。

▲柯潔烏鎮(zhèn)大戰(zhàn)AlphaGo撼負(fù)后的微博熱議
微博上每個(gè)用戶的言論、轉(zhuǎn)發(fā)內(nèi)容等都蘊(yùn)藏著用戶個(gè)人的興趣、話題等信息,文字內(nèi)容本身的智能分析理解也是數(shù)據(jù)分析領(lǐng)域長(zhǎng)久以來(lái)孜孜不倦追求的目標(biāo)。
社會(huì)網(wǎng)絡(luò)中的聚類(lèi)被稱(chēng)為社區(qū)發(fā)現(xiàn),許多精心設(shè)計(jì)的高效算法可以很好地處理上億用戶的大規(guī)模網(wǎng)絡(luò)。
針對(duì)微博用戶的海量數(shù)據(jù),對(duì)其進(jìn)行數(shù)據(jù)描述性可以分析群體的年齡、性別比例、職業(yè)等;對(duì)于平均數(shù)、中位數(shù)、分位數(shù)、方差等統(tǒng)計(jì)指標(biāo)可以幫助我們粗略了解數(shù)據(jù)分布;回歸分析、方差分析等方法則可以解釋年齡、職業(yè)等因素是否會(huì)影響用戶對(duì)某熱門(mén)話題的關(guān)注程度。
此外,數(shù)據(jù)挖掘在旅游、物流、醫(yī)學(xué)等領(lǐng)域都有著廣泛的應(yīng)用場(chǎng)景。比如數(shù)據(jù)挖掘可以對(duì)旅游客流的趨向有著準(zhǔn)確的預(yù)知性,同時(shí)對(duì)于游客的喜好也有著直接性的掌握;從醫(yī)學(xué)數(shù)據(jù)中尋找潛在的關(guān)系或規(guī)律,可以獲得對(duì)病人進(jìn)行診斷、治療的有效知識(shí),增加對(duì)疾病預(yù)測(cè)的準(zhǔn)確性等。
人工智能與數(shù)據(jù)挖掘
數(shù)據(jù)挖掘從一個(gè)新的視角將數(shù)據(jù)庫(kù)技術(shù)、統(tǒng)計(jì)學(xué)、機(jī)器學(xué)習(xí)、信息檢索技術(shù)、數(shù)據(jù)可視化和模式識(shí)別與人工智能等領(lǐng)域有機(jī)結(jié)合起來(lái),它組合了各個(gè)領(lǐng)域的優(yōu)點(diǎn),因而能從數(shù)據(jù)中挖掘到運(yùn)用其他傳統(tǒng)方法不能發(fā)現(xiàn)的有用知識(shí)。
一般來(lái)說(shuō),統(tǒng)計(jì)特征只能反映數(shù)據(jù)的極少量信息。簡(jiǎn)單的統(tǒng)計(jì)分析可以幫助我們了解數(shù)據(jù),如果希望對(duì)大數(shù)據(jù)進(jìn)行逐個(gè)地、更深層次地探索,總結(jié)出規(guī)律和模型,則需要更加智能的基于機(jī)器學(xué)習(xí)的數(shù)據(jù)分析方法。
所謂“機(jī)器學(xué)習(xí)”,是基于數(shù)據(jù)本身的,自動(dòng)構(gòu)建解決問(wèn)題的規(guī)則與方法。數(shù)據(jù)挖掘中既可以用到非監(jiān)督學(xué)習(xí)方法,也可以用到監(jiān)督學(xué)習(xí)方法。
(一)非監(jiān)督學(xué)習(xí)
非監(jiān)督學(xué)習(xí)是建立在所有數(shù)據(jù)的標(biāo)簽,即所屬的類(lèi)別都是未知的情況下使用的分類(lèi)方法。對(duì)于特定的一組數(shù)據(jù),不知道這些數(shù)據(jù)應(yīng)該分為哪幾類(lèi),也不知道這些類(lèi)別本來(lái)應(yīng)該有怎樣的特征,只知道每個(gè)數(shù)據(jù)的特征向量。若按它們的相關(guān)程度分成很多類(lèi),最先想到的想法就是認(rèn)為特征空間中距離較近的向量之間也較為相關(guān),倘若一個(gè)元素只和其中某些元素比較接近,和另一些元素則相距較遠(yuǎn)。
這時(shí)候,我們就希望每一個(gè)類(lèi)有一個(gè)“中心”,“中心”也是特征向量空間中的向量,是所有那一類(lèi)的元素在向量空間上的重心,即他的每一維為所有包含在這一類(lèi)中的元素的那一維的平均值。如果每一類(lèi)都有這么一個(gè)“中心”,那么我們?cè)诜诸?lèi)數(shù)據(jù)時(shí),只需要看他離哪個(gè)“中心”的距離最近,就將他分到該類(lèi)即可,這也就是K-means算法的思路。
K-means算法,在1957年由Stuart Lloyd在貝爾實(shí)驗(yàn)室提出,最初用于解決連續(xù)的圖區(qū)域劃分問(wèn)題,1982年正式發(fā)表。1965年,E.W.Forgy發(fā)明了Lloyd-Forgy or。James MacQueen在1967年將其命名為K-means算法。

上圖是以隨機(jī)生成的數(shù)據(jù)點(diǎn)為例,k=3的K-means算法的迭代過(guò)程,其中五角星為聚類(lèi)中心,點(diǎn)的顏色是其類(lèi)別。在實(shí)際應(yīng)用中,為了獲得一個(gè)比較好的特征空間,使得“數(shù)據(jù)之間的相似性與他們?cè)谔卣骺臻g上的距離有關(guān),距離越近越相似”這句話盡可能成立,我們往往會(huì)構(gòu)建模型來(lái)把原數(shù)據(jù)變換到這么一個(gè)特征空間,然后使用K-means算法來(lái)進(jìn)行分類(lèi)。
(二)監(jiān)督學(xué)習(xí)
不同于非監(jiān)督學(xué)習(xí),若已知一些數(shù)據(jù)上的真實(shí)分類(lèi)情況,現(xiàn)在要對(duì)新的未知的數(shù)據(jù)進(jìn)行分類(lèi)。這時(shí)候利用已知的分類(lèi)信息,可以得到一些更精確的分類(lèi)方法,這些就是監(jiān)督學(xué)習(xí)方法。
1、決策樹(shù)模型
所謂決策樹(shù),即是一種根據(jù)條件來(lái)進(jìn)行判斷的邏輯框架。其中,判斷的條件,即提出有區(qū)分性的問(wèn)題,以及對(duì)于不同的回答下一步的反映,以及最終的決策給出標(biāo)簽。
決策樹(shù)算法:
(1)選取包含所有數(shù)據(jù)的全集為算法的初始集合A0:
(2)對(duì)于當(dāng)前的集合A,計(jì)算所有可能的“問(wèn)題”在訓(xùn)練集上的F(A,D):
(3)選擇F(A,D)最大的“問(wèn)題”,對(duì)數(shù)據(jù)進(jìn)行提問(wèn),將當(dāng)前的集合由“問(wèn)題”的不同回答,劃分為數(shù)個(gè)子集;
(4)對(duì)每個(gè)子集,重復(fù)b、c,直到所有子集內(nèi)所有元素的類(lèi)別相同;
(5)在實(shí)際應(yīng)用中,數(shù)據(jù)往往有很多特征,因此,“問(wèn)題”往往是選取數(shù)據(jù)的某一特征,而“回答”則是此特征對(duì)應(yīng)的值。
在決策樹(shù)中,效度函數(shù)F(A,D)的選擇非常重要。決策樹(shù)的發(fā)展歷史,也基本是圍繞著F(A,D)的優(yōu)化而展開(kāi)。
2、kNN算法
只知道每個(gè)數(shù)據(jù)在特征空間下的特征向量情況下,可以對(duì)數(shù)據(jù)采用無(wú)監(jiān)督分類(lèi)方法K-means。如果我們擁有了其中一部分?jǐn)?shù)據(jù)的標(biāo)簽,我們就可以利用這些標(biāo)簽進(jìn)行kNN分類(lèi)。
數(shù)據(jù)之間的相似性與他們?cè)谔卣骺臻g上的距離有關(guān)。距離越近越相似,越可能擁有相同的標(biāo)簽。
假設(shè)我們已經(jīng)有了很多既知道特征向量也知道具體標(biāo)簽的數(shù)據(jù)對(duì)于新的只知道特征向量卻不知道具體標(biāo)簽的數(shù)據(jù),我們可以選取離這個(gè)特征向量最近的k個(gè)已經(jīng)知道標(biāo)簽的數(shù)據(jù),然后選取他們中間最多的元素所屬于的那個(gè)標(biāo)簽,作為新數(shù)據(jù)的預(yù)測(cè)標(biāo)簽。也可以根據(jù)他們與新數(shù)據(jù)的特征向量之間的距離加權(quán)(如最近得5分,第二近得4分等),取權(quán)重總和最大的標(biāo)簽作為預(yù)測(cè)標(biāo)簽。
kNN算法不需要構(gòu)建模型或者訓(xùn)練,和K-means算法一樣,往往是和某個(gè)構(gòu)建特征空間的模型一起使用。
此外,還有回歸分類(lèi)、神經(jīng)網(wǎng)絡(luò)、樸素貝葉斯分類(lèi)等等。
巨頭們的數(shù)據(jù)挖掘之路
在當(dāng)下,數(shù)據(jù)挖掘也逐漸成為當(dāng)下的熱門(mén)研究領(lǐng)域之一,受到了谷歌、亞馬遜、微軟、百度、阿里、騰訊等科技巨頭的追捧。
(一)谷歌
谷歌幾乎每年都會(huì)發(fā)表一些讓人驚艷的研究工作,包括之前的MapReduce、Word2Vec、BigTable,近期的BERT。數(shù)據(jù)挖掘是谷歌研究的一個(gè)重點(diǎn)領(lǐng)域。
2018年谷歌全球不同研究中心在數(shù)據(jù)挖掘頂級(jí)國(guó)際會(huì)議KDD上一共發(fā)表了7篇文章。
(二)亞馬遜
亞馬遜公司近幾年發(fā)展勢(shì)頭超級(jí)猛,前幾年華麗的轉(zhuǎn)身:從一個(gè)網(wǎng)上商店公司變?yōu)樵破脚_(tái)公司再轉(zhuǎn)變到目前的人工智能公司,亞馬遜也在數(shù)據(jù)挖掘領(lǐng)域開(kāi)始占有一席,尤其是在人才網(wǎng)羅、開(kāi)源、核心技術(shù)研發(fā)。
2018年亞馬遜在數(shù)據(jù)挖掘頂級(jí)國(guó)際會(huì)議KDD的Applied Data Science Track(應(yīng)用數(shù)據(jù)科學(xué)Track)上一共發(fā)表了2篇文章,另外還有兩個(gè)應(yīng)用科學(xué)的邀請(qǐng)報(bào)告。
(三)微軟
微軟是老牌論文王國(guó),一直以來(lái)都在學(xué)術(shù)界特別活躍,因此在KDD上每年和微軟有關(guān)的論文非常多,因此這里只統(tǒng)計(jì)了微軟作為第一作者的文章。
2018年在數(shù)據(jù)挖掘頂級(jí)國(guó)際會(huì)議KDD上一共發(fā)表了6篇文章,另外還有一個(gè)應(yīng)用科學(xué)的邀請(qǐng)報(bào)告,這些文章和報(bào)告都更多的從大數(shù)據(jù)的角度在思考如何更有效,更快速的分析。
(四)阿里巴巴
阿里巴巴在電子商務(wù)方面做了大量的數(shù)據(jù)挖掘研究。尤其是在表示學(xué)習(xí)和增強(qiáng)學(xué)習(xí)做了幾個(gè)很有意思的工作。
2018年阿里巴巴在數(shù)據(jù)挖掘頂級(jí)國(guó)際會(huì)議KDD上作為第一作者單位一共發(fā)表了8篇文章。
(五)騰訊
2018年騰訊在數(shù)據(jù)挖掘頂級(jí)國(guó)際會(huì)議KDD上作為第一作者單位一共發(fā)表了2篇文章。
(六)百度
2018年百度在數(shù)據(jù)挖掘頂級(jí)國(guó)際會(huì)議KDD上作為第一作者單位一共發(fā)表了2篇文章。
大數(shù)據(jù)與數(shù)據(jù)挖掘
大數(shù)據(jù)是近年隨著互聯(lián)網(wǎng)、物聯(lián)網(wǎng)、通信網(wǎng)絡(luò)以及人類(lèi)社交網(wǎng)絡(luò)快速發(fā)展的結(jié)果,成為一個(gè)交叉研究學(xué)科,和數(shù)據(jù)挖掘緊密相連。
大數(shù)據(jù)的迅速發(fā)展也使得數(shù)據(jù)挖掘?qū)ο笞兊酶鼮閺?fù)雜,不僅包括人類(lèi)社會(huì)與物理世界的復(fù)雜聯(lián)系,還包括呈現(xiàn)出的高度動(dòng)態(tài)化。這使得很多傳統(tǒng)數(shù)據(jù)挖掘算法不再適用,傳統(tǒng)數(shù)據(jù)挖掘算法必須滿足對(duì)真實(shí)數(shù)據(jù)和實(shí)時(shí)數(shù)據(jù)的處理能力,才能從大量無(wú)序數(shù)據(jù)中獲取真正價(jià)值。
一方面大數(shù)據(jù)包含數(shù)據(jù)挖掘的各個(gè)階段,即數(shù)據(jù)收集、預(yù)處理、特征選擇、模式挖掘、表示等;另一方面大數(shù)據(jù)的基礎(chǔ)架構(gòu)又為數(shù)據(jù)挖掘提供上層數(shù)據(jù)處理的硬件設(shè)施。
▲大數(shù)據(jù)處理平臺(tái)技術(shù)架構(gòu)圖
從技術(shù)架構(gòu)角度,大數(shù)據(jù)處理平臺(tái)可劃分為4個(gè)層次:數(shù)據(jù)采集層、數(shù)據(jù)存儲(chǔ)層、數(shù)據(jù)處理層和服務(wù)封裝層。
除此之外,大數(shù)據(jù)處理平臺(tái)一般還包括數(shù)據(jù)安全和隱式保護(hù)模塊,這一模塊貫穿大數(shù)據(jù)處理平臺(tái)的各個(gè)層次。
-
AI
+關(guān)注
關(guān)注
87文章
30728瀏覽量
268886
原文標(biāo)題:清華178頁(yè)深度報(bào)告:一文看懂AI數(shù)據(jù)挖掘
文章出處:【微信號(hào):robotop2025,微信公眾號(hào):每日機(jī)器人峰匯】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論