 NLP中的深度學習技術概述
NLP中的深度學習技術概述
該項目是對基于深度學習的自然語言處理(NLP)的概述,包括用來解決不同 NLP 任務和應用的深度學習模型(如循環神經網絡、卷積神經網絡和強化學習)的理論介紹和實現細節,以及對 NLP 任務(機器翻譯、問答和對話系統)當前最優結果的總結。
該項目的主要動機如下:
維護最新 NLP 研究學習資源,如當前最優結果、新概念和應用、新的基準數據集、代碼/數據集發布等。
創建開放性資源,幫助指引研究者和對 NLP 感興趣的人。
這是一個合作性項目,專家研究人員可以基于他們近期的研究和實驗結果提出變更建議。
第一章:簡介
自然語言處理(NLP)是指對人類語言進行自動分析和表示的計算技術,這種計算技術由一系列理論驅動。NLP 研究從打孔紙帶和批處理的時代就開始發展,那時分析一個句子需要多達 7 分鐘的時間。到了現在谷歌等的時代,數百萬網頁可以在不到一秒鐘內處理完成。NLP 使計算機能夠執行大量自然語言相關的任務,如句子結構解析、詞性標注、機器翻譯和對話系統等。
深度學習架構和算法為計算機視覺與傳統模式識別領域帶來了巨大進展。跟隨這一趨勢,現在的 NLP 研究越來越多地使用新的深度學習方法(見圖 1)。之前數十年,用于解決 NLP 問題的機器學習方法一般都基于淺層模型(如 SVM 和 logistic 回歸),這些模型都在非常高維和稀疏的特征(one-hot encoding)上訓練得到。而近年來,基于稠密向量表征的神經網絡在多種 NLP 任務上得到了不錯結果。這一趨勢取決了詞嵌入和深度學習方法的成功。深度學習使多級自動特征表征學習成為可能。而基于傳統機器學習的 NLP 系統嚴重依賴手動制作的特征,它們及其耗時,且通常并不完備。

圖 1:過去 6 年 ACL、EMNLP、EACL、NAACL 會議上深度學習論文的比例(長論文)。
Ronan Collobert 等人 2011 年的研究《Natural Language Processing (Almost) from Scratch》展示了在多個 NLP 任務上優于當時最優方法的簡單深度學習框架,比如命名實體識別(NER)、語義角色標注(SRL)和詞性標注。之后,研究人員提出了大量基于復雜深度學習的算法,用于解決有難度的 NLP 任務。本文綜述了用于自然語言任務的主要深度學習模型和方法,如卷積神經網絡、循環神經網絡和遞歸神經網絡。本文還討論了記憶增強策略、注意力機制,以及如何使用無監督模型、強化學習方法和深度生成模型解決語言任務。
本文綜述了 NLP 研究中最流行的深度學習方法,結構如下:第二章介紹分布式表征的概念,它們是復雜深度學習模型的基礎;第 3、4、5 章討論了流行的模型(如卷積、循環、遞歸神經網絡)及其在不同 NLP 任務中的應用;第 6 章列舉了強化學習在 NLP 中的近期應用,以及無監督句子表征學習的近期發展;第 7 章介紹了深度學習模型結合記憶模塊這一近期趨勢;第 8 章概述了多種深度學習方法在 NLP 任務標準數據集上的性能。機器之心選取了第 2、3、4、8 章進行重點介紹。
第二章:分布式表征
基于統計的 NLP 已經成為建模復雜自然語言任務的首要選擇。然而在它剛興起的時候,基于統計的 NLP 經常遭受到維度災難,尤其是在學習語言模型的聯合概率函數時。這為構建能在低維空間中學習分布式詞表征的方法提供了動力,這種想法也就導致了詞嵌入方法的誕生。
第一種在低維空間中學習密集型的分布式詞表征是 Yoshua Bengio 等人在 2003 年提出的 A Neural Probabilistic Language Model,這是一種基于學習而對抗維度災難的優美想法。
詞嵌入
如下圖 2 所示,分布式向量或詞嵌入向量基本上遵循分布式假設,即具有相似語義的詞傾向于具有相似的上下文詞,因此這些詞向量嘗試捕獲鄰近詞的特征。分布式詞向量的主要優點在于它們能捕獲單詞之間的相似性,使用余弦相似性等度量方法評估詞向量之間的相似性也是可能的。
詞嵌入常用于深度學習中的第一個數據預處理階段,一般我們可以在大型無標注文本語料庫中最優化損失函數,從而獲得預訓練的詞嵌入向量。例如基于上下文預測具體詞(Mikolov et al., 2013b, a)的方法,它能學習包含了一般句法和語義的詞向量。這些詞嵌入方法目前已經被證明能高效捕捉上下文相似性,并且由于它們的維度非常小,因此在計算核心 NLP 任務是非常快速與高效的。

圖 2:分布式詞向量表征,其中每一個詞向量只有 D 維,且遠小于詞匯量大小 V,即 D<
多年以來,構建這種詞嵌入向量的模型一般是淺層神經網絡,并沒有必要使用深層神經網絡構建更好的詞嵌入向量。不過基于深度學習的 NLP 模型常使用這些詞嵌入表示短語甚至句子,這實際上是傳統基于詞統計模型和基于深度學習模型的主要差別。目前詞嵌入已經是 NLP 任務的標配,大多數 NLP 任務的頂尖結果都需要借助它的能力。
本身詞嵌入就能直接用于搜索近義詞或者做詞義的類推,而下游的情感分類、機器翻譯、語言建模等任務都能使用詞嵌入編碼詞層面的信息。最近比較流行的預訓練語言模型其實也參考了詞嵌入的想法,只不過預訓練語言模型在詞嵌入的基礎上進一步能編碼句子層面的語義信息。總的而言,詞嵌入的廣泛使用早已體現在眾多文獻中,它的重要性也得到一致的認可。
分布式表示(詞嵌入)主要通過上下文或者詞的「語境」來學習本身該如何表達。上個世紀 90 年代,就有一些研究(Elman, 1991)標志著分布式語義已經起步,后來的一些發展也都是對這些早期工作的修正。此外,這些早期研究還啟發了隱狄利克雷分配等主題建模(Blei et al., 2003)方法和語言建模(Bengio et al., 2003)方法。
在 2003 年,Bengio 等人提出了一種神經語言模型,它可以學習單詞的分布式表征。他們認為這些詞表征一旦使用詞序列的聯合分布構建句子表征,那么就能構建指數級的語義近鄰句。反過來,這種方法也能幫助詞嵌入的泛化,因為未見過的句子現在可以通過近義詞而得到足夠多的信息。
圖 3:神經語言模型(圖源:http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf)。
Collobert 和 Weston(2008) 展示了第一個能有效利用預訓練詞嵌入的研究工作,他們提出的神經網絡架構構成了當前很多方法的基礎。這一項研究工作還率先將詞嵌入作為 NLP 任務的高效工具,不過詞嵌入真正走向 NLP 主流還是 Mikolov 等人在 2013 年做出的研究《Distributed Representations of Words and Phrases and their Compositionality》。
Mikolov 等研究者在這篇論文中提出了連續詞袋模型(CBOW)和 Skip-Gram 模型,這兩種方法都能學習高質量的分布式詞表征。此外,令這兩種方法受到極大關注的是另一種附加屬性:語義合成性,即兩個詞向量相加得到的結果是語義相加的詞,例如「man」+「royal」=「king」。這種語義合成性的理論依據最近已經由 Gittens et al. (2017) 給出,他們表示只有保證某些特定的假設才能滿足語義合成性,例如詞需要在嵌入空間中處于均勻分布。
Pennington et al. (2014) 提出了另一個非常出名的詞嵌入方法 GloVe,它基本上是一種基于詞統計的模型。在有些情況下,CBOW 和 Skip-Gram 采用的交叉熵損失函數有劣勢。因此 GloVe 采用了平方損失,它令詞向量擬合預先基于整個數據集計算得到的全局統計信息,從而學習高效的詞詞表征。
一般 GloVe 模型會先對單詞計數進行歸一化,并通過對數平滑來最終得到詞共現矩陣,這個詞共現矩陣就表示全局的統計信息。這個矩陣隨后可以通過矩陣分解得到低維的詞表征,這一過程可以通過最小化重構損失來獲得。下面將具體介紹目前仍然廣泛使用的 CBOW 和 Skip-Gram 兩種Word2Vec方法(Mikolov et al., 2013)。
Word2Vec
可以說 Mikolov 等人徹底變革了詞嵌入,尤其是他們提出的 CBOW 和 Skip-Gram 模型。CBOW 會在給定上下文詞的情況下計算目標詞(或中心詞)的條件概率,其中上下文詞的選取范圍通過窗口大小 k 決定。而Skip-Gram的做法正好與CBOW相反,它在給定目標詞或中心詞的情況下預測上下文詞。一般上下文詞都會以目標詞為中心對稱地分布在兩邊,且在窗口內的詞與中心詞的距離都相等。也就是說不能因為某個上下文詞離中心詞比較遠,就認為它對中心詞的作用比較弱。
在無監督的設定中,詞嵌入的維度可以直接影響到預測的準確度。一般隨著詞嵌入維度的增加,預測的準確度也會增加,直到準確率收斂到某個點。一般這樣的收斂點可以認為是最佳的詞嵌入維度,因為它在不影響準確率的情況下最精簡。通常情況下,我們使用的詞嵌入維度可以是 128、256、300、500 等,相比于幾十萬的詞匯庫大小已經是很小的維度了。
下面我們可以考慮 CBOW 的簡化版,上下文只考慮離中心詞最近的一個單詞,這基本上就是二元語言模型的翻版。
圖 4:CBOW 模型。
如圖 4 所示,CBOW 模型就是一個簡單的全連接神經網絡,它只有一個隱藏層。輸入層是上下文詞的 one-hot 向量,它有 V 個神經元(詞匯量),而中間的隱藏層只有 N 個神經元,N 是要遠遠小于 V 的。最后的輸出層是所有詞上的一個 Softmax 函數。層級之間的權重矩陣分別是 V*N 階的 W 和 N*V 階的 W',詞匯表中的每一個詞最終會表征為兩個向量:v_c 和 v_w,它們分別對應上下文詞表征和目標詞表征。若輸入的是詞表中第 k 個詞,那么我們有:
總體而言,在給定上下文詞 c 作為輸入的情況下,對于任意詞 w_i 有:
參數 θ={V_w, V_c} 都是通過定義目標函數而學習到的,一般目標函數可以定義為對數似然函數,且通過計算以下梯度更新權重:
在更廣泛的 CBOW 模型中,所有上下文詞的 one-hot 向量都會同時作為輸入,即:
詞嵌入的一個局限是它們無法表示短語(Mikolov et al., 2013),即兩個詞或多個詞的組合并不表示對應的短語意義,例如「人民」+「大學」并不能組合成「人民大學」。Mikolov 提出的一種解決辦法是基于詞共現識別這些短語,并為它們單獨地學一些詞嵌入向量,而 Rie Johnson 等研究者在 15 年更是提出直接從無監督數據中學習 n-gram 詞嵌入。
另一種局限性在于學習的詞嵌入僅基于周圍詞的小窗口,有時候「good」和「bad」幾乎有相同的詞嵌入,這對于情感分析等下游任務很不友好。有時候這些相似的詞嵌入有正好相反的情感,這對于需要區別情感的下游任務簡直是個災難,它甚至比用 One-hot 向量的表征方法還要有更差的性能。Duyu Tang(2014)等人通過提出特定情感詞嵌入(SSWE)來解決這個問題,他們在學習嵌入時將損失函數中的監督情感納入其中。
一個比較重要的觀點是,詞嵌入應該高度依賴于他們要使用的領域。Labutov 和 Lipson(2013) 提出了一種用于特定任務的詞嵌入,他們會重新訓練詞嵌入,因此將詞嵌入與將要進行的下游任務相匹配,不過這種方法對計算力的需求比較大。而 Mikolov 等人嘗試使用負采樣的方法來解決這個問題,負采樣僅僅只是基于頻率對負樣本進行采樣,這個過程直接在訓練中進行。
此外,傳統的詞嵌入算法為每個詞分配不同的向量,這使得其不能解釋多義詞。在最近的一項工作中,Upadhyay 等人 (2017) 提出了一種新方法來解決這個問題,他們利用多語平行數據來學習多語義詞嵌入。例如英語的「bank」在翻譯到法語時有兩種不同的詞:banc 和 banque,它們分別表示金融和地理意義,而多語言的分布信息能幫助詞嵌入解決一詞多義的問題。
下表 1 提供了用于創建詞嵌入的現有框架,它們都可以訓練詞嵌入并進一步與深度學習模型相結合:
說到這里,小編不得不宣傳一波我們的小項目,我們主要使用維基的中文語料訓練了一個中文詞嵌入,并提供了 Skip-Gram 和 GloVe 兩種模型的訓練方法。讀者可以簡單地使用我們已訓練的詞嵌入,或者根據我們提供的 Jupyter Notebook 教程學習如何訓練詞嵌入。簡單而言,訓練主要可以分為 5 個步驟,即下載維基中文語料、將繁體轉化為簡體、采用結巴分詞、預處理并構建數據集、開始訓練。
當然我們放在 Colab 的示例代碼只是訓練部分維基語料,但也能做出了較為合理的中文詞嵌入。
項目地址:https://github.com/HoratioJSY/cn-words
第三章:卷積神經網絡
隨著詞嵌入的流行及其在分布式空間中展現出的強大表征能力,我們需要一種高效的特征函數,以從詞序列或 n-grams 中抽取高級語義信息。隨后這些抽象的語義信息能用于許多 NLP 任務,如情感分析、自動摘要、機器翻譯和問答系統等。卷積神經網絡(CNN)因為其在計算機視覺中的有效性而被引入到自然語言處理中,實踐證明它也非常適合序列建模。
圖 5:用于執行詞級分類預測的 CNN 框架。(Collobert and Weston (2008))
使用 CNN 進行句子建模可以追溯到 Collobert 和 Weston (2008) 的研究,他們使用多任務學習為不同的 NLP 任務輸出多個預測,如詞性標注、語塊分割、命名實體標簽和語義相似詞等。其中查找表可以將每一個詞轉換為一個用戶自定義維度的向量。因此通過查找表,n 個詞的輸入序列 {s_1,s_2,... s_n } 能轉換為一系列詞向量 {w_s1, w_s2,... w_sn},這就是圖 5 所示的輸入。
這可以被認為是簡單的詞嵌入方法,其中權重都是通過網絡來學習的。在 Collobert 2011 年的研究中,他擴展了以前的研究,并提出了一種基于 CNN 的通用框架來解決大量 NLP 任務,這兩個工作都令 NLP 研究者嘗試在各種任務中普及 CNN 架構。
CNN 具有從輸入句子抽取 n-gram 特征的能力,因此它能為下游任務提供具有句子層面信息的隱藏語義表征。下面簡單描述了一個基于 CNN 的句子建模網絡到底是如何處理的。
基礎 CNN
1. 序列建模
對于每一個句子,w_i∈R^d 表示句子中第 i 個詞的詞嵌入向量,其中 d 表示詞嵌入的維度。給定有 n 個詞的句子,句子能表示為詞嵌入矩陣 W∈R^n×d。下圖展示了將這樣一個句子作為輸入饋送到 CNN 架構中。
圖 6:使用 CNN 的文本建模(Zhang and Wallace , 2015)。
若令 w_i:i+j 表示 w_i, w_i+1,...w_j 向量的拼接,那么卷積就可以直接在這個詞嵌入輸入層做運算。卷積包含 d 個通道的卷積核 k∈R^hd,它可以應用到窗口為 h 個詞的序列上,并生成新的特征。例如,c_i 即使用卷積核在詞嵌入矩陣上得到的激活結果:
若 b 是偏置項,f 是非線性激活函數,例如雙曲正切函數。使用相同的權重將濾波器 k 應用于所有可能的窗口,以創建特征圖。
在卷積神經網絡中,大量不同寬度的卷積濾波器(也叫做內核,通常有幾百個)在整個詞嵌入矩陣上滑動。每個內核提取一個特定的 n-gram 模式。卷積層之后通常是最大池化策略 c^=max{c},該策略通過對每個濾波器應用最大運算來對輸入進行二次采樣。使用這個策略有兩大原因。
首先,最大池化提供固定長度的輸出,這是分類所需的。因此,不管濾波器的大小如何,最大池化總是將輸入映射到輸出的固定維度上。其次,它在降低輸出維度的同時保持了整個句子中最顯著的 n-gram 特征。這是通過平移不變的方式實現的,每個濾波器都能從句子的任何地方提取特定的特征(如,否定),并加到句子的最終表示中。
詞嵌入可以隨機初始化,也可以在大型未標記語料庫上進行預訓練。第二種方法有時對性能提高更有利,特別是當標記數據有限時。卷積層和最大池化的這種組合通常被堆疊起來,以構建深度 CNN 網絡。這些順序卷積有助于改進句子的挖掘,以獲得包含豐富語義信息的真正抽象表征。內核通過更深的卷積覆蓋了句子的大部分,直到完全覆蓋并創建了句子特征的總體概括。
2. 窗口方法
上述架構將完整句子建模為句子表征。然而,許多 NLP 任務(如命名實體識別,詞性標注和語義角色標注)需要基于字的預測。為了使 CNN 適應這樣的任務,需要使用窗口方法,其假定單詞的標簽主要取決于其相鄰單詞。因此,對于每個單詞,存在固定大小的窗口,窗口內的子句都在處理的范圍內。如前所述,獨立的 CNN 應用于該子句,并且預測結果歸因于窗口中心的單詞。按照這個方法,Poira 等人(2016)采用多級深度 CNN 來標記句子中的每個單詞為 aspect 或 non-aspect。結合一些語言模式,它們的集成分類器在 aspect 檢測方面表現很好。
詞級分類的最終目的通常是為整個句子分配一系列的標簽。在這樣的情況下,有時會采用結構化預測技術來更好地捕獲相鄰分類標簽間的關系,最終生成連貫標簽序列,從而給整個句子提供最大分數。
為了獲得更大的上下文范圍,經典窗口方法通常與時延神經網絡(TDNN)相結合。這種方法中,可以在整個序列的所有窗口上進行卷積。通過定義特定寬度的內核,卷積通常會受到約束。因此,相較于經典窗口方法(只考慮要標記單詞周圍窗口中的單詞),TDNN 會同時考慮句子中的所有單詞窗口。TDNN 有時也能像 CNN 架構一樣堆疊,以提取較低層的局部特征和較高層的總體特征。
應用
在這部分,研究者介紹了一些使用 CNN 來處理 NLP 任務的研究,這些研究在它們當時所處時代屬于前沿。
Kim 探討了使用上述架構進行各種句子分類任務,包括情感、主觀性和問題類型分類,結果很有競爭力。因其簡單有效的特點,這種方法很快被研究者接受。在針對特定任務進行訓練之后,隨機初始化的卷積內核成為特定 n-gram 的特征檢測器,這些檢測器對于目標任務非常有用。但是這個網絡有很多缺點,最主要的一點是 CNN 沒有辦法構建長距離依存關系。
圖 7:4 種預訓練 7-gram 內核得到的最好核函數;每個內核針對一種特定 7-gram。
Kalchbrenner 等人的研究在一定程度上解決了上述問題。他們發表了一篇著名的論文,提出了一種用于句子語義建模的動態卷積神經網絡(DCNN)。他們提出了動態 k-max 池化策略,即給定一個序列 p,選擇 k 種最有效的特征。選擇時保留特征的順序,但對其特定位置不敏感。在 TDNN 的基礎上,他們增加了動態 k-max 池化策略來創建句子模型。這種結合使得具有較小寬度的濾波器能跨越輸入句子的長范圍,從而在整個句子中積累重要信息。在下圖中,高階特征具有高度可變的范圍,可能是較短且集中,或者整體的,和輸入句子一樣長。他們將模型應用到多種任務中,包括情感預測和問題類型分類等,取得了顯著的成果。總的來說,這項工作在嘗試為上下文語義建模的同時,對單個內核的范圍進行了注釋,并提出了一種擴展其范圍的方法。
圖 8:DCNN 子圖,通過動態池化,較高層級上的寬度較小濾波器也能建立輸入句子中的長距離相關性。
情感分類等任務還需要有效地抽取 aspect 與其情感極性(Mukherjee and Liu, 2012)。Ruder 等人(2016)還將 CNN 應用到了這類任務,他們將 aspect 向量與詞嵌入向量拼接以作為輸入,并獲得了很好的效果。CNN 建模的方法一般因文本的長短而異,在較長文本上的效果比較短文本上好。Wang et al. (2015) 提出利用 CNN 建模短文本的表示,但是因為缺少可用的上下文信息,他們需要額外的工作來創建有意義的表征。因此作者提出了語義聚類,其引入了多尺度語義單元以作為短文本的外部知識。最后 CNN 組合這些單元以形成整體表示。
CNN 還廣泛用于其它任務,例如 Denil et al. (2014) 利用 DCNN 將構成句子的單詞含義映射到文本摘要中。其中 DCNN 同時在句子級別和文檔級別學習卷積核,這些卷積核會分層學習并捕獲不同水平的特征,因此 DCNN 最后能將底層的詞匯特征組合為高級語義概念。
此外,CNN 也適用于需要語義匹配的 NLP 任務。例如我們可以利用 CNN 將查詢與文檔映射到固定維度的語義空間,并根據余弦相似性對與特定查詢相關的文檔進行排序。在 QA 領域,CNN 也能度量問題和實體之間的語義相似性,并借此搜索與問題相關的回答。機器翻譯等任務需要使用序列信息和長期依賴關系,因此從結構上來說,這種任務不太適合 CNN。但是因為 CNN 的高效計算,還是有很多研究者嘗試使用 CNN 解決機器翻譯問題。
總體而言,CNN 在上下文窗口中挖掘語義信息非常有效,然而它們是一種需要大量數據訓練大量參數的模型。因此在數據量不夠的情況下,CNN 的效果會顯著降低。CNN 另一個長期存在的問題是它們無法對長距離上下文信息進行建模并保留序列信息,其它如遞歸神經網絡等在這方面有更好的表現。
第四章:循環神經網絡
循環神經網絡(RNN)的思路是處理序列信息。「循環」表示 RNN 模型對序列中的每一個實例都執行同樣的任務,從而使輸出依賴于之前的計算和結果。通常,RNN 通過將 token 挨個輸入到循環單元中,來生成表示序列的固定大小向量。一定程度上,RNN 對之前的計算有「記憶」,并在當前的處理中使用對之前的記憶。該模板天然適合很多 NLP 任務,如語言建模、機器翻譯、語音識別、圖像字幕生成。因此近年來,RNN 在 NLP 任務中逐漸流行。
對 RNN 的需求
這部分將分析支持 RNN 在大量 NLP 任務中廣泛使用的基本因素。鑒于 RNN 通過建模序列中的單元來處理序列,它能夠捕獲到語言中的內在序列本質,序列中的單元是字符、單詞甚至句子。語言中的單詞基于之前的單詞形成語義,一個簡單的示例是「dog」和「hot dog」。RNN 非常適合建模語言和類似序列建模任務中的此類語境依賴,這使得大量研究者在這些領域中使用 RNN,頻率多于 CNN。
RNN 適合序列建模任務的另一個因素是它能夠建模不定長文本,包括非常長的句子、段落甚至文檔。與 CNN 不同,RNN 的計算步靈活,從而提供更好的建模能力,為捕獲無限上下文創造了可能。這種處理任意長度輸入的能力是使用 RNN 的主要研究的賣點之一。
很多 NLP 任務要求對整個句子進行語義建模。這需要在固定維度超空間中創建句子的大意。RNN 對句子的總結能力使得它們在機器翻譯等任務中得到更多應用,機器翻譯任務中整個句子被總結為固定向量,然后映射回不定長目標序列。
RNN 還對執行時間分布式聯合處理(time distributed joint processing)提供網絡支持,大部分序列標注任務(如詞性標注)屬于該領域。具體用例包括多標簽文本分類、多模態情感分析等應用。
上文介紹了研究人員偏好使用 RNN 的幾個主要因素。然而,就此認為 RNN 優于其他深度網絡則大錯特錯。近期,多項研究就 CNN 優于 RNN 提出了證據。甚至在 RNN 適合的語言建模等任務中,CNN 的性能與 RNN 相當。CNN 與 RNN 在建模句子時的目標函數不同。RNN 嘗試建模任意長度的句子和無限的上下文,而 CNN 嘗試提取最重要的 n-gram。盡管研究證明 CNN 是捕捉 n-gram 特征的有效方式,這在特定長度的句子分類任務中差不多足夠了,但 CNN 對詞序的敏感度有限,容易限于局部信息,忽略長期依賴。
《Comparative Study of CNN and RNN for Natural Language Processing》對 CNN 和 RNN 的性能提供了有趣的見解。研究人員在多項 NLP 任務(包括情感分類、問答和詞性標注)上測試后,發現沒有明確的贏家:二者的性能依賴于任務所需的全局語義。
下面,我們討論了文獻中廣泛使用的一些 RNN 模型。
RNN 模型
1. 簡單 RNN
在 NLP 中,RNN 主要基于 Elman 網絡,最初是三層網絡。圖 9 展示了一個較通用的 RNN,它按時間展開以適應整個序列。圖中 x_t 作為網絡在時間步 t 處的輸入,s_t 表示在時間步 t 處的隱藏狀態。s_t 的計算公式如下:
因此,s_t 的計算基于當前輸入和之前時間步的隱藏狀態。函數 f 用來做非線性變換,如 tanh、ReLU,U、V、W 表示在不同時間上共享的權重。在 NLP 任務中,x_t 通常由 one-hot 編碼或嵌入組成。它們還可以是文本內容的抽象表征。o_t 表示網絡輸出,通常也是非線性的,尤其是當網絡下游還有其他層的時候。
圖 9:簡單 RNN 網絡(圖源:https://www.nature.com/articles/nature14539)
RNN 的隱藏狀態通常被認為是其最重要的元素。如前所述,它被視為 RNN 的記憶元素,從其他時間步中累積信息。但是,在實踐中,這些簡單 RNN 網絡會遇到梯度消失問題,使學習和調整網絡之前層的參數變得非常困難。
該局限被很多網絡解決,如長短期記憶網絡(LSTM)、門控循環單元(GRU)和殘差網絡(ResNet),前兩個是 NLP 應用中廣泛使用的 RNN 變體。
2. 長短期記憶(LSTM)
LSTM 比簡單 RNN 多了『遺忘』門,其獨特機制幫助該網絡克服了梯度消失和梯度爆炸問題。
圖 10:LSTM 和 GRU 門圖示(圖源:https://arxiv.org/abs/1412.3555)
與原版 RNN 不同,LSTM 允許誤差通過無限數量的時間步進行反向傳播。它包含三個門:輸入門、遺忘門和輸出門,并通過結合這三個門來計算隱藏狀態,如下面的公式所示:
3. 門控循環單元(GRU)
另一個門控 RNN 變體是 GRU,復雜度更小,其在大部分任務中的實驗性能與 LSTM 類似。GRU 包括兩個門:重置門和更新門,并像沒有記憶單元的 LSTM 那樣處理信息流。因此,GRU 不加控制地暴露出所有的隱藏內容。由于 GRU 的復雜度較低,它比 LSTM 更加高效。其工作原理如下:
研究者通常面臨選擇合適門控 RNN 的難題,這個問題同樣困擾 NLP 領域開發者。縱觀歷史,大部分對 RNN 變體的選擇都是啟發式的。《Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling》對前面三種 RNN 變體進行了對比評估,不過評估不是在 NLP 任務上進行的,而是復調音樂建模和語音信號建模相關任務。他們的評估結果明確表明門控單元(LSTM 和 GRU)優于傳統的簡單 RNN(實驗中用的是 tanh 激活函數),如下圖所示。但是,他們對這兩種門控單元哪個更好沒有定論。其他研究也注意到了這一點,因此人們在二者之間作出選擇時通常利用算力等其他因素。
圖 11:不同 RNN 變體在訓練集和驗證集上的學習曲線,上圖 x 軸表示迭代次數,下圖 x 軸表示掛鐘時間,y 軸表示模型的負對數似然(以對數標尺顯示)。
應用
1. 用于單詞級別分類任務的 RNN
之前,RNN 經常出現在單詞級別的分類任務中。其中的很多應用到現在仍然是所在任務中的最優結果。論文《Neural Architectures for Named Entity Recognition》提出 LSTM+CRF 架構。它使用雙向 LSTM 解決命名實體識別問題,該網絡捕捉目標單詞周圍的任意長度上下文信息(緩解了固定窗口大小的約束),從而生成兩個固定大小的向量,再在向量之上構建另一個全連接層。最終的實體標注部分使用的是 CRF 層。
RNN 在語言建模任務上也極大地改善了基于 count statistics 的傳統方法。該領域的開創性研究是 Alex Graves 2013 年的研究《Generating Sequences With Recurrent Neural Networks》,介紹了 RNN 能夠有效建模具備長距離語境結構的復雜序列。該研究首次將 RNN 的應用擴展到 NLP 以外。之后,Sundermeyer 等人的研究《From Feedforward to Recurrent LSTM Neural Networks for Language Modeling》對比了在單詞預測任務中用 RNN 替換前饋神經網絡獲得的收益。該研究提出一種典型的神經網絡層級架構,其中前饋神經網絡比基于 count 的傳統語言模型有較大改善,RNN 效果更好,LSTM 的效果又有改進。該研究的一個重點是他們的結論可應用于多種其他任務,如統計機器翻譯。
2. 用于句子級別分類任務的 RNN
Xin Wang 等人 2015 年的研究《Predicting Polarities of Tweets by Composing Word Embeddings with Long Short-Term Memory》提出使用 LSTM 編碼整篇推文(tweet),用 LSTM 的隱藏狀態預測情感極性。這種簡單的策略被證明與 Nal Kalchbrenner 等人 2014 年的研究《A Convolutional Neural Network for Modelling Sentences》提出的較復雜 DCNN 結構性能相當,DCNN 旨在使 CNN 模型具備捕捉長期依賴的能力。在一個研究否定詞組(negation phrase)的特殊案例中,Xin Wang 等人展示了 LSTM 門的動態可以捕捉單詞 not 的反轉效應。
與 CNN 類似,RNN 的隱藏狀態也可用于文本之間的語義匹配。在對話系統中,Lowe 等人 2015 年的研究《The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems》提出用 Dual-LSTM 匹配信息和候選回復,Dual-LSTM 將二者編碼為固定大小的向量,然后衡量它們的內積用于對候選回復進行排序。
3. 用于生成語言的 RNN
NLP 領域中的一大難題是生成自然語言,而這是 RNN 另一個恰當的應用。基于文本或視覺數據,深度 LSTM 在機器翻譯、圖像字幕生成等任務中能夠生成合理的任務特定文本。在這些案例中,RNN 作為解碼器。
在 Ilya Sutskever 等人 2014 年的研究《Sequence to Sequence Learning with Neural Networks》中,作者提出了一種通用深度 LSTM 編碼器-解碼器框架,可以實現序列之間的映射。使用一個 LSTM 將源序列編碼為定長向量,源序列可以是機器翻譯任務中的源語言、問答任務中的問題或對話系統中的待回復信息。然后將該向量作為另一個 LSTM(即解碼器)的初始狀態。在推斷過程中,解碼器逐個生成 token,同時使用最后生成的 token 更新隱藏狀態。束搜索通常用于近似最優序列。
該研究使用了一個 4 層 LSTM 在機器翻譯任務上進行端到端實驗,結果頗具競爭力。《A Neural Conversational Model》使用了同樣的編碼器-解碼器框架來生成開放域的有趣回復。使用 LSTM 解碼器處理額外信號從而獲取某種效果現在是一種普遍做法了。《A Persona-Based Neural Conversation Model》提出用解碼器處理恒定人物向量(constant persona vector),該向量捕捉單個說話人的個人信息。在上述案例中,語言生成主要基于表示文本輸入的語義向量。類似的框架還可用于基于圖像的語言生成,使用視覺特征作為 LSTM 解碼器的初始狀態(圖 12)。
視覺 QA 是另一種任務,需要基于文本和視覺線索生成語言。2015 年的論文《Ask Your Neurons: A Neural-based Approach to Answering Questions about Images》是首個提供端到端深度學習解決方案的研究,他們使用 CNN 建模輸入圖像、LSTM 建模文本,從而預測答案(一組單詞)。
圖 12:結合 LSTM 解碼器和 CNN 圖像嵌入器,生成圖像字幕(圖源:https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Vinyals_Show_and_Tell_2015_CVPR_paper.pdf)
《Ask Me Anything: Dynamic Memory Networks for Natural Language Processing》提出動態記憶網絡(dynamic memory network,DMN)來解決這個問題。其思路是重復關注輸入文本和圖像,以使每次迭代中的信息都得到改善。注意力網絡用于關注輸入文本詞組。
圖 13:神經圖像 QA(圖源:https://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Malinowski_Ask_Your_Neurons_ICCV_2015_paper.pdf)
注意力機制
傳統編碼器-解碼器框架的一個潛在問題是:有時編碼器會強制編碼可能與目前任務不完全相關的信息。這個問題在輸入過長或信息量過大時也會出現,選擇性編碼是不可能的。
例如,文本摘要任務可以被視為序列到序列的學習問題,其中輸入是原始文本,輸出是壓縮文本。直觀上看,讓固定大小向量編碼長文本中的全部信息是不切實際的。類似的問題在機器翻譯任務中也有出現。
在文本摘要和機器翻譯等任務中,輸入文本和輸出文本之間存在某種對齊,這意味著每個 token 生成步都與輸入文本的某個部分高度相關。這啟發了注意力機制。該機制嘗試通過讓解碼器回溯到輸入序列來緩解上述問題。具體在解碼過程中,除了最后的隱藏狀態和生成 token 以外,解碼器還需要處理基于輸入隱藏狀態序列計算出的語境向量。
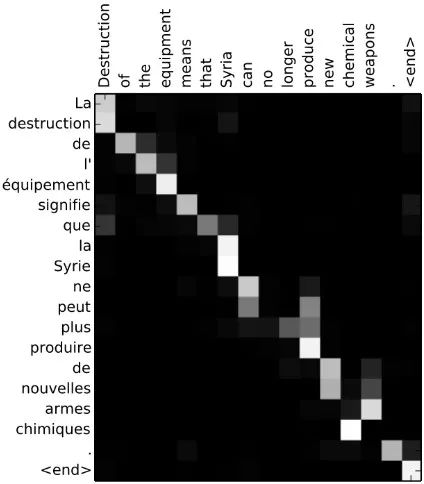
《Neural Machine Translation by Jointly Learning to Align and Translate》首次將注意力機制應用到機器翻譯任務,尤其改進了在長序列上的性能。該論文中,關注輸入隱藏狀態序列的注意力信號由解碼器最后的隱藏狀態的多層感知機決定。通過在每個解碼步中可視化輸入序列的注意力信號,可以獲得源語言和目標語言之間的清晰對齊(圖 14)。
圖 14:詞對齊矩陣(圖源:https://arxiv.org/abs/1409.0473)
類似的方法也被應用到摘要任務中,《A Neural Attention Model for Abstractive Sentence Summarization》用注意力機制處理輸入句子從而得到摘要中的每個輸出單詞。作者執行 abstractive summarization,它與 extractive summarization 不同,但可以擴展到具備最小語言輸入的大型數據。
在圖像字幕生成任務中,《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》用 LSTM 解碼器在每個解碼步中處理輸入圖像的不同部分。注意力信號由之前的隱藏狀態和 CNN 特征決定。《Grammar as a Foreign Language》將解析樹線性化,從而將句法解析問題作為序列到序列學習任務。該研究證明注意力機制更加數據高效。指回輸入序列的進一步步驟是:在特定條件下,直接將輸入中的單詞或子序列復制到輸出序列,這在對話生成和文本摘要等任務中也有用。解碼過程中的每個時間步可以選擇復制還是生成。
在基于 aspect 的情感分析中,《Attention-based LSTM for Aspect-level Sentiment Classification》提出基于注意力的解決方案,使用 aspect 嵌入為分類提供額外支持(圖 15)。注意力模塊選擇性關注句子的某些區域,這會影響 aspect 的分類。圖 16 中,對于 a 中的 aspect「service」,注意力模塊動態聚焦詞組「fastest delivery times」,b 中對于 aspect「food」,注意力在整個句子中識別了多個關鍵點,包括「tasteless」和「too sweet」。近期,《Targeted Aspect-Based Sentiment Analysis via Embedding Commonsense Knowledge into an Attentive LSTM》用層級注意力機制(包含目標級注意力和句子級注意力)增強 LSTM,利用常識處理基于目標 aspect 的情感分析。
圖 15:使用注意力機制進行 aspect 分類(圖源:https://aclanthology.coli.uni-saarland.de/papers/D16-1058/d16-1058)
圖 16:對于特定 aspect,注意力模塊對句子的關注點(圖源:https://aclanthology.coli.uni-saarland.de/papers/D16-1058/d16-1058)
另一方面,《Aspect Level Sentiment Classification with Deep Memory Network》采用基于記憶網絡(也叫 MemNet)的解決方案,使用多跳注意力(multiple-hop attention)。記憶網絡上的多個注意力計算層可以改善對記憶中大部分信息區域的查找,從而有助于分類。這一研究目前仍是該領域的當前最優結果。
由于注意力模塊應用的直觀性,NLP 研究者和開發者在越來越多的應用中積極使用注意力模塊。
并行化注意力:Transformer
CNN 和 RNN 在包括編碼器-解碼器架構在內的序列傳導應用中非常關鍵。注意力機制可以進一步提升這些模型的性能。但是,這些架構面臨的一個瓶頸是編碼步中的序列處理。為了解決該問題,《Attention Is All You Need》提出了 Transformer,它完全去除了編碼步中的循環和卷積,僅依賴注意力機制來捕捉輸入和輸出之間的全局關系。因此,整個架構更加并行化,在翻譯、解析等任務上訓練得到積極結果所需的時間也更少。
圖 17:multi-head 注意力(圖源:https://arxiv.org/abs/1706.03762)
Transformer 的編碼器和解碼器部分都有一些堆疊層。每個層有兩個由 multi-head 注意力層組成的子層(圖 17),之后是 position-wise 前饋網絡。對于查詢集 Q、關鍵 K 和值 V,multi-head 注意力模塊執行注意力 h 次,計算公式如下:
此處,W_i^{[.]} 和 W^o 是投影參數。該模型融合了殘差連接、層歸一化、dropout、位置編碼等技術,在英語-德語、英語-法語翻譯和 constituency parsing 中獲得了當前最優結果。
第八章:不同模型在不同 NLP 任務上的表現
在下面表 2 到表 7 中,我們總結了一系列深度學習方法在標準數據集上的表現,這些數據集都是近年來最流行的探究主題。我們的目標是向讀者展示深度學習社區常用的數據集以及不同模型在這些數據集上的當前最佳結果。
詞性標注
WSJ-PTB(the Wall Street Journal part of the Penn Treebank Dataset)語料庫包含 117 萬個 token,已被廣泛用于開發和評估詞性標注系統。Giménez 和 arquez(2004)在 7 個單詞窗口內采用了基于人工特征的一對多 SVM,其中有些基本的 n-gram 模式被評估用來構成二元特征,如:「前一個單詞是 the」,「前兩個標簽是 DT NN」等。詞性標注問題的一大特征是相鄰標簽之間的強依賴性。通過簡單的從左到右標注方案,該方法僅通過特征工程建模相鄰標簽之間的依賴性。
為了減少特征工程,Collobert 等人(2011)通過多層感知機僅依賴于單詞窗口中的詞嵌入。Santos 和 Zadrozny(2014)將詞嵌入和字符嵌入連接起來,以便更好地利用形態線索。在論文《Learning Character-level Representations for Part-of-Speech Tagging》中,他們沒有考慮 CRF,但由于單詞級的決策是在上下文窗口上做出的,可以看到依賴性被隱式地建模。Huang 等人(2015)把單詞嵌入和手動設計的單詞級特征連接起來,并采用雙向 LSTM 來建模任意長度的上下文。
一系列消融分析(ablative analysis)表明,雙向 LSTM 和 CRF 都提升了性能。Andor 等人(2016)展示了一種基于轉換(transition-based)的方法,該方法通過簡單的前饋神經網絡上產生了具有競爭性的結果。當應用于序列標注任務時,DMN(Kumar et al., 2015)允許通過把每個 RNN 的隱藏狀態視為記憶實體來多次關注上下文,且每次都關注于上下文的不同部分。
表 2:詞性標注
句法分析
有兩種句法分析:依存句法分析(dependency parsing)和成分句法分析(constituency parsing)。前者將單個單詞及其關系聯系起來,后者依次將文本拆分成子短語(sub-phrase)。基于轉換的方法是很多人的選擇,因為它們在句子長度上是線性的。解析器(parser)會做出一系列決定:根據緩沖器(buffer)順序讀取單詞,然后逐漸將它們組合到句法結構中(Chen and Manning, 2014)。
在每個時間步,決策是基于包含可用樹節點的堆棧、包含未讀單詞的緩沖器和獲得的依存關系集來確定的。Chen and Manning 利用帶有一個隱藏層的神經網絡來建模每個時間步做出的決定。輸入層包含特定單詞、詞性標注和弧標簽的嵌入向量,這些分別來自堆棧、緩沖器和依存關系集。
Tu 等人(2015)擴展了 Chen and Manning 的工作,他們用了帶有兩個隱藏層的深度模型。但是,不管是 Tu 等人還是 Chen 和 Manning,他們都依賴于從解析器狀態中選擇手動特征,而且他們只考慮了少數最后的幾個 token。Dyer 等人(2015)提出堆棧-LSTMs 來建模任意長度的 token 序列。當我們對樹節點的堆棧進行 push 或 pop 時,堆棧的結束指針(end pointer)會改變位置。Zhou 等人(2017)整合集束搜索和對比學習,以實現更好的優化。
基于變換的模型也被應用于成分句法分析。Zhu 等人(2013)基于堆棧和緩沖器頂部幾個單詞的特征(如詞性標簽、成分標簽)來進行每個轉換動作。通過用線性標簽序列表示解析樹,Vinyals 等人(2015)將 seq2seq 學習方法應用于該問題。
表 3.1:依存句法分析(UAS/LAS=未標記/標記的 Attachment 分數;WSJ=The Wall Street Journal Section of Penn Treebank)
表 3.2:成分句法分析
命名實體識別
CoNLL 2003 是用于命名實體識別(NER)的標準英語數據集,其中主要包含四種命名實體:人、地點、組織和其它實體。NER 屬于自然語言處理問題,其中詞典非常有用。Collobert 等人(2011)首次通過用地名索引特征增強的神經架構實現了具有競爭性的結果。Chiu and Nichols(2015)將詞典特征、字符嵌入和單詞嵌入串聯起來,然后將其作為雙向 LSTM 的輸入。
另一方面,Lample 等人(2016)僅靠字符和單詞嵌入,通過在大型無監督語料庫上進行預訓練嵌入實現了具有競爭性的結果。與 POS 標簽類似,CRF 也提升了 NER 的性能,這一點在 Lample 等人(2016)的《Neural Architectures for Named Entity Recognition》中得到了證實。總體來說,帶有 CRF 的雙向 LSTM 對于結構化預測是一個強有力的模型。
Passos 等人(2014)提出經修正的 skip-gram 模型,以更好地學習與實體類型相關的詞嵌入,此類詞嵌入可以利用來自相關詞典的信息。Luo 等人(2015)聯合優化了實體以及實體和知識庫的連接。Strubell 等人(2017)提出用空洞卷積,他們希望通過跳過某些輸入來定義更寬的有效輸入,因此實現更好的并行化和上下文建模。該模型在保持準確率的同時展示出了顯著的加速。
表 4:命名實體識別
語義角色標注
語義角色標注(SRL)旨在發現句子中每個謂詞的謂詞-論元(predicate-argument)結構。至于每個目標動詞(謂語),句子中充當動詞語義角色的所有成分都會被識別出來。典型的語義論元包括施事者、受事者、工具等,以及地點、時間、方式、原因等修飾語 (Zhou and Xu, 2015)。表 5 展示了不同模型在 CoNLL 2005 & 2012 數據集上的性能。
傳統 SRL 系統包含幾個階段:生成解析樹,識別出哪些解析樹節點代表給定動詞的論元,最后給這些節點分類以確定對應的 SRL 標簽。每個分類過程通常需要抽取大量特征,并將其輸入至統計模型中(Collobert et al., 2011)。
給定一個謂詞,T?ckstr?m 等人(2015)基于解析樹,通過一系列特征對該謂詞的組成范圍以及該范圍與該謂詞的可能關系進行打分。他們提出了一個動態規劃算法進行有效推斷。Collobert 等人(2011)通過解析以附加查找表形式提供的信息,并用卷積神經網絡實現了類似的結果。Zhou 和 Xu(2015)提出用雙向 LSTM 來建模任意長度的上下文,結果發現不使用任何解析樹的信息也是成功的。
表 5:語義角色標注
情感分類
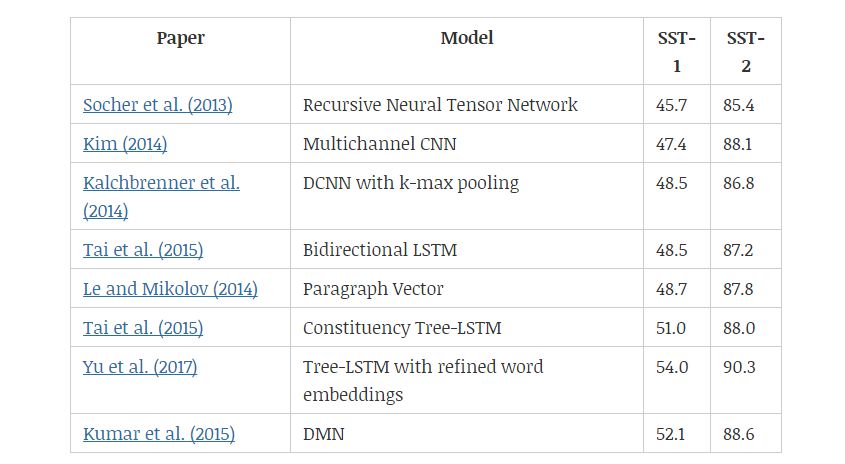
SST 數據集(Stanford Sentiment Treebank)包含從電影評論網 Rotten Tomatoe 上收集的句子。它由 Pang 和 Lee(2005)提出,后來被 Socher 等人(2013)進一步拓展。該數據集的標注方案啟發了一個新的情感分析數據集——CMU-MOSI,其中模型需要在多模態環境中研究情感傾向。
Socher 等人(2013)和 Tai 等人(2015)都是通過成分解析樹及遞歸神經網絡來改善語義表征。另一方面,樹形 LSTM(tree-LSTM)比線性雙向 LSTM 表現更好,說明樹結構能夠更好地捕捉自然句子的句法特性。Yu 等人(2017)提出用情感詞匯微調預訓練的詞嵌入,然后基于 Tai 等人(2015)的研究觀察改進結果。
Kim(2014)和 l Kalchbrenner 等人(2014)都使用卷積層。Kim 等人提出的模型與圖 5 中的相似,而 Kalchbrenner 等人通過將 k-max 池化層和卷積層交替使用,以分層方式構建模型。
表 6:不同情感分類模型在 SST-1 和 SST-2 數據集上的效果。
機器翻譯
基于短語的 SMT 框架(Koehn et al., 2003)將翻譯模型分解為原語短語和目標語短語之間的概率匹配問題。Cho et al. (2014) 進一步提出用 RNN 編碼器-解碼器框架學習原語與目標語的匹配概率。而基于循環神經網絡的編碼器-解碼器架構,再加上注意力機制在一段時間內成為了業內最標準的架構。Gehring et al. (2017) 提出了基于 CNN 的 Seq2Seq 模型,CNN 以并行的方式利用注意力機制計算每一個詞的表征,解碼器再根據這些表征確定目標語序列。Vaswani et al. (2017) 隨后提出了完全基于注意力機制的 Transformer,它目前已經是神經機器翻譯最常見的架構了。
表 7:不同機器翻譯模型和 BLEU 值。
問答系統
QA 問題有多種形式,有的研究者根據大型知識庫來回答開放性問題,也有的研究者根據模型對句子或段落的理解回答問題。對于基于知識庫的問答系統,學習回答單關系查詢的核心是數據庫中找到支持的事實。
表 8:不同模型在不同問答數據集上的效果。
上下文嵌入
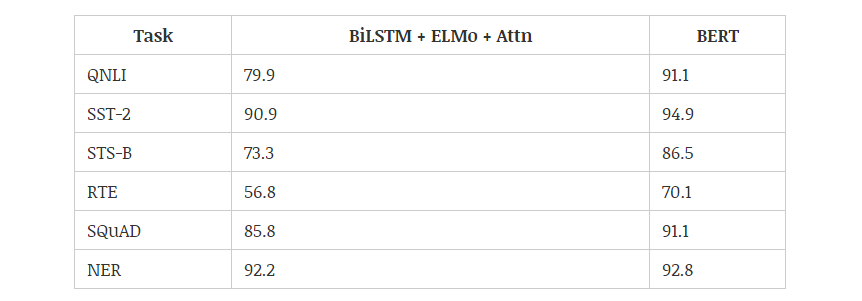
2018 年,使用預訓練的語言模型可能是 NLP 領域最顯著的趨勢,它可以利用從無監督文本中學習到的「語言知識」,并遷移到各種 NLP 任務中。這些預訓練模型有很多,包括 ELMo、ULMFiT、OpenAI Transformer 和 BERT,其中又以 BERT 最具代表性,它在 11 項 NLP 任務中都獲得當時最佳的性能。不過目前有 9 項任務都被微軟的新模型超過。下圖展示了不同模型在 12 種 NLP 任務中的效果:
小編曾解讀過 BERT 的的核心過程,它會先從數據集抽取兩個句子,其中第二句是第一句的下一句的概率是 50%,這樣就能學習句子之間的關系。其次隨機去除兩個句子中的一些詞,并要求模型預測這些詞是什么,這樣就能學習句子內部的關系。最后再將經過處理的句子傳入大型 Transformer 模型,并通過兩個損失函數同時學習上面兩個目標就能完成訓練。
如上所示為不同預訓練模型的架構,BERT 可以視為結合了 OpenAI GPT 和 ELMo 優勢的新模型。其中 ELMo 使用兩條獨立訓練的 LSTM 獲取雙向信息,而 OpenAI GPT 使用新型的 Transformer 和經典語言模型只能獲取單向信息。
BERT 的主要目標是在 OpenAI GPT 的基礎上對預訓練任務做一些改進,以同時利用 Transformer 深度模型與雙向信息的優勢。這種「雙向」的來源在于 BERT 與傳統語言模型不同,它不是在給定所有前面詞的條件下預測最可能的當前詞,而是隨機遮掩一些詞,并利用所有沒被遮掩的詞進行預測。








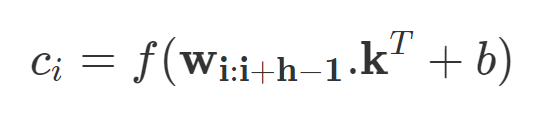







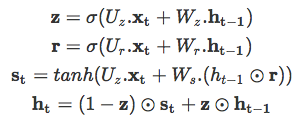
















-
深度學習
+關注
關注
73文章
5500瀏覽量
121111 -
nlp
+關注
關注
1文章
488瀏覽量
22033
原文標題:萬字長文概述NLP中的深度學習技術
文章出處:【微信號:aicapital,微信公眾號:全球人工智能】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
2017全國深度學習技術應用大會
基于深度學習的異常檢測的研究方法
基于深度學習的異常檢測的研究方法
專欄 | 深度學習在NLP中的運用?從分詞、詞性到機器翻譯、對話系統
從語言學到深度學習NLP,一文概述自然語言處理
對2017年NLP領域中深度學習技術應用的總結
NLP的介紹和如何利用機器學習進行NLP以及三種NLP技術的詳細介紹






 工商網監
工商網監
評論