 GPipe是什么,效果如何?為什么要對跨加速器的模型進行分區?
GPipe是什么,效果如何?為什么要對跨加速器的模型進行分區?
加速DNN模型訓練速度方法中,數據并行受到單個加速器可支持模型大小的限制;而模型并行因為DNN順序性導致大量算力浪費。目前Google推出GPipe,將兩種方法的優勢進行結合,解決了兩者的劣勢,成功提升訓練速度。
深度神經網絡(DNN)已經推動了許多機器學習任務,比如語音識別,視覺識別和語言處理。
BigGan、Bert和GPT2.0的最新進展表明,越大的DNN模型,越能帶來更好的性能。
而視覺識別任務的過去進展也表明,模型大小和分類準確性之間,存在很強的相關性。
例如2014年ImageNet視覺識別挑戰賽中,獲勝者GoogleNet使用400萬參數,精確度達到了74.8%。
而2017年ImageNet挑戰賽的獲勝者Squeeze-and-Excitation Networks,使用1.5億參數,精確度達到了82.7%。
僅僅3年,數據處理能力翻了36番。而在同一時期,GPU內存僅增加了約3倍。
當前最先進的圖像模型,已經達到了云TPUv2內存的可用上限。因此,迫切需要一種更高效、可擴展的基礎設施,以實現大規模深度學習,并克服當前加速器的內存限制。
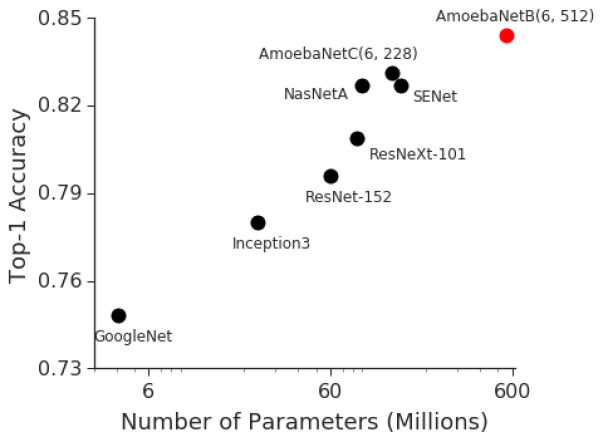
ImageNet精度和模型大小之間的強相關性
基于以上目的,Google推出了GPipe。
GPipe是什么,效果如何?
GPipe是一個分布式機器學習、可擴展的管道并行庫,可以學習巨型深度神經網絡。
使用同步隨機梯度下降和管道并行性進行訓練,適用于由多個連續層組成的任何DNN。
GPipe允許研究人員輕松部署更多加速器來訓練更大的模型,并在不調整超參數的情況下,達到提升性能的效果。
GPipe將跨加速器和管道執行的網絡層進行分區,以便實現對硬件更高的利用率,同時利用重新計算來將激活的內存使用降至最低。
例如,使用8個加速器的分區,GPipe就可以訓練25倍大神經網絡。
而GPipe也幾乎實現了線性加速。使用4倍數量的加速器,處理同一個模型的速度提升了3.5倍;16倍加速器速度提升11倍。
同時它也要保證計算的梯度和分區的數量保持一致,從而在不對模型的參數做任何改動的前提下,都能保持線性加速。
目前,核心GPipe庫已在Lingvo框架下開源。
為什么要對跨加速器的模型進行分區?
有兩種標準方法可以加速DNN模型:
數據并行方法,使用更多的機器并將輸入數據分開
模型并行性。將模型移動到如GPU或TPU等具有加速模型訓練的特殊硬件
然而加速器的內存、與主機的通信帶寬均有限。因此模型并行性就需要將模型進行分割,將不同的分區分配給不通過的加速器。
可是由于由于DNN的順序性,這種樸素的策略可能導致在計算期間,只有一個加速器處于激活狀態,導致大量算力的浪費。
而標準數據并行方法是允許在多個加速器上,同時訓練不同輸入數據的相同模型,但每個加速器可支持模型大小又有限制。
GPipe的做法是將模型分割,并劃分給不同的加速器,自動將小Batch拆分為更小的微Batch,這樣就實現了跨多個加速器的高效訓練。
此外,因為梯度一直在微批次中累積,所以分區數量不會影響模型質量。
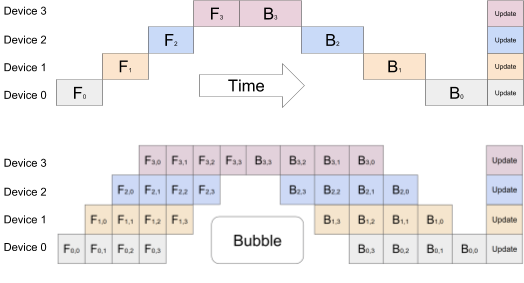
Time部分:由于網絡的連續性,幼稚模型并行策略導致嚴重的未充分利用。 一次只有一個加速器處于活動狀態
Bubble部分:GPipe將輸入小批量分成較小的微批次,使不同的加速器可以同時在單獨的微批次上工作
使用GPipe和不使用,之間的差異有多大?
一個TPUv2有8個加速器核心和64GB內存(每個加速器8GB),由于內存限制,單個加速器可以訓練的參數量上限是8200萬。
借助反向傳播和批量分割中的重新計算,GPipe將中間激活內存從6.26GB減少到3.46GB,將單個加速器參數處理上限提升至3.18億個。
我們還看到,通過管道并行性,最大模型大小與分區數成正比,如預期的那樣。
通過GPipe,AmoebaNet能夠在云TPUv2的8個加速器上加入18億個參數,比沒有GPipe的情況下多25倍。
Google測量了GPipe對AmoebaNet-D模型吞吐量的影響。效率和加速器的數量幾乎是呈線性加速,8個加速器+8個分區,比2個加速器+2個分區快2.5倍。
TPUv3效果更好。在1024個令牌句子上啟用了80億個參數Transformer語言模型,16個加速器將速度提升了11倍
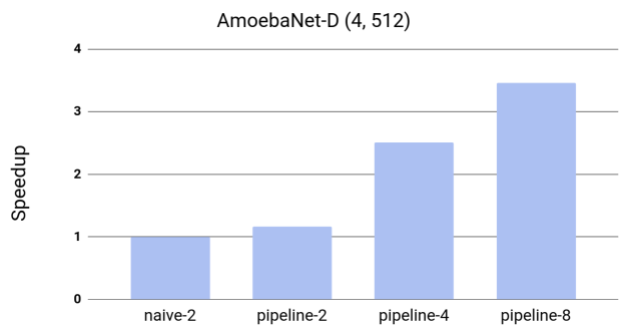
使用GPipe加速AmoebaNet-D,這種模型不適合一個加速器
基線naive-2是將模型拆分為兩個分區時本機分區方法的性能
Pipeline-k指的是GPipe的性能,它將模型分成帶有k個加速器的k個分區
GPipe還可以通過使用更多加速器來擴展訓練,而無需更改超參數。因此,它可以與數據并行性相結合,以互補的方式使用更多的加速器來擴展神經網絡訓練。
GPipe精確度能達到多少?
前面我們提到,處理的數據量越大,獲得的精度就越高。
Google在ImageNet ILSVRC-2012數據集上,使用Cloud TPUv2訓練了一個有5.57億參數、480 x 480輸入圖像尺寸的AmoebaNet-B模型。
該網絡被分成4個分區,這個巨型模型在多個流行數據集上表現良好,在沒有任何外部數據的情況下,精度達到了最先進的84.3% top-1,以及97% top-5的single-crop驗證準確度。
大型神經網絡不僅適用于ImageNet等數據集,還通過遷移學習,與其他數據集息息相關。
目前我們已知ImageNet模型越好,遷移就越好。Google在CIFAR10和CIFAR100數據集上進行了遷移學習實驗,將最佳公布的CIFAR-10精度提高到99%,將CIFAR-100精度提高到91.3%。
哪里能獲取到GPipe?
Github:
https://github.com/tensorflow/lingvo/blob/master/lingvo/core/gpipe.py
-
加速器
+關注
關注
2文章
804瀏覽量
37983 -
神經網絡
+關注
關注
42文章
4777瀏覽量
100974 -
機器學習
+關注
關注
66文章
8430瀏覽量
132858
原文標題:谷歌開源效率怪獸GPipe,速度提升25倍,CIFAR-10精度達到99%
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
英偉達AI加速器新藍圖:集成硅光子I/O,3D垂直堆疊 DRAM 內存

IBM將在云平臺部署AMD加速器
IBM與AMD攜手將在IBM云上部署AMD Instinct MI300X加速器
具有邊沿速率加速器的TXB和TXS電壓電平轉換器的注意事項

什么是神經網絡加速器?它有哪些特點?
Hailo獲1.2億美元新融資,首發AI加速器Hailo-10,助力邊緣設備實現生成式人工智能
Hitek Systems開發基于PCIe的高性能加速器以滿足行業需求






 工商網監
工商網監
評論