


本次直播課程是由深度學(xué)習(xí)資深研究者-楊陽博士從百度Apollo自動(dòng)駕駛感知技術(shù)出發(fā),講解環(huán)境感知中深度學(xué)習(xí)的實(shí)用性與高效性。
課程從Apollo 3.5感知技術(shù)介紹、自動(dòng)駕駛中的目標(biāo)檢測與識(shí)別、深度學(xué)習(xí)在目標(biāo)檢測中的意義、Apollo中深度學(xué)習(xí)的應(yīng)用、百度深度學(xué)習(xí)框架對目標(biāo)檢測的實(shí)操五個(gè)方面著手,全面解讀深度學(xué)習(xí)在目標(biāo)檢測中的運(yùn)用。
以下是楊陽博士分享的全部內(nèi)容,希望給各位開發(fā)者帶來更多的幫助。

首先,本次課程將以百度Apollo自動(dòng)駕駛技術(shù)為出發(fā)點(diǎn),詳解百度深度學(xué)習(xí)技術(shù)在Apollo自動(dòng)駕駛目標(biāo)檢測中的應(yīng)用。其次,基于百度深度學(xué)習(xí)框架對目標(biāo)檢測技術(shù)進(jìn)一步探討,最后理論聯(lián)系實(shí)際,通過一個(gè)典型案例體驗(yàn)百度深度學(xué)習(xí)在環(huán)境感知中的實(shí)用性與高效性。
簡要了解一下自動(dòng)駕駛
首先我們可以從安全駕駛角度來簡單了解自動(dòng)駕駛的重要性。為什么我們需要自動(dòng)駕駛?這里羅列了一些自動(dòng)駕駛的優(yōu)勢,除了減少交通事故、節(jié)省燃料外,還涉及到獲得更多自主休息的時(shí)間。此外,自動(dòng)駕駛技術(shù)還有很多其它優(yōu)點(diǎn),例如可以輕輕松松停車,讓老人開車相對更安全一些。

表中給出了全球?qū)τ谧詣?dòng)駕駛技術(shù)的評級,包括從純粹的人工駕駛L0級到高度的自動(dòng)駕駛L4級。不過目前各國重點(diǎn)研發(fā)的還是有條件的自動(dòng)駕駛,例如L3級的自動(dòng)駕駛以及高度的自動(dòng)駕駛L4級,完全的自動(dòng)駕駛(L5級)目前還沒有辦法預(yù)測。
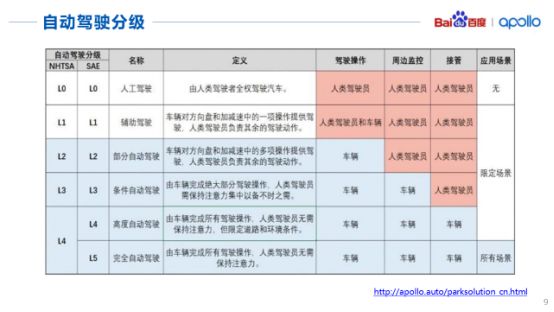
其中一些企業(yè)推出了有條件的自動(dòng)駕駛,還有一些停留在部分自動(dòng)駕駛L2級和輔助自動(dòng)駕駛L1級的測試階段,暫未投入到商用。
不過值得高興的一點(diǎn),百度今年剛剛推出了L4級的自動(dòng)駕駛車輛以及相關(guān)解決方案,相信未來在L5級的自動(dòng)駕駛領(lǐng)域,我們國家一定會(huì)有所突破,實(shí)現(xiàn)L5級自動(dòng)駕駛指日可待。
接下來我們探究自動(dòng)駕駛車輛的基本組成,以百度Apollo3.5的無人駕駛車輛為例,明確整個(gè)自動(dòng)駕駛車輛包括哪些部分。首先,車輛頂端應(yīng)配置360度的3D掃描雷達(dá),以及前排陣列攝像頭、后排攝像頭陣列,同時(shí)還包含GPS天線、前置雷達(dá)等。這些都是用來對周圍環(huán)境進(jìn)行感知的。
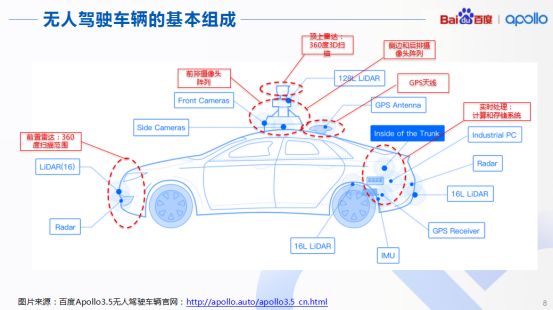
感知結(jié)果得到實(shí)時(shí)處理后,就會(huì)產(chǎn)生大量數(shù)據(jù),從而匯總到車后端的實(shí)時(shí)處理系統(tǒng)中,也就是計(jì)算和存儲(chǔ)系統(tǒng),隨后做到汽車在行進(jìn)過程中對車輛周圍環(huán)境的完全感知。如今的Apollo3.5,傳感器部分以及計(jì)算存儲(chǔ)系統(tǒng)還是相當(dāng)完善的。從Apollo完整框架分析,我們可以看到上端是云端服務(wù),下端三層屬于車端服務(wù)。
全新的Apollo3.5技術(shù)框架對其中14個(gè)模塊進(jìn)行了升級,主要分布在硬件系統(tǒng)以及軟件系統(tǒng)中。例如,3.5版本感知算法加上全新的傳感器升級,可以達(dá)到360度無死角的全面覆蓋。

云端服務(wù)方面,涉及例如高精度地圖、仿真數(shù)據(jù)平臺(tái)、安全模塊等。全新的基于多場景的決策和預(yù)測架構(gòu),使開發(fā)變得更加靈活與友好,所以一些開發(fā)者完全可以選擇這種軟件平臺(tái)和硬件平臺(tái)來進(jìn)行相應(yīng)開發(fā),同時(shí)我們也將90%仿真驅(qū)動(dòng)開放,大力提升開發(fā)者們的效率以及研發(fā)安全性。
Apollo對于自動(dòng)駕駛具備至關(guān)重要的四個(gè)部分,我們也給予相應(yīng)升級,包括規(guī)劃、預(yù)測、感知以及定位。
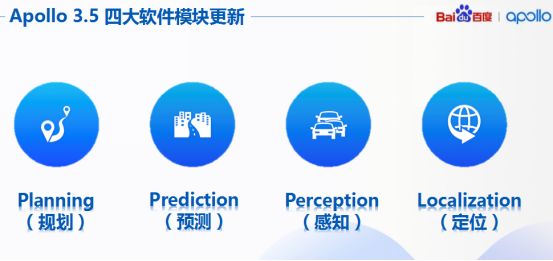
如今Apollo3.5在感知能力上也得到了升級,可以做到通過增加盲區(qū)檢測傳感器以及雷達(dá)等方式,例如用于盲區(qū)檢測的傳感器套件以及新的128線的激光雷達(dá)拓展檢測范圍,同時(shí)包含3D定位算法以及目標(biāo)檢測算法,表現(xiàn)更強(qiáng)大。

自動(dòng)駕駛中的目標(biāo)檢測與識(shí)別
所謂目標(biāo)檢測,就是區(qū)分圖像或者視頻中的目標(biāo)與其他不感興趣的部分,例如圖中的建筑物、樹林、盒子以及瓶子等,其實(shí)這些物體同畫面產(chǎn)生了一些明顯區(qū)分,那么如何讓計(jì)算機(jī)像人類一樣做到明確區(qū)分呢?這就涉及目標(biāo)檢測,可以說讓計(jì)算機(jī)能夠區(qū)分出這些,是目標(biāo)檢測的第一步。
目標(biāo)檢測的第二步是什么?是讓計(jì)算機(jī)識(shí)別剛才區(qū)分出來的畫面究竟是什么,從而確定視頻或圖像中目標(biāo)的種類。例如為了實(shí)現(xiàn)自動(dòng)駕駛的目標(biāo),最初需要讓計(jì)算機(jī)認(rèn)識(shí)交通目標(biāo),才能讓其成為真正的AI老司機(jī)。

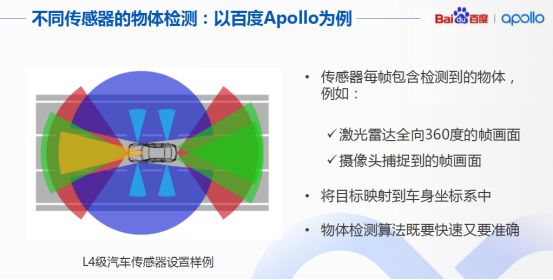
如何建立一個(gè)高準(zhǔn)確率、高召回率的物體識(shí)別系統(tǒng)?這實(shí)際是無人車感知的一個(gè)核心問題,而物體檢測更是重中之重,要求我們對不同傳感器設(shè)計(jì)不同的算法來準(zhǔn)確檢測障礙物。例如Apollo技術(shù)框架中為3D設(shè)計(jì)了CNSEG(音譯)深度學(xué)習(xí)算法,還包括為二級圖像設(shè)計(jì)的YOLO3D深度學(xué)習(xí)算法等。
具體說到物體檢測,我們要求完成單幀障礙物的檢測,并借助傳感器內(nèi)外參數(shù)標(biāo)定轉(zhuǎn)換矩陣,將檢測結(jié)果統(tǒng)一影射到車身的座標(biāo)系中,這種物體檢測算法既快速又準(zhǔn)確。
引入深度學(xué)習(xí)究竟為何般?
有些小伙伴可能產(chǎn)生疑問,描述了這么多種方法,為什么一定要使用深度學(xué)習(xí)呢?或許將深度學(xué)習(xí)與傳統(tǒng)圖像處理PK下,就能明了其中緣由。
業(yè)界共知,傳統(tǒng)的目標(biāo)檢測與識(shí)別算法分為三部分,包含目標(biāo)特征提取、目標(biāo)識(shí)別以及目標(biāo)定位,其中涉及的典型算法就是基于組件檢測的DPM算法。
實(shí)際上DPM算法就是訓(xùn)練出物體的梯度模型,然后對實(shí)際物體進(jìn)行套用。但很顯然,人為提取出來模型種類還是有限的,面對現(xiàn)實(shí)中紛繁多變的大千世界,即便是后來人為成功提取了更多特征因素,也很難做到對圖像中全部細(xì)節(jié)進(jìn)行詳細(xì)描述,因此類似DPM算法。
由于傳統(tǒng)目標(biāo)檢測算法主要基于人為特征提取,對于更復(fù)雜或者更高階的圖像特征很難進(jìn)行有效描述,所以限制了目標(biāo)檢測的識(shí)別效果,這一點(diǎn)可以被認(rèn)定是人為特征提取導(dǎo)致傳統(tǒng)算法的性能瓶頸。

同傳統(tǒng)的圖像處理方法不同,采用深度學(xué)習(xí)的方法進(jìn)行圖像處理,最大的區(qū)別就是特征圖不再通過人工特征提取,而是利用計(jì)算機(jī),這樣提取出來的特征會(huì)非常豐富,也很全面。
所謂的深度學(xué)習(xí)就是通過集聯(lián)多層的神經(jīng)網(wǎng)絡(luò)形成一個(gè)很深的層,當(dāng)層數(shù)越多,提取出來的特征也就越多而且越豐富。所以在目標(biāo)檢測和識(shí)別的過程中,最主要使用的深度學(xué)習(xí)特征提取模型就是深度卷積網(wǎng)絡(luò),英文簡稱CNN。
為什么CNN圖像處理的方式比以前更好呢?究其原因,根本還是在于對圖像特征提取。例如,當(dāng)我們使用多層進(jìn)行特征提取的時(shí)候,其實(shí)有些層是針對圖像的邊緣輪廓來提取的,有些則是針對質(zhì)地或者紋理來進(jìn)行的,還有些是針對物體特征進(jìn)行操作,總而言之不同的層有不同的分割方式。
回歸到目標(biāo)檢測這個(gè)問題上,卷積神經(jīng)網(wǎng)絡(luò)的每一層如果能夠準(zhǔn)確提取出所需特征,最后也就容易判斷許多。因此決定CNN的目標(biāo)檢測和識(shí)別的關(guān)鍵就在于對每一層如何設(shè)計(jì)。
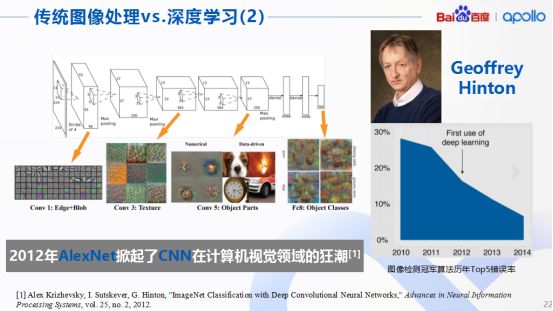
這可能就是八仙過海各顯神通的時(shí)刻了,不過不得不提及的是,一個(gè)著名的卷積神經(jīng)網(wǎng)絡(luò)AlexNet,這個(gè)網(wǎng)絡(luò)由多倫多大學(xué)的Hinton教授團(tuán)隊(duì)于2012年提出,一經(jīng)提出立馬轟動(dòng)了計(jì)算機(jī)的視覺領(lǐng)域,對其他相關(guān)行業(yè)后期也產(chǎn)生了深遠(yuǎn)的影響。
AlexNet在整個(gè)算法處理的步驟,其實(shí)與之前提到的一般CNN的處理方式?jīng)]有本質(zhì)區(qū)別,而且在國際上每年都會(huì)舉辦圖像檢測算法的比賽,AlexNet就在某屆圖像檢測比賽中獲得了冠軍。那一年AlexNet橫空出世,把當(dāng)年的top5錯(cuò)誤率硬生生降到了17%以下。
既然深度學(xué)習(xí)能夠在目標(biāo)檢測中大顯身手,那么針對當(dāng)前目標(biāo)檢測的方法又有哪些?簡單將當(dāng)前的方法進(jìn)行分類,其實(shí)可以歸納為三種算法方案:
第一種是對于候選區(qū)域的目標(biāo)檢測算法,典型的網(wǎng)絡(luò)是R-CNN和FasterR-CNN;第二個(gè)方案則是基于回歸的目標(biāo)檢測算法,典型實(shí)現(xiàn)是YOLO和SSD,最后一種是基于增強(qiáng)學(xué)習(xí)的目標(biāo)檢測算法,典型表現(xiàn)為深度Q學(xué)習(xí)網(wǎng)絡(luò),但這幾種算法其實(shí)各有各的優(yōu)缺點(diǎn)。
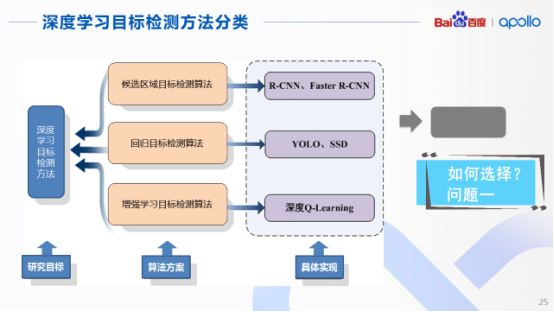
由于今天的話題是目標(biāo)檢測,自然就會(huì)想到在多種算法門派中如何進(jìn)行選擇的問題,以及在自動(dòng)駕駛領(lǐng)域中適合其研發(fā)的算法以及框架是什么。
深度學(xué)習(xí)框架呼之欲出
關(guān)于深度學(xué)習(xí)框架的選擇,大家可以嘗試用百度PaddlePaddle。就目前而言,市面上深度學(xué)習(xí)框架很多,包括Tensorflow、Caffe、PyTorch、MXNet等在內(nèi),而PaddlePaddle是眾多深度學(xué)習(xí)框架中唯一一款國內(nèi)自主研發(fā)的。
它支持分布式計(jì)算,即多GPU多臺(tái)機(jī)器并行計(jì)算,同時(shí)還支持FPGA,與其他一些僅支持GPU的框架不同,支持FPGA是PaddlePaddle的一個(gè)亮點(diǎn)。

有了解稱,F(xiàn)PGA特有的流水線結(jié)構(gòu)降低了數(shù)據(jù)同內(nèi)存的反復(fù)交互,從而大大降低了運(yùn)行功耗,這對于深度學(xué)習(xí)進(jìn)行大規(guī)模的推斷有諸多好處。如果能將這一特性擴(kuò)展到自動(dòng)駕駛領(lǐng)域,對于未來降低汽車的發(fā)熱問題顯然有很大幫助。而PaddlePaddle中的PaddleMobile框架以及API的方式支持移動(dòng)端設(shè)備,這樣就可以利用手機(jī)來完成想要的功能。
算法方案如何高效選擇?
先前提到的三種方案,首先來看候選區(qū)域目標(biāo)檢測算法。這類算法的典型案例是FasterR-CNN。工作的基本步驟可歸納為首先提取圖像中的候選區(qū)域,隨后針對這些候選區(qū)域進(jìn)行分類判斷,當(dāng)然由于這些候選區(qū)域是通過算法搜索出來的,所以并不一定準(zhǔn)確,因此還需要對選出的區(qū)域做位置回歸,隨之進(jìn)行目標(biāo)定位,最后輸出一個(gè)定位結(jié)果。總體來說,首先要先選擇、再判斷,最后剔除不想要的。
類似于找工作,選擇這種方法進(jìn)行圖像目標(biāo)檢測是可以做到精準(zhǔn)定位以及識(shí)別,所以精度較高,不過由于需要反復(fù)進(jìn)行候選區(qū)域的選擇,所以算法的效率被限制。

值得注意的一點(diǎn),F(xiàn)asterR-CNN引入了一種稱為區(qū)域生成網(wǎng)絡(luò)RPN(音譯)的概念,用來進(jìn)行算法加速。可以看到,RPN實(shí)際上是在分類和特征圖,也就是卷積層出來之后的特征圖之間,這樣就解決了端到端的問題。
同時(shí),我們可以利用GPU來進(jìn)行網(wǎng)絡(luò)加速,從而提升檢測的速率,這也是為什么FasterR-CNN和R-CNN相比多了一個(gè)Faster的原因。此外,候選區(qū)域檢測這類算法在VOC2007數(shù)據(jù)集上,也可以達(dá)到檢測精度為73.2%的準(zhǔn)確率。講到候選區(qū)域目標(biāo)檢測算法,實(shí)際上前面候選區(qū)域的目標(biāo)檢測算法主要是利用對于候選區(qū)域進(jìn)行目標(biāo)提取。
接下來介紹的第二個(gè)算法就是剛才提到的回歸目標(biāo)檢測算法,它的特點(diǎn)是SingleShot,也就是只需觀測一次圖片就能進(jìn)行目標(biāo)的檢測以及識(shí)別,因此算法的效率非常高。
在此羅列了一個(gè)稱之為SSD的典型回歸目標(biāo)檢測算法,這個(gè)算法分為四個(gè)步驟:第一步通過深度神經(jīng)網(wǎng)絡(luò)提取整個(gè)圖片的特征;第二步對于不同尺度的深度特征圖設(shè)計(jì)不同大小的特征抓取盒;第三步通過提取出這些抓去盒中的特征進(jìn)行目標(biāo)識(shí)別,最后,在識(shí)別出的這些結(jié)果中運(yùn)用非極大值抑制選擇最佳的目標(biāo)識(shí)別結(jié)果。

所以其實(shí)SSD算法核心思想與第一種算法類型類似,都是從深度神經(jīng)網(wǎng)絡(luò)的不同層提取特征,分別利用這些特征進(jìn)行回歸預(yù)測。當(dāng)然基于回歸的目標(biāo)檢測算法是不能同候選區(qū)域目標(biāo)檢測算法那樣特別精確的,尤其是對畫面中一些小目標(biāo),同樣給出SSD算法在VOC2007數(shù)據(jù)集上準(zhǔn)確度的數(shù)值,為68%。
雖然比候選區(qū)域目標(biāo)檢測算法低那么一丟丟,但是基本上性能沒有太大損失,此外,由于它是SingleShot,算法的效率也是相當(dāng)高的。
之前說到的兩種類型算法,對于圖中目標(biāo)的邊框、尺寸都是固定的,也就是說檢測算法中目標(biāo)邊框雖然數(shù)目特別多,但一旦邊框確定就無法改變,因此并不能適應(yīng)場景變化。所以為了檢測出不同目標(biāo)、不同場景,就需要準(zhǔn)備出多種區(qū)域選擇框。然而大千世界紛繁多變,檢測目標(biāo)在畫面中的大小更是差別巨大,如果能夠根據(jù)不同的情況在目標(biāo)候選區(qū)域進(jìn)行邊框調(diào)整,就可以做到適應(yīng)各種各樣的環(huán)境了。
回到第三種算法的介紹,也就是增強(qiáng)學(xué)習(xí)算法,可以說場景適應(yīng)性算是比較強(qiáng)的。增強(qiáng)學(xué)習(xí)算法目標(biāo)檢測可被看成不斷動(dòng)態(tài)調(diào)整候選區(qū)域邊框的過程,這種算法的典型代表是Q學(xué)習(xí)算法。

首先,通過圖像進(jìn)行特征提取,可以通過一個(gè)CNN網(wǎng)絡(luò)來完成,第二,主動(dòng)搜索,目的是根據(jù)不同的目標(biāo)和場景調(diào)整搜索的步長,并且結(jié)合歷史動(dòng)作反饋的信息,憑借深度Q學(xué)習(xí)網(wǎng)絡(luò)來預(yù)測下一步的動(dòng)作,也就是通過算法中設(shè)定一定的獎(jiǎng)勵(lì)機(jī)制來判斷這個(gè)特征提取邊框的大小變化以及上下左右移動(dòng)是否有效。當(dāng)網(wǎng)絡(luò)中預(yù)測下一步動(dòng)作完成后,再開始進(jìn)行識(shí)別并最后輸出結(jié)果。因此,這類算法的核心思想可以看成是由原來不可以改變大小的、靜態(tài)的特征抓取框,變成了現(xiàn)在可變的動(dòng)態(tài)抓取框,但這類算法目前在VOC2007數(shù)據(jù)集上準(zhǔn)確度的數(shù)值是46.1%,比較低。
原因主要是在進(jìn)行邊框調(diào)整過程中很容易造成特征抓取框和標(biāo)定的區(qū)域差距比較大,這樣會(huì)嚴(yán)重影響模型的訓(xùn)練效果,從而造成性能的下降;此外由于要進(jìn)行主動(dòng)搜索和多次邊框的調(diào)整,所以算法的計(jì)算也比較耗時(shí)。不過這種算法唯一的好處是相對靈活,俗稱百搭。
最后總結(jié)下,可以看到,從速度上回歸目標(biāo)檢測算法是最快的,原因在于只需看一次圖片就能夠“一見鐘情”;而從精度角度而言,后續(xù)區(qū)域目標(biāo)檢測算法已經(jīng)可以達(dá)到很高的精度水平了,然而回歸目標(biāo)檢測算法的能力也能夠做到和候選區(qū)域算法比較接近的程度。
以上我們介紹的都是典型的基本算法,最后從框架支持的角度來看,開發(fā)者很容易搭建候選區(qū)域檢測算法和回歸目標(biāo)檢測算法框架來實(shí)現(xiàn)。由于增強(qiáng)學(xué)習(xí)這種算法的動(dòng)態(tài)變化比較大,直接用框架來實(shí)現(xiàn)目前是有一定難度的,但如果大家對深度學(xué)習(xí)框架有所了解,其實(shí)目前已經(jīng)有可支持深度Q網(wǎng)絡(luò)的模型。

三種算法介紹完畢之后,究竟哪種算法最適合人們熟知的自動(dòng)駕駛場景呢?當(dāng)然是回歸目標(biāo)檢測算法。雖然在理論上候選區(qū)域目標(biāo)檢測算法能夠做到精確度特別高,但由于需要反復(fù)觀測畫面,所以大大降低了檢測速度,特別是在自動(dòng)駕駛領(lǐng)域中,需要進(jìn)行高速反應(yīng)來完成目標(biāo)識(shí)別,在這個(gè)層面并不適合。
百度Apollo中深度學(xué)習(xí)的應(yīng)用
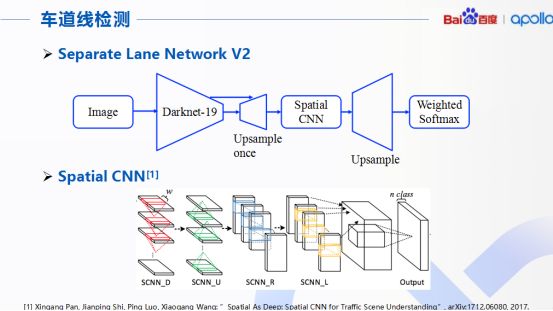
第一點(diǎn),關(guān)于車道線的檢測。目前百度Apollo采用了稱為分離車道線網(wǎng)絡(luò)的結(jié)構(gòu),圖像通過一個(gè)D9和一個(gè)空間卷積神經(jīng)網(wǎng)絡(luò)S-CNN完成對于道路上車道線的檢測和識(shí)別,整個(gè)網(wǎng)絡(luò)的核心是下面展示的S-CNN,網(wǎng)絡(luò)中用來增強(qiáng)對于行車時(shí)車道的檢測能力。S-CNN首先將特征圖的行和列分別看成多個(gè)層級的形式。
同時(shí)采用順序卷積,非線性激活函數(shù)以及求和操作形成一個(gè)深度神經(jīng)網(wǎng)絡(luò),好處是將原來CNN隱藏層之間空間關(guān)系關(guān)聯(lián)起來,從而更好處理畫面中連續(xù)相關(guān)的目標(biāo),這個(gè)算法特別對于行車時(shí)車道的目標(biāo)檢測任務(wù),精度很高,準(zhǔn)確率高達(dá)96.53%。
可以看出,傳統(tǒng)情況下都是在實(shí)際檢測過程中有一些干擾,使得在檢測過程中原來需要正確檢測出的像素點(diǎn)和其他的像素點(diǎn)發(fā)生了關(guān)聯(lián),受到的周圍環(huán)境干擾比較大。
不過S-CNN就不一樣了,這是深度挖掘了前后線條間的相關(guān)性,避免這種情況出現(xiàn),所以可以清晰的看到圖上檢測出來的電線桿和車道線都是比較粗和連續(xù)的。
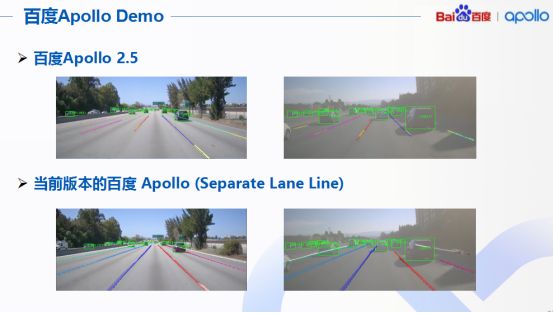
針對百度Apollo和當(dāng)前版本的百度Apollo對于車道線檢測效果的對比,很直觀看到,采用剛才提出的算法以后,對于自動(dòng)駕駛的視覺系統(tǒng)而言,性能提升非常明顯。原來路邊車道線模糊或者根本看不到車道線的地方現(xiàn)在通過引入新的分離的車道線檢測技術(shù)以后,可以看出Apollo在行使過程中可以準(zhǔn)確檢測出車道線了。
在Apollo2.5和3.0中,基于YOLO設(shè)計(jì)了一些單物攝像頭下的物體檢測神經(jīng)網(wǎng)絡(luò),稱為Multi-Task YOLO 3D。因?yàn)樗淖罱K輸出是單目攝像頭3D障礙物檢測的信息,最后會(huì)輸出多于2D圖像檢測的全部信息,所以可以看到與普通的CNN網(wǎng)絡(luò)檢測出來的效果并不一樣,這是立體的檢測結(jié)果,也就是說檢測出來的那個(gè)框結(jié)果是立體的。

不同之處在于首先就是3D框輸出,其次它也會(huì)輸出相對障礙物所檢測出來的一些偏轉(zhuǎn)角,此外現(xiàn)在的Apollo3.5還包含物體的分割信息,具有物體分割的功能,包括車道線的信息,用來提供給定位模塊等。
在Apollo檢測的事例中可以看到,算法其實(shí)對于路邊的行人判斷還是比較準(zhǔn)確的,可以在一堆繁忙的公路上清晰看到最終要檢測出來的某個(gè)行人。此外,Apollo單目攝像頭下的障礙物檢測速度是比較快的,特別是對繁忙路段和高速場景都是比較適配,檢測速度達(dá)到了30赫茲,也就是說每秒鐘可以檢測30張圖像。
除此之外,Apollo還有一些相關(guān)功能,例如典型目標(biāo)的檢測,包含了基于經(jīng)典計(jì)算機(jī)視覺障礙的物體識(shí)別和基于深度學(xué)習(xí)的障礙物識(shí)別。基于經(jīng)典計(jì)算機(jī)視覺的障礙物識(shí)別的計(jì)算復(fù)雜度比較低,單核CPU可以達(dá)到實(shí)現(xiàn),同時(shí)因?yàn)閺?fù)雜度比較低,訓(xùn)練也比較快。此外,深度學(xué)習(xí)主要依賴GPU,當(dāng)速度比較快,而且訓(xùn)練數(shù)據(jù)足夠多的時(shí)候,可以得到最好的準(zhǔn)確度。
百度深度學(xué)習(xí)框架對目標(biāo)檢測的實(shí)操
為了方便開發(fā)者們的理解,我們以百度PaddlePaddle為例為大家介紹實(shí)際目標(biāo)檢測中的可喜效果。
首先提出PaddlePaddle官方倉庫里的MobileNet+SSD的檢測效果,這個(gè)模型可以從官方倉庫上下載,整個(gè)模型也非常適合移動(dòng)端場景,算法的流程和前面介紹的比較類似。
最初采用G網(wǎng)絡(luò)MobileNet來抽取特征,隨后利用前面介紹的SDD中的堆疊卷積盒來進(jìn)行特征識(shí)別,不同位置檢測不同大小、不同形狀的目標(biāo),最后再利用非極大值抑制篩選出最合適的識(shí)別結(jié)果,整個(gè)模型最重要的是對候選框信息的獲取,包括框的位置、目標(biāo)類別、置信概率三個(gè)信息在內(nèi)。

具體如何獲取這些框的相關(guān)信息呢?實(shí)際上PaddlePaddle已經(jīng)提供了封裝好的API,使用時(shí)直接調(diào)用即可。我們調(diào)用這個(gè)函數(shù),就是Multi_box_head,從MobileNet最后一層進(jìn)行連接,用來生成SSD中的特征抓取盒,其中包含所謂的四個(gè)返回值,分別是候選框邊界的精細(xì)回歸、框內(nèi)出現(xiàn)物體的置信度、候選框原始位置、候選框原始位置方差。實(shí)際上就是候選框的位置以及關(guān)于這些位置相對偏移的量。
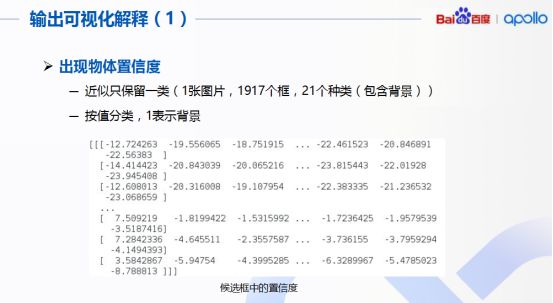
如果把這些值進(jìn)行輸出可視化,首先給出的是出現(xiàn)物體的置信度,通常用框進(jìn)行識(shí)別的過程中,一般認(rèn)為框里只近似保留一種,最后只會(huì)出現(xiàn)一類判斷結(jié)果。第一個(gè)值如果是最大的,就被認(rèn)為屬于背景類,也就是說第一個(gè)張量,它的這個(gè)框的目標(biāo)就是背景。接著把所有背景選出來之后,再把這些背景去掉,剩下來的自然而然就是畫面中要識(shí)別出來的目標(biāo)。
接下來利用Detection_output這一層,加入一個(gè)可視化的邊框的操作,可以看到,藍(lán)色的表示人,紅色的表示摩托車,最后利用非極大值抑制的操作,把這些框當(dāng)中多余的框全部去掉,只保留最貼近檢測效果的框,也就是最后想要的結(jié)果。可以看到,經(jīng)過非極大值抑制后,同類的折疊框一般只保留概率較高的、重疊較小的,這就完成了最終的目標(biāo)檢測。

-
自動(dòng)駕駛
+關(guān)注
關(guān)注
788文章
14302瀏覽量
170466 -
Apollo
+關(guān)注
關(guān)注
5文章
348瀏覽量
18819 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5560瀏覽量
122748
原文標(biāo)題:深度學(xué)習(xí)在自動(dòng)駕駛感知領(lǐng)域的應(yīng)用
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
歐洲央行行長一行到訪百度Apollo Park
百度Apollo向北京工商大學(xué)捐贈(zèng)自動(dòng)駕駛車輛
百度最新消息:蘿卜快跑在港自動(dòng)駕駛測試區(qū)再擴(kuò)大 百度智能云持續(xù)領(lǐng)跑中國大模型

新能源車軟件單元測試深度解析:自動(dòng)駕駛系統(tǒng)視角
百度李彥宏稱自動(dòng)駕駛比人類司機(jī)安全十倍
百度自動(dòng)駕駛或進(jìn)軍阿聯(lián)酋市場
百度Apollo開放平臺(tái)10.0正式發(fā)布
百度獲香港首個(gè)自動(dòng)駕駛先導(dǎo)牌照
百度“蘿卜快跑”自動(dòng)駕駛服務(wù)將試水香港
Apollo自動(dòng)駕駛開放平臺(tái)10.0版即將全球發(fā)布
FPGA在自動(dòng)駕駛領(lǐng)域有哪些優(yōu)勢?
FPGA在自動(dòng)駕駛領(lǐng)域有哪些應(yīng)用?
“蘿卜快跑”自動(dòng)駕駛技術(shù),奪走了誰的方向盤?

禾賽科技獨(dú)供百度Apollo新一代無人車主激光雷達(dá)
單車4臺(tái)AT128!禾賽科技獲得百度蘿卜快跑新一代無人駕駛平臺(tái)主激光雷達(dá)獨(dú)家定點(diǎn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論