") 從算法到硬件 2019,AI將如何演進(jìn)
從算法到硬件 2019,AI將如何演進(jìn)
在剛剛過去的2018年,人工智能領(lǐng)域的大事件、新發(fā)現(xiàn)和新進(jìn)展層出不窮。
BERT重磅發(fā)布,刷新了很多NLP的任務(wù)的最好性能;GAN相關(guān)研究論文持續(xù)增長,生成的照片達(dá)到了以假亂真的程度;Deepfakes發(fā)展神速,讓許多政客和明星供大眾娛樂了一番;強(qiáng)化學(xué)習(xí)也在與人類的對戰(zhàn)游戲中獨(dú)領(lǐng)風(fēng)騷......
硬件方面,Nvidia一騎絕塵,Intel努力求變,定制硬件市場繁榮;
除此之外,自動駕駛、AI倫理等也是過去一年的討論重點(diǎn)。
回顧2018展望2019,人工智能和機(jī)器學(xué)習(xí)將走向何方?
Medium的一位專欄作者為此撰文概括了過去一年中人工智能領(lǐng)域的一些模式,并試圖勾勒出其中的某些趨勢。注意,這篇總結(jié)是以美國的發(fā)展為中心展開,以下是文章全文:
毫無疑問,算法話語權(quán)由深度神經(jīng)網(wǎng)絡(luò)(DNN)主導(dǎo)。
當(dāng)然,你可能會聽說有人在這里或那里部署了一個“經(jīng)典的”機(jī)器學(xué)習(xí)模型(比如梯度提升樹或多臂老虎機(jī)),并聲稱這是每個人唯一需要的東西。有人宣稱,深度學(xué)習(xí)正處于垂死掙扎中。甚至連頂級的研究人員也在質(zhì)疑一些深度神經(jīng)網(wǎng)絡(luò)(DNN)架構(gòu)的效率和抗變換性。
但是,不管你喜歡與否,DNN無處不在: 自動駕駛汽車、自然語言系統(tǒng)、機(jī)器人——所有你能想到的皆是如此。
在自然語言處理、生成式對抗網(wǎng)絡(luò)和深度增強(qiáng)學(xué)習(xí)中,DNN取得的飛躍尤為明顯。
Deep NLP: BERT以及其他
盡管在2018年之前,文本使用DNN(比如word2vec、GLOVE和基于LSTM的模型)已經(jīng)取得了一些突破,但缺少一個關(guān)鍵的概念元素:遷移學(xué)習(xí)。
也就是說,使用大量公開可用的數(shù)據(jù)對模型進(jìn)行訓(xùn)練,然后根據(jù)你正在處理的特定數(shù)據(jù)集對其進(jìn)行“微調(diào)”。在計(jì)算機(jī)視覺中,利用在著名的ImageNet 數(shù)據(jù)集上發(fā)現(xiàn)的模式來解決特定的問題,通常是一種解決方案。
問題是,用于遷移學(xué)習(xí)的技巧并不能很好地應(yīng)用于自然語言處理(NLP)問題。在某種意義上,像word2vec 這樣的預(yù)先訓(xùn)練的嵌入正在彌補(bǔ)這一點(diǎn),但它們只能應(yīng)用于單個單詞級別,無法捕捉到語言的高級結(jié)構(gòu)。
然而,在2018年,這種情況發(fā)生了變化。ELMo,情境化嵌入成為提高NLP 遷移學(xué)習(xí)的第一個重要步驟。ULMFiT 甚至更進(jìn)一步: 由于不滿意嵌入式的語義捕捉能力,作者找到了一種為整個模型進(jìn)行遷移學(xué)習(xí)的方法。
但最有趣的進(jìn)步無疑是BERT的引入。通過讓語言模型從英文維基百科的全部文章中進(jìn)行學(xué)習(xí),這個團(tuán)隊(duì)能夠在11個NLP 任務(wù)中取得最高水準(zhǔn)的結(jié)果——這是一個壯舉!更妙的是,它開源了。所以,你可以把這一突破應(yīng)用到自己的研究問題上。
生成式對抗網(wǎng)絡(luò)(GAN)的多面性
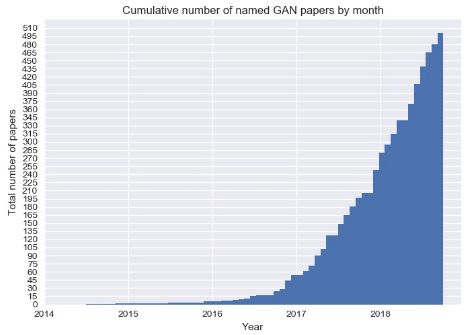
CPU的速度不會再呈現(xiàn)指數(shù)級的增長,但是生成式對抗網(wǎng)絡(luò)(GAN)的學(xué)術(shù)論文數(shù)量肯定會繼續(xù)增長。GAN多年來一直是學(xué)術(shù)界的寵兒。然而,其在現(xiàn)實(shí)生活中的應(yīng)用似乎很少,而且這一點(diǎn)在2018年幾乎沒有改變。但是GAN仍然有著驚人的潛力等待著我們?nèi)?shí)現(xiàn)。
目前出現(xiàn)了一種新的方法,即逐步增加生成式對抗網(wǎng)絡(luò): 使生成器在整個訓(xùn)練過程中逐步提高其輸出的分辨率。很多令人印象深刻的論文都使用了這種方法,其中有一篇采用了風(fēng)格轉(zhuǎn)移技術(shù)來生成逼真的照片。有多逼真?你來告訴我:
這些照片中哪一張是真人?
這個問題有陷阱:以上皆不是。
然而,GAN是如何工作的,以及它為什么會起效呢?我們對此還缺乏深入的了解,但是我們正在采取一些重要的措施: 麻省理工學(xué)院的一個團(tuán)隊(duì)已經(jīng)對這個問題進(jìn)行了高質(zhì)量的研究。
另一個有趣的進(jìn)展是“對抗補(bǔ)丁“,從技術(shù)上來說它并非是一個生成式對抗網(wǎng)絡(luò)。它同時使用黑盒(基本上不考慮神經(jīng)網(wǎng)絡(luò)的內(nèi)部狀態(tài))和白盒方法來制作一個“補(bǔ)丁”,可以騙過一個基于CNN的分類器。從而得出一個重要的結(jié)果:它引導(dǎo)我們更好地了解深度神經(jīng)網(wǎng)絡(luò)如何工作,以及我們距離獲得人類級別的概念認(rèn)知還有多遠(yuǎn)。
你能區(qū)分香蕉和烤面包機(jī)嗎?人工智能仍然不能。
強(qiáng)化學(xué)習(xí)(RL)
自從2016年AlphaGo 擊敗李世石后,強(qiáng)化學(xué)習(xí)就一直是公眾關(guān)注的焦點(diǎn)。
在訓(xùn)練中,強(qiáng)化學(xué)習(xí)依賴于“獎勵”信號,即對其在最后一次嘗試中表現(xiàn)的評分。電腦游戲提供了一個與現(xiàn)實(shí)生活相反的自然環(huán)境,讓這種信號隨時可用。因此,RL研究的所有注意力都放在了教AI玩雅達(dá)利游戲上。
談到它們的新發(fā)明 DeepMind,AlphaStar又成了新聞。這種新模式擊敗了星際爭霸II的頂級職業(yè)選手之一。星際爭霸比國際象棋和圍棋復(fù)雜得多,與大多數(shù)棋類游戲不同,星際爭霸有巨大的動作空間和隱藏在玩家身上的重要信息。這次勝利對整個領(lǐng)域來說,都是一次非常重要的飛躍。
在RL這個領(lǐng)域,另一個重要角色OpenAI也沒有閑著。讓它們聲名鵲起的是OpenAI Five,這個系統(tǒng)在2018年8月?lián)魯×薉ota 2這個極其復(fù)雜的電子競技游戲中99.95%的玩家。
盡管OpenAI 已經(jīng)對電腦游戲給予了很多關(guān)注,但是他們并沒有忽視RL 真正的潛在應(yīng)用領(lǐng)域: 機(jī)器人。
在現(xiàn)實(shí)世界中,一個人能夠給予機(jī)器人的反饋是非常稀少且昂貴的:在你的R2-D2(電影中的虛擬機(jī)器人)嘗試走出第一“步”時,你基本上需要一個人類保姆來照看它。你需要數(shù)以百萬計(jì)的數(shù)據(jù)點(diǎn)。
為了彌合這一差距,最新的趨勢是學(xué)會模擬一個環(huán)境,同時并行地運(yùn)行大量場景以教授機(jī)器人基本技能,然后再轉(zhuǎn)向現(xiàn)實(shí)世界。OpenAI和Google都在研究這種方法。
榮譽(yù)獎:Deepfakes
Deepfakes指一些偽造的圖像或視頻,(通常)展示某個公眾人物正在做或說一些他們從未做過或說過的事情。在“目標(biāo)”人物大量鏡頭的基礎(chǔ)上訓(xùn)練一個生成式對抗網(wǎng)絡(luò),然后在其中生成包含所需動作的新媒體——deepfakes就是這樣創(chuàng)建的。
2018年1月發(fā)布的名為FakeApp的桌面應(yīng)用程序,可以讓所有擁有計(jì)算機(jī)科學(xué)知識的人和對此一無所知的人都能創(chuàng)建deepfakes。雖然它制作的視頻很容易被人看出來是假的,但這項(xiàng)技術(shù)已經(jīng)取得了長足的進(jìn)步。
基礎(chǔ)設(shè)施
TensorFlow與PyTorch
目前,我們擁有很多深度學(xué)習(xí)框架。這個領(lǐng)域是廣闊的,這種多樣性表面上看是有意義的。但實(shí)際上,最近大多數(shù)人都在使用Tensorflow或PyTorch。如果你關(guān)心可靠性、易于部署性和模型重載等SREs 通常關(guān)心的問題,那么你可能會選擇Tensorflow。如果你正在寫一篇研究論文,而且不在谷歌工作,那么你很可能使用PyTorch。
ML作為一種服務(wù)隨處可見
今年,我們看到了更多的人工智能解決方案,它們被一個未獲得斯坦福大學(xué)機(jī)器學(xué)習(xí)博士學(xué)位的軟件工程師打包成一個供消費(fèi)的API。Google Cloud和Azure都改進(jìn)了舊服務(wù),并且增加了新服務(wù)。AWS機(jī)器學(xué)習(xí)服務(wù)列表開始看起來十分令人生畏。

天啊,AWS的服務(wù)很快就會多到需要兩級目錄層次結(jié)構(gòu)來展示了。
盡管這種狂熱現(xiàn)象已經(jīng)冷卻了一些,但還是有很多創(chuàng)業(yè)公司發(fā)出了挑戰(zhàn)。每個人都承諾了模型訓(xùn)練的速度、推理過程中的易用性和驚人的模型性能。
只要輸入你的信用卡信息,上傳你的數(shù)據(jù),給模型一些時間去訓(xùn)練或者微調(diào),調(diào)用REST (或者,給更有前瞻性的創(chuàng)業(yè)公司GraphQL)的API,就可以成為人工智能方面的大師,甚至不需要搞清楚“隨機(jī)失活(dropout)”是什么。
有了這么多的選擇,為什么還有人會費(fèi)心自己建造模型和基礎(chǔ)設(shè)施呢?實(shí)際上,現(xiàn)成的MLaaS 產(chǎn)品在80% 的實(shí)用案例中表現(xiàn)得非常好。如果你希望剩下的20% 也能正常工作,那就沒那么幸運(yùn)了: 你不僅不能真正地選擇模型,甚至不能控制超參數(shù)。或者,如果你需要在云的舒適區(qū)之外的某個地方進(jìn)行推斷——一般情況下都做不到。這就是代價(jià)。
榮譽(yù)獎:AutoML和AI Hub
今年推出的兩項(xiàng)特別有趣的服務(wù)均由谷歌發(fā)布。
首先,Google Cloud AutoML是一套定制的NLP 和計(jì)算機(jī)視覺模型培訓(xùn)產(chǎn)品。這是什么意思?汽車設(shè)計(jì)師通過自動微調(diào)幾個預(yù)先訓(xùn)練的模型,并選擇其中最好的那個,從而解決了模型定制問題。這意味著你很可能不需要自己去定制模型。
當(dāng)然,如果你想做一些真正新鮮或不同的東西,那么這個服務(wù)并不適合你。但是,谷歌在大量專有數(shù)據(jù)的基礎(chǔ)上預(yù)先訓(xùn)練其模型,這是一個附帶的好處。想想所有關(guān)于貓的照片,它們一定比Imagenet 更具推廣性!
第二,AI Hub 和TensorFlow Hub。在這兩者出現(xiàn)之前,重復(fù)使用某人的模型確實(shí)是件苦差事。基于GitHub 的隨機(jī)代碼很少能用,通常記錄得很差,而且一般來說,處理起來并不愉快。還有預(yù)先訓(xùn)練的遷移學(xué)習(xí)權(quán)重……這么說吧,你甚至不想嘗試把它們用于工作中。
這正是TF Hub想要解決的問題: 它是一個可靠的、有組織的模型存儲庫,你可以對其進(jìn)行微調(diào)或構(gòu)建。只要加入幾行代碼——TF Hub 客戶端就可以從谷歌的服務(wù)器上獲取代碼和相應(yīng)的權(quán)重——然后,哇哦,它就可以正常工作了!
Ai Hub 更進(jìn)一步:它允許你共享整個ML管道,而不僅僅是模型!它仍然處于alpha 測試階段,但如果你明白我的意思的話,它已經(jīng)比一個連最新的文件也是“3年前才修改”的隨機(jī)存儲庫要好得多。
硬件
Nvidia(英偉達(dá))
如果你在2018年認(rèn)真研究過ML,尤其是DNN,那么你就曾用過一個(或多個)GPU。因此,GPU的領(lǐng)頭羊在這一年里都非常忙碌。
隨著加密狂潮的冷卻和隨后的股價(jià)暴跌,Nvidia發(fā)布了基于圖靈架構(gòu)的全新一代消費(fèi)級卡。新卡僅使用了2017年發(fā)布的基于Volta芯片的專業(yè)卡,且包含了被稱為Tensor Cores的新的高速矩陣乘法硬件。矩陣乘法是DNN運(yùn)行方式的核心,因此加快這些運(yùn)算將大大提高新GPU上神經(jīng)網(wǎng)絡(luò)訓(xùn)練的速度。
對于那些對“小”和“慢”的游戲GPU不滿意的人來說,Nvidia更新了他們的“超級計(jì)算平臺”。 DGX-2具有多達(dá)16塊Tesla V,用于FP16操作的480TFLOP(480萬億次浮點(diǎn)運(yùn)算),真可謂是一款“怪物”盒子。而其價(jià)格也更新了,高達(dá)40萬美元。
此外,自動硬件也得到了更新。Jetson AGX Xavier是Nvidia希望能為下一代自動駕駛汽車提供動力的一個模塊。八核CPU、視覺加速器以及深度學(xué)習(xí)加速器,這些都是日益增長的自動駕駛行業(yè)所需的。
在一個有趣的開發(fā)項(xiàng)目中,Nvidia為他們的游戲卡推出了基于DNN的一種功能:深度學(xué)習(xí)超級取樣(Deep Learning Super Sampling)。其想法是去替換抗鋸齒,目前主要通過先渲染分辨率高于所需(例如4倍)的圖片然后再將其縮放到本機(jī)監(jiān)視器分辨率來完成。
現(xiàn)在,Nvidia允許開發(fā)人員在發(fā)布游戲之前以極高的質(zhì)量去訓(xùn)練圖像轉(zhuǎn)換模型。然后,使用預(yù)先訓(xùn)練的模型將游戲發(fā)送給最終用戶。在游戲過程中,圖形通過該模型來運(yùn)作以提高圖像質(zhì)量,而不會產(chǎn)生舊式抗鋸齒的成本。
Intel英特爾
英特爾在2018年絕對不是人工智能硬件領(lǐng)域的開拓者,但似乎他們希望改變這一點(diǎn)。
令人驚訝的是,英特爾的大多數(shù)動作都發(fā)生在軟件領(lǐng)域。英特爾正在努力使其現(xiàn)有和即將推出的硬件更加適合開發(fā)人員。考慮到這一點(diǎn),他們發(fā)布了一對(既令人驚訝又有競爭力的)工具包:OpenVINO和nGraph。
他們更新了自己的神經(jīng)計(jì)算棒:一個小型USB設(shè)備,可以加速任何帶USB端口的DNN,甚至是Raspberry Pi。
有關(guān)英特爾獨(dú)立GPU的傳聞變得越來越錯綜復(fù)雜。雖然這一傳聞持續(xù)流傳,但新設(shè)備對DNN訓(xùn)練的適用性仍有待觀察。絕對適用于深度學(xué)習(xí)的是傳聞中的專業(yè)深度學(xué)習(xí)卡,它們的代號為Spring Hill和Spring Crest。而后者基于初創(chuàng)公司Nervana(英特爾幾年前已將其收購)的技術(shù)。
尋常(和不常見)的定制硬件
谷歌推出了他們的第三代TPU:基于ASIC的DNN專用加速器,具有驚人的128Gb HMB內(nèi)存。256個這樣的設(shè)備組裝成一個具有超過每秒100千兆次性能的集合體。谷歌今年不再僅憑這些設(shè)備來挑逗世界的其他玩家了,而是通過Google Cloud向公眾提供TPU。
在類似的、但主要針對推理應(yīng)用程序的項(xiàng)目中,亞馬遜已經(jīng)部署了AWS Inferentia:一種更便宜、更有效的在生產(chǎn)中運(yùn)行模型的方式。
谷歌還宣布了Edge TPU項(xiàng)目:這個芯片很小:10個芯片加起來才有一美分硬幣的大小。與此同時,它能做到在實(shí)時視頻上運(yùn)行DNN,并且?guī)缀醪幌娜魏文芰浚@就足夠了。
一個有趣的潛在新玩家是Graphcore。這家英國公司已經(jīng)籌集了3.1億美元,并在2018年推出了他們的第一款產(chǎn)品GC2芯片。根據(jù)基準(zhǔn)測試,GC2在進(jìn)行推理時碾壓了頂級Nvidia服務(wù)器GPU卡,同時消耗的功率顯著降低。
榮譽(yù)獎:AWS Deep Racer
亞馬遜推出了一款小型自動駕駛汽車DeepRacer,以及一個賽車聯(lián)盟。這完全出人意料,但也有點(diǎn)像他們之前推出DeepLens時的情況。這款400美元的汽車配備了Atom處理器,400萬像素?cái)z像頭,wifi,幾個USB端口,以及可運(yùn)行數(shù)小時的充足電量。
自動駕駛模型可以使用完全在云端的3D模擬環(huán)境進(jìn)行訓(xùn)練,然后直接部署到這款車上。如果你一直夢想著建造自己的自動駕駛汽車,那么亞馬遜的這款車就能讓你如愿,而不必再去自己創(chuàng)立受到VC支持的公司了。
接下來還有什么?重點(diǎn)會轉(zhuǎn)向決策智能
既然算法、基礎(chǔ)設(shè)施和硬件等讓AI變得有用的因素都比以往任何時候要更好,企業(yè)于是意識到開始應(yīng)用AI的最大絆腳石在于其實(shí)際性層面:你如何將AI從想法階段落實(shí)到有效、安全又可靠的生產(chǎn)系統(tǒng)中?
應(yīng)用AI或應(yīng)用機(jī)器學(xué)習(xí)(ML),也稱為決策智能,是為現(xiàn)實(shí)世界問題創(chuàng)建AI解決方案的科學(xué)。雖然過去我們把重點(diǎn)放在算法背后的科學(xué)上,但未來我們應(yīng)該對該領(lǐng)域的端到端應(yīng)用給予更加平等的關(guān)注。
人工智能在促進(jìn)就業(yè)方面功大于過
“人工智能會拿走我們所有的工作”是媒體一直反復(fù)宣揚(yáng)的主題,也是藍(lán)領(lǐng)和白領(lǐng)共同的恐懼。而且從表面上看,這似乎是一個合理的預(yù)測。但到目前為止,情況恰恰相反。例如,很多人都通過創(chuàng)建標(biāo)簽數(shù)據(jù)集的工作拿到了薪酬。
像LevelApp這樣的應(yīng)用程序可以讓難民只需用手機(jī)標(biāo)記自己的數(shù)據(jù)就可以賺到錢。Harmon則更進(jìn)一步:他們甚至為難民營中的移民提供設(shè)備,以便這些人可以做出貢獻(xiàn)并以此謀生。
除了數(shù)據(jù)標(biāo)簽之外,整個行業(yè)都是通過新的AI技術(shù)創(chuàng)建的。我們能夠做到幾年前無法想象的事情,比如自動駕駛汽車或新藥研發(fā)。
更多與ML相關(guān)的計(jì)算將在邊緣領(lǐng)域進(jìn)行
Pipeline的后期階段通常通過降采樣或其他方式降低信號的保真度。另一方面,隨著AI模型變得越來越復(fù)雜,它們在數(shù)據(jù)更多的情況下表現(xiàn)得更好。將AI組件移近數(shù)據(jù)、靠近邊緣,是否會有意義嗎?
舉一個簡單的例子:想象一個高分辨率的攝像機(jī),可以每秒30千兆次的速度生成高質(zhì)量的視頻。處理該視頻的計(jì)算機(jī)視覺模型在服務(wù)器上運(yùn)行。攝像機(jī)將視頻流式傳輸?shù)椒?wù)器,但上行帶寬有限,因此視頻會縮小并被高度壓縮。為何不將視覺模型移動到相機(jī)并使用原始視頻流呢?
與此同時,多個障礙總是存在,它們主要是:邊緣設(shè)備上可用的計(jì)算能力的數(shù)量和管理的復(fù)雜性(例如將更新的模型推向邊緣)。專用硬件(如Google的Edge TPU、Apple的神經(jīng)引擎等)、更高效的模型和優(yōu)化軟件的出現(xiàn),讓計(jì)算的局限性逐漸消失。通過改進(jìn)ML框架和工具,管理復(fù)雜性問題不斷得到解決。
整合AI基礎(chǔ)架構(gòu)空間
前幾年人工智能基礎(chǔ)設(shè)施相關(guān)活動層出不窮:盛大的公告、巨額的多輪融資和厚重的承諾。2018年,這個領(lǐng)域似乎降溫了。雖然仍然有很多新的進(jìn)步,但大部分貢獻(xiàn)都是由現(xiàn)有大型玩家做出的。
一個可能的解釋也許是我們對AI系統(tǒng)的理想基礎(chǔ)設(shè)施的理解還不夠成熟。由于問題很復(fù)雜,需要長期、持久、專注而且財(cái)力雄厚的努力,才能產(chǎn)生可行的解決方案——這是初創(chuàng)公司和小公司所不擅長的。如果一家初創(chuàng)公司“解決”了AI的問題,那絕對會讓人驚奇不已。
另一方面,ML基礎(chǔ)設(shè)施工程師卻很少見。對于大公司來說,一個僅有幾名員工、掙扎求生的創(chuàng)業(yè)公司顯然是很有價(jià)值的并購目標(biāo)。這個行業(yè)中至少有幾個玩家是為了勝利在不斷奮斗的,它們同時建立了內(nèi)部和外部工具。例如,對于AWS和Google Cloud而言,AI基礎(chǔ)設(shè)施服務(wù)是一個主要賣點(diǎn)。
綜上可以預(yù)測,未來在這個領(lǐng)域會出現(xiàn)一個整合多個玩家的壟斷者。
更多定制硬件
至少對于CPU而言,摩爾定律已經(jīng)失效了,并且這一事實(shí)已經(jīng)存在很多年了。GPU很快就會遭受類似的命運(yùn)。雖然我們的模型變得越來越高效,但為了解決一些更高級的問題,我們需要用到更多的計(jì)算能力。這可以通過分布式訓(xùn)練來解決,但它自身也有局限。
此外,如果你想在資源受限的設(shè)備上運(yùn)行一些較大的模型,分布式訓(xùn)練會變得毫無用處。進(jìn)入自定義AI加速器。根據(jù)你想要的或可以實(shí)現(xiàn)的自定義方式,可以節(jié)省一個數(shù)量級的功耗、成本或潛在消耗。
在某種程度上,即使是Nvidia的Tensor Cores也已經(jīng)投身于這一趨勢。如果沒有通用硬件的話,我們會看到更多的案例。
減少對訓(xùn)練數(shù)據(jù)的依賴
標(biāo)記數(shù)據(jù)通常很昂貴,或者不可用,也可能二者兼有。這一規(guī)則幾乎沒有例外。開放的高質(zhì)量數(shù)據(jù)集,如MNIST、ImageNet、COCO、Netflix獎和IMDB評論,都是令人難以置信的創(chuàng)新源泉。但是許多問題并沒有可供使用的相應(yīng)數(shù)據(jù)集。研究人員不可能自己去建立數(shù)據(jù)集,而可提供贊助或發(fā)布數(shù)據(jù)集的大公司卻并不著急:他們正在構(gòu)建龐大的數(shù)據(jù)集,但不讓外人靠近。
那么,一個小型獨(dú)立實(shí)體,如創(chuàng)業(yè)公司或大學(xué)研究小組,如何為那些困難的問題提供有趣的解決方案呢?構(gòu)建對監(jiān)督信號依賴性越來越小,但對未標(biāo)記和非結(jié)構(gòu)化數(shù)據(jù)(廉價(jià)傳感器的互聯(lián)和增多使得這類數(shù)據(jù)變得很豐富)依賴性越來越大的系統(tǒng)就可以實(shí)現(xiàn)這一點(diǎn)。這在一定程度上解釋了人們對GAN、轉(zhuǎn)移和強(qiáng)化學(xué)習(xí)的興趣激增的原因:所有這些技術(shù)都需要較少(或根本不需要)對訓(xùn)練數(shù)據(jù)集的投資。
所以這一切僅僅是個泡沫?
這一行業(yè)已進(jìn)入熱門人工智能“盛夏”的第七年。這段時間內(nèi),大量的研究項(xiàng)目、學(xué)術(shù)資助、風(fēng)險(xiǎn)投資、媒體關(guān)注和代碼行都涌入了這個領(lǐng)域。
但人們有理由指出,人工智能所做出的大部分承諾仍然還未兌現(xiàn):他們最近優(yōu)步打車的行程依然是人類駕駛員在開車;目前依然沒有出現(xiàn)早上能做煎蛋的實(shí)用機(jī)器人。我甚至不得不自己綁鞋帶,真是可悲至極!
然而,無數(shù)研究生和軟件工程師的努力并非徒勞。似乎每家大公司都已經(jīng)十分依賴人工智能,或者在未來實(shí)施此類計(jì)劃。AI的藝術(shù)大行其道。自動駕駛汽車雖然尚未出現(xiàn),但它們很快就會誕生了。
2018年,美國在人工智能領(lǐng)域發(fā)展迅速,中國也不遑多讓。這個趨勢從近期百度和BOSS直聘聯(lián)合發(fā)布的《2018年中國人工智能ABC人才發(fā)展報(bào)告》中就可窺一斑。
未來智能實(shí)驗(yàn)室是人工智能學(xué)家與科學(xué)院相關(guān)機(jī)構(gòu)聯(lián)合成立的人工智能,互聯(lián)網(wǎng)和腦科學(xué)交叉研究機(jī)構(gòu)。
未來智能實(shí)驗(yàn)室的主要工作包括:建立AI智能系統(tǒng)智商評測體系,開展世界人工智能智商評測;開展互聯(lián)網(wǎng)(城市)云腦研究計(jì)劃,構(gòu)建互聯(lián)網(wǎng)(城市)云腦技術(shù)和企業(yè)圖譜,為提升企業(yè),行業(yè)與城市的智能水平服務(wù)。
-
算法
+關(guān)注
關(guān)注
23文章
4608瀏覽量
92845 -
AI
+關(guān)注
關(guān)注
87文章
30763瀏覽量
268917 -
智能硬件
+關(guān)注
關(guān)注
205文章
2345瀏覽量
107536
原文標(biāo)題:從算法到硬件,一文讀懂2019年 AI如何演進(jìn)
文章出處:【微信號:AItists,微信公眾號:人工智能學(xué)家】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
《算力芯片 高性能 CPUGPUNPU 微架構(gòu)分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
【「從算法到電路—數(shù)字芯片算法的電路實(shí)現(xiàn)」閱讀體驗(yàn)】+內(nèi)容簡介
【「從算法到電路—數(shù)字芯片算法的電路實(shí)現(xiàn)」閱讀體驗(yàn)】+介紹基礎(chǔ)硬件算法模塊
【「從算法到電路—數(shù)字芯片算法的電路實(shí)現(xiàn)」閱讀體驗(yàn)】+一本介紹基礎(chǔ)硬件算法模塊實(shí)現(xiàn)的好書
名單公布!【書籍評測活動NO.46】從算法到電路 | 數(shù)字芯片算法的電路實(shí)現(xiàn)
從IC設(shè)計(jì)到系統(tǒng)創(chuàng)新,新思科技為AI創(chuàng)新提速
Arm CPU如何推動AI創(chuàng)新
聲智科技超低成本部署,打造AI硬件與AI交互產(chǎn)業(yè)生態(tài)
從TPU v1到Trillium TPU,蘋果等科技公司使用谷歌TPU進(jìn)行AI計(jì)算
平衡創(chuàng)新與倫理:AI時代的隱私保護(hù)和算法公平
從端側(cè)到云測,給硬件減負(fù)的AI超分技術(shù)
從端側(cè)到云側(cè),給硬件減負(fù)的AI超分技術(shù)

NanoEdge AI的技術(shù)原理、應(yīng)用場景及優(yōu)勢

新火種AI|從GPT-5到AI芯片廠,山姆·奧特曼在下一盤多大的棋?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論