 來看看Spark和Flink各自的優劣和主要區別
來看看Spark和Flink各自的優劣和主要區別
2018和2019年是大數據領域蓬勃發展的兩年,自2019年伊始,實時流計算技術開始步入普通開發者視線,各大公司都在不遺余力地試用新的流計算框架,實時流計算引擎Spark Streaming、Kafka Streaming、Beam和Flink持續火爆。
最近Spark社區,來自Databricks、NVIDIA、Google以及阿里巴巴的工程師們正在為Apache Spark 3.0添加原生的GPU調度支持,參考(SPARK-24615和SPARK-24579)該方案將填補了Spark在GPU資源的任務調度方面的空白,極大擴展了Spark在深度學習、信號處理的應用場景。
與此同時,2019年1月底,阿里巴巴內部版本Blink正式開源!一石激起千層浪,Blink開源的消息立刻刷爆朋友圈,整個大數據計算領域一直以來由Spark獨領風騷,瞬間成為兩強爭霸的時代。那么未來Spark和Blink的發展會碰撞出什么樣的火花?誰會成為大數據實時計算領域最亮的那顆星?
我們接下來看看Spark和Flink各自的優劣和主要區別。
底層機制
Spark的數據模型是彈性分布式數據集 RDD(Resilient Distributed Dattsets),這個內存數據結構使得spark可以通過固定內存做大批量計算。初期的Spark Streaming是通過將數據流轉成批(micro-batches),即收集一段時間(time-window)內到達的所有數據,并在其上進行常規批處,所以嚴格意義上,還不能算作流式處理。但是Spark從2.x版本開始推出基于 Continuous Processing Mode的 Structured Streaming,支持按事件時間處理和端到端的一致性,但是在功能上還有一些缺陷,比如對端到端的exactly-once語義的支持。
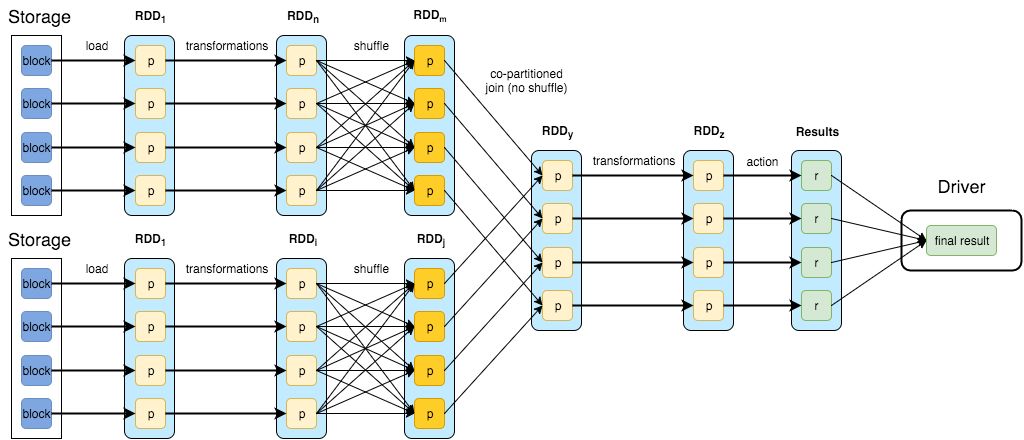
一個典型的Spark DAG示意圖
Flink是統一的流和批處理框架,基本數據模型是數據流,以及事件(Event)的序列,Flink從設計之初秉持了一個觀點:批是流的特例。每一條數據都可以出發計算邏輯,那么Flink的流特性已經在延遲方面占得天然優勢。
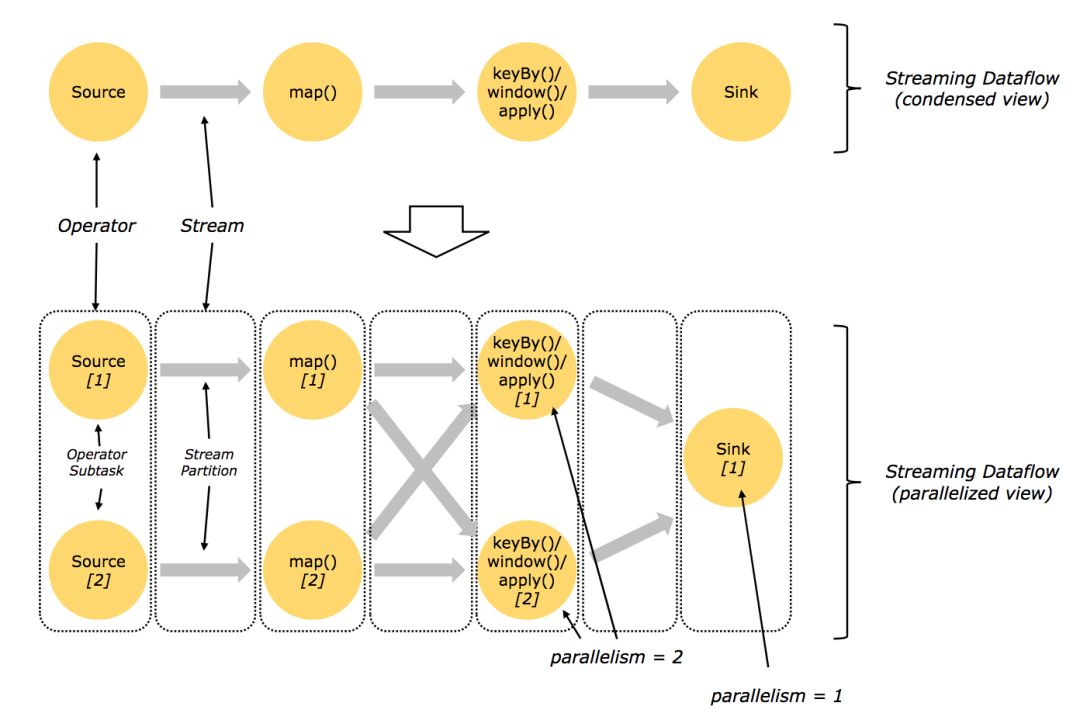
一個典型的Flink workflow示意圖
Flink還提供了一個獨特的概念叫做有狀態的計算,它被用來處理一種情況:數據的處理和之前處理過的數據或者事件有關聯。比如,在做聚合操作的時候,一個批次的數據聚合的結果依賴于之前處理過的批次。早期的Spark用戶會經常受此類問題所困擾,直到Structured Streaming的出現才得已解決。
Flink從一開始就引入了state的概念來處理這種問題。為狀態計算提供了一個通用的解決方案。
周邊生態
在大數據領域,任何一個項目的火爆都被離不開完善的技術棧,Spark和Flink都基于對底層數據和計算調度的高度抽象的內核上開發出了批處理,流處理,結構化數據,圖數據,機器學習等不同套件,完成對絕大多數數據分析領域的場景的支持,意圖統一數據分析領域。
Flink和Spark都是由Scla和Java混合編程實現,Spark的核心邏輯由Scala完成,而Flink的主要核心邏輯由Java完成。在對第三方語言的支持上,Spark支持的更為廣泛,Spark幾乎完美的支持Scala,Java,Python,R語言編程。
Spark周邊生態(圖來源于官網)
與此同時,Flink&Spark官方都支持與存儲系統如HDFS,S3的集成,資源管理/調度Yarn,Mesos,K8s等集成,數據庫Hbase,Cassandra,消息系統Amazon,Kinesis,Kafka等。
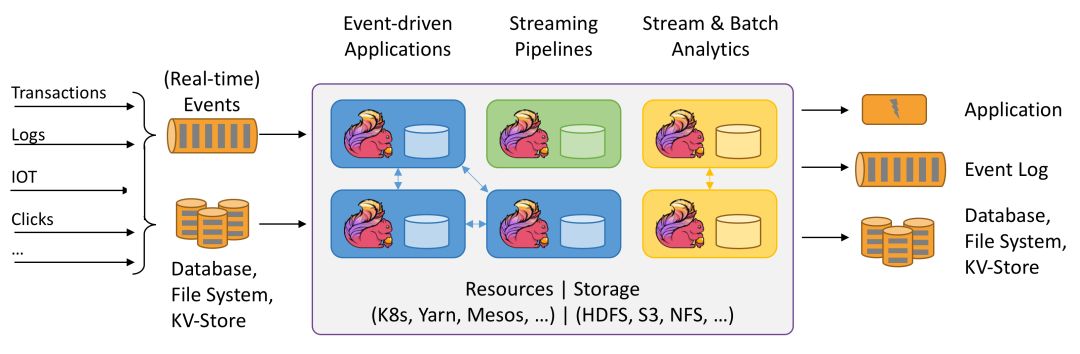
Flink周邊生態(圖來源于官網)
在最近的Spark+AI峰會上,Databricks公司推出了自己的統一分析平臺(Unified Analytics Platform),目標是使戶在一個系統里解決盡可能多的數據需求。Flink的目標和Spark一致,包含AI的統一平臺也是Flink的發展方向,從技術上來看,Flink是完全有能力支持對機器學習和深度學習的集成,但目前來看,Flink仍有很長的路要走。
未來趨勢
2018年是機器學習和深度學習元年,ML在數據處理領域占比越來越重。Spark和Flink在做好實時計算的同時,誰能把握住這次機會就可以在未來的發展中占得先機。另外隨著5G的發展,網絡傳輸不再是瓶頸之時,IOT的爆發式發展也將會是實時計算需求爆發之時,屆時Flink在流式計算中的天然優勢將發揮的淋漓盡致,Blink的開源和阿里巴巴對Blink的加持無疑又給Flink未來的發展注入一針強心劑。
總結
Spark和Flink發展至今,基本上已經是實時計算領域的事實標準。兩者在易用性和生態系統建設上都投入了大量的資源,是現在和未來一段時間內大數據領域最有有力的競爭者。二者的發展是競爭中伴隨著互相促進,在與機器學習集成和統一處理平臺的建設上雙方各有優劣,誰能盡早補齊短板就會在未來的發展中占得優勢。對于普通大數據領域的開發者而言,當下也是最好的時代,可以見證兩大數據引擎的蓬勃發展,除了學習別無選擇,這何嘗不是是一種幸運?
-
gpu
+關注
關注
28文章
4762瀏覽量
129162 -
數據集
+關注
關注
4文章
1208瀏覽量
24764 -
SPARK
+關注
關注
1文章
105瀏覽量
19935
原文標題:開源的Blink和Spark3.0,誰將稱霸大數據領域?
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
請問AD9162和AD9164的主要區別是什么?
hadoop和spark的區別
HDL語言中的unsigned與signed的主要區別是什么
AD9162和AD9164的主要區別是什么?
unpacked數組和packed數組的主要區別

步進電機和伺服電機的主要區別





 工商網監
工商網監
評論