 5個最近推出的用于圖像合成的GAN架構
5個最近推出的用于圖像合成的GAN架構
本文總結了5個最近推出的用于圖像合成的GAN架構,對論文從核心理念、關鍵成就、社區價值、未來商業化及可能的落地應用方向對論文進行解讀,對創業者、開發者、工程師、學者均有非常高的價值。
1. STARGAN:
多域圖像到圖像翻譯的統一生成網絡。作者YUNJEY CHOI,MINJE CHOI,MUNYOUNG KIM,JUNG-WOO HA,SUNGHUN KIM,JAEGUL CHOO。論文地址:
https://arxiv.org/abs/1711.09020
論文摘要
最近的研究表明,兩個領域的圖像到圖像轉換取得了顯著的成功。然而,現有方法在處理兩個以上的域時,可擴展性和魯棒性的比較有限,因為需要為每對圖像域獨立地構建不同的模型。
StarGAN的出現就是為了解決這一問題。研究人員提出了一種新穎且可擴展的方法,可以實現僅靠單個模型就能對多個域執行圖像到圖像的轉換。
StarGAN這種統一模型架構,允許在單個網絡內同時訓練具有不同域的多個數據集。與現有模型相比,StarGAN有著更高的圖像轉化質量,以及將輸入圖像靈活地轉換為任何所需目標域的新穎功能。
我們憑經驗證明了我們的方法在面部屬性轉移,和面部表情綜合任務方面的有效性。
核心理念
StarGAN是一種可擴展的圖像到圖像轉換模型,可以使用單個網絡從多個域中學習:
生成器不是學習固定的轉換(例如,年輕到年老),而是接收圖像和域信息作為輸入,以在相應的域中生成圖像
提供域信息作為標簽(例如,二進制或one-hot矢量)
StarGAN還可以從包含不同類型標簽的多個數據集中學習:
例如,作者展示了如何使用具有頭發顏色,性別和年齡等屬性的CelebA數據集,以及具有與面部表情相對應的標簽的RaFD數據集來訓練模型
將mask向量添加到域標簽后,生成器會學著忽略未知標簽,并專注于明確給定的標簽
關鍵成就
定性和定量評估表明,StarGAN在面部屬性轉移和面部表情綜合方面優于基準模型:
在更復雜的多屬性傳輸任務中,優勢尤為明顯,這反映了StarGAN處理具有多個屬性更改的圖像轉換的能力
由于多任務學習的隱含數據增強效果,StarGAN還可以生成更具視覺吸引力的圖像
社區評價
該研究論文在計算機視覺的重要會議CVPR 2018 oral上被接受。
未來的研究領域
探索進一步改善生成圖像的視覺質量的方法。
可能的商業應用
圖像到圖像轉換可以降低用于廣告和電子商務用途的媒體創意的成本。
源碼
https://github.com/yunjey/stargan
2. ATTNGAN
用細致的文字生成圖像,作者TAO XU, PENGCHUAN ZHANG, QIUYUAN HUANG, HAN ZHANG, ZHE GAN, XIAOLEI HUANG, XIAODONG HE。論文地址:
https://arxiv.org/abs/1711.10485
論文摘要
在論文中,我們提出了一種Attentional生成對抗網絡(AttnGAN)。它允許注意力驅動的多階段細化,以實現細粒度粒度的文本到圖像的生成。
通過新穎的注意力生成網絡,AttnGAN可以通過關注自然語言描述中的相關單詞,來合成圖像的不同子區域的細粒度細節。此外,提出了一種深度attentional多模態相似度模型,來計算用于訓練生成器的細粒度圖像文本匹配損失。
AttnGAN明顯優于當前最先進的技術水平,在CUB數據集上提升了14.14%的最佳報告得分,在更具挑戰性的COCO數據集上得到170.25%的提升。同時還通過可視化AttnGAN的注意力層來執行詳細分析。它首次表明分層注意力GAN能夠自動選擇單詞級別的條件,以生成圖像的不同部分。
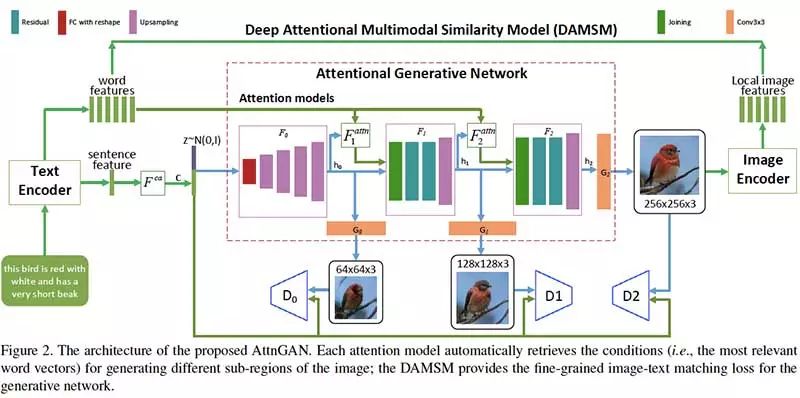
核心理念
可以通過多階(例如,單詞級和句子級)調節來實現細粒度的高質量圖像生成。因此,研究人員提出了一種體系結構,其中生成網絡通過這些子區域最相關的單詞來繪制圖像。
Attentional Generative AdversarialNetwork有兩個新穎的組件:Attentional generative network和深度Attentional多模態相似度模型(DAMSM)。
Attentional generative network包括以下2個方面
利用全局句子向量在第一階段生成低分辨率圖像
將區域圖像矢量與對應的詞語上下文矢量組合以在周圍子區域中生成新的圖像特征
而深度Attentional多模態相似度模型(DAMSM),用于計算生成的圖像和文本描述之間的相似性,為訓練生成器提供額外的細粒度圖文匹配損失。
關鍵成就
CUB數據集上提升了14.14%的最佳報告得分
COCO數據集提升了170.25%
證明分層條件GAN能夠自動關注相關單詞以形成圖像生成的正確條件
社區評價
該論文在計算機視覺的重要會議2018年CVPR上發表。
未來的研究領域
探索使模型更好地捕獲全局相干結構的方法;增加生成圖像的照片真實感。
可能的商業應用
根據文本描述自動生成圖像,可以提高計算機輔助設計和藝術品的生產效率。
源碼
GitHub上提供了AttnGAN的PyTorch實現。
3. 通過條件生成式GAN獲得高分辨率圖像合成及語義操作
作者TING-CHUN WANG, MING-YU LIU, JUN-YAN ZHU, ANDREW TAO, JAN KAUTZ, BRYAN CATANZARO。論文地址:
https://arxiv.org/abs/1711.11585
論文摘要
Conditional GAN已有很多應用案例,但通常僅限于低分辨率圖像,且遠未達到以假亂真的地步。NVIDIA引入了一個新的方法,可以從語義標簽貼圖中合成高分辨率(2048×1024)、照片級的逼真圖像。
他們的方法基于新的強大對抗性學習目標,以及新的多尺度生成器和鑒別器架構。這種新方法在語義分割和照片真實性的準確性方面,總體上優于以前的方法。此外,研究人員還擴展其框架以支持交互式語義操作,合并了對象實例分割信息,似的它可以實現對象操作,例如更改對象類別、添加/刪除對象或更改對象的顏色和紋理。
人類裁判經過肉眼比對后表示,此方法明顯優于現有方法。
核心理念
稱為pix2pixHD(基于pix2pix方法)的新框架合成高分辨率圖像,有幾處改進:
coarse-to-fine(由粗糙到細粒度)生成器:訓練全局生成器以1024×512的分辨率合成圖像,然后訓練局部增強器以提高分辨率
多尺度鑒別器:使用3個不同圖像尺度的鑒別器
改進的對抗性損失:基于鑒別器結合特征匹配損失
該框架還允許交互式對象編輯,這要歸功于添加額外的低維特征通道作為生成器網絡的輸入。
關鍵成就
引入的pix2pixHD方法在以下方面的表現優于最先進的方法:
語義分割的逐像素精度,得分為83.78(來自pix2pix基準的5.44,僅比原始圖像的精度低0.51個點)
人工評估員可以在任意數據集和任意時間設置(無限時間和有限時間)上進行的成對比較
社區評價
在計算機視覺的重要會議CVPR 2018上 Oral上,深度學習研究員Denny Britz對此評價:“這些GAN結果令人印象深刻。 如果你現在正在用Photoshop修圖來謀生,那么可能是時候另謀出路了。“
可能的商業應用
該方法為更高級別的圖像編輯提供了新工具,例如添加/刪除對象或更改現有對象的外觀。可以用在修圖工具中,或者創建新的修圖工具。
源碼
https://github.com/NVIDIA/pix2pixHD
4. 高強度自然圖像合成的大型GAN訓練
作者ANDREW BROCK,JEFF DONAHUE和KAREN SIMONYAN,論文地址:
https://arxiv.org/abs/1809.11096
論文摘要
DeepMind團隊發現,盡管最近在生成圖像建模方面取得了進展,但是從像ImageNet這樣的復雜數據集中成功生成高分辨率、多樣化的樣本仍然是一個難以實現的目標。
經過對GAN進行了最大規模的訓練嘗試,并研究了這種規模特有的不穩定性后,發現將正交正則化應用于生成器可以使得它適合于簡單的“截斷技巧”,允許通過截斷潛在空間來精確控制樣本保真度和變化之間的權衡。
這樣的改動導致模型在類條件圖像合成中達到了新的技術高度,當在ImageNet上以128×128分辨率進行訓練時,模型(BigGAN)的Inception Score(IS)達到了166.3;Frechet Inception Distance(FID)為9.6。而之前的最佳IS為52.52,FID為18.65。
該論文表明,如果GAN以非常大的規模進行訓練,例如用兩倍到四倍的參數和八倍于之前的批量大小,就可以生成看起來非常逼真的圖像。這些大規模的GAN(即BigGAN)是類條件圖像合成中最先進的新技術。
核心理念
隨著批量大小和參數數量的增加,GAN的性能在提升
將正交正則化應用于生成器使得模型響應于特定技術(“截斷技巧”),通過這種方式提供對樣本保真度和變化之間的權衡的控制
關鍵成就
證明GAN可以通過增加數據量來獲得更好的收益
構建模型,允許對樣本種類和保真度之間的權衡進行明確的、細粒度的控制
發現大規模GAN的不穩定性并根據經驗進行表征
在ImageNet上以128×128分辨率訓練的BigGAN實現
Inception Score(IS)為166.3,之前的最佳IS為52.52
FrechetInception Distance(FID)為9.6,之前的最佳FID為18.65
社區評價
該文件正在被評審是否錄取為下一屆ICLR 2019。
在BigGAN發生器登上TF Hub后,來自世界各地的AI研究人員用BigGAN來生成狗,手表,比基尼圖像,蒙娜麗莎,海濱等等,玩的不亦樂乎
未來的研究領域
遷移到更大的數據集以緩解GAN穩定性問題
探索減少GAN產生的奇怪樣本數量的可能性
可能的商業應用
替代廣告和電商成本較高的手動媒體創建。
源碼
https://colab.research.google.com/github/tensorflow/hub/blob/master/examples/colab/biggan_generation_with_tf_hub.ipynb
https://github.com/AaronLeong/BigGAN-pytorch
5.基于風格的生成器網絡的生成器架構
作者TERO KARRAS,SAMULI LAINE,TIMO AILA,論文地址:
https://arxiv.org/abs/1812.04948
論文摘要
NVIDIA團隊推出了一種新的生成器架構StyleGAN,借鑒了風格轉移文獻。在這項研究中,他們解決了對傳統GAN架構生成的圖像進行非常有限的控制的問題。
StyleGAN中的生成器自動學習分離圖像的不同方面,而無需任何人為監督,從而可以多種不同方式組合這些方面。例如,我們可以從一個人那里獲取性別,年齡,頭發長度,眼鏡和姿勢,而從另一個人那里獲取所有其他方面。由此產生的圖像在質量和真實性方面優于先前的技術水平。
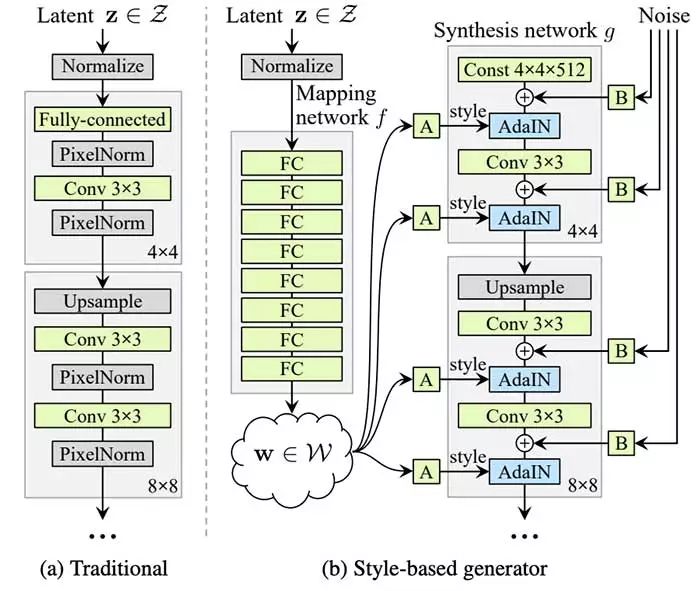
核心理念
StyleGAN基于漸進式GAN設置,其中假定網絡的每個層控制圖像的不同視覺特征,層越低,其影響的特征越粗糙:
對應于粗糙空間分辨率(4×4 - 8×8)的層使得能夠控制姿勢、一般發型、面部形狀等
中間層(16×16 - 32×32)影響較小規模的面部特征,如發型、睜眼/閉眼等
細粒度分辨率(64×64 - 1024×1024)的層主要帶來顏色方案和微結構
受風格轉移文獻的推動,NVIDIA團隊引入了一種生成器架構,可以通過新穎的方式控制圖像合成過程
省略輸入層并從學習的常量開始
在每個卷積層調整圖像“樣式”,允許直接控制不同尺度的圖像特征的強度
在每個卷積之后添加高斯噪聲以生成隨機細節
關鍵成就
在CelebA-HQ數據集上得到5.06的Frèchet inception distance(FID)得分,在Flickr-Faces-HQ數據集上獲得4,40得分
呈現人臉Flickr-Faces-HQ的新數據集,其具有比現有高分辨率數據集更高的圖像質量和更寬的變化
社區評價
Uber的軟件工程師Philip Wang創建了一個網站
thispersondoesnotexist.com
可以在其中找到使用StyleGAN生成的面孔。這個網站形成了病毒式傳播
未來的研究領域
探索在訓練過程中直接塑造中間潛在空間的方法
可能的商業應用
由于StyleGAN方法的靈活性和高質量的圖像,它可以替代廣告和電子商務中昂貴的手工媒體創作。
-
圖像
+關注
關注
2文章
1087瀏覽量
40496 -
GaN
+關注
關注
19文章
1945瀏覽量
73664 -
生成器
+關注
關注
7文章
317瀏覽量
21050
原文標題:5個最新圖像合成GAN架構解讀:核心理念、關鍵成就、商業化路徑
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
使用用于GaN的LMG1210EVM-012 300V半橋驅動器

GaN可靠性測試新突破:廣電計量推出高壓性能評估方案






 工商網監
工商網監
評論