


以下是節(jié)選內(nèi)容
按照技術實現(xiàn),我們可將任務驅(qū)動的對話系統(tǒng)劃分為如下兩類:
模塊化的對話系統(tǒng)
分模塊串行處理對話任務,每一個模塊負責特定的任務,并將結(jié)果傳遞給下一個模塊,通常由NLU(Natural Language Understanding,自然語言理解)、DST(Dialogue State Tracking,對話狀態(tài)追蹤)、DPL(Dialogue Policy Learning,對話策略學習)、NLG(Natural Language Generation,自然語言生成)4個部分構(gòu)成。在具體的實現(xiàn)上,可以針對任一模塊采用基于規(guī)則的人工設計方式,或者基于數(shù)據(jù)驅(qū)動的模型方式。
端到端的對話系統(tǒng)
考慮采用由輸入直接到輸出的端到端對話系統(tǒng),忽略中間過程,采用數(shù)據(jù)驅(qū)動的模型實現(xiàn)。
目前,主流的任務對話系統(tǒng)實現(xiàn)為模塊化方式,由于現(xiàn)有訓練數(shù)據(jù)規(guī)模的限制,端到端的方式仍處于探索階段。本文主要介紹模塊化的面向任務的對話系統(tǒng),圖1介紹了其主要模塊。
(1)NLU:將用戶輸入的自然語言語句映射為機器可讀的結(jié)構(gòu)化語義表述,這種結(jié)構(gòu)化語義一般由兩部分構(gòu)成,分別是用戶意圖(user intention)和槽值(slot-value)。
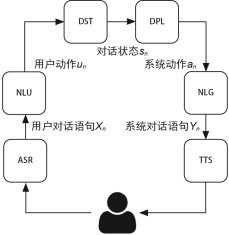
圖1面向任務的對話系統(tǒng)的主要模塊
(2)DST:這一模塊的目標是追蹤用戶需求并判斷當前的對話狀態(tài)。該模塊以多輪對話歷史、當前的用戶動作為輸入,通過總結(jié)和推理理解在上下文的環(huán)境下用戶當前輸入自然語言的具體含義。對于對話系統(tǒng)來說,這一模塊有著重大意義,很多時候需要綜合考慮用戶的多輪輸入才能讓對話系統(tǒng)理解用戶的真正需求。
(3)DPL:也被稱為對話策略優(yōu)化(optimization),根據(jù)當前的對話狀態(tài),對話策略決定下一步執(zhí)行什么系統(tǒng)動作。系統(tǒng)行動與用戶意圖類似,也由意圖和槽位構(gòu)成。
(4)NLG:負責把對話策略模塊選擇的系統(tǒng)動作轉(zhuǎn)化為自然語言,最終反饋給用戶。
在與用戶直接關聯(lián)的兩個模塊中,ASR指的是自動語音識別,TTS指的是語音合成。如第2章介紹的,ASR和TTS并不是系統(tǒng)必備的模塊,也不是本書介紹的重點,因此在面向任務的對話系統(tǒng)中不對這兩部分技術做詳細介紹。
1.NLU模塊
本文主要結(jié)合NLU在面向任務的對話系統(tǒng)中的具體應用進行介紹。
對面向任務的對話系統(tǒng)來說,NLU模塊的主要任務是將用戶輸入的自然語言映射為用戶的意圖和相應的槽位值。因此,在面向任務的對話系統(tǒng)中,NLU模塊的輸入是用戶對話語句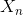 ,輸出是解析
,輸出是解析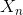 后得到的用戶動作
后得到的用戶動作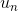 。該模塊涉及的主要技術是意圖識別和槽位填充,這兩種技術分別對應用戶動作的兩項結(jié)構(gòu)化參數(shù),即意圖和槽位。
。該模塊涉及的主要技術是意圖識別和槽位填充,這兩種技術分別對應用戶動作的兩項結(jié)構(gòu)化參數(shù),即意圖和槽位。
下面主要討論如何針對面向任務的對話系統(tǒng)設計NLU模塊,包括針對特定任務定義意圖和相應的槽位,以及后續(xù)從用戶的輸入中獲取任務目標的意圖識別方法和對應的槽位填充方法。
(1)意圖和槽位的定義
意圖和槽位共同構(gòu)成了“用戶動作”,機器是無法直接理解自然語言的,因此用戶動作的作用便是將自然語言映射為機器能夠理解的結(jié)構(gòu)化語義表示。
意圖識別,也被稱為SUC(Spoken Utterance Classification),顧名思義,是將用戶輸入的自然語言會話進行劃分,類別(classification)對應的就是用戶意圖。例如“今天天氣如何”,其意圖為“詢問天氣”。自然地,可以將意圖識別看作一個典型的分類問題。意圖的分類和定義可參考ISO-24617-2標準,其中共有56種詳細的定義。面向任務的對話系統(tǒng)中的意圖識別通常可以視為文本分類任務。同時,意圖的定義與對話系統(tǒng)自身的定位和所具有的知識庫有很大關系,即意圖的定義具有非常強的領域相關性。
槽位,即意圖所帶的參數(shù)。一個意圖可能對應若干個槽位,例如詢問公交車路線時,需要給出出發(fā)地、目的地、時間等必要參數(shù)。以上參數(shù)即“詢問公交車路線”這一意圖對應的槽位。語義槽位填充任務的主要目標是在已知特定領域或特定意圖的語義框架(semantic frame)的前提下,從輸入語句中抽取該語義框架中預先定義好的語義槽的值。語義槽位填充任務可以轉(zhuǎn)化為序列標注任務,即運用經(jīng)典的IOB標記法,標記某一個詞是某一語義槽的開始(begin)、延續(xù)(inside),或是非語義槽(outside)。
要使一個面向任務的對話系統(tǒng)能正常工作,首先要設計意圖和槽位。意圖和槽位能夠讓系統(tǒng)知道該執(zhí)行哪項特定任務,并且給出執(zhí)行該任務時需要的參數(shù)類型。為了方便與問答系統(tǒng)做異同對比,我們依然以一個具體的“詢問天氣”的需求為例,介紹面向任務的對話系統(tǒng)中對意圖和槽位的設計。
用戶輸入示例:“今天上海天氣怎么樣”
用戶意圖定義:詢問天氣,Ask_Weather
槽位定義
槽位一:時間,Date
槽位二:地點,Location
“詢問天氣”的需求對應的意圖和槽位如圖2所示。
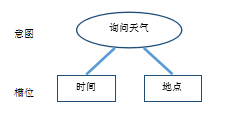
圖2意圖與槽位定義(1)
在上述示例中,針對“詢問天氣”任務定義了兩個必要的槽位,它們分別是“時間”和“地點”。
對于一個單一的任務,上述定義便可解決任務需求。但在真實的業(yè)務環(huán)境下,一個面向任務的對話系統(tǒng)往往需要能夠同時處理若干個任務,例如氣象臺除了能夠回答“詢問天氣”的問題,也應該能夠回答“詢問溫度”的問題。
對于同一系統(tǒng)處理多種任務的復雜情況,一種優(yōu)化的策略是定義更上層的領域,如將“詢問天氣”意圖和“詢問溫度”意圖均歸屬于“天氣”領域。在這種情況下,可以簡單地將領域理解為意圖的集合。定義領域并先進行領域識別的優(yōu)點是可以約束領域知識范圍,減少后續(xù)意圖識別和槽位填充的搜索空間。此外,對于每一個領域進行更深入的理解,利用好任務及領域相關的特定知識和特征,往往能夠顯著地提升NLU模塊的效果。據(jù)此,對圖2的示例進行改進,加入“天氣”領域。
用戶輸入示例
1.“今天上海天氣怎么樣”
2.“上海現(xiàn)在氣溫多少度”
領域定義:天氣,Weather
用戶意圖定義
1. 詢問天氣,Ask_Weather
2. 詢問溫度,Ask_Temperature
槽位定義
槽位一:時間,Date
槽位二:地點,Location
改進后的“詢問天氣”的需求對應的意圖和槽位如圖3所示。
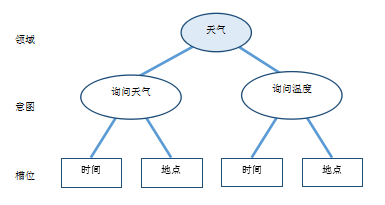
圖3意圖與槽位定義(2)
(2)意圖識別和槽位填充
做好意圖和槽位的定義后,需要從用戶輸入中提取用戶意圖和相應槽對應的槽值。意圖識別的目標是從用戶輸入的語句中提取用戶意圖,單一任務可以簡單地建模為一個二分類問題,如“詢問天氣”意圖,在意圖識別時可以被建模為“是詢問天氣”或者“不是詢問天氣”二分類問題。當涉及需要對話系統(tǒng)處理多種任務時,系統(tǒng)需要能夠判別各個意圖,在這種情況下,二分類問題就轉(zhuǎn)化成了多分類問題。
槽位填充的任務是從自然語言中提取信息并填充到事先定義好的槽位中,例如在圖2中已經(jīng)定義好了意圖和相應的槽位,對于用戶輸入“今天上海天氣怎么樣”系統(tǒng)應當能夠提取出“今天”和“上海”并分別將其填充到“時間”和“地點”槽位。基于特征提取的傳統(tǒng)機器學習模型已經(jīng)在槽位填充任務上得到了廣泛應用。近年來,隨著深度學習技術在自然語言處理領域的發(fā)展,基于深度學習的方法也逐漸被應用于槽位填充任務。相比于傳統(tǒng)的機器學習方法,深度學習模型能夠自動學習輸入數(shù)據(jù)的隱含特征。例如,將可以利用更多上下文特征的最大熵馬爾可夫模型引入槽位填充的過程中[8],類似地,也有研究將條件隨機場模型引入槽位填充。
基于RNN的深度學習模型在意圖識別和槽位填充領域也得到了大量的應用,Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling中介紹了使用Attention-Based RNN模型進行意圖識別和槽位填充的方法,作者提出將“alignment information”加入Encoder-Decoder模型,以及將“alignment information”和“attention”加入RNN這兩種解決槽位填充和意圖識別問題的模型。需要特別介紹的是,與基于RNN的意圖識別和槽位填充相比,基于LSTM模型的槽位填充可以有效解決RNN模型中存在的梯度消失問題。
另外,在實際工程中往往需要先對句子中的各個組成部分進行標注,所以通常也會應用到序列標注方法。
進行意圖識別和槽位填充的傳統(tǒng)方法是使用串行執(zhí)行的方式,即先進行意圖識別,再根據(jù)意圖識別的結(jié)果進行槽位填充任務。這種方式的主要缺陷是:
可能產(chǎn)生錯誤傳遞,導致錯誤放大。
限定領域也就意味著不同領域需要不同的方法和模型進行處理,各個領域之間的模型沒有共享,但在很多情況下,例如訂火車票和飛機票時,時間、地點等槽位都是一致的。
因為串行執(zhí)行的方式存在上述問題,所以研究人員改為使用Multi-Domain Joint Semantic Frame Parsing Using Bi-Directional RNN-LSTM, INTERSPEECH中設計的聯(lián)合學習(joint learning)方式進行意圖識別和槽位填充。
另外,還有一種情況需要特別注意。在一次天氣詢問任務完成后,用戶又問“那明天呢”時,實際上可以認為第二個問句是開始了另一次“詢問天氣”任務,只是其中的“時間”槽位是指定的,而“地點”槽位則需要重復利用(繼承)上一次任務中的值。
對意圖識別模塊和槽位填充模塊的主要評價指標包括:
意圖識別的準確率,即分類的準確率。
槽位填充的F1-score。
2.DST模塊
DST模塊以當前的用戶動作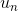 、n-1前輪的對話狀態(tài)和相應的系統(tǒng)動作作為輸入,輸出是DST模塊判定得到的當前對話狀態(tài)
、n-1前輪的對話狀態(tài)和相應的系統(tǒng)動作作為輸入,輸出是DST模塊判定得到的當前對話狀態(tài)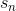 。
。
對話狀態(tài)的表示(DST-State Representation)通常由以下3部分構(gòu)成。
(1)目前為止的槽位填充情況。
(2)本輪對話過程中的用戶動作。
(3)對話歷史。
其中,槽位的填充情況通常是最重要的狀態(tài)表示指標。
我們知道,由于語音識別不準確或是自然語言本身存在歧義性等原因,NLU模塊的識別結(jié)果往往與真實情況存在一定的誤差。所以,NLU模塊的輸出往往是帶概率的,即每一個可能的結(jié)果有一個相應的置信程度。由此,DST在判斷當前的對話狀態(tài)時就有了兩種選擇,這兩種選擇分別對應了兩種不同的處理方式,一種是1-Best方式,另一種則是N-Best方式[11]。
1-Best方式指DST判斷當前對話狀態(tài)時只考慮置信程度最高的情況,因此維護對話狀態(tài)的表示時,只需要等同于槽位數(shù)量的空間,如圖4所示。
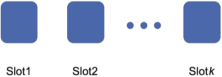
圖4 1-Best方式下的對話狀態(tài)與槽位的對應
N-Best方式指DST判斷當前對話狀態(tài)時會綜合考慮所有槽位的所有置信程度,因此每一個槽位的N-Best結(jié)果都需要考慮和維護,并且最終還需要維護一個槽位組合在一起(overall)的整體置信程度,將其作為最終的對話狀態(tài)判斷依據(jù),如圖5所示。
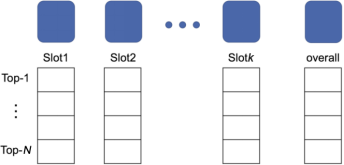
圖5N-Best方式下的對話狀態(tài)與槽位的對應
實現(xiàn)DST模塊的方法主要有:基于條件隨機場模型的序列跟蹤模型、基于RNN和LSTM的序列跟蹤模型等。
3.DPL模塊
DPL模塊的輸入是DST模塊輸出的當前對話狀態(tài)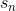 ,通過預設的對話策略,選擇系統(tǒng)動作
,通過預設的對話策略,選擇系統(tǒng)動作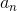 作為輸出。下面結(jié)合具體案例介紹基于規(guī)則的DPL方法,也就是通過人工設計有限狀態(tài)自動機的方法實現(xiàn)DPL。
作為輸出。下面結(jié)合具體案例介紹基于規(guī)則的DPL方法,也就是通過人工設計有限狀態(tài)自動機的方法實現(xiàn)DPL。
案例一:詢問天氣
以有限狀態(tài)自動機的方法進行規(guī)則的設計,有兩種不同的方案:一種以點表示數(shù)據(jù),以邊表示操作;另一種以點表示操作,以邊表示數(shù)據(jù),這兩種方案各有優(yōu)點,在具體實現(xiàn)時可以根據(jù)實際情況進行選擇。
方案一:以點表示數(shù)據(jù)(槽位狀態(tài)),以邊表示操作(系統(tǒng)動作)(如圖6所示)
在這種情況下,有限狀態(tài)自動機中每一個對話狀態(tài)S表示槽位的填充情況,例如槽位均為空時,狀態(tài)為NULL,表示為(0,0);僅時間(Time)槽位被填充時,狀態(tài)表示為(0,1)。本示例中槽位共有兩個,分別為時間和地點(Location),因此共有4種不同的狀態(tài)。
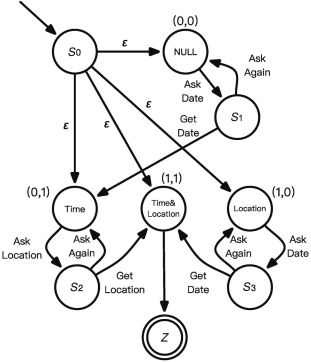
圖6“詢問天氣”有限狀態(tài)自動機設計(1)
狀態(tài)遷移是由系統(tǒng)動作引起的,例如僅時間槽位被填充時,下一步的系統(tǒng)動作為“詢問地點”(AskLocation),以獲取完整的槽位填充。S0為起始狀態(tài),Z為終結(jié)狀態(tài),S1、S2、S3三個狀態(tài)的作用是對槽位填充進行確認。如果成功填充,則跳轉(zhuǎn)到下一個狀態(tài)繼續(xù);如果沒有成功,則再一次詢問進行槽位填充(Ask Again)。
這種方式的弊端非常明顯:隨著槽位數(shù)量的增加,對話狀態(tài)的數(shù)量也會急劇增加。具體來說,在上述方案中,對話狀態(tài)的總數(shù)由槽位的個數(shù)決定,如果槽位有k個,那么對話狀態(tài)的數(shù)量為2k個。嘗試改進這一弊端的研究有很多,如Young S等人提出的隱藏信息狀態(tài)模型(Hidden Information State,HIS)和Thomson B等人提出的基于貝葉斯更新的對話狀態(tài)管理模型(Bayesian Update of Dialogue State,BUDS)等。
方案二:以點表示操作(系統(tǒng)動作),以邊表示數(shù)據(jù)(槽位狀態(tài))(如圖7所示)
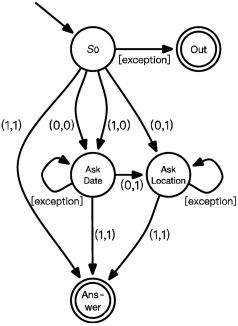
圖7“詢問天氣”有限狀態(tài)自動機設計(2)
在這種情況下,有限狀態(tài)自動機中每一個對話狀態(tài)S表示一種系統(tǒng)動作,本例中系統(tǒng)動作共有3種,分別是兩種問詢動作:“詢問時間”(Ask Date)和“詢問地點”(Ask Location),以及最后的系統(tǒng)回復“回答天氣”(Answer)動作。有限狀態(tài)自動機中狀態(tài)的遷移則是由槽位的狀態(tài)變化,即“用戶動作”引起的。
對比上述兩種方案可以發(fā)現(xiàn),第二種有限狀態(tài)自動機以系統(tǒng)動作為核心,設計方式更簡潔,并且易于工程實現(xiàn),更適合人工設計的方式。第一種有限狀態(tài)自動機以槽位狀態(tài)為核心,枚舉所有槽位情況的做法過于復雜,更適合數(shù)據(jù)驅(qū)動的機器學習方式。
系統(tǒng)動作的定義通常有問詢、確認和回答3種。問詢的目的是了解必要槽位缺失的信息;確認是為了解決容錯性問題,填槽之前向用戶再次確認;回答則是最終回復,意味著任務和有限狀態(tài)自動機工作的結(jié)束。
細心的讀者可能已經(jīng)發(fā)現(xiàn),采取問詢的方式獲得缺失的槽位信息,在一些情況下是不合適的,以“詢問天氣”任務為例,向用戶問詢槽位缺失的信息會大幅降低用戶對系統(tǒng)的滿意度。在真實的業(yè)務環(huán)境下,系統(tǒng)往往會直接采取默認值填充槽位的方式,或者結(jié)合以往的對話歷史數(shù)據(jù),自動填補個性化的結(jié)果。例如,用戶以往問的都是上海的天氣,那么“地點”槽位就會被個性化地填充為“上海”。
這就引出了對面向任務的對話系統(tǒng)的質(zhì)量評估方法:對面向任務的對話系統(tǒng)而言,完成用戶指定任務所需的對話輪數(shù)越少越好。在實際應用中,諸如“詢問天氣”這樣的任務,通常都盡可能地在一次對話中完成,而有些任務則必須要進行多輪對話,例如訂餐、購票等任務。
接下來,我們以“訂餐需求”為例,說明多輪對話的必要性,以及對話輪數(shù)的取舍問題。
案例二:訂餐
在典型的訂餐領域的對話系統(tǒng)中,根據(jù)生活經(jīng)驗,我們知道需要為系統(tǒng)定義以下幾個槽位。
(1)slot1:用戶住址(Address)。
(2)slot2:用戶手機號碼(Phone)。
(3)slot3:訂餐餐廳名稱(Res_name)。
(4)slot4:食物名稱(Food_item)。
(5)slot5:食物類型(Food_type)。
(6)slot6:價格范圍(Price_range)。
其中前4項為必要槽位,對訂餐任務來說是必須提供的參數(shù),最后兩項為非必要槽位,可有可無,有的話可以提高訂餐任務的精準度。參考案例一的處理過程,首先對此任務設計相應的有限狀態(tài)自動機,如圖8所示。
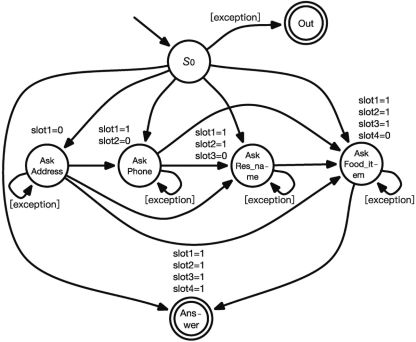
圖8“訂餐”系統(tǒng)有限狀態(tài)自動機設計
可以發(fā)現(xiàn),在該任務下的有限狀態(tài)自動機設計中,我們只加入了必要槽位的問詢操作,沒有對Food_type和Price_range進行強制的系統(tǒng)問詢。兩個非必要槽位能夠?qū)Α癆sk Food_item”,即詢問具體的食物名稱起到輔助作用。當用戶沒有明確需求時,系統(tǒng)可以給出具體的食物推薦,這樣的設定可以有效地減少非必要的對話,減少對話輪數(shù)。
4.NLG模塊
NLG模塊的輸入是DPL模塊輸出的系統(tǒng)動作 ,輸出是系統(tǒng)對用戶輸入
,輸出是系統(tǒng)對用戶輸入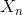 的回復
的回復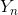 。
。
目前,NLG模塊仍廣泛采用傳統(tǒng)的基于規(guī)則的方法,表1給出了3個示例規(guī)則的定義。根據(jù)規(guī)則可以將各個系統(tǒng)動作映射成自然語言表達。

為了實現(xiàn)回復的多樣性,各種基于深度神經(jīng)網(wǎng)絡的模型方法被提出并得到發(fā)展。
以上是《自然語言處理實踐:聊天機器人技術原理與應用》節(jié)選內(nèi)容。
-
數(shù)據(jù)驅(qū)動
關注
0文章
140瀏覽量
12575 -
模塊化
+關注
關注
0文章
340瀏覽量
21956 -
自然語言
+關注
關注
1文章
291瀏覽量
13650
原文標題:NLP實踐:對話系統(tǒng)技術原理和應用
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
AD7745在使用中,需要進行偏移校準和系統(tǒng)校準嗎?
RFID在工地監(jiān)控中的具體應用

完整版—單片機編程思想(推薦下載!)
NVIDIA大語言模型在推薦系統(tǒng)中的應用實踐

mes系統(tǒng)的功能有哪些?工廠mes系統(tǒng)介紹

村田電容0402在工業(yè)設備中的具體應用

無人機在光伏巡檢中的具體應用
Linux計劃任務介紹
AI對話魔法 Prompt Engineering 探索指南






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論