 FPGA在人工智能時代的獨特優勢的全面分析
FPGA在人工智能時代的獨特優勢的全面分析
作者 | 老石,博士畢業于倫敦帝國理工大學電子工程系,現任某知名半導體公司高級FPGA研發工程師,深耕于FPGA的數據中心網絡加速、網絡功能虛擬化、高速有線網絡通信等領域的研發和創新工作。曾經針對FPGA、高性能與可重構計算等技術在學術界頂級會議和期刊上發表過多篇研究論文。
很多世界頂尖的“建筑師”可能是你從未聽說過的人,他們設計并創造出了很多你可能從未見過的神奇結構,比如在芯片內部源于沙子的復雜體系。如果你使用手機、電腦,或者通過互聯網收發信息,那么你就無時無刻不在受益于這些建筑師們的偉大工作。
Doug Burger博士就是這群“建筑師”里的一員。他現任微軟技術院士(Technical Fellow),曾任微軟研究院杰出工程師、德克薩斯大學奧斯丁分校計算機科學教授。他也是微軟FPGA項目Catapult和Brainwave的首席架構師和主要負責人。2018年,Doug Burger在微軟研究院的播客里分享了他對后摩爾定律時代芯片產業發展的觀點與愿景,并展望了人工智能時代芯片技術的前進方向。
老石對他的觀點進行了整理和采編。本文主要是Doug Burger博士對FPGA在人工智能時代的獨特優勢的全面分析,以及他對于人工智能技術發展的深刻思考。文章很長,但全部是他幾十年從業經驗的深入淺出的闡述,盡顯大師之風,值得一讀。
目 錄
1. 什么是暗硅效應
2. FPGA:解決暗硅效應的有效途徑
3. 使用FPGA的獨特優勢是什么
4. 什么是Catapult項目
5. 腦波項目與實時AI
6. 評價實時AI系統的主要標準
7. AI未來的發展路在何方?
1. 什么是暗硅效應
在我加入微軟之前,我和我的博士生Hadi Esmaeilzadeh正在開展一系列研究工作。他現在已經是加州大學圣地亞哥分校的副教授。在當時,學術界和業界的主要發展趨勢就是多核心架構。雖然尚未完全成為一個正式的全球性共識,但多核架構是當時非常熱門的研究方向。人們認為,如果可以找到編寫和運行并行軟件的方法,我們就能直接將處理器架構擴展到數千個核心。然而,Hadi和我卻對此不以為然。
于是,我們在2011年發表了一篇論文,并因此獲得了很高的知名度。雖然在那篇論文里沒有明確的定義“暗硅(dark silicon)”這個詞,但是它的意義卻得到了廣泛認可。
暗硅效應指的是,雖然我們可以不斷增加處理器核心的數量,但是由于能耗限制,無法讓它們同時工作。就好像一幢大樓里有很多房間,但由于功耗太大,你無法點亮每個房間的燈光,使得這幢大樓在夜里看起來有很多黑暗的部分。這其中的本質原因是在后摩爾定律時代,晶體管的能效發展已經趨于停滯。
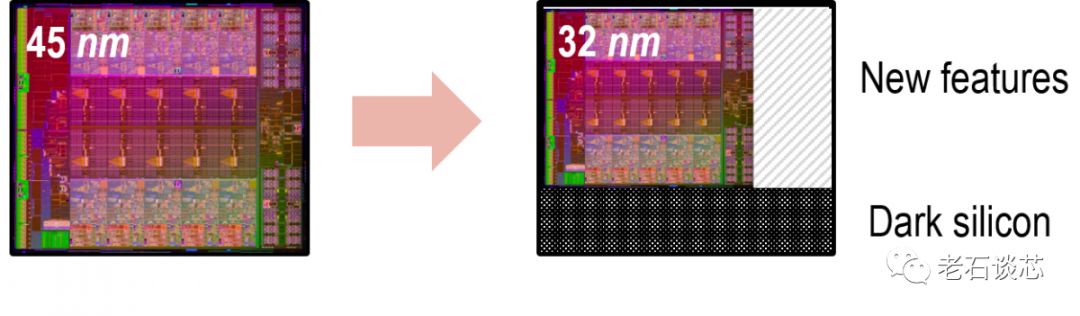
(暗硅示意圖,圖片來自NYU)
這樣,即使人們開發出了并行軟件,并且不斷增加了核心數量,所帶來的性能提升也會比以往要小得多。所以,除此之外,業界還需要在其他方面帶來更多進展,以克服“暗硅”的問題。
2. FPGA:解決暗硅效應的有效途徑
在我看來,一個可行的解決方法就是采用“定制計算”,也就是為特定的工作場景和負載優化硬件設計。然而,定制計算或定制芯片的主要問題就是高昂的成本。例如對于一個復雜的云計算場景,不論是設計者還是使用者都不會采用一個由47000種不同的芯片所組成的系統。
因此,我們將賭注押在了這個名叫FPGA的芯片上。FPGA全名叫“現場可編程邏輯陣列”,它本質是一種可編程的芯片。人們可以把硬件設計重復燒寫在它的可編程存儲器里,從而使FPGA芯片可以執行不同的硬件設計和功能。另外,你也可以在使用現場動態的改變它上面運行的功能,這就是為什么它們被稱作“現場可編程”的原因。事實上,你可以每隔幾秒就改變一次FPGA芯片上運行的硬件設計,因此這種芯片非常靈活。
(英特爾Stratix 10 FPGA芯片,圖片來自英特爾)
基于這些特點,我們在FPGA這項技術上押下重注,并且將其廣泛的部署到了微軟的云數據中心里。與此同時,我們也開始將很多重要的應用和功能,從基于軟件的實現方式,慢慢轉移到基于FPGA的硬件實現方式上。可以說,這是一個非常有趣的計算架構,它也將是我們的基于定制化硬件的通用計算平臺。
通過使用FPGA,我們一方面可以盡早開展定制化計算與定制芯片的研究與設計,另一方面,我們可以保持與現有架構相互兼容的同構性。
如果具體的應用場景或算法發展的太快,或者硬件規模太小的時候,我們可以繼續使用FPGA實現這些硬件功能。當應用規模逐漸擴大時,我們可以在合適的時機,選擇將這些已經成熟的定制化硬件設計直接轉化成定制化芯片,以提高它們的穩定性,降低功耗和成本。
靈活性是FPGA最重要的特點。要知道,FPGA芯片已經在電信領域中得到了非常廣泛的使用。這種芯片非常擅長對數據流進行快速處理,同時也被用于流片前的功能測試等。但是在云計算中,之前并沒有人能夠真正成功的大規模部署FPGA。我指的“部署”,并不是指那些用來作為原型設計或概念驗證的工作,而是指真正的用于工業級使用的部署。
3. 使用FPGA的獨特優勢是什么
首先我想說的是,CPU和GPU都是令人驚嘆的計算機架構,它們是為了不同的工作負載與應用場景而設計的。
CPU是一種非常通用的架構,它的工作方式基于一系列的計算機指令,也稱為“指令集”。簡單來說,CPU從內存中提取一小部分數據,放在寄存器或者緩存中,然后使用一系列指令對這些數據進行操作。操作完畢后,將數據寫回內存,提取另一小部分數據,再用指令進行操作,并周而復始。我把這種計算方式稱為“時域計算”。
不過,如果這些需要用指令進行處理的數據集太大,或者這些數據值太大,那么CPU就不能很高效地應對這種情況。這就是為什么在處理高速網絡流量的時候,我們往往需要使用定制芯片,比如網卡芯片等,而不是CPU。這是因為在CPU中,即使處理一個字節的數據也必須使用一堆指令才能完成,而當數據流以每秒125億字節進入系統時,這種處理方式哪怕使用再多的線程也忙不過來。
對于GPU來說,它所擅長的是被稱作“單指令多數據流(SIMD)”的并行處理。這種處理方式的本質是,在GPU中有著一堆相同的計算核心,可以處理類似但并不是完全相同的數據集。因此,可以使用一條指令,就讓這些計算核心執行相同的操作,并且平行的處理所有數據。
然后對于FPGA而言,它實際上是CPU計算模型的轉置。與其將數據鎖定在架構上,然后使用指令流對其處理,FPGA將“指令”鎖定在架構上,然后在上面運行數據流。
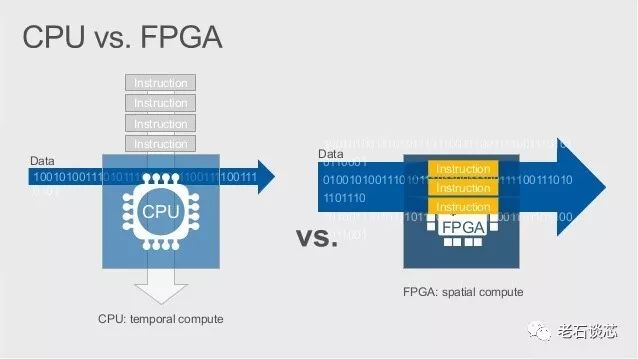
(CPU與FPGA計算模型的對比,圖片來自微軟)
我把這種計算方式稱為“結構計算”,也有人稱之為“空間計算”,與CPU的“時域計算”模型相對應。其實叫什么名稱都無所謂,但它的核心思想是,將某種計算架構用硬件電路實現出來,然后持續的將數據流輸入系統,并完成計算。在云計算中,這種架構對于高速傳輸的網絡數據非常有效,并且對于CPU來說也是一個很好的補充。
4. 什么是Catapult項目
Catapult項目的主要目的是在微軟的云數據中心大規模部署FPGA。雖然這個項目涵蓋了電路和系統架構設計等工程實踐,但它的本質還是一個研究項目。
在2015年末,我們開始在微軟購買的幾乎每臺新服務器上部署Catapult FPGA板卡。這些服務器被用于微軟的必應搜索、Azure云服務以及其他應用。到目前為止,我們已經發展到了非常大的規模,FPGA已經在世界范圍內被大規模部署。這也使得微軟成為了世界上最大的FPGA客戶之一。
(Catapult FPGA板卡,圖片來自微軟)
在微軟內部,很多團隊都在使用Catapult FPGA來增強自己的服務。同時,我們使用FPGA對云計算的諸多網絡功能進行加速,這樣我們的客戶會得到比以往更加快速、穩定、安全的云計算和網絡服務。比如,當網絡數據包以每秒500億比特的速度進行傳輸時,我們可以使用FPGA對這些數據包進行控制、分類和改寫。相反的,如果我們使用CPU來做這些事情的話,將需要海量的CPU內核資源。因此,對于我們這樣的應用場景,FPGA是一個更好的選擇。
(微軟的FPGA板卡,圖片來自微軟)
5. 腦波項目與實時AI
當前,人工智能有了很大的發展,而這很大程度上歸功于深度學習技術的發展。人們逐漸認識到,當你有了深度學習算法、模型,并構建了深度神經網絡時,需要足夠多的數據去訓練這個網絡。只有加入更多的數據,才會讓深度神經網絡變的更大、更好。通過使用深度學習,我們在很多傳統的AI領域取得了長足的進展,比如機器翻譯、語音識別、計算機視覺等等。同時,深度學習也可以逐步替換這些領域發展多年的專用算法。
這些巨大的發展和變革,促使我思考它們對半導體和芯片架構的影響。于是,我們開始重點布局針對AI、機器學習、特別是深度學習的定制化硬件架構,這也就是腦波項目(Project Brainwave)產生的主要背景。
在腦波項目里,我們提出了一種深度神經網絡處理器,也有人稱之為神經處理單元,或者NPU(Neural Processing Unit)。對于像必應搜索這樣的應用來說,他們需要很強的計算能力,因為只有不斷學習和訓練,才能向用戶提供更優的搜索結果。因此,我們將大的深度神經網絡利用FPGA進行加速,并在很短的時間內返回結果。目前,這種計算架構已經在全球范圍內運行了一段時間。在2018年的微軟開發者大會上,我們正式發布了腦波項目在Azure云服務上的預覽版。我們也為一些用戶提供帶有FPGA的板卡,使他們可以使用自己公司的服務器,從Azure上獲取AI模型并運行。
(Brainwave FPGA板卡,圖片來自微軟)
對于腦波項目來說,另外一個非常重要的問題在于神經網絡的推斷。目前的很多技術使用的是一種叫做批處理的方法。比如說,你需要將很多個不同的請求收集到一起,然后打包發送到NPU進行處理,然后一次性得到所有的答案。
對于這種情形,我經常把它比喻成你在銀行里排隊,你排在第二個,但總共有100個人排隊。出納員將所有人的信息收集起來,并詢問每個人想要辦什么業務,然后取錢存錢,再把錢和收據發給每個人。這樣每個人的業務都在同一時刻完成,而這就是所謂的批處理。
對于批處理應用來說,可以達到很好的吞吐量,但是往往會有很高的延時。這就是我們為什么在嘗試推動實時AI的發展。
6. 評價實時AI系統的主要標準
評價實時AI的主要性能指標之一,就是延時的大小。然而,延時到底多小才算“夠小”,這更像是一個哲學問題。事實上,這取決于具體的應用場景。比如,如果在網絡上監控并接收多個信號,并從中分析哪個地方發生了緊急情況,那么幾分鐘的時間就算夠快了。然而,如果你正在和某人通過網絡進行交談,哪怕是非常小的延時和卡頓也會影響通話質量,就像很多電視直播采訪里經常出現的兩個人在同時講話那樣。
另外一個例子是,微軟的另一項人工智能技術是所謂的HPU,它被用于HoloLens設備中。HoloLens是一款智能眼鏡,它能提供混合現實和增強現實等功能,它里面的HPU也具備神經網絡的處理功能。
(宇航員Scott Kelly在國際空間站上使用HoloLens,圖片來自NASA)
對于HPU,它需要實時分析使用者周圍的環境,這樣才能在你環顧四周時,無縫的展示虛擬現實的內容。因此在這種情況下,即使延時只有幾個毫秒,也會對使用者的體驗造成影響。
除了速度之外,另一個需要考慮的重要因素就是成本。舉例來說,如果你希望通過處理數十億張圖像或數百萬行文本,進而分析和總結出人們常問的問題或者可能在尋找的答案,就像很多搜索引擎做的那樣;抑或是醫生想要從很多放射掃描影像中尋找潛在的癌癥指征,那么對于這些類型的應用來說,服務成本就非常重要。在很多情況下,我們需要權衡以下兩點,一個是系統的處理速度有多快,或者通過何種方式能提升處理速度;另一個就是對于每個服務請求或處理,它的成本有多少。
很多情況下,增加系統的處理速度勢必代表著更多的投入和成本的攀升,兩者很難同時滿足。但這就是腦波項目的主要優勢所在,通過使用FPGA,我認為我們在這兩個方面都處于非常有利的位置。在性能方面我們是最快的,在成本上我們大概率也是最便宜的。
7. AI未來的發展路在何方?
說實話,我一點也不擔心人工智能的末日。相比任意一種現有的生物系統的智能,人工智能的效率還差著成千上萬倍的距離。可以說,我們現在的AI其實并不算怎么“智能”。另外,我們也需要在道德層面關注和掌控AI的發展。
不管怎樣,我們的工作從某種程度上提高了計算的效率,這使得它可以用來幫助解決重大的科學問題,我對此有很強的成就感。
對于那些正在考慮從事硬件系統和計算機架構研究的人來說,最重要的就是找到那顆能讓你充滿激情并為之不懈奮斗的“北極星”,然后不顧一切的為之努力。一定要找到那種打了雞血的感覺,不用擔心太多諸如職業規劃、工作選擇等問題,要相信車到山前必有路。你在做的工作,應該能讓你感受到它真正能帶來變革,并幫助你在變革的道路上不斷前行。
當前,人們已經開始意識到,在我說的這些“后·馮諾依曼時代”的異構加速器之外,還有遠比這些更加深刻的東西等待我們探尋。我們已經接近了摩爾定律的終點,而基于馮諾依曼體系的計算架構也已經存在了相當長的時間。自從馮諾依曼在上世紀四十年代發明了這種計算架構以來,它已經取得了驚人的成功。
但是現在,除了這種計算結構外,又產生了各種硬件加速器,以及許多人們正在開發的新型架構,但是從整體上來看,這些新結構都處在一個比較混亂的狀態。
我認為,在這個混亂的表象之下,還隱藏著更加深刻的真理,而這將會是人們在下個階段的最重要發現,這也是我目前經常在思考的問題。
我慢慢發現,那些可能已經普遍存在的東西會是計算架構的下一個巨大飛躍。當然,我也可能完全錯了,但這就是科學研究的樂趣所在。
-
FPGA
+關注
關注
1629文章
21729瀏覽量
603012 -
存儲器
+關注
關注
38文章
7484瀏覽量
163765 -
人工智能
+關注
關注
1791文章
47183瀏覽量
238265
原文標題:FPGA在人工智能時代的獨特優勢
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
FPGA在人工智能中的應用有哪些?
risc-v在人工智能圖像處理應用前景分析
人工智能是什么?
人工智能的前世今生 引爆人工智能大時代
百度人工智能大神離職,人工智能的出路在哪?
人工智能到底用 GPU?還是用 FPGA?
數據對人工智能發展的重要性
人工智能的影響超乎你想象
請問FPGA在人工智能時代有哪些獨特的優勢?
人工智能芯片是人工智能發展的
《移動終端人工智能技術與應用開發》人工智能的發展與AI技術的進步
CPU在人工智能應用中有什么獨特優勢?






 工商網監
工商網監
評論