 無人駕駛方面的優秀論文,一起來看看該領域最前沿的研究課題
無人駕駛方面的優秀論文,一起來看看該領域最前沿的研究課題
近日,CVPR 2019發布接收論文ID列表,共計1300篇論文被接收,接受率為25.2%。本文整理了無人駕駛方面的優秀論文,一起來看看該領域最前沿的研究課題。
CVPR 是首屈一指的年度計算機視覺盛會,在機器學習領域享有盛名。今年的 CVPR 將于 6 月 16 日-20 日于美國加州的長灘市舉行。
CVPR 作為計算機視覺領域的頂級學術會議,今年共收到了 5165 篇有效提交論文,比去年 CVPR2018 增加了 56%。不久之前,CVPR 2019 官網放出了最終的論文接收結果。據統計,本屆大會共接收了 1300 論文,接收率接近 25.2%。本文智車科技整理了本屆會議上與無人駕駛相關的優秀論文及項目,并附有下載鏈接。
1.
題目:Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving(偽激光雷達)
作者:Yan Wang, Wei-Lun Chao, Divyansh Garg, Bharath Hariharan, Mark Campbell, Kilian Q. Weinberger論文鏈接:https://arxiv.org/abs/1812.07179項目鏈接:https://mileyan.github.io/pseudo_lidar/代碼鏈接:https://github.com/mileyan/pseudo_lidar
摘要:3D物體檢測是自動駕駛中的基本任務。如果從精確但昂貴的LiDAR技術獲得3D輸入數據,則最近的技術具有高度準確的檢測率。迄今為止,基于較便宜的單目或立體圖像數據的方法導致精度顯著降低 - 這種差距通常歸因于基于圖像的深度估計不良。然而,在本文中,我們認為數據表示(而不是其質量)占據了差異的大部分。考慮到卷積神經網絡的內部工作原理,我們建議將基于圖像的深度圖轉換為偽LiDAR表示 - 基本上模仿LiDAR信號。通過這種表示,我們可以應用不同的現有基于LiDAR的檢測算法。在流行的KITTI基準測試中,我們的方法在現有的基于圖像的性能方面取得了令人印象深刻的改進 - 提高了30米范圍內物體的檢測精度,從先前的22%到現在的前所未有的74% 。在提交時,我們的算法在KITTI 3D對象檢測排行榜上保持最高條目,用于基于立體圖像的方法。
2.
題目:ApolloCar3D: A Large 3D Car Instance Understanding Benchmark for Autonomous Driving(數據集)
作者:Xibin Song, Peng Wang, Dingfu Zhou, Rui Zhu, Chenye Guan, Yuchao Dai, Hao Su, Hongdong Li, Ruigang Yang論文鏈接:https://arxiv.org/abs/1811.12222
摘要:自動駕駛引起了業界和學術界的極大關注。一個重要的任務是估計道路上移動或停放的車輛的3D特性(例如,翻譯,旋轉和形狀)。這項任務雖然至關重要,但在計算機視覺領域仍未得到充分研究 - 部分原因在于缺乏適合自動駕駛研究的大規模和完全注釋的3D汽車數據庫。在本文中,我們貢獻了第一個適合3D汽車實例理解的大型數據庫 - ApolloCar3D。該數據集包含5,277個駕駛圖像和超過60K的汽車實例,其中每輛汽車都配備了具有絕對模型尺寸和語義標記關鍵點的行業級3D CAD模型。該數據集比PASCAL3D +和KITTI(現有技術水平)大20倍以上。為了在3D中實現高效標記,我們通過考慮單個實例的2D-3D關鍵點對應關系和多個實例之間的3D關系來構建管道。配備這樣的數據集,我們使用最先進的深度卷積神經網絡構建各種基線算法。具體來說,我們首先使用預先訓練的Mask R-CNN對每輛車進行分段,然后基于可變形的3D汽車模型,使用或不使用語義關鍵點,對其3D姿勢和形狀進行回歸。研究表明,使用關鍵點可以顯著提高擬合性能。最后,我們開發了一個新的3D度量,共同考慮3D姿勢和3D形狀,允許進行全面的評估和消融研究。
3.
題目:SR-LSTM: State Refinement for LSTM towards Pedestrian Trajectory Prediction(行人預測)
作者:Pu Zhang, Wanli Ouyang, Pengfei Zhang, Jianru Xue, Nanning Zheng
論文鏈接:https://arxiv.org/abs/1903.02793
摘要:在人群場景中,行人的可靠軌跡預測需要深刻理解他們的社交行為。大量研究已經很好地研究了這些行為,而規則很難充分表達。最近基于LSTM網絡的研究表明,學習社交行為的能力很強。然而,這些方法中的許多方法依賴于先前的相鄰隱藏狀態,但忽略了鄰居的重要當前意圖。為了解決這個問題,我們提出了一個用于LSTM網絡(SR-LSTM)的數據驅動狀態細化模塊,它激活了對鄰居當前意圖的利用,并共同和迭代地改進了人群中所有參與者的當前狀態。通過消息傳遞機制。為了有效地提取鄰居的社會影響,我們進一步介紹了一種社會意識信息選擇機制,包括逐元素運動門和行人注意力,以便從鄰近的行人中選擇有用的信息。兩個公共數據集(即ETH和UCY)的實驗結果證明了我們提出的SR-LSTM的有效性,并且我們實現了最先進的結果。
4.
題目:Selective Sensor Fusion for Neural Visual-Inertial Odometry(視覺慣性測距)
作者:Changhao Chen,Stefano Rosa,Yishu Miao,Chris Xiaoxuan Lu,Wei Wu,Andrew Markham,Niki Trigoni
論文鏈接:https://arxiv.org/abs/1903.01534
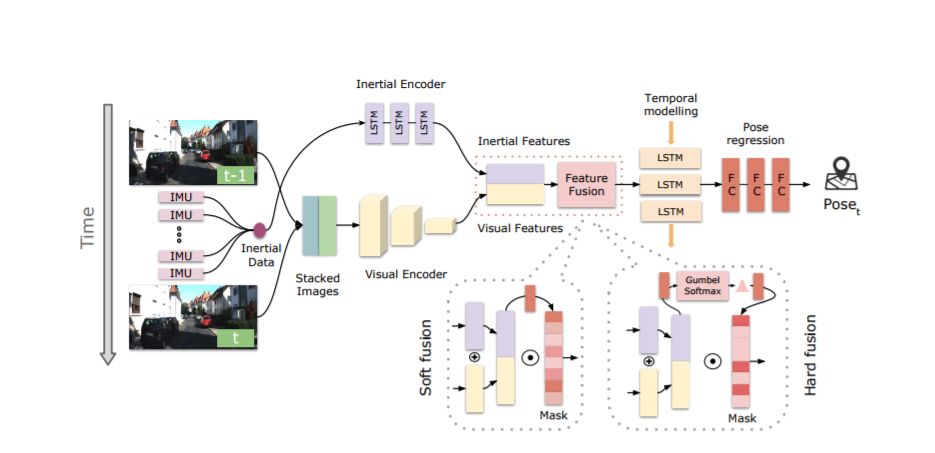
摘要:視覺慣性測距(VIO)的深度學習方法已被證明是成功的,但他們很少專注于結合穩健的融合策略來處理不完美的輸入感覺數據。我們提出了一種新穎的端對端選擇性傳感器融合框架,用于單眼VIO,融合單眼圖像和慣性測量,以估計軌跡,同時提高對實際問題的魯棒性,如丟失和損壞的數據或不良的傳感器同步。特別地,我們提出了兩種基于不同掩蔽策略的融合模態:確定軟性融合和隨機硬融合,并與先前提出的直接融合基線進行比較。在測試期間,網絡能夠選擇性地處理可用傳感器模態的特征并且產生大規模的軌跡。我們對三種公共自動駕駛,微型飛行器(MAV)和手持VIO數據集的性能進行了全面調查。結果證明了融合策略的有效性,與直接融合相比,其提供了更好的性能,特別是在存在損壞的數據的情況下。此外,我們通過可視化不同場景中的掩蔽層和不同的數據損壞來研究融合網絡的可解釋性,揭示融合網絡與不完美的傳感輸入數據之間的有趣相關性。
5.
題目:DeepMapping: Unsupervised Map Estimation From Multiple Point Clouds作者:Li Ding, Chen Feng論文鏈接:https://arxiv.org/abs/1811.11397項目鏈接:https://ai4ce.github.io/DeepMapping/
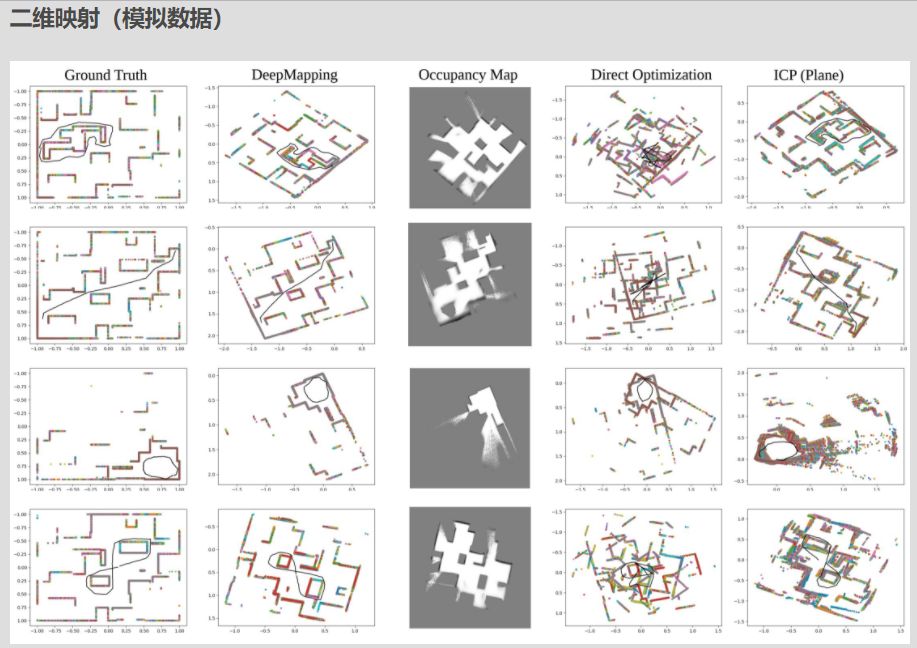
摘要:我們提出DeepMapping,一種新穎的注冊框架,使用深度神經網絡(DNN)作為輔助功能,將多點云從頭開始對齊到全局一致的幀。我們使用DNN來模擬高度非凸映射過程,該過程傳統上涉及手工制作的數據關聯,傳感器姿態初始化和全局細化。我們的關鍵新穎之處在于,正確定義無監督損失以通過反向傳播來“訓練”這些DNN等同于解決基礎注冊問題,但是對ICP的要求實現良好初始化的依賴性更小。我們的框架包含兩個DNN:一個估計輸入點云姿態的本地化網絡,以及一個通過估計全局坐標的占用狀態來模擬場景結構的地圖網絡。這允許我們將配準問題轉換為二進制占用分類,這可以使用基于梯度的優化來有效地解決。我們進一步表明,通過在連續點云之間施加幾何約束,可以很容易地擴展DeepMapping以解決激光雷達SLAM的問題。在模擬和真實數據集上進行實驗。定性和定量比較表明,與現有技術相比,DeepMapping通常能夠實現更加穩健和準確的多點云全局注冊。在模擬和真實數據集上進行實驗。定性和定量比較表明,與現有技術相比,DeepMapping通常能夠實現更加穩健和準確的多點云全局注冊。在模擬和真實數據集上進行實驗。定性和定量比較表明,與現有技術相比,DeepMapping通常能夠實現更加穩健和準確的多點云全局注冊。
6.
題目:Stereo R-CNN based 3D Object Detection for Autonomous Driving
作者:Peiliang Li, Xiaozhi Chen, Shaojie Shen
研究機構:香港科技大學、大疆
論文下載鏈接:
https://arxiv.org/abs/1902.09738
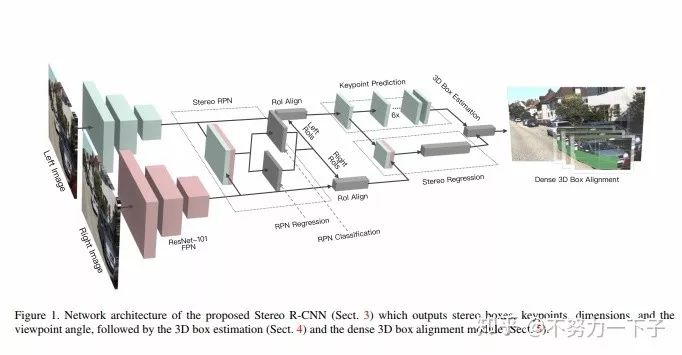
摘要 :我們通過充分利用立體圖像中的稀疏,密集,語義和幾何信息,提出了一種用于自動駕駛的三維物體檢測方法。 我們的方法,稱為Stereo R-CNN,擴展了更快的R-CNN用于立體聲輸入,以同時檢測和關聯左右圖像中的對象。 我們在立體聲區域提議網絡(RPN)之后添加額外分支來預測稀疏關鍵點,視點和對象維度,這些關鍵點與2D左右框組合以計算粗略的3D對象邊界框。 然后,我們通過使用左右RoI的基于區域的光度對準來恢復精確的3D邊界框。 我們的方法不需要深度輸入和3D位置監控,但是,優于所有現有的完全監督的基于圖像的方法。 在具有挑戰性的KITTI數據集上的實驗表明,我們的方法在3D檢測和3D定位任務上的性能優于最先進的基于立體的方法約30%AP。
7.
題目:Group-wise Correlation Stereo Network
作者:Xiaoyang Guo,Kai Yang,Wukui Yang,Xiaogang Wang,Hongsheng Li
團隊:香港中文大學電子工程系、商湯科技
論文鏈接:https://arxiv.org/abs/1903.04025
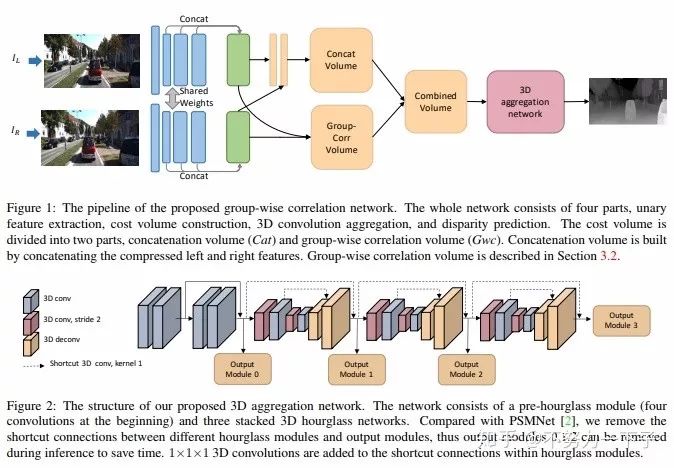
摘要:立體匹配估計整流圖像對之間的差異,這對深度感測、自動駕駛和其他相關任務非常重要。先前的工作建立了在所有視差水平上具有交叉相關或串聯左右特征的成本量,然后利用2D或3D卷積神經網絡來回歸視差圖。在本文中,我們建議通過分組相關來構建成本量。左邊特征和右邊特征沿著通道維度被分成組,并且在每個組之間計算相關圖以獲得多個匹配成本提議,然后將其打包到成本量中。分組相關為測量特征相似性提供了有效的表示,并且不會丟失過多的信息,如完全相關。與以前的方法相比,它在減少參數時也能保持更好的性能。在先前的工作中提出的3D堆疊沙漏網絡被改進以提高性能并降低推理計算成本。實驗結果表明,我們的方法在Scene Flow,KITTI 2012和KITTI 2015數據集上優于以前的方法。此代碼可通過xy-guo/GwcNet(代碼待更新)獲得。
8.
題目:Hierarchical Discrete Distribution Decomposition for Match Density Estimation研究結構:伯克利DeepDrive作者:Zhichao Yin
論文鏈接:https://arxiv.org/abs/1812.06264
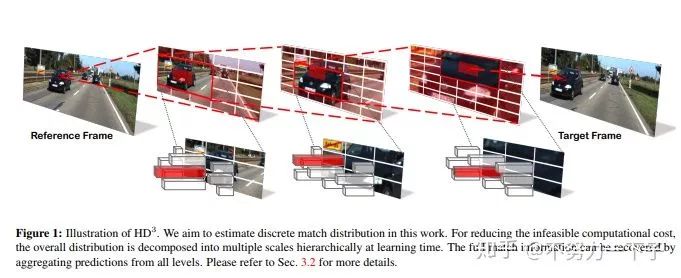
摘要:用于像素對應的現有深度學習方法輸出運動場的點估計,但不表示完全匹配分布。匹配分布的顯式表示對于許多應用是期望的,因為它允許直接表示對應概率。使用深度網絡估計全概率分布的主要困難是推斷整個分布的高計算成本。在本文中,我們提出了分層離散分布分解,稱為HD3,以學習概率點和區域匹配。它不僅可以模擬匹配不確定性,還可以模擬區域傳播。為了實現這一點,我們估計了不同圖像尺度下像素對應的層次分布,而沒有多假設集合。盡管它很簡單,但我們的方法可以在既定基準上實現光流和立體匹配的競爭結果,而估計的不確定性是錯誤的良好指標。此外,即使區域在圖像上變化,也可以將區域內的點匹配分布組合在一起以傳播整個區域。
9.
題目:Deep Rigid Instance Scene Flow
研究機構:Uber ATG部門、MIT、多倫多大學
作者:Wei-Chiu Ma、Shenlong Wang 、Rui Hu、Yuwen Xiong、 Raquel Urtasun
論文鏈接:
https://people.csail.mit.edu/weichium/papers/cvpr19-drisf/paper.pdf
摘要:在本文中,我們解決了自動駕駛環境下的場景流量估計問題。 我們利用深度學習技術以及強大的先驗,因為在我們的應用領域中,場景的運動可以由機器人的運動和場景中的演員的3D運動來組成。 我們將問題表達為深度結構化模型中的能量最小化,這可以通過展開高斯 - 牛頓求解器在GPU中有效地求解。 我們在具有挑戰性的KITTI場景流數據集中的實驗表明,我們以超大的優勢超越了最先進的技術,同時快了800倍。
10.
題目:MagicVO: End-to-End Monocular Visual Odometry through Deep Bi-directional Recurrent Convolutional Neural Network(單目視覺測距)
作者:Jian Jiao,Jichao Jiao,Yaokai Mo,Weilun Liu,Zhongliang Deng
研究結構:北郵
論文鏈接:https://arxiv.org/abs/1811.10964
摘要:本文提出了一種解決單眼視覺測距問題的新框架,稱為MagicVO。 基于卷積神經網絡(CNN)和雙向LSTM(Bi-LSTM),MagicVO在攝像機的每個位置輸出6-DoF絕對標度姿勢,并以一系列連續單目圖像作為輸入。 它不僅利用CNN在圖像特征處理中的出色表現,充分提取圖像幀的豐富特征,而且通過Bi-LSTM從圖像序列前后學習幾何關系,得到更準確的預測。 MagicVO的管道如圖1所示.MagicVO系統是端到端的,KITTI數據集和ETH-asl cla數據集的實驗結果表明MagicVO比傳統的視覺測距具有更好的性能( VO)系統在姿態的準確性和泛化能力方面。
11.
題目:SSA-CNN: Semantic Self-Attention CNN for Pedestrian Detection
作者:Chengju Zhou,Meiqing Wu,Siew-Kei Lam研究機構:南洋理工大學
論文鏈接:https://arxiv.org/abs/1902.09080v1
摘要:行人檢測在諸如自動駕駛的許多應用中起著重要作用。我們提出了一種方法,將語義分割結果作為自我關注線索進行探索,以顯著提高行人檢測性能。具體而言,多任務網絡被設計為從具有弱框注釋的圖像數據集聯合學習語義分割和行人檢測。語義分割特征圖與相應的卷積特征圖連接,為行人檢測和行人分類提供更多的辨別特征。通過聯合學習分割和檢測,我們提出的行人自我關注機制可以有效識別行人區域和抑制背景。此外,我們建議將來自多尺度層的語義注意信息結合到深度卷積神經網絡中以增強行人檢測。實驗結果表明,該方法在Caltech數據集上獲得了6.27%的最佳檢測性能,并在CityPersons數據集上獲得了競爭性能,同時保持了較高的計算效率。
-
計算機視覺
+關注
關注
8文章
1700瀏覽量
46059 -
論文
+關注
關注
1文章
103瀏覽量
14971 -
自動駕駛
+關注
關注
784文章
13915瀏覽量
166774
原文標題:CVPR 2019 無人駕駛相關論文合集(附下載鏈接)
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
中國最大露天礦無人駕駛項目驗收成功
小馬智行第六代無人駕駛Robotaxi亮相香港國際機場
磁致伸縮位移傳感器的品牌有哪些?一起來看看吧!

飛騰榮獲“2024年度十佳卓越課題”及“2024年度優秀課題”獎項
首鋼水廠鐵礦無人駕駛礦卡實現常態化無人運行
UWB模塊如何助力無人駕駛技術
特斯拉推出無人駕駛Model Y
選2088還是3051?一起來說說TA們的不同~

5G賦能車聯網,無人駕駛引領未來出行

無人駕駛汽車應用晶振TSX-3225

中國或支持特斯拉測試無人駕駛出租
無人機反制技術在公共安全領域的應用
吉利完成全球首個汽車無人駕駛漂移,擬明年啟用AI數字底盤技術
5G車載路由器引領無人駕駛車聯網應用






 工商網監
工商網監
評論