 機器學習從業者指出了一個明顯的問題:你如何調試模型?
機器學習從業者指出了一個明顯的問題:你如何調試模型?
當你花了幾個星期構建一個數據集、編碼一個神經網絡并訓練好了模型,然后發現結果并不理想,接下來你會怎么做?
深度學習通常被視為一個黑盒子,我并不反對這種觀點——但是你能講清楚學到的上萬參數的意義嗎?
但是黑盒子的觀點為機器學習從業者指出了一個明顯的問題:你如何調試模型?
在這篇文章中,我將會介紹一些我們在 Cardiogram 中調試 DeepHeart 時用到的技術,DeepHeart 是使用來自 Apple Watch、 Garmin、和 WearOS 的數據預測疾病的。
在 Cardiogram 中,我們認為構建 DNN 并不是煉金術,而是工程學。

你的心臟暴露了很多你的信息。DeepHeart 使用來自 Apple Watch、 Garmin、和 WearOS 的心率數據來預測你患糖尿病、高血壓以及睡眠窒息癥(sleep apnea)的風險。
一、預測合成輸出
通過預測根據輸入數據構建的合成輸出任務來測試模型能力。
我們在構建檢測睡眠窒息癥的模型時使用了這個技術。現有關于睡眠窒息癥篩查的文獻使用日間和夜間心率標準差的差異作為篩查機制。因此我們為每周的輸入數據創建了合成輸出任務:
標準差 (日間心率)—標準差 (夜間心率)
為了學習這個函數,模型要能夠:
1. 區分白天和黑夜
2. 記住過去幾天的數據
這兩個都是預測睡眠窒息癥的先決條件,所以我們使用新架構進行實驗的第一步就是檢查它是否能學習這個合成任務。
你也可以通過在合成任務上預訓練網絡,以半監督的形式來使用類似這樣的合成任務。當標記數據很稀缺,而你手頭有大量未標記數據時,這種方法很有用。
二、可視化激活值
理解一個訓練好的模型的內部機制是很難的。你如何理解成千上萬的矩陣乘法呢?
在這篇優秀的 Distill 文章《Four Experiments in Handwriting with a Neural Network》中,作者通過在熱圖中繪制單元激活值,分析了手寫模型。我們發現這是一個「打開 DNN 引擎蓋」的好方法。
我們檢查了網絡中幾個層的激活值,希望能夠發現一些語義屬性,例如,當用戶在睡覺、工作或者焦慮時,激活的單元是怎樣的?
用 Keras 寫的從模型中提取激活值的代碼很簡單。下面的代碼片段創建了一個 Keras 函數 last_output_fn,該函數在給定一些輸入數據的情況下,能夠獲得一層的輸出(即它的激活值)。
fromkerasimportbackendasKdefextract_layer_output(model,layer_name,input_data):layer_output_fn=K.function([model.layers[0].input],[model.get_layer(layer_name).output])layer_output=layer_output_fn([input_data])#layer_output.shapeis(num_units,num_timesteps)returnlayer_output[0]
我們可視化了網絡好幾層的激活值。在檢查第二個卷積層(一個寬為 128 的時間卷積層)的激活值時,我們注意到了一些奇怪的事:
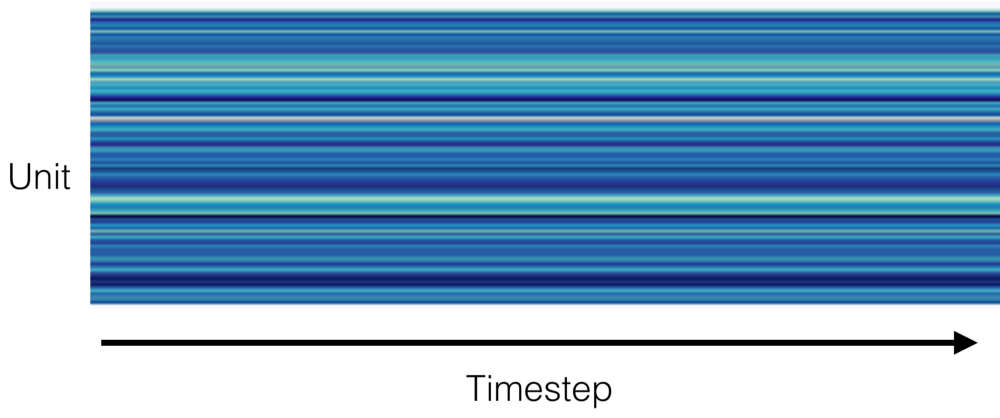
卷積層的每個單元在每個時間步長上的激活值。藍色的陰影代表的是激活值。
激活值竟然不是隨著時間變化的!它們不受輸入值影響,被稱為「死神經元」。
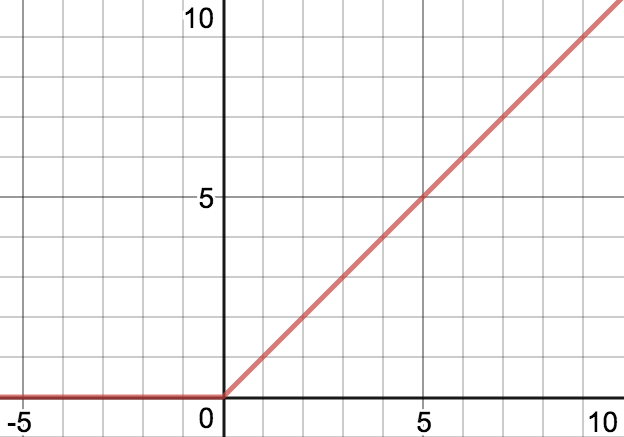
ReLU 激活函數,f(x) = max(0, x)
這個架構使用了 激活函數,當輸入是負數的時候它輸出的是 0。盡管它是這個神經網絡中比較淺的層,但是這確實是實際發生的事情。
在訓練的某些時候,較大的梯度會把某一層的所有偏置項都變成負數,使得 ReLU 函數的輸入是很小的負數。因此這層的輸出就會全部為 0,因為對小于 0 的輸入來說,ReLU 的梯度為零,這個問題無法通過來解決。
當一個卷積層的輸出全部為零時,后續層的單元就會輸出其偏置項的值。這就是這個層每個單元輸出一個不同值的原因——因為它們的偏置項不同。
我們通過用 Leaky ReLU 替換 ReLU 解決了這個問題,前者允許梯度傳播,即使輸入為負時。
我們沒想到會在此次分析中發現「死神經元」,但最難找到的錯誤是你沒打算找的。
三、梯度分析
梯度的作用當然不止是優化損失函數。在梯度下降中,我們計算與Δparameter 對應的Δloss。盡管通常意義上梯度計算的是改變一個變量對另一個變量的影響。由于梯度計算在梯度下降方法中是必需的,所以像 TensorFlow 這樣的框架都提供了計算梯度的函數。
我們使用梯度分析來確定我們的深度神經網絡能否捕捉數據中的長期依賴。DNN 的輸入數據特別長:4096 個時間步長的心率或者計步數據。我們的模型架構能否捕捉數據中的長期依賴非常重要。例如,心率的恢復時間可以預測糖尿病。這就是鍛煉后恢復至休息時的心率所耗的時間。為了計算它,深度神經網絡必須能夠計算出你休息時的心率,并記住你結束鍛煉的時間。
衡量模型能否追蹤長期依賴的一種簡單方法是去檢查輸入數據的每個時間步長對輸出預測的影響。如果后面的時間步長具有特別大的影響,則說明模型沒有有效地利用早期數據。
對于所有時間步長 t,我們想要計算的梯度是與Δinput_t 對應的Δoutput。下面是用 Keras 和 TensorFlow 計算這個梯度的代碼示例:
defgradient_output_wrt_input(model,data):#[:,2048,0]meansallusersinbatch,midpointtimestep,0thtask(diabetes)output_tensor=model.model.get_layer('raw_output').output[:,2048,0]#output_tensor.shape==(num_users)#Averageoutputoverallusers.Resultisascalar.output_tensor_sum=tf.reduce_mean(output_tensor)inputs=model.model.inputs#(num_usersxnum_timestepsxnum_input_channels)gradient_tensors=tf.gradients(output_tensor_sum,inputs)#gradient_tensors.shape==(num_usersxnum_timestepsxnum_input_channels)#Averageoverusersgradient_tensors=tf.reduce_mean(gradient_tensors,axis=0)#gradient_tensors.shape==(num_timestepsxnum_input_channels)#eggradient_tensor[10,0]isderivoflastoutputwrt10thinputheartrate#ConverttoKerasfunctionk_gradients=K.function(inputs=inputs,outputs=gradient_tensors)#Applyfunctiontodatasetreturnk_gradients([data.X])
在上面的代碼中,我們在平均池化之前,在中點時間步長 2048 處計算了輸出。我們之所以使用中點而不是最后的時間步長的原因是,我們的 LSTM 單元是雙向的,這意味著對一半的單元來說,4095 實際上是第一個時間步長。我們將得到的梯度進行了可視化:
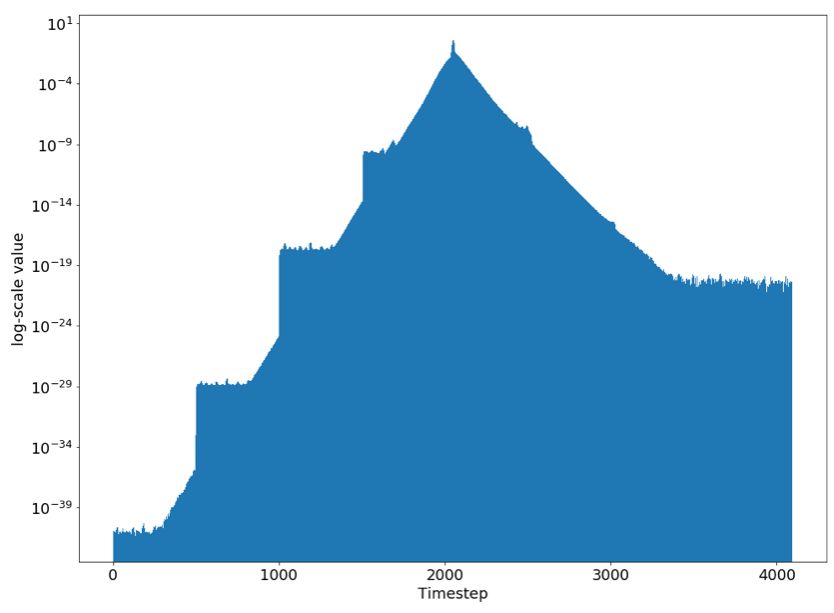
Δoutput_2048 / Δinput_t
請注意我們的 y 軸是 log 尺度的。在時間步長 2048 處,與輸入對應的輸出梯度是 0.001。但是在時間步長 2500 處,對應的梯度小了一百萬倍!通過梯度分析,我們發現這個架構無法捕捉長期依賴。
四、分析模型預測
你可能已經通過觀察像 AUROC 和平均絕對誤差這樣的指標分析了模型預測。你還可以用更多的分析來理解模型的行為。
例如,我們好奇 DNN 是否真的用心率輸入來生成預測,或者說它的學習是不是嚴重依賴于所提供的元數據——我們用性別、年齡這樣的用戶元數據來初始化 LSTM 的狀態。為了理解這個,我們將模型與在元數據上訓練的 logistic 回歸模型做了對比。
DNN 模型接收了一周的用戶數據,所以在下面的散點圖中,每個點代表的是一個用戶周。

這幅圖驗證了我們的猜想,因為預測結果并不是高度相關的。
除了進行匯總分析,查看最好和最壞的樣本也是很有啟發性的。對一個二分類任務而言,你需要查看最令人震驚的假陽性和假陰性(也就是預測距離標簽最遠的情況)。嘗試鑒別損失模式,然后過濾掉在你的真陽性和真陰性中出現的這種模式。
一旦你對損失模式有了假設,就通過分層分析進行測試。例如,如果最高損失全部來自第一代 Apple Watch,我們可以用第一代 Apple Watch 計算我們的調優集中用戶集的準確率指標,并將這些指標與在剩余調優集上計算的指標進行比較。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100720 -
機器學習
+關注
關注
66文章
8408瀏覽量
132575 -
數據集
+關注
關注
4文章
1208瀏覽量
24691
原文標題:你用什么方法調試深度神經網絡?這里有四種簡單的方式哦
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
10個問題及答案保障LED從業者用電安全
軟件測試從業者需要具備哪些技能
軟件測試從業者需要具備哪些技能
機器學習從業者工具使用方面大數據分析

NVIDIA持續助力AI教育及研究從業者
機器學習的12大經驗總結
谷歌發布機器學習框架:一個名叫NSL的神經結構學習框架
AI繪圖幫助藝術家“解放雙手” 將幫助增加創意產業從業者的利益的“優質股票”
ML從業者如何閱讀研究論文






 工商網監
工商網監
評論