 基于M55H的定制化backbone模型AxeraSpine
基于M55H的定制化backbone模型AxeraSpine
一
背景
Backbone模型是各種視覺任務訓練的基石,視覺任務模型的性能和模型的速度都受backbone模型的影響,良好的backbone模型可以有效提高視覺任務模型的性能和精度。因此設計優良的backbone模型對視覺任務模型的表現至關重要。目前存在低延遲且高性能的開源模型已經有很多,但這些模型的設計往往只考慮到了理論計算量,并沒有和實際的硬件條件相結合,因此這些模型部署到實際的硬件上,并不能發揮最大的速度潛能。針對這個挑戰,為了發揮backbone模型的最大潛力,我們在M55H平臺上,基于MobileNetV2模型定制了適用于M55H平臺的backbone模型AXSpine系列,相比于原始MobileNetV2模型,AXSpine-Middle在精度提升的同時,速度提升了50%,硬件的MAC利用率大幅提高,在多個具體任務上達到80%以上。另外還有多組通過裁剪或者擴充的AXSpine系列模型提供,以供不同延遲和精度要求的視覺任務進行選擇。
二
性能指標
以下展示AXSpine-Middle模型和MobileNetV2模型在愛芯元智M55H平臺上不同分辨率的性能對比,數據集采用ImageNet數據集,精度均在224x224分辨率條件下進行測試,更多AXSpine模型指標在文章末尾表格中:
| 模型名稱 | Input shape | acc1(224 x 224 標準輸入條件下) | M55H 幀率(@vnpu111) |
| MobileNetV2 | 1x3x576x320 | 71.88 | 124 fps |
| MobileNetV2 | 1x3x288x160 | 71.88 | 373.7 fps |
| AXSpine-Middle | 1x3x576x320 | 72.87 | 186 fps |
| AXSpine-Middle | 1x3x1280x720 | 72.87 | 36.5 fps |
| AXSpine-Middle | 1x3x1920x1080 | 72.87 | 19.4 fps |
三
相關模型介紹
3.1 MobileNetV2
MobileNetV2是google提出的用于移動端的backbone模型,具有精度高、計算量小的特點,在移動端設備上推理效果顯著。MobileNetV2模型的基本組成塊為倒置殘差卷積,由兩組1x1的卷積和一組3x3的depthwise卷積構成。1x1卷積主要作用為對depthwise卷積做升/降維,3x3的depthwise卷積則在升維的空間上進行卷積運算,這種架構可以在保證表達能力的同時有效地增強計算效率。隨后,這種倒置殘差卷積結構進行若干次的堆疊,構造成為MobileNetV2模型。
3.2 地平線相關模型
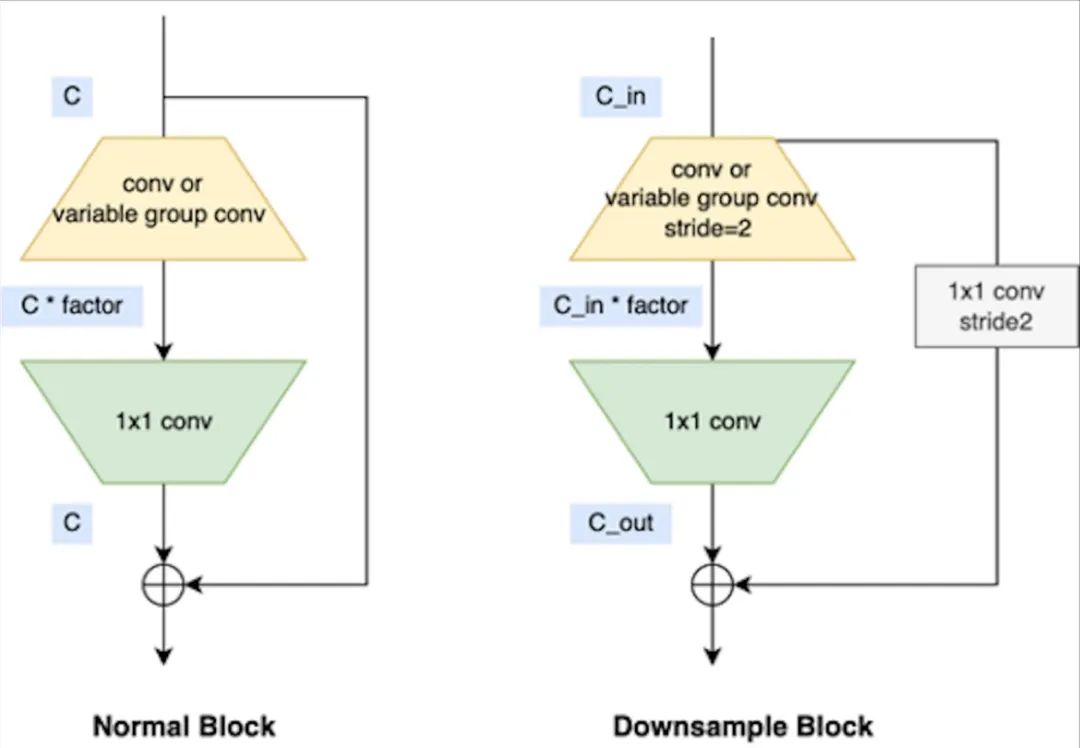
地平線公司也在自身平臺上專門對backbone模型進行了優化,并推出了VarGENet和MixVarGENet等系列模型,其基本塊如下圖所示:

3.3 特斯拉相關模型
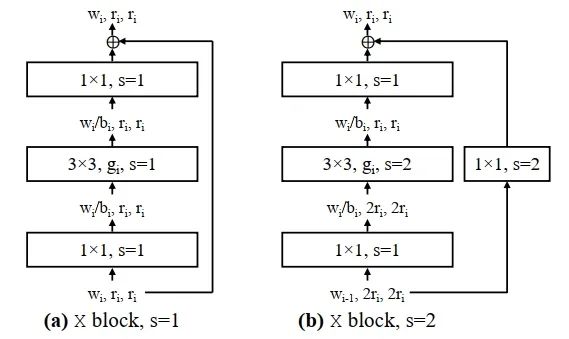
特斯拉相關模型為RegNet,RegNet為何凱明的相關工作,旨在用超參數搜索的方式,指導模型設計的相關工作,在低運算量的條件下,取得了相對優良的精度,由于沒有用到depthwise卷積,在GPU模型上表現良好,被特斯拉硬件采用。其基本結構與resnet等同,如下所示:
四
模型優化
相對于MobileNetV2官方實現,AXSpine模型做了以下改動:
●將MobileNetV2的所有的depthwise卷積修改為小channel size的group卷積;
●將模型第二層的倒置殘差卷積替換為一個簡單的3x3 conv層;
●對不滿足硬件通道對齊的層進行硬件通道對齊;
● 減小部分層的expand_ratio提高運算速度;
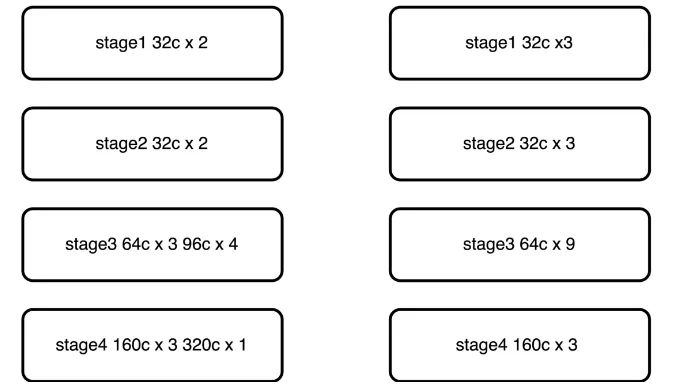
● 將原有的5層stage結構,仿照convnext修改為4層stage結構3393,速度提升,精度降低。
五
改動詳細說明
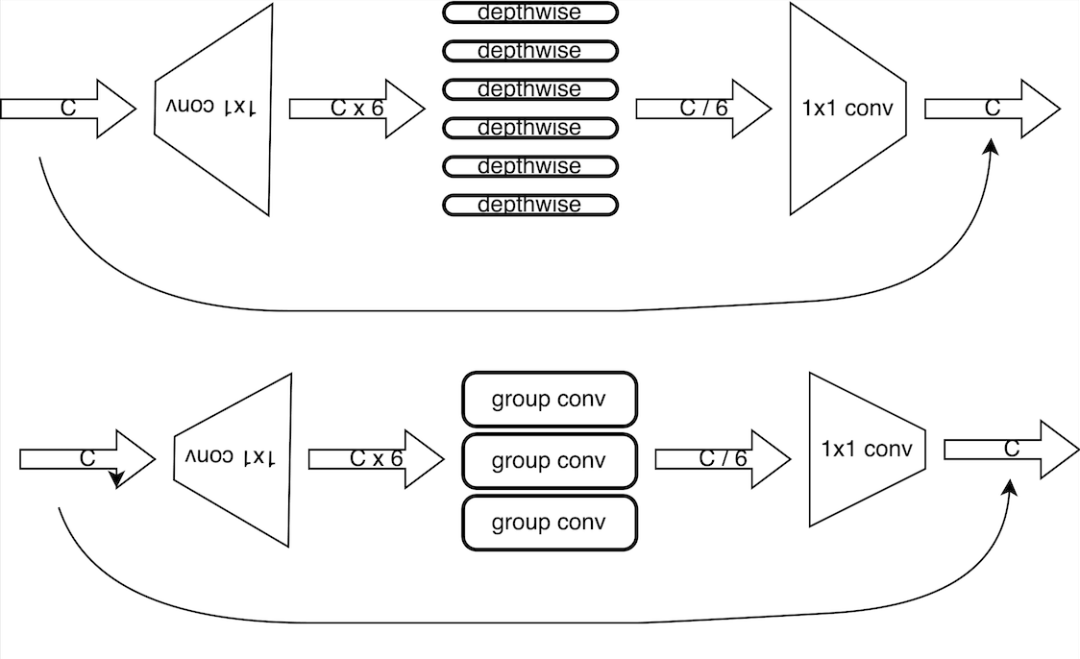
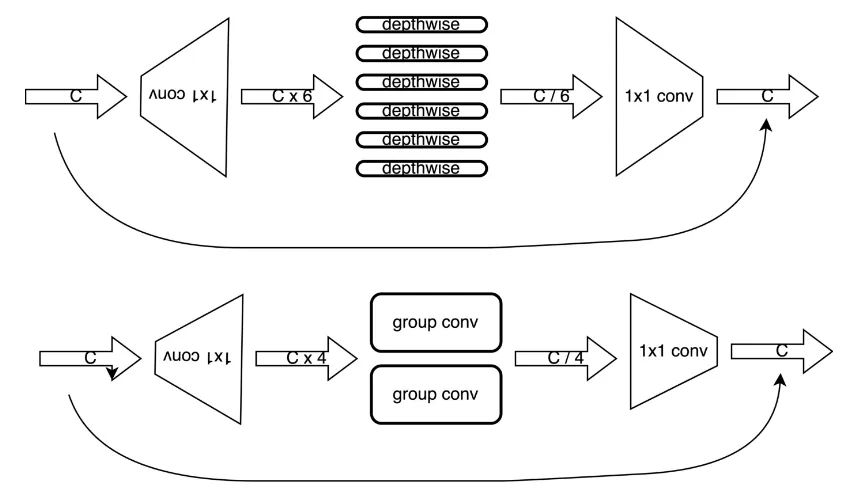
5.1 depthwise卷積修改為group卷積
由于邊緣側芯片的depthwise卷積的支持往往比較低效,這導致使用depthwise卷積的MobileNetV2無法發揮理論計算效率,在這里將depthwise卷積修改為group卷積,增強模型的表達能力,由于芯片組卷積,在特定channel的情況最為高效,因此將所有的depthwise卷積修改為特定channel數的group卷積。
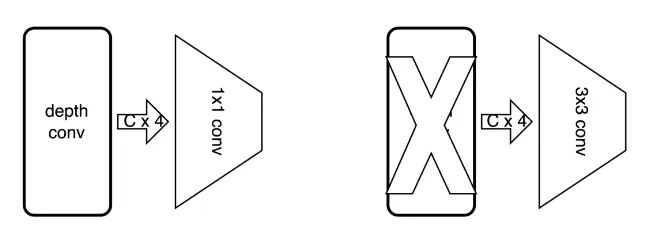
5.2 替換第二層倒置殘差卷積
MobileNetV2的第一層為一個3x3的普通卷積,第二層為一個expand_ratio = 1 的倒置殘差卷積,在原有的MobileNetV2設計中,使用倒置殘差卷積的目的是為了減少計算量,然而當修改為group卷積后,運算量反倒大幅增加,因此將第二層的倒置殘差卷積的兩個堆疊的卷積層,修改為單個普通的3x3卷積。
5.3 對不滿通道對齊的卷積進行對齊
硬件單元在計算的過程中,需要進行數據對齊,如果不滿足數據對齊條件,就會降低運算效率,M55H硬件也是一樣。因此,為了充分利用硬件的計算能力,需要對不滿足channel對齊的層進行對齊操作,MobileNetV2模型中,部分層不滿足硬件對齊條件,這里需要對不滿足硬件對齊的層進行向上補齊操作,不影響性能,表達能力有所提升。
5.4 減小expand_ratio
由于原有的depthwise卷積被替換成了group卷積,模型的表達能力大幅增強,而我們修改MobileNetV2模型的最終目的是為了在保證精度的情況下,提升速度,因此在此處對expand_ratio進行消減,將expand_ratio從6修改為4,第二層的expand_ratio由4再消減為2,理論上模型的計算量減少約30%,這種expand_同時也考慮到了M55H的調度特性,在實際的調度過程中,由于各層特征圖的大小得到了均衡,整體調度效率也得到了提升。
5.5 修改模型stage排布
借鑒convnext文章中的的思路,模型應當包含有4個stage,每個stage的比例大概為13:1較優,基于此判斷,對MobileNetV2模型的stage進行重新劃分,將原有的stage排布按照39:3進行排列,相比于直接削減channel數提升速度的方式,修改stage對模型精度的損傷較小,修改見下圖所示:
六
總結
經過對MobilenetV2模型的適應性改動,愛芯元智發布了基于M55H芯片平臺的定制化模型AXSpine,相比于原版MobilenetV2模型,AXSpine-Middle模型具有更高的精度和達到50%提升的速度。得益于愛芯元智M55H平臺軟硬件聯合設計優化,經過改良后的AXSpine模型相較業界友商在單位算力情況下,展現出了強大的性能和延遲表現。此外除了AXSpine-Middle模型以外,還有若干組模型上架,以滿足不同的延遲和精度需求,總結表格如下,以下模型目前已應用于多組視覺任務中,歡迎使用:
| 模型名稱 | Input shape | acc1(224 x 224 標準輸入條件下) | M55H 幀率(@vnpu111) |
| MobileNetV2 | 1x3x576x320 | 71.88 | 124 fps |
| AXSpine-Small | 1x3x576x320 | 71.59 | 227 fps |
| AXSpine-Middle | 1x3x576x320 | 72.87 | 186 fps |
| AXSpine-Big | 1x3x576x320 | 75.31 | 131 fps |
審核編輯:劉清
-
GPU芯片
+關注
關注
1文章
303瀏覽量
5820
原文標題:愛芯分享 | 基于M55H的定制化backbone模型AxeraSpine
文章出處:【微信號:愛芯元智AXERA,微信公眾號:愛芯元智AXERA】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

AI模型部署邊緣設備的奇妙之旅:目標檢測模型
可靈AI全球首發視頻模型定制功能,助力AI視頻創作
語言模型自動化的優點

浪潮信息發布KOS AI定制版,大幅提升大模型訓練效率
資料保存1:工業定制化儀器設計方案

M12航插連接器與線束定制,為您的自動化設備提供專業互連支持

移遠通信推出大模型解決方案,重塑千行百業智能邊界

Al大模型機器人
快手自研文生圖大模型“可圖”開放,支持AI圖像創作及定制
浪潮信息發布“源2.0-M32”開源大模型
MGMF444A1H9M-MINAS A6N系列 介紹 松下

定制化DC電源模塊的設計與制作






 工商網監
工商網監
評論