 自然語言生成的演變史
自然語言生成的演變史
摘要:自科幻電影誕生以來,社會一直對人工智能著迷。
每當我們聽到“AI”一詞時,我們的第一個想法通常是電影中的未來機器人,如終結者和黑客帝國。盡管我們距離可以自己思考的機器人還有幾年的時間,但在過去幾年中,機器學習和自然語言理解領域已經取得了重大進展。 個人助理(Siri / Alexa),聊天機器人和問答機器人a等應用程序真正徹底改變了我們與機器和開展日常生活的方式。自然語言理解(NLU)和自然語言生成(NLG)是人工智能發展最快的應用之一,因為人們越來越需要理解和從語言中獲得意義,其中含有大量含糊不清的結構。 根據Gartner的說法,“到2019年,自然語言生成將成為90%的現代BI和分析平臺的標準功能”。 在這篇文章中,我們將討論NLG成立初期的簡短歷史,以及它在未來幾年的發展方向。
什么是自然語言生成
語言生成的目標是通過預測句子中的下一個單詞來傳達信息。 可以通過使用語言模型來解決。語言模型是對詞序列的概率分布。 語言模型可以在字符級別,短語級別,句子級別甚至段落級別構建。 例如,為了預測“我需要學習如何___”之后出現的下一個單詞,模型為下一個可能的單詞分配概率,這些單詞可以是“寫作”,“開車”等。神經網絡的最新進展如RNN和LSTM允許處理長句,顯著提高語言模型的準確性。
馬爾可夫鏈
馬爾可夫鏈是最早用于語言生成的算法之一。 它通過使用當前單詞來預測句子中的下一個單詞。 例如,如果模型僅使用以下句子進行訓練:“我早上喝咖啡”和“我吃三明治加茶”。 有100%的可能性預測“咖啡”跟隨“飲酒”,而“我”有50%的機會跟著“喝”,50%跟隨“吃”。 馬爾可夫鏈考慮每個獨特單詞之間的關系來計算下一個單詞的概率。 它們在早期版本的智能手機鍵盤中使用,為句子中的下一個單詞生成建議。
遞歸神經網絡(RNN)
神經網絡是受人類大腦運作啟發的模型,通過建模輸入和輸出之間的非線性關系提供另一種計算方法 - 它們用于語言建模被稱為神經語言建模。
RNN是一種可以利用輸入的順序性質的神經網絡。 它通過前饋網絡傳遞序列的每個項目,并將模型的輸出作為序列中下一項的輸入,允許存儲前面步驟中的信息。 RNN擁有的“記憶”使它們非常適合語言生成,因為它們可以隨時記住對話的背景。 RNN與馬爾可夫鏈不同,因為它會查看先前看到的單詞來進行預測。
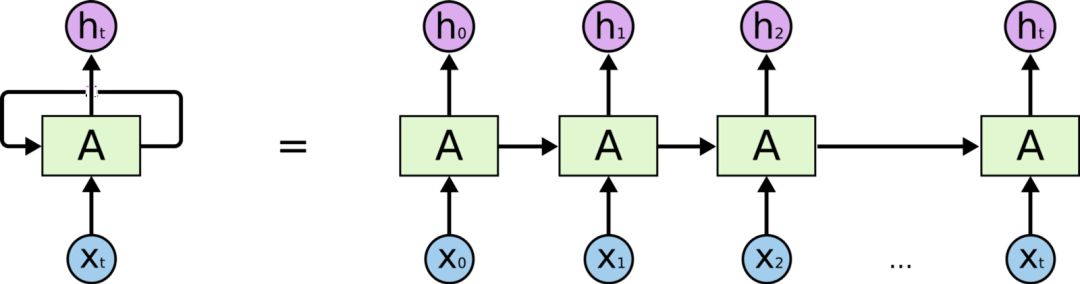
用于語言生成的RNN
在RNN的每次迭代中,模型在其存儲器中存儲遇到的先前單詞并計算下一單詞的概率。 例如,如果模型生成了文本“我們需要租用___”,那么它現在必須弄清楚句子中的下一個單詞。 對于字典中的每個單詞,模型根據它看到的前一個單詞分配概率。 在我們的例子中,“house”或“car”這個詞比“river”或“dinner”這樣的詞有更高的概率。 選擇具有最高概率的單詞并將其存儲在存儲器中,然后模型繼續進行下一次迭代。
RNN受到梯度消失的限制。 隨著序列的長度增加,RNN不能存儲在句子中遠處遇到的單詞,并且僅基于最近的單詞進行預測。 這限制了RNN用于產生聽起來連貫的長句子的應用。
LSTM
基于LSTM的神經網絡是RNN的變體,旨在更準確地處理輸入序列中的長程依賴性。 LSTM具有與RNN類似的鏈式結構; 然而,它們包括四層神經網絡而不是RNN的單層網絡。 LSTM由4個部分組成:單元,輸入門,輸出門和忘記門。 這些允許RNN通過調節單元的信息流來記住或忘記任意時間間隔的單詞。
考慮以下句子作為模型的輸入:“我來自西班牙。我精通____。“為了正確預測下一個單詞為”西班牙語“,該模型在前面的句子中側重于”西班牙“一詞,并使用單元格的記憶”記住“它。該信息在處理序列時由單元存儲,然后在預測下一個字時使用。當遇到句號時,遺忘門意識到句子的上下文可能有變化,并且可以忽略當前的單元狀態信息。這允許網絡選擇性地僅跟蹤相關信息,同時還最小化消失的梯度問題,這允許模型在更長的時間段內記住信息。
LSTM及其變體似乎是消除漸變以產生連貫句子的問題的答案。然而,由于仍存在從先前單元到當前單元的復雜順序路徑,因此可以節省多少信息存在限制。這將LSTM記憶的序列長度限制為幾百個單詞。另一個缺陷是LSTM由于高計算要求而非常難以訓練。由于它們的順序性,它們難以并行化,限制了它們利用諸如GPU和TPU之類的現代計算設備的能力。
Transformer
Transformer最初是在2017年Google論文“Attention is all you need”中引入的,它提出了一種稱為“自注意力機制”的新方法。變形金剛目前正在各種NLP任務中使用,例如語言建模,機器翻譯和文本生成。變換器由一堆編碼器組成,用于處理任意長度的輸入和另一堆解碼器,以輸出生成的句子。
與LSTM相比,Transformer僅執行小的,恒定數量的步驟,同時應用自注意力機制,該機制直接模擬句子中所有單詞之間的關系,而不管它們各自的位置如何。當模型處理輸入序列中的每個單詞時,自注意力允許模型查看輸入序列的其他相關部分以更好地編碼單詞。它使用多個注意頭,擴展了模型聚焦在不同位置的能力,無論它們在序列中的距離如何。
最近,對普通Transformer架構進行了一些改進,顯著提高了它們的速度和精度。在2018年,谷歌發布了一篇關于變形金剛雙向編碼器表示的論文(BERT),該論文為各種NLP任務提供了最先進的結果。同樣,在2019年,OpenAI發布了一個基于變換器的語言模型,其中包含大約15億個參數,只需幾行輸入文本即可生成長篇連貫的文章。
用于語言生成的Transformer
最近,Transformer也被用于語言生成。 用于語言生成的Transformer最著名的例子之一是OpenAI,他們的GPT-2語言模型。 該模型通過使用注意力集中于先前在模型中看到的與預測下一個單詞相關的單詞來學習預測句子中的下一個單詞。
使用變形金剛生成文本的基礎與機器翻譯所遵循的結構類似。如果我們采用一個例句“她的禮服有粉紅色,白色和___點。”該模型將預測藍色,通過使用自注意力分析列表中的前一個單詞作為顏色(白色和粉紅色)并理解期望的詞也需要是一種顏色。自我關注允許模型選擇性地關注每個單詞的句子的不同部分,而不是僅僅記住循環塊(在RNN和LSTM中)的一些特征,這些特征通常不會用于幾個塊。這有助于模型回憶起前一句的更多特征,并導致更準確和連貫的預測。與以前的模型不同,Transformer可以在上下文中使用所有單詞的表示,而無需將所有信息壓縮為單個固定長度表示。這種架構允許變換器在更長的句子中保留信息,而不會顯著增加計算要求。它們在跨域的性能也優于以前的模型,無需特定領域的修改。
語言生成的未來
在這篇博客中,我們看到了語言生成的演變,從使用簡單的馬爾可夫鏈生成句子到使用自我注意模型生成更長距離的連貫文本。然而,我們正處于生成語言建模的曙光,而變形金剛只是向真正自主文本生成方向邁出的一步。還針對其他類型的內容(例如圖像,視頻和音頻)開發了生成模型。這開啟了將這些模型與生成文本模型集成的可能性,以開發具有音頻/視覺界面的高級個人助理。
然而,作為一個社會,我們需要謹慎對待生成模型的應用,因為它們為生成假新聞,虛假評論和在線冒充人們開辟了多種可能性。 OpenAI決定拒絕發布他們的GPT-2語言模型,因為它可能被誤用,這證明了我們現在已經進入了一個語言模型足夠引起關注的時代。
生成模型有可能改變我們的生活;然而,它們是一把雙刃劍。通過對這些模型進行適當的審查,無論是通過研究界還是政府法規,未來幾年在這一領域肯定會取得更多進展。無論結果如何,都應該有激動人心的時刻!
未來智能實驗室是人工智能學家與科學院相關機構聯合成立的人工智能,互聯網和腦科學交叉研究機構。
未來智能實驗室的主要工作包括:建立AI智能系統智商評測體系,開展世界人工智能智商評測;開展互聯網(城市)云腦研究計劃,構建互聯網(城市)云腦技術和企業圖譜,為提升企業,行業與城市的智能水平服務。
-
AI
+關注
關注
87文章
30993瀏覽量
269279 -
人工智能
+關注
關注
1791文章
47350瀏覽量
238741 -
機器
+關注
關注
0文章
784瀏覽量
40741
原文標題:自然語言生成的演變史
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論