 一個單路徑One-Shot模型,以解決訓練過程中面對的主要挑戰
一個單路徑One-Shot模型,以解決訓練過程中面對的主要挑戰
近日,來自曠視研究院的郭梓超、張祥雨、穆皓遠、孫劍等人發表一篇新論文“Single Path One-Shot Neural Architecture Search with Uniform Sampling”,提出一個單路徑 One-Shot 模型,以解決訓練過程中面對的主要挑戰。目前,這一方法在大型數據集 ImageNet 上取得了當前最優結果。
值得一提的是,孫劍現任曠視研究院院長,與同為深度殘差網絡ResNet作者之一的張祥雨(與孫劍一起加盟曠視)早已合作多次。

傳送門:
https://arxiv.org/abs/1904.00420
導語
簡介
本文 One-Shot NAS
One-Shot NAS方法回顧
單路徑超網絡與均勻采樣
超網絡與選擇單元
通道數搜索
混合精度量化搜索
基于進化算法的模型搜索
總結
實驗
構造單元搜索
通道數搜索
對比SOTA方法
混合精度量化搜索
搜索成本分析
參考文獻
導語
一步法(One-Shot)是一個強大的神經網絡模型搜索(Neural Architecture Search/NAS)框架,但是它的訓練相對復雜,并且很難在大型數據集(比如 ImageNet)上取得較有競爭力的結果。
本文中,曠視研究院提出一個單路徑 One-Shot 模型,以解決訓練過程中面對的主要挑戰,其核心思想是構建一個簡化的超網絡——單路徑超網絡(Single Path Supernet),這個網絡按照均勻的路徑采樣方法進行訓練。
所有子結構(及其權重)獲得充分而平等的訓練。基于這個已訓練的超網絡,可以通過進化算法快速地搜索最優子結構,其中無需對任何子結構進行微調。
對比實驗證明了這一方法的靈活性和有效性,不僅易于訓練和快速搜索,并且可以輕松支持不同的復雜搜索空間(比如構造單元,通道數,混合精度量化)和搜索約束(比如 FLOPs,速度),從而便于滿足多種需求。這一方法在大型數據集 ImageNet 上取得了當前最優結果。
簡介
深度學習終結了手工設計特征的時代,同時解決了權重優化問題。NAS 則旨在通過另一個方法——模型搜索(architecture search),終結人工設計架構。
早期的 NAS 方法使用嵌套式優化,從搜索空間采樣出模型結構,接著從頭訓練其權重,缺點是對于大型數據集來講計算量過大。新近的 NAS 方法則采用權重共享策略減少計算量。本文提出的超網絡則包含所有子結構,只訓練一次,所有子結構便可以直接從超網絡獲得其權重,無需從頭訓練。即使在大型數據集上,計算也十分高效。
大多數權重共享方法使用連續的搜索空間,將模型結構分布不斷參數化。這些參數在超網絡訓練期間與網絡權重進行聯合優化。因此可以在優化時進行模型搜索,從分布中采樣最優的架構。其公式化表示優雅而理論完備。但是存在兩個問題:
第一,超網絡的權重深度耦合。目前尚不清楚為什么特定結構的復用權重(inherited weights)依然有效。第二,聯合優化導致了模型參數和超網絡權重的進一步耦合。梯度方法的貪婪天性不可避免地在結構分布和超網絡權重中引入偏差。這很容易誤導模型搜索。精細地微調超參數和優化過程被用于先前方法之中。
One-Shot 是一種新范式。它定義了超網絡,并以相似的方式做權重復用。但是并沒有將模型結構分布參數化。模型搜索從超網絡訓練中解耦,并且解決步驟是獨立的。因此,One-Shot 具有序列性。它結合了上述嵌套式和聯合式優化方法的優點,因此靈活而高效。
盡管第二個問題已解決,現有 One-Shot 并未很好地解決第一個問題。超網絡的權重依然耦合。優化依然復雜,并包含敏感的超參數,導致在大型數據集上表現欠佳。
本文方法的動機旨在吸收 One-Shot 的優點,克服其缺點。One-Shot 成功的關鍵是使用復用權重的模型的精度可以用來預測從頭訓練模型的精度。因此,曠視研究院提出,超網絡訓練應是隨機的。這樣所有子結構的權重能夠被同時且均勻地優化。
為減少超網絡的權重耦合,曠視研究院提出一個單路徑超網絡,在每次迭代訓練中只有單路徑結構被激活。訓練中不需要任何超參數來指導子結構的選擇,采用均勻采樣的方式,平等對待所有子結構。
本文方法簡單而靈活,超網絡訓練中沒有超參數。其簡易性允許設計豐富的搜索空間,包括新設計通道單元和位寬單元。模型搜索過程十分高效,因為只需要基于超網絡的權重進行前向計算。進化算法則用來輕松支持多種約束。
綜合性消融實驗及在大型數據集(ImageNet)上的實驗證明了這一方法在精度、內存消耗、訓練時間、模型搜索的有效性及靈活性方面都表現良好,達到了當前最優的結果。
本文 One-Shot NAS
One-Shot NAS方法回顧
上所述,耦合式模型搜索和權重優化是存在挑戰和問題的。通過回顧發現,早期使用嵌套優化的 NAS 方法在于解決公式 (1) 和 (2) 的優化問題,這不禁引起思考,問題解耦和權重共享的優點是否可以兼得?


這一考慮誕生了所謂的 One-Shot 。這些方法依然只訓練一次超網絡,并允許各結構共享其中的權重。
但是,超網絡訓練及模型搜索作為先后次序的兩個步驟是解耦的。請注意,這不同于嵌套優化或聯合優化。
首先,超網絡權重被優化為:
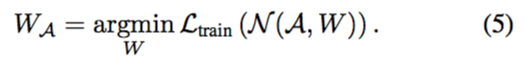
相比公式 (4)
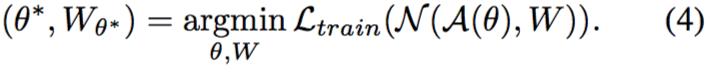
,公式 (5) 已經不存在搜索空間的連續參數化,只有網絡權重被優化。
其次,搜索部分被表示為:

公式 (6) 與公式 (1) 、 (2) 的最大區別是其權重是預先初始化的。評估  僅需要推理。沒有微調或者再訓練。因此搜索非常有效。
僅需要推理。沒有微調或者再訓練。因此搜索非常有效。
通過借助進化算法,搜索同樣非常靈活。像等式 (3)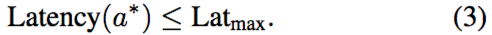 對模型結構進行的約束可以精確地滿足。并且一旦訓練好一個超網絡,可在同一超網絡內基于不同約束(比如 100ms 和 200ms 延遲)重復搜索。這些特性是先前方法所缺失的,將使 One-Shot NAS 方法對實際任務更具吸引力。
對模型結構進行的約束可以精確地滿足。并且一旦訓練好一個超網絡,可在同一超網絡內基于不同約束(比如 100ms 和 200ms 延遲)重復搜索。這些特性是先前方法所缺失的,將使 One-Shot NAS 方法對實際任務更具吸引力。
但依然存在一個問題。在等式 (5) 中,超網絡訓練的圖節點權重是耦合的,復用權重是否適用于任意子結構尚不清楚。
單路徑超網絡和均勻采樣
按照基本原理重新出發,會使 One-Shot 范式更有效。在等式 (5) 中,模型搜索成功的關鍵在于,在驗證集中,使用復用權重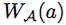 (沒有額外的微調)的任意子結構的精度是高度可信的。正如等式 (1) 是理想情況,需要權重
(沒有額外的微調)的任意子結構的精度是高度可信的。正如等式 (1) 是理想情況,需要權重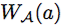
 。近似的效果和訓練損失函數
。近似的效果和訓練損失函數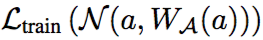
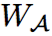 的優化應當與搜索空間中所有子結構的優化同時進行。這可表示為:
的優化應當與搜索空間中所有子結構的優化同時進行。這可表示為:

請注意,等式 (7) 是等式 (5) 的實現。在優化的每一步中,子結構是隨機采樣的,只有對應的權重 被激活和更新。這不僅節省內存空間,而且高效。由此,超網絡本身不再是一個有效的網絡,而變成一個隨機的網絡。
被激活和更新。這不僅節省內存空間,而且高效。由此,超網絡本身不再是一個有效的網絡,而變成一個隨機的網絡。
為減少節點權重之間的協同適應,曠視研究院提出最大化簡化搜索空間
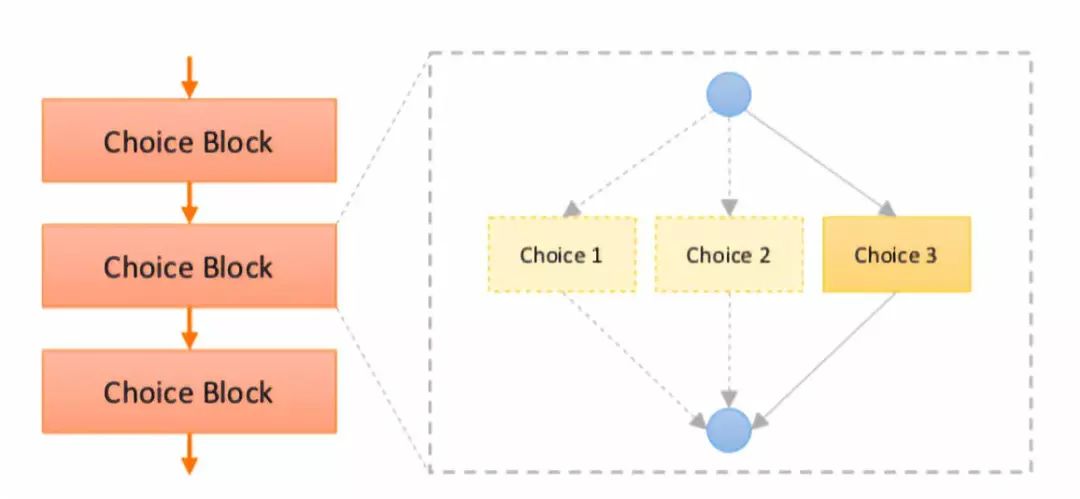
圖 1:單一路徑超網絡架構圖
在每次訓練時僅保留一個。不存在任何調優。訓練在本文實驗中收斂良好。
先驗分布
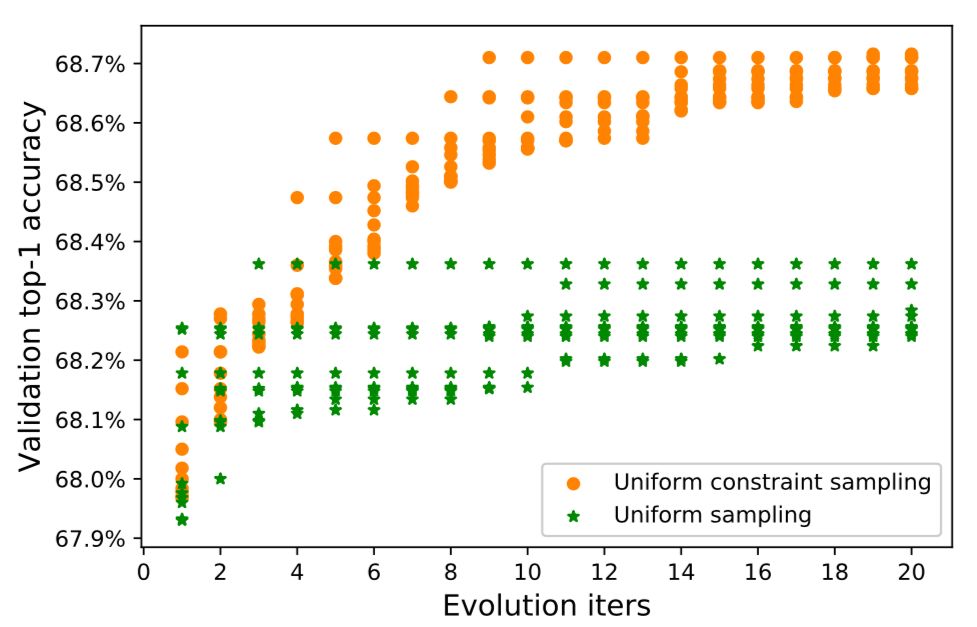
表 2:不同采樣策略的單路徑超網絡的進化模型搜索
本文注意到,在優化時根據結構分布采樣一個路徑已經出現在之前的權重共享方法之中,區別在于,在本文的訓練中(等式(7))分布  ? ? ?是一個固定的先驗,而在先前方法中,它是可學習和更新的(等式(4)),后者會使超網絡權重和結構參數優化高度關聯。
? ? ?是一個固定的先驗,而在先前方法中,它是可學習和更新的(等式(4)),后者會使超網絡權重和結構參數優化高度關聯。
請注意,本文并未聲明在訓練時一個固定的先驗分布天生優于優化分布。不存在這樣的理論保證。本文更優的結果可能是受益于這一事實:當前優化技術的成熟度不足以滿足等式 (4) 中的聯合優化需求。
超網絡與選擇單元
選擇單元用于構建一個超網絡。圖 1 給出了一個實例。一個選擇單元包含多個選擇。對于本文提出的單路徑超網絡,每個選擇單元一次只調用一個選擇。一個路徑的獲得是通過隨機采樣所有選擇單元實現的。
本文方法的簡易性允許定義不同類型的選擇單元,以搜索不同的結構變量。具體而言,曠視研究院提出兩個全新的選擇單元,以支持復雜的搜索空間。
通道數搜索。選擇單元旨在搜索一個卷積層的通道數。其主要思想是預先分配一個帶有最大通道數的權重張量。在超網絡訓練期間,系統隨機選擇通道數并分割出用于卷積的相應的子張量。詳見圖 4。

圖 4:用于通道數搜索的選擇單元
混合精度量化搜索。選擇單元可以搜索卷積層權重和特征的量化精度。在超網絡訓練中,特征圖的位寬和和權重被隨機選取。詳見圖 5。
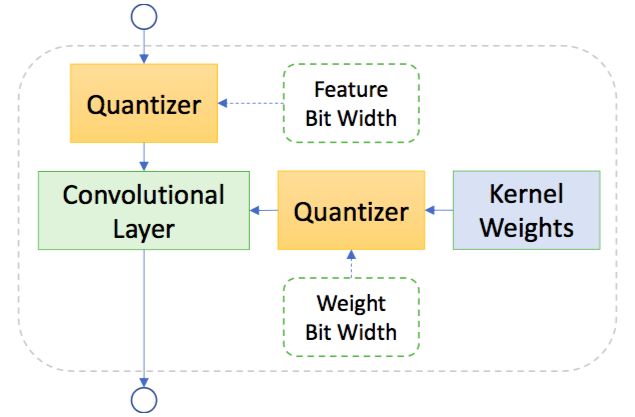
圖 5:用于混合精度量化搜索的選擇單元
基于進化算法的模型搜索
針對等式 (6) 中的模型搜索,先前的 One-Shot 工作使用隨機搜索。這在大的搜索空間中并不奏效。因此,本文使用了進化算法,同時揚棄了從頭開始訓練每個子結構的缺點,只涉及推理部分,因此非常高效。詳見算法 1。

算法 1:基于進化算法的模型搜索
圖 3 描繪了使用進化算法和隨機搜索兩種方法在進化迭代時的驗證集精度。很明顯進化算法搜索更有效。
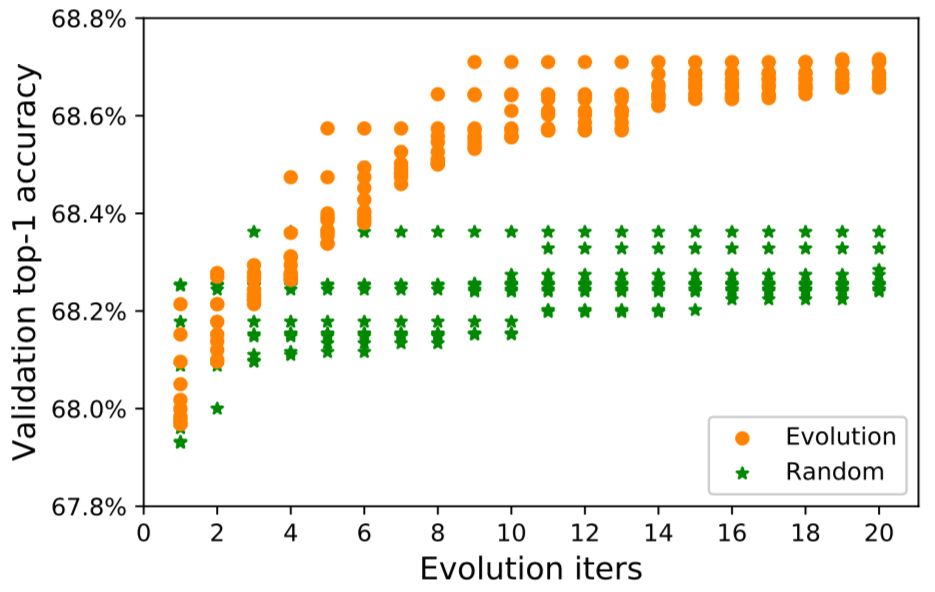
圖 3:進化算法搜索對比隨機搜索
進化算法可以靈活處理等式 (3) 的不同約束,因為變異和交叉過程是可控的,以產生滿足約束條件的合適候選。
總結
單路徑超網絡、均勻采樣訓練策略、基于進化算法的模型搜索、豐富的搜索空間設計,上述多種設計使得本文方法簡單、高效和靈活。表 1 給出了本文方法與其他權重共享方法的一個全方位、多維度對比結果。

表 1:本文方法對比當前權重共享 SOTA 方法
實驗
所有實驗是在 ImageNet 上進行的。驗證集和測試集的設定遵從 Proxyless NAS[4]。對于超網絡的訓練,以及(進化搜索之后)最優模型結構的從頭再訓練,本文使用和 [17] 一樣的設定。
構造單元搜索
構造單元(building block)的設計靈感來自手工設計網絡的代表作——ShuffleNet v2。表 2 給出了超網絡的整體架構。共有 20 個選擇單元。

表 2:超網絡架構
表 3 給出了結果。為了對比,本文設置了一系列基線,如下:1)只選擇一個特定的單元選擇;2)從搜索空間中隨機選擇一些候選;3)使用隨機搜索替代本文的進化算法模型搜索。

表 3:構造單元搜索結果
通道數搜索
搜索卷積層的通道數非常有挑戰,如圖 4 所示,本文提出一個全新的選擇單元用于通道數搜索,并首先在基線結構 “all choice 3”(見表 3)做了評估,結果如表 4 (第一部分)所示;為進一步提升精度,本文對構造單元和通道做了聯合搜索。結果如表 4(第二部分)所示。
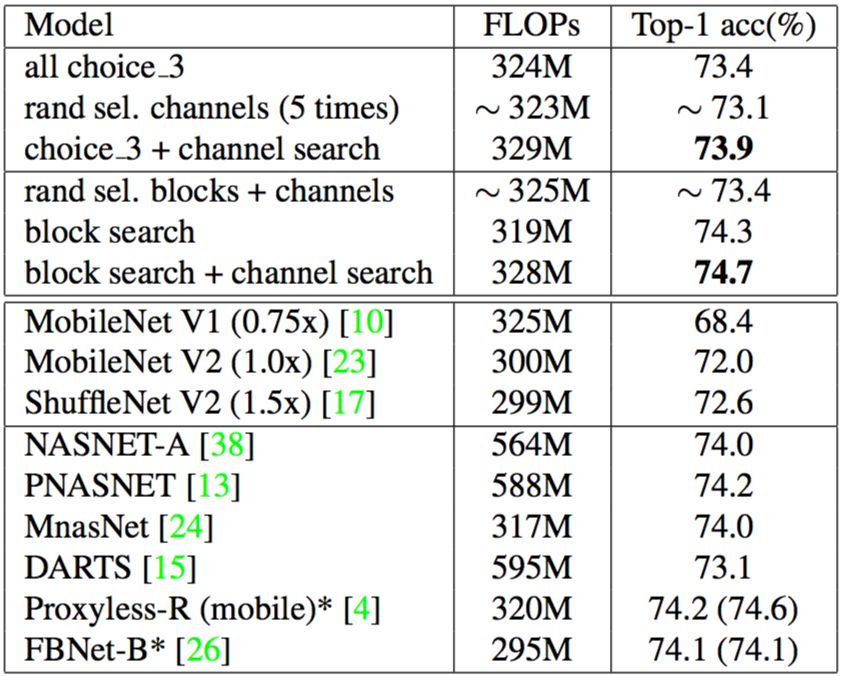
表 4:通道數搜索
對比SOTA方法
雖然表 4 展示了本文方法的優越性,但是由于搜索空間和訓練方法的不同,存在不公平對比的可能性。為直接進行對比,本文采用和 Proxyless NAS [4]、FBNet [26] 相同的搜索空間,并在同一設置下再訓練已搜索的模型,具體對比結果如表 5 所示:

表 5:本文方法與當前 SOTA NAS 方法的對比
混合精度量化搜索
低功率設備部署模型時需要用到量化技術。但是在通道數與位寬之間找到一個權衡不無挑戰。對于這些問題,本文方法可迎刃而解。
這里的搜索空間包含上述的通道搜索空間和混合精度量化搜索空間,后者使用一個全新的選擇單元搜索權重和特征圖的位寬,如圖 5 所示。
在超網絡訓練中,對于每個選擇單元,特征位寬和權重位寬是隨機采樣的。他們在進化步驟中被確定。具體實驗結果如表 6 所示:
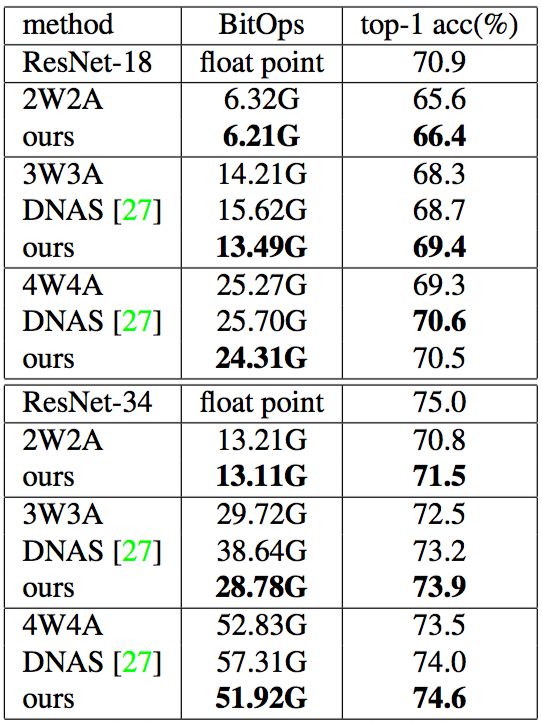
表 6:混合精度量化搜索的結果
搜索成本分析
搜索成本在 NAS 中是一件要緊的事。本文給出了與先前方法 [4] [26] 的一些對比結果,如表 7 所示:

表 7:搜索成本
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100714 -
數據集
+關注
關注
4文章
1208瀏覽量
24689 -
深度學習
+關注
關注
73文章
5500瀏覽量
121111
原文標題:曠視提出AutoML新方法,在ImageNet取得新突破 | 技術頭條
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
請問采樣保持芯片AD783的ONE-SHOT是什么電路
卷積神經網絡訓練過程中的SGD的并行化設計
思必馳積淀許久的one-shot功能也終于揭開神秘面紗

如何在訓練過程中正確地把數據輸入給模型
基于分割后門訓練過程的后門防御方法
基于GLM-6B對話模型的實體屬性抽取項目實現解析
CNN模型的基本原理、結構、訓練過程及應用領域
深度學習的典型模型和訓練過程
解讀PyTorch模型訓練過程
FP8模型訓練中Debug優化思路





 工商網監
工商網監
評論