 CPU Cache Line偽共享問題的總結和分析
CPU Cache Line偽共享問題的總結和分析
1. 關于本文
本文基于 Joe Mario 的一篇博客改編而成。Joe Mario 是 Redhat 公司的 Senior Principal Software Engineer,在系統的性能優化領域頗有建樹,他也是本文描述的perf c2c工具的貢獻者之一。這篇博客行文比較口語化,且假設讀者對 CPU 多核架構,Cache Memory 層次結構,以及 Cache 的一致性協議有所了解。故此,筆者決定放棄照翻原文,并且基于原博客文章做了一些擴展,增加了相關背景知識簡介。本文中若有任何疏漏錯誤,責任在于編譯者。有任何建議和意見,請回復內核月談微信公眾號,或通過 oliver.yang at linux.alibaba.com 反饋。
2. 背景知識
要搞清楚 Cache Line 偽共享的概念及其性能影響,需要對現代理器架構和硬件實現有一個基本的了解。如果讀者已經對這些概念已經有所了解,可以跳過本小節,直接了解 perf c2c 發現 Cache Line 偽共享的方法。(注:本節中的所有圖片,均來自與 Google 圖片搜索,版權歸原作者所有。)
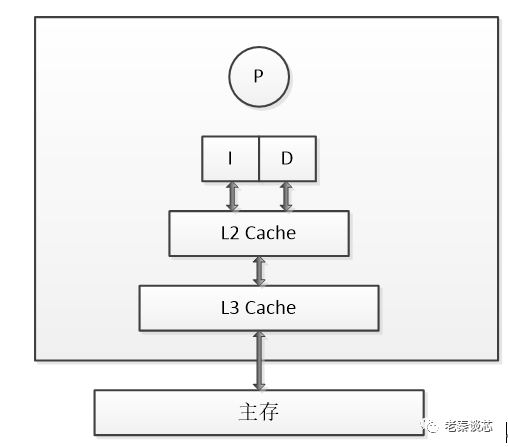
2.1 存儲器層次結構
眾所周知,現代計算機體系結構,通過存儲器層次結構 (Memory Hierarchy) 的設計,使系統在性能,成本和制造工藝之間作出取舍,從而達到一個平衡。下圖給出了不同層次的硬件訪問延遲,可以看到,各個層次硬件訪問延遲存在數量級上的差異,越高的性能,往往意味著更高的成本和更小的容量:

通過上圖,可以對各級存儲器 Cache Miss 帶來的性能懲罰有個大致的概念。
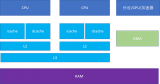
2.2 多核架構
隨著多核架構的普及,對稱多處理器 (SMP) 系統成為主流。例如,一個物理 CPU 可以存在多個物理 Core,而每個 Core 又可以存在多個硬件線程。x86 以下圖為例,1 個 x86 CPU 有 4 個物理 Core,每個 Core 有兩個 HT (Hyper Thread),
從硬件的角度,上圖的 L1 和 L2 Cache 都被兩個 HT 共享,且在同一個物理 Core。而 L3 Cache 則在物理 CPU 里,被多個 Core 來共享。而從 OS 內核角度,每個 HT 都是一個邏輯 CPU,因此,這個處理器在 OS 來看,就是一個 8 個 CPU 的 SMP 系統。
2.3 NUMA 架構
一個 SMP 系統,按照其 CPU 和內存的互連方式,可以分為 UMA (均勻內存訪問) 和 NUMA (非均勻內存訪問) 兩種架構。其中,在多個物理 CPU 之間保證 Cache 一致性的 NUMA 架構,又被稱做 ccNUMA (Cache Coherent NUMA) 架構。
以 x86 為例,早期的 x86 就是典型的 UMA 架構。例如下圖,四路處理器通過 FSB (前端系統總線) 和主板上的內存控制器芯片 (MCH) 相連,DRAM 是以 UMA 方式組織的,延遲并無訪問差異,
然而,這種架構帶來了嚴重的內存總線的性能瓶頸,影響了 x86 在多路服務器上的可擴展性和性能。
因此,從 Nehalem 架構開始,x86 開始轉向 NUMA 架構,內存控制器芯片被集成到處理器內部,多個處理器通過 QPI 鏈路相連,從此 DRAM 有了遠近之分。而 Sandybridge 架構則更近一步,將片外的 IOH 芯片也集成到了處理器內部,至此,內存控制器和 PCIe Root Complex 全部在處理器內部了。下圖就是一個典型的 x86 的 NUMA 架構:
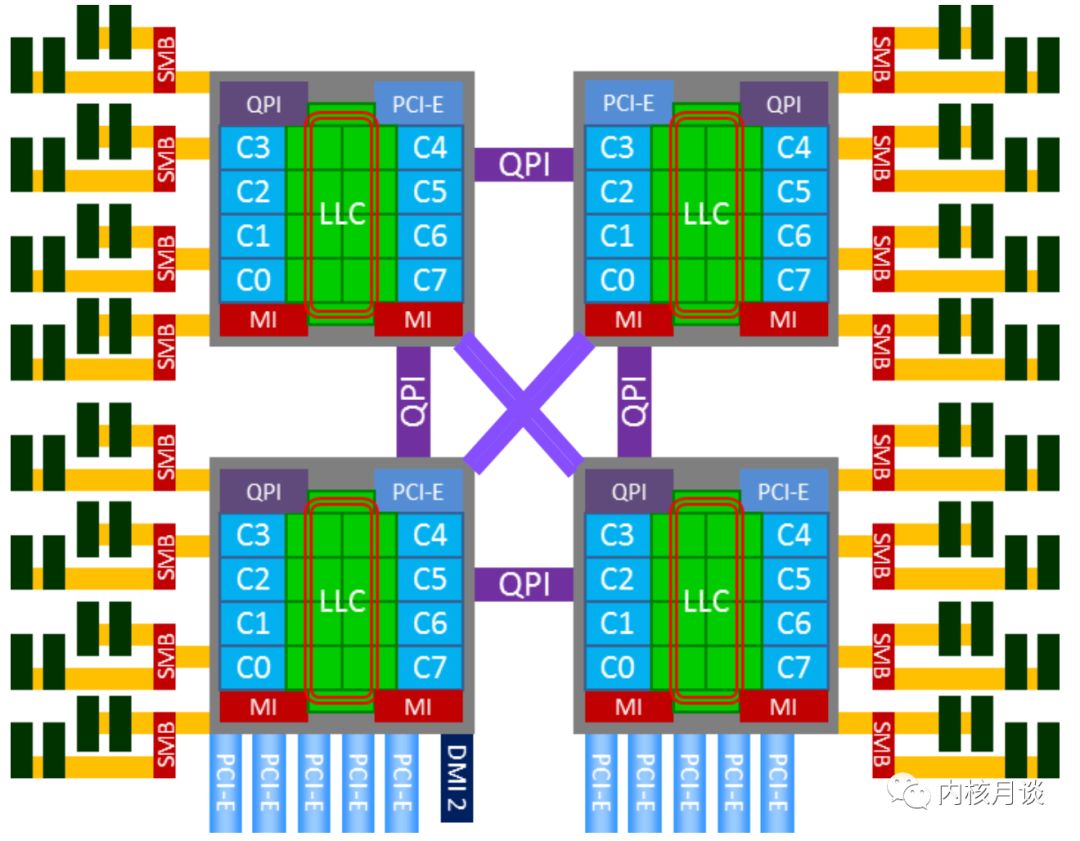
由于 NUMA 架構的引入,以下主要部件產生了因物理鏈路的遠近帶來的延遲差異:
-
Cache
除物理 CPU 有本地的 Cache 的層級結構以外,還存在跨越系統總線 (QPI) 的遠程 Cache 命中訪問的情況。需要注意的是,遠程的 Cache 命中,對發起 Cache 訪問的 CPU 來說,還是被記入了 LLC Cache Miss。
-
DRAM
在兩路及以上的服務器,遠程 DRAM 的訪問延遲,遠遠高于本地 DRAM 的訪問延遲,有些系統可以達到 2 倍的差異。需要注意的是,即使服務器 BIOS 里關閉了 NUMA 特性,也只是對 OS 內核屏蔽了這個特性,這種延遲差異還是存在的。
-
Device
對 CPU 訪問設備內存,及設備發起 DMA 內存的讀寫活動而言,存在本地 Device 和遠程 Device 的差別,有顯著的延遲訪問差異。
因此,對以上 NUMA 系統,一個 NUMA 節點通常可以被認為是一個物理 CPU 加上它本地的 DRAM 和 Device 組成。那么,四路服務器就擁有四個 NUMA 節點。如果 BIOS 打開了 NUMA 支持,Linux 內核則會根據 ACPI 提供的表格,針對 NUMA 節點做一系列的 NUMA 親和性的優化。
在 Linux 上,numactl --hardware可以返回當前系統的 NUMA 節點信息,特別是 CPU 和 NUMA 節點的對應信息。
2.4 Cache Line
Cache Line 是 CPU 和主存之間數據傳輸的最小單位。當一行 Cache Line 被從內存拷貝到 Cache 里,Cache 里會為這個 Cache Line 創建一個條目。這個 Cache 條目里既包含了拷貝的內存數據,即 Cache Line,又包含了這行數據在內存里的位置等元數據信息。
由于 Cache 容量遠遠小于主存,因此,存在多個主存地址可以被映射到同一個 Cache 條目的情況,下圖是一個 Cache 和主存映射的概念圖:

而這種 Cache 到主存的映射,通常是由內存的虛擬或者物理地址的某幾位決定的,取決于 Cache 硬件設計是虛擬地址索引,還是物理地址索引。然而,由于索引位一般設計為低地址位,通常在物理頁的頁內偏移以內,因此,不論是內存虛擬或者物理地址,都可以拿來判斷兩個內存地址,是否在同一個 Cache Line 里。
Cache Line 的大小和處理器硬件架構有關。在 Linux 上,通過getconf就可以拿到 CPU 的 Cache Line 的大小,

2.5 Cache 的結構
前面 Linuxgetconf命令的輸出,除了*_LINESIZE指示了系統的 Cache Line 的大小是 64 字節外,還給出了 Cache 類別,大小。其中*_ASSOC則指示了該 Cache 是幾路關聯 (Way Associative) 的。
下圖很好的說明了 Cache 在 CPU 里的真正的組織結構,

一個主存的物理或者虛擬地址,可以被分成三部分:高地址位當作 Cache 的 Tag,用來比較選中多路 (Way) Cache 中的某一路 (Way),而低地址位可以做 Index,用來選中某一個 Cache Set。在某些架構上,最低的地址位,Block Offset 可以選中在某個 Cache Line 中的某一部份。
因此,Cache Line 的命中,完全依靠地址里的 Tag 和 Index 就可以做到。關于 Cache 結構里的 Way,Set,Tag 的概念,請參考相關文檔或者資料。這里就不再贅述。
2.6 Cache 一致性
如前所述,在 SMP 系統里,每個 CPU 都有自己本地的 Cache。因此,同一個變量,或者同一行 Cache Line,有在多個處理器的本地 Cache 里存在多份拷貝的可能性,因此就存在數據一致性問題。通常,處理器都實現了 Cache 一致性 (Cache Coherence)協議。如歷史上 x86 曾實現了MESI協議以及MESIF協議。
假設兩個處理器 A 和 B, 都在各自本地 Cache Line 里有同一個變量的拷貝時,此時該 Cache Line 處于Shared狀態。當處理器 A 在本地修改了變量,除去把本地變量所屬的 Cache Line 置為Modified狀態以外,還必須在另一個處理器 B 讀同一個變量前,對該變量所在的 B 處理器本地 Cache Line 發起 Invaidate 操作,標記 B 處理器的那條 Cache Line 為Invalidate狀態。隨后,若處理器 B 在對變量做讀寫操作時,如果遇到這個標記為Invalidate的狀態的 Cache Line,即會引發 Cache Miss,從而將內存中最新的數據拷貝到 Cache Line 里,然后處理器 B 再對此 Cache Line 對變量做讀寫操作。
本文中的 Cache Line 偽共享場景,就基于上述場景來講解,關于 Cache 一致性協議更多的細節,請參考相關文檔。
2.7 Cache Line 偽共享
Cache Line 偽共享問題,就是由多個 CPU 上的多個線程同時修改自己的變量引發的。這些變量表面上是不同的變量,但是實際上卻存儲在同一條 Cache Line 里。在這種情況下,由于 Cache 一致性協議,兩個處理器都存儲有相同的 Cache Line 拷貝的前提下,本地 CPU 變量的修改會導致本地 Cache Line 變成Modified狀態,然后在其它共享此 Cache Line 的 CPU 上,引發 Cache Line 的 Invaidate 操作,導致 Cache Line 變為Invalidate狀態,從而使 Cache Line 再次被訪問時,發生本地 Cache Miss,從而傷害到應用的性能。在此場景下,多個線程在不同的 CPU 上高頻反復訪問這種 Cache Line 偽共享的變量,則會因 Cache 顛簸引發嚴重的性能問題。
下圖即為兩個線程間的 Cache Line 偽共享問題的示意圖,

3. Perf c2c 發現偽共享
當應用在 NUMA 環境中運行,或者應用是多線程的,又或者是多進程間有共享內存,滿足其中任意一條,那么這個應用就可能因為 Cache Line 偽共享而性能下降。
但是,要怎樣才能知道一個應用是不是受偽共享所害呢?Joe Mario 提交的 patch 能夠解決這個問題。Joe 的 patch 是在 Linux 的著名的 perf 工具上,添加了一些新特性,叫做 c2c,意思是“緩存到緩存” (cache-2-cache)。
Redhat 在很多 Linux 的大型應用上使用了 c2c 的原型,成功地發現了很多熱的偽共享的 Cache Line。Joe 在博客里總結了一下perf c2c的主要功能:
-
發現偽共享的 Cache Line
-
誰在讀寫上述的 Cache Line,以及訪問發生處的 Cache Line 的內部偏移
-
這些讀者和寫者分別的 pid, tid, 指令地址,函數名,二進制文件
-
每個讀者和寫者的源代碼文件,代碼行號
-
這些熱點 Cache Line 上的,load 操作的平均延遲
-
這些 Cache Line 的樣本來自哪些 NUMA 節點, 由哪些 CPU 參與了讀寫
perf c2c和perf里現有的工具比較類似:
-
先用perf c2c record通過采樣,收集性能數據
-
再用perf c2c report基于采樣數據,生成報告
如果想了解perf c2c的詳細使用,請訪問:PERF-C2C(1)
這里還有一個完整的perf c2c的輸出的樣例。
最后,還有一個小程序的源代碼,可以產生大量的 Cache Line 偽共享,用以測試體驗:Fasle sharing .c src file
3.1 perf c2c 的輸出
下面,讓我們就之前給出的perf c2c的輸出樣例,做一個詳細介紹。
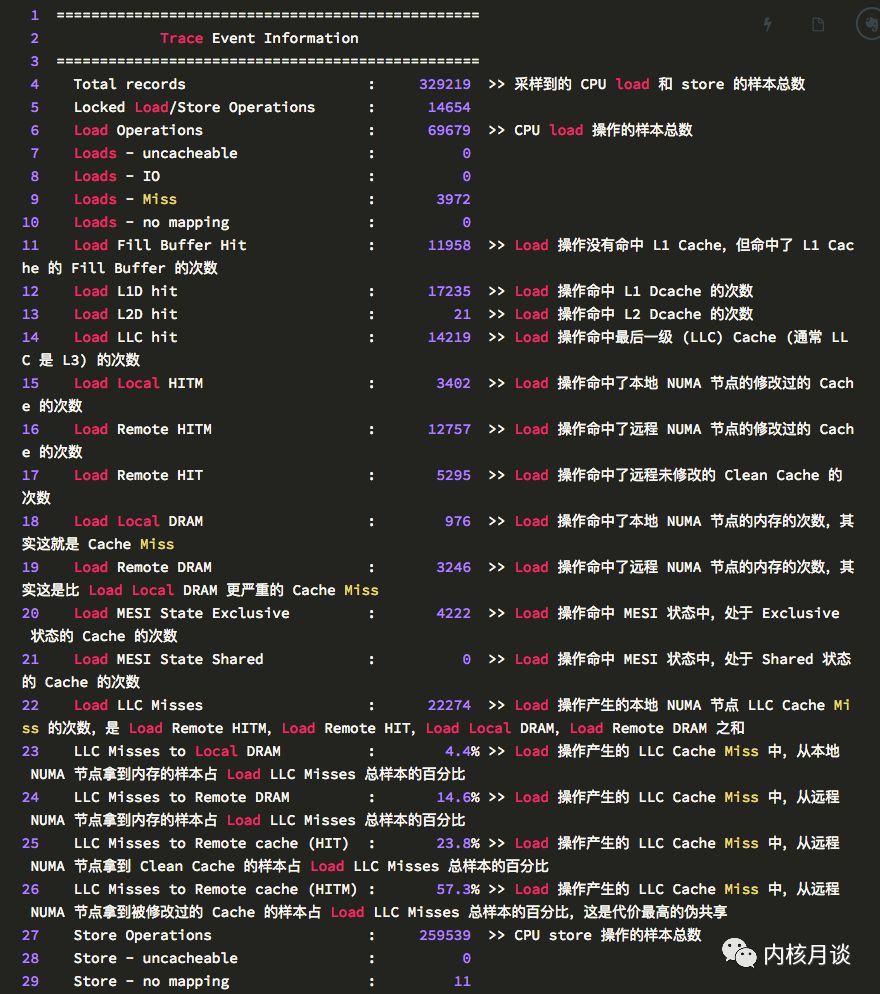
輸出里的第一個表,概括了 CPU 在perf c2c數據采樣期間做的 load 和 store 的樣本。能夠看到 load 操作都是在哪里取到了數據。
在perf c2c輸出里,HITM意為 “Hit In The Modified”,代表 CPU 在 load 操作命中了一條標記為Modified狀態的 Cache Line。如前所述,偽共享發生的關鍵就在于此。
而Remote HITM,意思是跨 NUMA 節點的HITM,這個是所有 load 操作里代價最高的情況,尤其在讀者和寫者非常多的情況下,這個代價會變得非常的高。
對應的,Local HITM,則是本地 NUMA 節點內的HITM,下面是對perf c2c輸出的詳細注解:
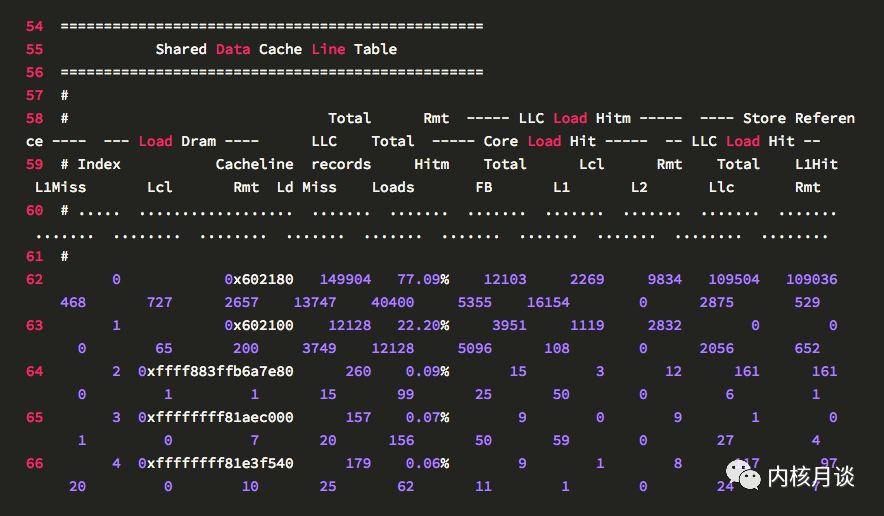
perf c2c輸出的第二個表, 以 Cache Line 維度,全局展示了 CPU load 和 store 活動的情況。這個表的每一行是一條 Cache Line 的數據,顯示了發生偽共享最熱的一些 Cache Line。默認按照發生Remote HITM的次數比例排序,改下參數也可以按照發生Local HITM的次數比例排序。
要檢查 Cache Line 偽共享問題,就在這個表里找Rmt LLC Load HITM(即跨 NUMA 節點緩存里取到數據的)次數比較高的,如果有,就得深挖一下。
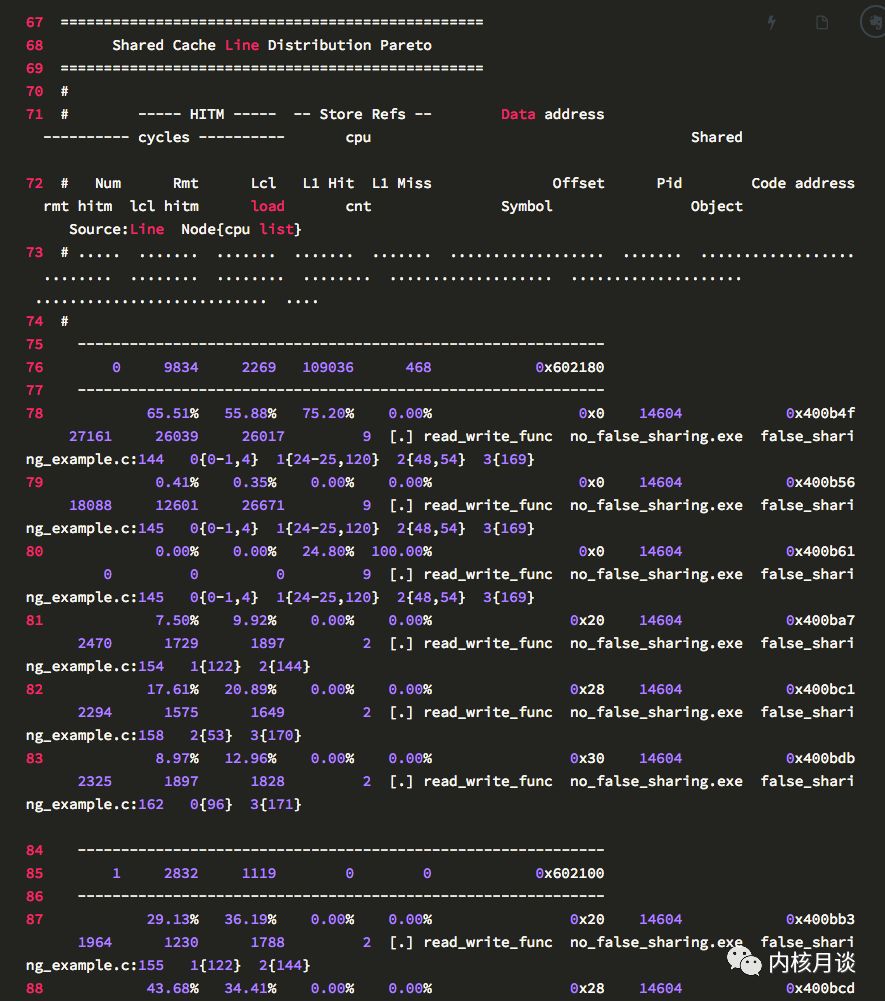
這是最重要的一個表。為了精簡,這里只展示了三條 Cache Line 相關的記錄,表格里包含了這些信息:
-
其中 71,72 行是列名,每列都解釋了Cache Line的一些活動。
-
標號為 76,85,91 的行顯示了每條 Cache Line 的HITM和 store 活動情況: 依次是 CPU load 和 store 活動的計數,以及 Cache Line 的虛擬地址。
-
78 到 83 行,是針對 76 行 Cache Line 訪問的細目統計,具體格式如下:
-
首先是百分比分布,包含了 HITM 中 remote 和 local 的百分比,store 里的 L1 Hit 和 Miss 的百分比分布。注意,這些百分比縱列相加正好是 100%。
-
然后是數據地址列。上面提到了 76 行顯示了 Cache Line 的虛擬地址,而下面幾行的這一列則是行內偏移。
-
下一列顯示了pid,或線程id(如果設置了要輸出tid)。
-
接下來是指令地址。
-
接下來三列,展示了平均load操作的延遲。我常看著里有沒有很高的平均延遲。這個平均延遲,可以反映該行的競爭緊張程度。
-
cpu cnt列展示了該行訪問的樣本采集自多少個cpu。
-
然后是函數名,二進制文件名,源代碼名,和代碼行數。
-
最后一列展示了對于每個節點,樣本分別來自于哪些cpu
-
以下為樣例輸出:
3.2 如何用perf c2c
下面是常見的perf c2c使用的命令行:

熟悉perf的讀者可能已經注意到,這里的-F選項指定了非常高的采樣頻率: 60000。請特別注意:這個采樣頻率不建議在線上或者生產環境使用,因為這會在高負載機器上帶來不可預知的影響。此外perf c2c對 CPU load 和 store 操作的采樣會不可避免的影響到被采樣應用的性能,因此建議在研發測試環境使用perf c2c去優化應用。
對采樣數據的分析,可以使用帶圖形界面的 tui 來看輸出,或者只輸出到標準輸出

默認情況,為了規范輸出格式,符號名被截斷為定長,但可以用 “–full-symbols” 參數來顯示完整符號名。
例如:
3.3 找到 Cache Line 訪問的調用棧
有的時候,很需要找到讀寫這些 Cache Line 的調用者是誰。下面是獲得調用圖信息的方法。但一開始,一般不會一上來就用這個,因為輸出太多,難以定位偽共享。一般都是先找到問題,再回過頭來使用調用圖。
3.4 如何增加采樣頻率
為了讓采樣數據更可靠,會把perf采樣頻率提升到-F 60000或者-F 80000,而系統默認的采樣頻率是 1000。
提升采樣頻率,可以短時間獲得更豐富,更可靠的采樣集合。想提升采樣頻率,可以用下面的方法。可以根據dmesg里有沒有perf interrupt took too long …信息來調整頻率。注意,如前所述,這有一定風險,嚴禁在線上或者生產環境使用。
然后運行前面講的perf c2c record命令。之后再運行,
3.5 如何讓避免采樣數據過量
在大型系統上(比如有 4,8,16 個物理 CPU 插槽的系統)運行perf c2c,可能會樣本太多,消耗大量的CPU時間,perf.data文件也可能明顯變大。 對于這個問題,有以下建議(包含但不僅限于):
-
將ldlat從 30 增加大到 50。這使得perf跳過沒有性能問題的 load 操作。
-
降低采樣頻率。
-
縮短perf record的睡眠時間窗口。比如,從sleep 5改成sleep 3。
3.6 使用 c2c 優化應用的收獲
一般搭建看見性能工具的輸出,都會問這些數據意味著什么。Joe 總結了他使用c2c優化應用時,學到的東西,
-
perf c2c采樣時間不宜過長。Joe 建議運行perf c2c3 秒、5 秒或 10 秒。運行更久,觀測到的可能就不是并發的偽共享,而是時間錯開的 Cache Line 訪問。
-
如果對內核樣本沒有興趣,只想看用戶態的樣本,可以指定--all-user。反之使用--all-kernel。
-
CPU 很多的系統上(如 >148 個),設置-ldlat為一個較大的值(50 甚至 70),perf可能能產生更豐富的C2C樣本。
-
讀最上面那個具有概括性的Trace Event表,尤其是LLC Misses to Remote cache HITM的數字。只要不是接近 0,就可能有值得追究的偽共享。
-
看Pareto表時,需要關注的,多半只是最熱的兩三個 Cache Line。
-
有的時候,一段代碼,它不在某一行 Cache Line 上競爭嚴重,但是它卻在很多 Cache Line 上競爭,這樣的代碼段也是很值得優化的。同理還有多進程程序訪問共享內存時的情況。
-
在Pareto表里,如果發現很長的 load 操作平均延遲,常常就表明存在嚴重的偽共享,影響了性能。
-
接下來去看樣本采樣自哪些節點和 CPU,據此進行優化,將哪些內存或 Task 進行 NUMA 節點鎖存。
最后,Pareto表還能對怎么解決對齊得很不好的Cache Line,提供靈感。 例如:
-
很容易定位到:寫地很頻繁的變量,這些變量應該在自己獨立的 Cache Line。可以據此進行對齊調整,讓他們不那么競爭,運行更快,也能讓其它的共享了該 Cache Line 的變量不被拖慢。
-
很容易定位到:沒有 Cache Line 對齊的,跨越了多個 Cache Line 的熱的 Lock 或 Mutex。
-
很容易定位到:讀多寫少的變量,可以將這些變量組合到相同或相鄰的 Cache Line。
3.7 使用原始的采樣數據
有時直接去看用perf c2c record命令生成的perf.data文件,其中原始的采樣數據也是有用的。可以用perf script命令得到原始樣本,man perf-script可以查看這個命令的手冊。輸出可能是編碼過的,但你可以按load weight排序(第 5 列),看看哪個 load 樣本受偽共享影響最嚴重,有最大的延遲。
-
處理器
+關注
關注
68文章
19312瀏覽量
230035 -
存儲器
+關注
關注
38文章
7494瀏覽量
163915 -
cpu
+關注
關注
68文章
10872瀏覽量
211999
原文標題:CPU Cache Line偽共享問題的總結和分析
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
cpu與cache內存交互的過程
關于cache和cache_line的一個概念問題
為什么需要cache?cache是如何影響code的呢
嵌入式CPU指令Cache的設計與實現
淺談tms320c6748最小系統設計和cache配置
CPU是如何調度任務的?
cache的排布與CPU的典型分布
CPU Cache偽共享問題
CPU設計之Cache存儲器
多個CPU各自的cache同步問題





 工商網監
工商網監
評論