 Python爬蟲爬取美劇網站
Python爬蟲爬取美劇網站
一直有愛看美劇的習慣,一方面鍛煉一下英語聽力,一方面打發一下時間。之前是能在視頻網站上面在線看的,可是自從廣電總局的限制令之后,進口的美劇英劇等貌似就不在像以前一樣同步更新了。但是,作為一個宅diao的我又怎甘心沒劇追呢,所以網上隨便查了一下就找到一個能用迅雷下載的美劇下載網站【天天美劇】,各種資源隨便下載,最近迷上的BBC的高清紀錄片,大自然美得不要不要的。
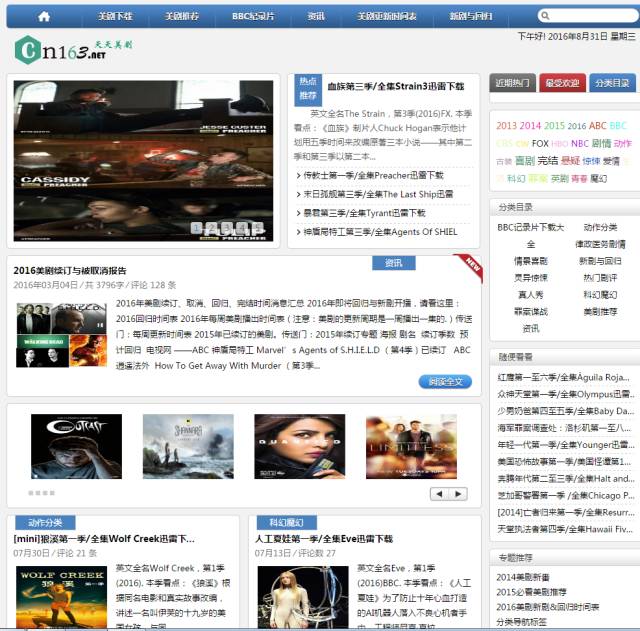
雖說找到了資源網站可以下載了,但是每次都要打開瀏覽器,輸入網址,找到該美劇,然后點擊鏈接才能下載。時間長了就覺得過程好繁瑣,而且有時候網站鏈接還會打不開,會有點麻煩。正好一直在學習Python爬蟲,所以今天就心血來潮來寫了個爬蟲,抓取該網站上所有美劇鏈接,并保存在文本文檔中,想要哪部劇就直接打開復制鏈接到迅雷就可以下載啦。
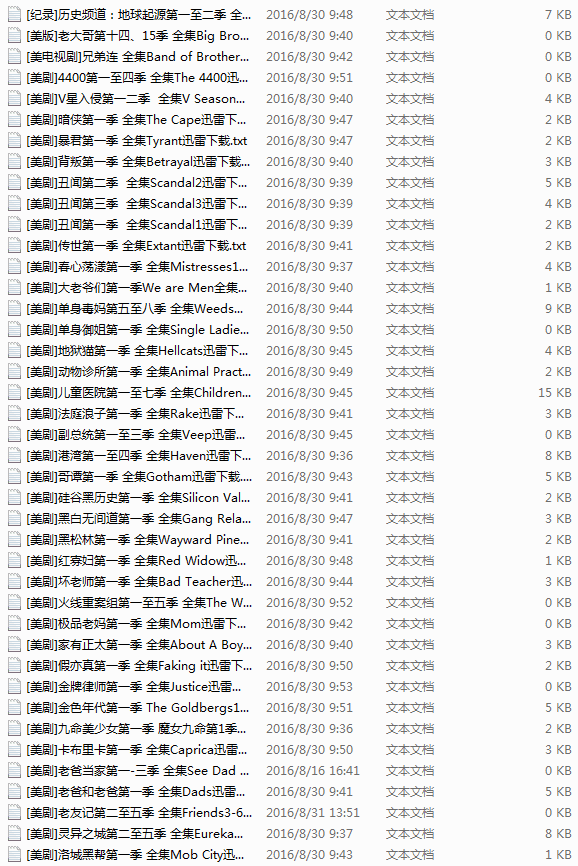
其實一開始打算寫那種發現一個url,使用requests打開抓取下載鏈接,從主頁開始爬完全站。但是,好多重復鏈接,還有其網站的url不是我想的那么規則,寫了半天也沒有寫出我想要的那種發散式的爬蟲,也許是自己火候還不到吧,繼續努力。。。
后來發現,其電視劇鏈接都是在文章里面,然后文章url后面有個數字編號,就像這樣的http://cn163.net/archives/24016/,所以機智的我又用了之前寫過的爬蟲經驗,解決方法就是自動生成url,其后面的數字不是可以變的嗎,而且每部劇的都是唯一的,所以嘗試了一下大概有多少篇文章,然后用range函數直接連續生成數來構造url。
但是很多url是不存在的,所以會直接掛掉,別擔心,我們用的可是requests,其自帶的status_code就是用來判斷請求返回的狀態的,所以只要是返回的狀態碼是404的我們都把它跳過,其他的都進去爬取鏈接,這就解決了url的問題了。
以下就是上述步驟的實現代碼。
def get_urls(self): try: for i in range(2015,25000): base_url='http://cn163.net/archives/' url=base_url+str(i)+'/' if requests.get(url).status_code == 404: continue else: self.save_links(url) except Exception,e: pass
其余的就進行的很順利了,網上找到前人寫的類似的爬蟲,但是只是爬取一篇文章的,所以借鑒了一下其正則表達式。自己用了BeautifulSoup還沒有正則效果好,所以果斷棄了,學海無涯啊。但是效果也不是那么理想,有一半左右的鏈接不能正確抓取,還需繼續優化。
# -*- coding:utf-8 -*- import requests import re import sys import threading import time reload(sys) sys.setdefaultencoding('utf-8') class Archives(object): def save_links(self,url): try: data=requests.get(url,timeout=3) content=data.text link_pat='"(ed2k://\|file\|[^"]+?\.(S\d+)(E\d+)[^"]+?1024X\d{3}[^"]+?)"' name_pat=re.compile(r'
(.*?)
',re.S) links = set(re.findall(link_pat,content)) name=re.findall(name_pat,content) links_dict = {} count=len(links) except Exception,e: pass for i in links: links_dict[int(i[1][1:3]) * 100 + int(i[2][1:3])] = i#把劇集按s和e提取編號 try: with open(name[0].replace('/',' ')+'.txt','w') as f: print name[0] for i in sorted(list(links_dict.keys())):#按季數+集數排序順序寫入 f.write(links_dict[i][0] + '\n') print "Get links ... ", name[0], count except Exception,e: pass def get_urls(self): try: for i in range(2015,25000): base_url='http://cn163.net/archives/' url=base_url+str(i)+'/' if requests.get(url).status_code == 404: continue else: self.save_links(url) except Exception,e: pass def main(self): thread1=threading.Thread(target=self.get_urls()) thread1.start() thread1.join() if __name__ == '__main__': start=time.time() a=Archives() a.main() end=time.time() print end-start完整版代碼,其中還用到了多線程,但是感覺沒什么用,因為Python的GIL的緣故吧,看似有兩萬多部劇,本以為要很長時間才能抓取完成,但是除去url錯誤的和沒匹配到的,總共抓取時間20分鐘不到。搞得我本來還想使用Redis在兩臺Linux上爬取,但是折騰了一番之后感覺沒必要,所以就這樣吧,后面需要更大數據的時候再去弄。
還有過程中遇到一個很折磨我的問題是文件名的保存,必須在此抱怨一下,txt文本格式的文件名能有空格,但是不能有斜線、反斜線、括號等。就是這個問題,一早上的時間都花在這上面的,一開始我以為是抓取數據的錯誤,后面查了半天才發現是爬取的劇名中帶有斜杠,這可把我坑苦了。
-
函數
+關注
關注
3文章
4327瀏覽量
62573 -
python
+關注
關注
56文章
4792瀏覽量
84629 -
爬蟲
+關注
關注
0文章
82瀏覽量
6867
原文標題:Python爬蟲爬取美劇網站
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論