 微軟美國研究院和清華聯合推出了一款開源的多領域端到端對話系統平臺—ConvLab
微軟美國研究院和清華聯合推出了一款開源的多領域端到端對話系統平臺—ConvLab
近年來對話系統迅速發展,同時也出現了一系列豐富的數據集。但對于剛剛進入這一領域團隊來說,迅速搭建起對于特定任務的可用的對話系統依然充滿挑戰。這主要是由于這一領域內缺乏結構完善、易于使用的開源系統,讓研究人員可以便捷的搭建和測評對話機器人。
眾所周知,基礎性的開源系統為AI研究的突破打下了堅實的基礎,在這一領域的Moses、HTK和CoreNLP等項目都被廣泛用于機器翻譯、語音識別和自然語言處理,推動了各層次研究的飛速發展。
為了促進這一領域的發展,微軟美國研究院和清華聯合推出了一款開源的多領域端到端對話系統平臺—ConvLab,使得研究人員可以便捷地搭建對話系統、自動訓練對話模型、構建并評測對話機器人的各方面表現。
ConvLab
為了便于用于構建不同類型任務導向的機器人、將更多的自動化引入構建、訓練和測評過程中,ConvLab包含了豐富的模型工具和運行引擎、以及端到端的測評平臺。簡單來講臺中包含了基于模塊和端到端兩種架構類型的對話系統:基于模塊的架構系統包含了自然語言理解(NLU)、對話系統追蹤(DST)、對話策略(POL)和自然語言生成(NLG)等模塊;完全端到端神經架構減少了手工編程的工作量,并減小了誤差在工作流程中的傳播。
與先前工具集集中于系統策略或者受限于固定的預訓練模型不同,ConvLab基于全標注的數據集覆蓋了所有可訓練的統計模型,解決了先前對于系統性能度量的困難。
很多時候用戶需要在多子域之間無縫銜接實現高層用戶目標,多層級的對話系統對數據收集、標注以及模型的開發都提出了復雜的要求。有研究人員提出了MultiWOZ數據集(包含了旅行相關的多鄰域對話內容),但目前卻缺乏對應的開源平臺來處理多域多意圖對話。為了加速多領域對話的研究ConvLab研究了MultiWOZ任務的特征,并提供了一系列完整的參考模型(包含了獨立的模塊和端到端模型)、這些模型在為用戶對話額外標注的MultiWOZ數據集上進行了訓練。ConvLab目前還作為DSTC18多領域端到端對話追蹤的標準平臺,得到了更廣泛的應用和實際的檢驗。為了更好的支持端到端評價、ConvLab提供了兩個互補模塊、分別集成了亞馬遜Amazon Mechanical Turk平臺用于人類測評、同時也集成了虛擬用戶用于自動測評。針對用戶仿真,平臺同時提供了基于規則和基于數據驅動的模擬器。ConvLab在開發模擬用戶的過程中也研發出了一系列先進的用戶模擬技術。
架構設計
整個系統基于模塊化的設計保障了靈活性和適應性。為了支持多領域對話系統的搭建,平臺使用了主體-環境-對話實體的組合設計(Agents-Environments-Bodies,AEB),除了單環境和單主體的配置外,系統還包含了一系列先進的研究實驗、包括多任務學習、多主體學習和角色扮演、無需復雜的代碼即可導入到實例中使用。

此外,為了系統性地對比不同的主體和環境,并實現自動超參數搜索,平臺充分利用了SLM Lab和Ray^2 作為實驗組件。他們提供了多層級的控制,從會話、嘗試和試驗上為每一層次生成評測報告。
其中會話用于初始化主體和環境、并以預設的輪次運行。隨后利用隨機種子來啟動多個會話進行嘗試、并最終在會話上分析并求平均。最后利用實驗來確定不同超參數的表現。
對話主體和環境的配置
在系統中每個層代表了構建對話系統的不同方式,在下圖中可以看到最上層代表了傳統方式構建對話系統的架構路線圖,包括了NLU,DST,POL,NLG。研究人員近年來通過引入詞級對話狀態追蹤、對話策略和端到端模型等典型組件,探索了構建對話系統不同可能的組合實現形式。在ConvLab平臺上,研究人員可以聚焦于下圖中的任意組件,并以端到端的簡單方式進行測試。
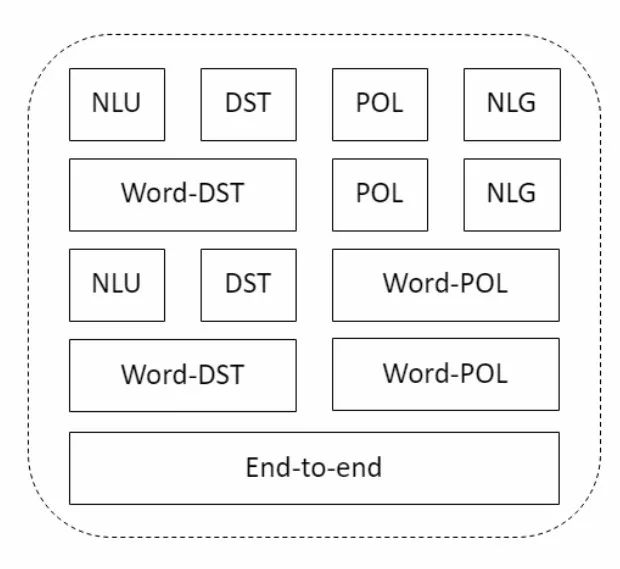
對于環境構建來說,可以由很可能的組件來進行構建。在研究對話策略優化的強化學習算法中,典型的方法是利用用戶模擬器在對話行為層級上進行操作。對話主體會盡可能利用端到端的方式嘗試減小對標注數據的需求,對于人類評測來說平臺提供了基于Amazon Mechanical Turk來作為最后一層進行環境構建。

參考模型和跨域數據實驗
在ConvLab中還涵蓋了針對多重任務的模型供研究人員進行參考評測,包括了自然語言理解領域的Semantic Tuple Classi-?er (STC)、 OneNet以及作為拓展的Multi-intent LU (MILU);對話狀態追蹤引入了DSTCs基準模型、詞級對話狀態追蹤領域集成了MDBT模型將域識別與置信狀態追蹤進行結合;在系統策略方面平臺支持DQN,REINFORCE\PPO以及自模仿等;自然語言生成領域則使用了SC-LSTM方法。在詞級策略上使用了Budzianowski等人提出的基準;在用戶策略上ConvLab提供了基于agenda的方法和基于數據驅動(例如HUS等)的方法,模型在對話行為級別進行并可與NLU等模塊協同構架出完整的用戶模擬器;最后再端到端模型上則包含了Mem2Seq,Sequicity,并使得Sequicity實現了對于多域的支持。目前ConvLab主要支持MultiWOZ和Movie兩個不同復雜度的數據域。其中MultiWOZ的主要任務是幫助旅客,其中引入了包含景點介紹和酒店預訂等不同方面的內容。MultiWOZ中主要包含了7個子領域的問題:景點、醫院、酒店、警察、餐廳、出租車、火車等方面的內容。其中包含了10438個標注對話。對于單領域和多領域的對話輪次平均為8.93和15.93輪。ConvLab對于用戶對話行為進行了額外的標注、并為對話系統元件和用戶模擬器提供了預訓練基準模型、以及基于此數據訓練的端到端的自然對話模型。Movie則來自于微軟對話挑戰賽,主要集中于電影票預訂場景,包含了2890個標注對話,評論為7.5輪,同時還提供了針對主體和用戶模擬器的一系列完整的參考模型。研究人員表示在未來還會加入Taxi和Restaurant等領域的任務不斷豐富平臺支持的領域。
-
微軟
+關注
關注
4文章
6624瀏覽量
104307 -
開源
+關注
關注
3文章
3395瀏覽量
42634 -
模塊化
+關注
關注
0文章
333瀏覽量
21409
原文標題:微軟與清華開源多領域端到端對話系統集成平臺ConvLab,幫助研究人員迅速搭建對話系統
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
安謀科技與智源研究院達成戰略合作,共建開源AI“芯”生態

端到端自動駕駛技術研究與分析
智己汽車“端到端”智駕方案推出,老司機真的會被取代嗎?
端到端InfiniBand網絡解決LLM訓練瓶頸

字節跳動與清華AIR成立聯合研究中心
香港城市大學與富士康鴻海研究院成立聯合研究中心

易華錄無錫數據湖與清華大學蘇州汽車研究院(吳江)合作挖掘智能駕駛數據新價值
英維克、英特爾、寶德聯合推出首款多平臺液冷鋁冷板系統
華為IPv6+端到端解決方案通過信通院IPv6+ 2.0 Advanced測試評估

北京開源芯片研究院正式加入甲辰計劃!

人工智能模型公司Anthropic近日推出了一款Claude移動端App
智行者聯合清華完成國內首套全棧式端到端自動駕駛系統的開放道路測試





 工商網監
工商網監
評論