 谷歌AI與機器人實驗室聯合發布的最新研究結果,效果可媲美LiDAR
谷歌AI與機器人實驗室聯合發布的最新研究結果,效果可媲美LiDAR
從視頻中估計3D結構和相機運動是計算機視覺中的一個關鍵問題,這個技術在自動駕駛領域有著廣闊的工業應用前景。今日,谷歌AI與機器人實驗室聯合發布的最新成果:無需相機參數、單目、以無監督學習的方式從未標記場景視頻中搞定深度圖,效果堪比激光雷達。
目前自動駕駛的核心技術是LiDAR(激光雷達),一種運用雷達原理,采用光和激光作為主要傳感器的汽車視覺系統。LiDAR傳感器賦予了自動駕駛汽車能夠看到周邊環境的“雙眼”,激光雷達技術越先進,視覺感知的精準程度越高,這是自動駕駛得以實現的底層技術基礎。
但是最近幾年,放在攝像頭上的深度學習研究,發展很蓬勃。相比之下, 雖然激光雷達 (LiDAR)的數據有諸多優點,但相關學術進展并不太多。相機+數據+神經網絡的組合,正在迅速縮小與LiDAR的能力差距。
無需相機參數、單目、以無監督學習的方式從未標記場景視頻中搞定深度圖!
這是谷歌AI與機器人實驗室聯合發布的最新研究結果,效果可媲美LiDAR。
什么是深度圖?
深度圖像(depth image)也被稱為距離影像(range image),由相機拍攝,是指將從圖像采集器到場景中各點的距離(深度)作為像素值的圖像,它直接反映了景物可見表面的幾何形狀。單位為mm,效果參考下圖:
在場景視頻景深學習領域,谷歌AI和機器人實驗室聯合公布了三項最新研究突破:
第一,證明了可以以一種無監督的方式訓練深度網絡,這個深度網絡可以從視頻本身預測相機的內在參數,包括鏡頭失真(見圖1)。
第二,在這種情況下,他們是第一個以幾何方式從預測深度直接解決遮擋的問題。
第三,大大減少了處理場景中移動元素所需的語義理解量:只需要一個覆蓋可能屬于移動對象的像素的單個掩碼,而不是分割移動對象的每個實例并跨幀跟蹤它。
圖1:從未知來源的視頻中學習深度的方法的定性結果,通過同時學習相機的外在和內在參數來實現。由于該方法不需要知道相機參數,因此它可以應用于任何視頻集。所有深度圖(在右側可視化,作為差異)都是從原始視頻中學習而不使用任何相機內在函數。從上到下:來自YouTube8M的幀,來自EuRoC MAV數據集,來自Cityscapes和來自KITTI的幀。
推特網友對此不吝贊美:“這是我見過的最令人印象深刻的無監督結果之一。來自未標記視頻的深度圖對于自動駕駛非常有用:)“
以下是論文具體內容:
從視頻中估計3D結構和相機運動是計算機視覺中的一個關鍵問題,這個技術在自動駕駛領域有著廣闊的工業應用前景。
解決該問題的傳統方法依賴于在多個連續幀中識別場景中的相同點,并求解在這些幀上最大程度一致的3D結構和相機運動。
但是,幀之間的這種對應關系只能針對所有像素的子集建立,這導致了深度估計不確定的問題。與通常處理逆問題一樣,這些缺口是由連續性和平面性等假設填充的。
深度學習能夠從數據中獲得這些假設,而不是手工指定這些假設。在信息不足以解決模糊性的地方,深度網絡可以通過對先前示例進行歸納,以生成深度圖和流場。
無監督方法允許單獨從原始視頻中學習,使用與傳統方法類似的一致性損失,但在訓練期間對其進行優化。在推論中,經過訓練的網絡能夠預測來自單個圖像的深度以及來自成對或更長圖像序列的運動。
隨著對這個方向的研究越來越有吸引力,很明顯,物體運動是一個主要障礙,因為它違反了場景是靜態的假設。已經提出了幾個方向來解決該問題,包括通過實例分割利用對場景的語義理解。
遮擋是另一個限制因素,最后,在此方向的所有先前工作中,必須給出相機的內在參數。這項工作解決了這些問題,因此減少了監督,提高了未標記視頻的深度和運動預測質量。
首先,我們證明了可以以一種無監督的方式訓練深度網絡,這個深度網絡從視頻本身預測相機的內在參數,包括鏡頭失真(見圖1)。
其次,在這種情況下,我們是第一個以幾何方式從預測深度直接解決遮擋的問題。
最后,我們大大減少了處理場景中移動元素所需的語義理解量:我們需要一個覆蓋可能屬于移動對象的像素的單個掩碼,而不是分割移動對象的每個實例并跨幀跟蹤它。
這個掩模可能非常粗糙,實際上可以是矩形邊界框的組合。獲得這樣的粗糙掩模是一個簡單得多的問題,而且與實例分割相比,使用現有的模型可以更可靠地解決這個問題。
除了這些定性進展之外,我們還對我們的方法進行了廣泛的定量評估,并發現它在多個廣泛使用的基準數據集上建立了新的技術水平。將數據集匯集在一起,這種能力通過我們的方法得到了極大的提升,證明可以提高質量。
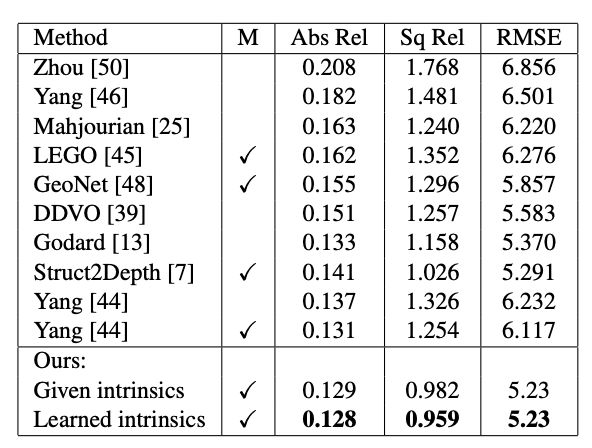
表1:總結了在KITTI上訓練的模型和評估結果,使用給定相機內建和學習相機內建兩種方式來評估我們方法的深度估計,結果顯而易見,我們獲得了當前最佳SOTA。
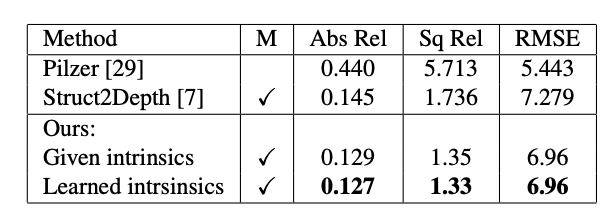
表2:總結了在Cityscapes上訓練和測試的模型的評估結果,我們的方法優于以前的方法,并從學習的內建中獲益。
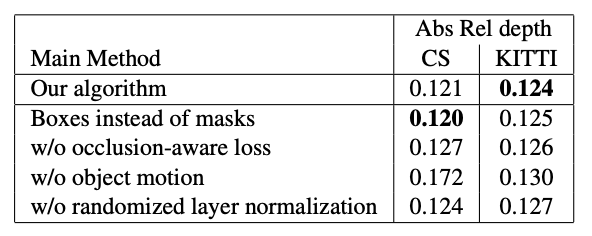
表3:深度估計的消融實驗。在所有實驗中,訓練集是Cityscapes(CS)和KITTI組合,我們分別在Cityscapes(CS)和KITTI(Eigen partition)上測試模型。每行代表一個實驗,其中與主方法相比進行了一次更改,如“實驗”行中所述。數字越小越好。
除了這些定性的進步,我們對我們的方法進行了廣泛的定量評估,發現它在多個廣泛使用的基準數據集上建立了一個新的技術狀態。將數據集集中在一起,這種方法大大提高了數據集的質量。
最后,我們首次演示了可以在YouTube視頻上學習深度和相機內在預測,這些視頻是使用多個不同的相機拍攝的,每個相機的內建都是未知的,而且通常是不同的。
來自YouTube8M收集的圖像和學習的視差圖。
論文摘要
《場景視頻景深學習——非特定相機單眼圖片景深無監督學習》
我們提出了一種新穎的方法,僅使用相鄰視頻幀的一致性作為監督信號,用于同時學習單眼視頻的深度,運動,物體運動和相機內建。與先前的工作類似,我們的方法通過將可微變形應用于幀,并將結果與相鄰結果進行比較來學習,但它提供了若干改進:我們直接使用在訓練期間預測的深度圖,以幾何和可微的方式處理遮擋。我們介紹了隨機層標準化,一種新穎的強大正則化器,并考慮了目標相對于場景的運動。據我們所知,我們的工作是第一個以無監督的方式從視頻中學習相機固有參數(包括鏡頭失真)的工作,從而使我們能夠從規模未知原點的任意視頻中提取準確的深度圖和運動信息。
我們在Cityscapes,KITTI和EuRoC數據集上評估我們的結果,建立深度預測和測距的新技術水平,并定性地證明,深度預測可以從YouTube上的一系列視頻中學到。
-
傳感器
+關注
關注
2550文章
51035瀏覽量
753077 -
谷歌
+關注
關注
27文章
6161瀏覽量
105300 -
自動駕駛
+關注
關注
784文章
13784瀏覽量
166388
原文標題:谷歌AI:根據視頻生成深度圖,效果堪比激光雷達
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
谷歌公布機器人研究細節 軟件如何支持機器人互相學習?
代替人類完成危險性較大實驗的雙臂機器人——Mahoro
LabVIEW 的Tripod 機器人視覺處理和定位研究
【HarmonyOS HiSpark AI Camera】基于Hi3516DV300的機器人集群系統
基于DSP和FPGA的四關節實驗室機器人控制器的研制





 工商網監
工商網監
評論