 換個角度來聊機器翻譯
換個角度來聊機器翻譯
公元652年,玄奘在慈恩寺西院建造了大雁塔,用于收藏他從天竺帶回來的657部佛經經卷,之后的12年里玄奘一直在此翻譯佛經。
當巴別塔出現的時候,人類開始有了不同的語言,而大雁塔出現的時候,人類已經在不同的語言中開始翻譯。
這周的課程,我們來講一個同學們都比較熟悉的知識點——機器翻譯。
之前咱們AI大學劉俊華導師從“三大核心翻譯技術”的角度,給大家普及了基于規則的翻譯方法(RMT)、基于統計的翻譯方法(SMT)、基于神經網絡的翻譯方法(NMT)的三種翻譯技術的相應原理。
今天我們換個角度來聊機器翻譯,從歷史角度來看看這個比人工智能概念誕生還早的自然語言處理任務。

機器翻譯發展歷史圖譜
一、從傳說開始的故事
《圣經》中記載了這樣一個故事:
人類曾經聯合起來興建能通往天堂的高塔——巴別塔,為了阻止人類的計劃,上帝讓人類說不同的語言,使人類相互之間不能溝通,計劃因此失敗,人類自此各散東西。
實現不同語種之間的無障礙溝通,一直都是人類終極夢想之一。
在認識到不眠不休窮盡人類一生的力量,也只能掌握幾十種語言時,很多科學家開始思考,是不是可以用機器來幫助人們去解決溝通問題?
這一問題在1933年首次得到了答案,蘇聯科學家Peter Troyanskii向蘇聯科學院介紹了能將一種語言翻譯成另一種語言的機器。
這個法明很簡單,在當時并未受到蘇聯政府的重視,他們覺得這臺擁有各種語言卡片的機器沒有實際作用。
Troyanskii用20多年的時間將這臺翻譯機器發明出來,后死于心絞痛。
我們今天能如此清晰的復述這段故事,是因為在1956年蘇聯2位科學家發現了Troyanskii所創造的翻譯機器,并將它公之于世。
如果不是這樣,或許我們到現在都不會知道,早在1933年就有人想過將語言卡片、打字機、老式膠片組合在一起,發明一臺翻譯機器。
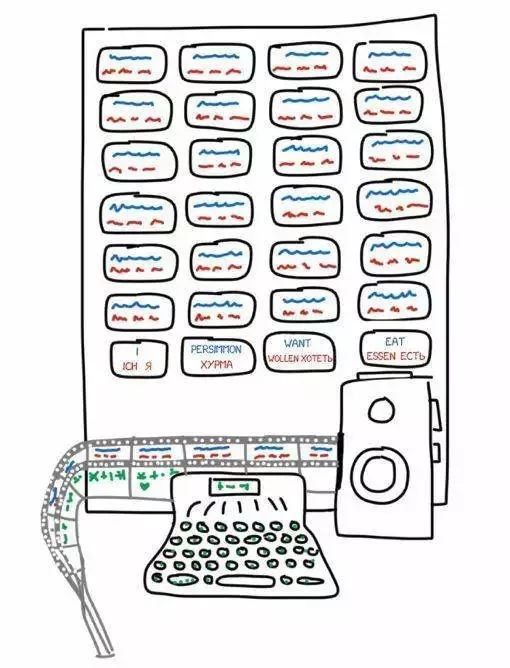
Troyanskii發明的翻譯機器簡化圖
二、萌芽于冷戰中的軍備競賽
正像計算機是被戰爭催生出一樣,機器翻譯技術的萌芽也與軍事有關。
1947年杜魯門主義出臺,美蘇冷戰正式開始,對于俄文情報資料的翻譯,需求量很大。
1954年,美國喬治敦大學在IBM公司協同下用IBM-701計算機首次完成了英俄機器翻譯試驗,拉開了機器翻譯研究的序幕。
當時的系統,僅能容納250個單詞,遵循6條語法規則,翻譯49個句子。
但這一切已足以點燃科學家們的激情,機器翻譯成功引起了蘇聯、日本和歐洲國家的研究興趣。一時間,各國政府紛紛撥款,全球機器翻譯熱潮興起。
然而,技術的發展都是曲折艱難的,和這種狂熱的關注相比機器翻譯的研究進展著實緩慢,美國科學院成立了語言自動處理咨詢委員會(ALPAC)于1966年公布了一份名為《語言與機器》的報告,該研究否認機器翻譯可行性,機器翻譯研究進入蕭條期。
雖然這一階段的機器翻譯發展并不順利,但還是為現代自然語言處理技術打下了堅實的基礎。

三、20世紀末的又一次興起
20世紀70年代IBM沃森實驗室的賈里尼克,他提出了基于統計的語音識別框架,這個框架對語音和語言處理都有著深遠影響,它從根本上使得語音識別有實用的可能。從此,自然語言處理開始走上統計方法之路。
1993年,IBM的Brown等提出基于詞對齊的統計翻譯模型,基于語料庫的方法開始盛行,標志著第二代機器翻譯技術——「基于統計的機器翻譯」開始興起,其核心在于設計概率模型對翻譯過程建模。
統計機器翻譯避開了語言規則,使用大量的雙語文本,建立兩種語言的平行語料庫,雖然避開了繁雜的語法規則,但需要大規模的語料庫,這在當時非常難以實現。
2014年谷歌和蒙特利爾大學提出的第三代機器翻譯技術,也就是基于端到端的神經機器翻譯,標志著第三代機器翻譯技術的到來。
2016年月28日,谷歌發布新的神經機器翻譯系統GNMT,同時支持PC端和移動端,這項服務背后的核心算法是基于短語的機器翻譯。
同時期國內科技企業在機器翻譯上的進展也非常迅速,以語音和語義理解見長的科大訊飛在2014年國際口語翻譯大賽IWSLT上獲得中英和英中兩個翻譯方向的全球第一名,在2015年又在由美國國家標準技術研究院組織的機器翻譯大賽中取得全球第一的成績。
自此,神經機器翻譯開始大規模走向應用。

四、重建巴別塔之路
從1993年到2019年,機器翻譯技術發展了80多年,巴別塔的傳說已經成了過去,我們今天重溫機器翻譯的發展歷史,并不是為了再去修建一座真的「通天塔」,而是想讓同學們更加深刻地了解機器翻譯這門學科。
-
人工智能
+關注
關注
1791文章
47183瀏覽量
238264 -
機器翻譯
+關注
關注
0文章
139瀏覽量
14880 -
自然語言處理
+關注
關注
1文章
618瀏覽量
13552
原文標題:A.I.公開課預告 | 機器翻譯的光榮與夢想
文章出處:【微信號:iFLYTEK1999,微信公眾號:科大訊飛】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
谷景科普工字電感換個比原來大的行嗎
方向角度傳感器故障怎么解決
方向角度傳感器壞了有什么影響
DeepL推出新一代翻譯編輯大型語言模型
nlp自然語言處理基本概念及關鍵技術
nlp自然語言處理的應用有哪些
RNN神經網絡適用于什么
從市場角度簡要解讀“人形機器人”
從市場角度簡要解讀“人形機器人”

開源項目!設計一款智能手語翻譯眼鏡
機器學習怎么進入人工智能
從老板角度來解讀工廠物料流轉機器人
Transformer壓縮部署的前沿技術:RPTQ與PB-LLM





 工商網監
工商網監
評論