") 幾個(gè)常用算法的適應(yīng)場(chǎng)景及其優(yōu)缺點(diǎn)!
幾個(gè)常用算法的適應(yīng)場(chǎng)景及其優(yōu)缺點(diǎn)!
本文的目的,是務(wù)實(shí)、簡(jiǎn)潔地盤(pán)點(diǎn)一番當(dāng)前機(jī)器學(xué)習(xí)算法。文中內(nèi)容結(jié)合了個(gè)人在查閱資料過(guò)程中收集到的前人總結(jié),同時(shí)添加了部分自身總結(jié),在這里,依據(jù)實(shí)際使用中的經(jīng)驗(yàn),將對(duì)此類(lèi)模型優(yōu)缺點(diǎn)及選擇詳加討論
主要回顧下幾個(gè)常用算法的適應(yīng)場(chǎng)景及其優(yōu)缺點(diǎn)!
機(jī)器學(xué)習(xí)算法太多了,分類(lèi)、回歸、聚類(lèi)、推薦、圖像識(shí)別領(lǐng)域等等,要想找到一個(gè)合適算法真的不容易,所以在實(shí)際應(yīng)用中,我們一般都是采用啟發(fā)式學(xué)習(xí)方式來(lái)實(shí)驗(yàn)。通常最開(kāi)始我們都會(huì)選擇大家普遍認(rèn)同的算法,諸如SVM,GBDT,Adaboost,現(xiàn)在深度學(xué)習(xí)很火熱,神經(jīng)網(wǎng)絡(luò)也是一個(gè)不錯(cuò)的選擇。
假如你在乎精度(accuracy)的話,最好的方法就是通過(guò)交叉驗(yàn)證(cross-validation)對(duì)各個(gè)算法一個(gè)個(gè)地進(jìn)行測(cè)試,進(jìn)行比較,然后調(diào)整參數(shù)確保每個(gè)算法達(dá)到最優(yōu)解,最后選擇最好的一個(gè)。但是如果你只是在尋找一個(gè)“足夠好”的算法來(lái)解決你的問(wèn)題,或者這里有些技巧可以參考,下面來(lái)分析下各個(gè)算法的優(yōu)缺點(diǎn),基于算法的優(yōu)缺點(diǎn),更易于我們?nèi)ミx擇它。
1.天下沒(méi)有免費(fèi)的午餐
在機(jī)器學(xué)習(xí)領(lǐng)域,一個(gè)基本的定理就是“沒(méi)有免費(fèi)的午餐”。換言之,就是沒(méi)有算法能完美地解決所有問(wèn)題,尤其是對(duì)監(jiān)督學(xué)習(xí)而言(例如預(yù)測(cè)建模)。
舉例來(lái)說(shuō),你不能去說(shuō)神經(jīng)網(wǎng)絡(luò)任何情況下都能比決策樹(shù)更有優(yōu)勢(shì),反之亦然。它們要受很多因素的影響,比如你的數(shù)據(jù)集的規(guī)模或結(jié)構(gòu)。
其結(jié)果是,在用給定的測(cè)試集來(lái)評(píng)估性能并挑選算法時(shí),你應(yīng)當(dāng)根據(jù)具體的問(wèn)題來(lái)采用不同的算法。
當(dāng)然,所選的算法必須要適用于你自己的問(wèn)題,這就要求選擇正確的機(jī)器學(xué)習(xí)任務(wù)。作為類(lèi)比,如果你需要打掃房子,你可能會(huì)用到吸塵器、掃帚或是拖把,但你絕對(duì)不該掏出鏟子來(lái)挖地。
2. 偏差&方差
在統(tǒng)計(jì)學(xué)中,一個(gè)模型好壞,是根據(jù)偏差和方差來(lái)衡量的,所以我們先來(lái)普及一下偏差(bias)和方差(variance):
1.偏差:描述的是預(yù)測(cè)值(估計(jì)值)的期望E’與真實(shí)值Y之間的差距。偏差越大,越偏離真實(shí)數(shù)據(jù)。
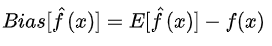
2.方差:描述的是預(yù)測(cè)值P的變化范圍,離散程度,是預(yù)測(cè)值的方差,也就是離其期望值E的距離。方差越大,數(shù)據(jù)的分布越分散。
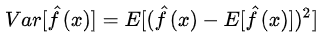
模型的真實(shí)誤差是兩者之和,如公式:
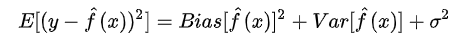
通常情況下,如果是小訓(xùn)練集,高偏差/低方差的分類(lèi)器(例如,樸素貝葉斯NB)要比低偏差/高方差大分類(lèi)的優(yōu)勢(shì)大(例如,KNN),因?yàn)楹笳邥?huì)發(fā)生過(guò)擬合(overfiting)。然而,隨著你訓(xùn)練集的增長(zhǎng),模型對(duì)于原數(shù)據(jù)的預(yù)測(cè)能力就越好,偏差就會(huì)降低,此時(shí)低偏差/高方差的分類(lèi)器就會(huì)漸漸的表現(xiàn)其優(yōu)勢(shì)(因?yàn)樗鼈冇休^低的漸近誤差),而高偏差分類(lèi)器這時(shí)已經(jīng)不足以提供準(zhǔn)確的模型了。
為什么說(shuō)樸素貝葉斯是高偏差低方差?
首先,假設(shè)你知道訓(xùn)練集和測(cè)試集的關(guān)系。簡(jiǎn)單來(lái)講是我們要在訓(xùn)練集上學(xué)習(xí)一個(gè)模型,然后拿到測(cè)試集去用,效果好不好要根據(jù)測(cè)試集的錯(cuò)誤率來(lái)衡量。但很多時(shí)候,我們只能假設(shè)測(cè)試集和訓(xùn)練集的是符合同一個(gè)數(shù)據(jù)分布的,但卻拿不到真正的測(cè)試數(shù)據(jù)。這時(shí)候怎么在只看到訓(xùn)練錯(cuò)誤率的情況下,去衡量測(cè)試錯(cuò)誤率呢?
由于訓(xùn)練樣本很少(至少不足夠多),所以通過(guò)訓(xùn)練集得到的模型,總不是真正正確的。(就算在訓(xùn)練集上正確率100%,也不能說(shuō)明它刻畫(huà)了真實(shí)的數(shù)據(jù)分布,要知道刻畫(huà)真實(shí)的數(shù)據(jù)分布才是我們的目的,而不是只刻畫(huà)訓(xùn)練集的有限的數(shù)據(jù)點(diǎn))。
而且,實(shí)際中,訓(xùn)練樣本往往還有一定的噪音誤差,所以如果太追求在訓(xùn)練集上的完美而采用一個(gè)很復(fù)雜的模型,會(huì)使得模型把訓(xùn)練集里面的誤差都當(dāng)成了真實(shí)的數(shù)據(jù)分布特征,從而得到錯(cuò)誤的數(shù)據(jù)分布估計(jì)。這樣的話,到了真正的測(cè)試集上就錯(cuò)的一塌糊涂了(這種現(xiàn)象叫過(guò)擬合)。但是也不能用太簡(jiǎn)單的模型,否則在數(shù)據(jù)分布比較復(fù)雜的時(shí)候,模型就不足以刻畫(huà)數(shù)據(jù)分布了(體現(xiàn)為連在訓(xùn)練集上的錯(cuò)誤率都很高,這種現(xiàn)象較欠擬合)。過(guò)擬合表明采用的模型比真實(shí)的數(shù)據(jù)分布更復(fù)雜,而欠擬合表示采用的模型比真實(shí)的數(shù)據(jù)分布要簡(jiǎn)單。
在統(tǒng)計(jì)學(xué)習(xí)框架下,大家刻畫(huà)模型復(fù)雜度的時(shí)候,有這么個(gè)觀點(diǎn),認(rèn)為Error = Bias + Variance。這里的Error大概可以理解為模型的預(yù)測(cè)錯(cuò)誤率,是有兩部分組成的,一部分是由于模型太簡(jiǎn)單而帶來(lái)的估計(jì)不準(zhǔn)確的部分(Bias),另一部分是由于模型太復(fù)雜而帶來(lái)的更大的變化空間和不確定性(Variance)。
所以,這樣就容易分析樸素貝葉斯了。它簡(jiǎn)單的假設(shè)了各個(gè)數(shù)據(jù)之間是無(wú)關(guān)的,是一個(gè)被嚴(yán)重簡(jiǎn)化了的模型。所以,對(duì)于這樣一個(gè)簡(jiǎn)單模型,大部分場(chǎng)合都會(huì)Bias部分大于Variance部分,也就是說(shuō)高偏差而低方差。
在實(shí)際中,為了讓Error盡量小,我們?cè)谶x擇模型的時(shí)候需要平衡Bias和Variance所占的比例,也就是平衡over-fitting和under-fitting。
當(dāng)模型復(fù)雜度上升的時(shí)候,偏差會(huì)逐漸變小,而方差會(huì)逐漸變大。
3. 常見(jiàn)算法優(yōu)缺點(diǎn)
3.1 樸素貝葉斯
樸素貝葉斯屬于生成式模型(關(guān)于生成模型和判別式模型,主要還是在于是否需要求聯(lián)合分布),比較簡(jiǎn)單,你只需做一堆計(jì)數(shù)即可。如果注有條件獨(dú)立性假設(shè)(一個(gè)比較嚴(yán)格的條件),樸素貝葉斯分類(lèi)器的收斂速度將快于判別模型,比如邏輯回歸,所以你只需要較少的訓(xùn)練數(shù)據(jù)即可。即使NB條件獨(dú)立假設(shè)不成立,NB分類(lèi)器在實(shí)踐中仍然表現(xiàn)的很出色。它的主要缺點(diǎn)是它不能學(xué)習(xí)特征間的相互作用,用mRMR中R來(lái)講,就是特征冗余。引用一個(gè)比較經(jīng)典的例子,比如,雖然你喜歡Brad Pitt和Tom Cruise的電影,但是它不能學(xué)習(xí)出你不喜歡他們?cè)谝黄鹧莸碾娪啊?/p>
優(yōu)點(diǎn):
1. 樸素貝葉斯模型發(fā)源于古典數(shù)學(xué)理論,有著堅(jiān)實(shí)的數(shù)學(xué)基礎(chǔ),以及穩(wěn)定的分類(lèi)效率;
2. 對(duì)大數(shù)量訓(xùn)練和查詢時(shí)具有較高的速度。即使使用超大規(guī)模的訓(xùn)練集,針對(duì)每個(gè)項(xiàng)目通常也只會(huì)有相對(duì)較少的特征數(shù),并且對(duì)項(xiàng)目的訓(xùn)練和分類(lèi)也僅僅是特征概率的數(shù)學(xué)運(yùn)算而已;
3. 對(duì)小規(guī)模的數(shù)據(jù)表現(xiàn)很好,能個(gè)處理多分類(lèi)任務(wù),適合增量式訓(xùn)練(即可以實(shí)時(shí)的對(duì)新增的樣本進(jìn)行訓(xùn)練);
4. 對(duì)缺失數(shù)據(jù)不太敏感,算法也比較簡(jiǎn)單,常用于文本分類(lèi);
5. 樸素貝葉斯對(duì)結(jié)果解釋容易理解。
缺點(diǎn):
1. 需要計(jì)算先驗(yàn)概率;
2. 分類(lèi)決策存在錯(cuò)誤率;
3. 對(duì)輸入數(shù)據(jù)的表達(dá)形式很敏感;
4. 由于使用了樣本屬性獨(dú)立性的假設(shè),所以如果樣本屬性有關(guān)聯(lián)時(shí)其效果不好。
樸素貝葉斯應(yīng)用領(lǐng)域
1. 欺詐檢測(cè)中使用較多;
2. 一封電子郵件是否是垃圾郵件;
3. 一篇文章應(yīng)該分到科技、政治,還是體育類(lèi);
4. 一段文字表達(dá)的是積極的情緒還是消極的情緒;
5. 人臉識(shí)別。
3.2 Logistic Regression(邏輯回歸)
邏輯回歸屬于判別式模型,同時(shí)伴有很多模型正則化的方法(L0, L1,L2,etc),而且你不必像在用樸素貝葉斯那樣擔(dān)心你的特征是否相關(guān)。與決策樹(shù)、SVM相比,你還會(huì)得到一個(gè)不錯(cuò)的概率解釋?zhuān)闵踔量梢暂p松地利用新數(shù)據(jù)來(lái)更新模型(使用在線梯度下降算法-online gradient descent)。如果你需要一個(gè)概率架構(gòu)(比如,簡(jiǎn)單地調(diào)節(jié)分類(lèi)閾值,指明不確定性,或者是要獲得置信區(qū)間),或者你希望以后將更多的訓(xùn)練數(shù)據(jù)快速整合到模型中去,那么使用它吧。
Sigmoid函數(shù):表達(dá)式如下:
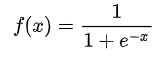
優(yōu)點(diǎn):
1. 實(shí)現(xiàn)簡(jiǎn)單,廣泛的應(yīng)用于工業(yè)問(wèn)題上;
2. 分類(lèi)時(shí)計(jì)算量非常小,速度很快,存儲(chǔ)資源低;
3. 便利的觀測(cè)樣本概率分?jǐn)?shù);
4. 對(duì)邏輯回歸而言,多重共線性并不是問(wèn)題,它可以結(jié)合L2正則化來(lái)解決該問(wèn)題;
5. 計(jì)算代價(jià)不高,易于理解和實(shí)現(xiàn)。
缺點(diǎn):
1. 當(dāng)特征空間很大時(shí),邏輯回歸的性能不是很好;
2. 容易欠擬合,一般準(zhǔn)確度不太高;
3. 不能很好地處理大量多類(lèi)特征或變量;
4. 只能處理兩分類(lèi)問(wèn)題(在此基礎(chǔ)上衍生出來(lái)的softmax可以用于多分類(lèi)),且必須線性可分;
5. 對(duì)于非線性特征,需要進(jìn)行轉(zhuǎn)換。
logistic回歸應(yīng)用領(lǐng)域:
1. 用于二分類(lèi)領(lǐng)域,可以得出概率值,適用于根據(jù)分類(lèi)概率排名的領(lǐng)域,如搜索排名等;
2. Logistic回歸的擴(kuò)展softmax可以應(yīng)用于多分類(lèi)領(lǐng)域,如手寫(xiě)字識(shí)別等;
3. 信用評(píng)估;
4. 測(cè)量市場(chǎng)營(yíng)銷(xiāo)的成功度;
5. 預(yù)測(cè)某個(gè)產(chǎn)品的收益;
6. 特定的某天是否會(huì)發(fā)生地震。
3.3 線性回歸
線性回歸是用于回歸的,它不像Logistic回歸那樣用于分類(lèi),其基本思想是用梯度下降法對(duì)最小二乘法形式的誤差函數(shù)進(jìn)行優(yōu)化,當(dāng)然也可以用normal equation直接求得參數(shù)的解,結(jié)果為:
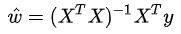
而在LWLR(局部加權(quán)線性回歸)中,參數(shù)的計(jì)算表達(dá)式為:
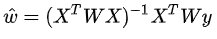
由此可見(jiàn)LWLR與LR不同,LWLR是一個(gè)非參數(shù)模型,因?yàn)槊看芜M(jìn)行回歸計(jì)算都要遍歷訓(xùn)練樣本至少一次。
優(yōu)點(diǎn):實(shí)現(xiàn)簡(jiǎn)單,計(jì)算簡(jiǎn)單。
缺點(diǎn):不能擬合非線性數(shù)據(jù)。
3.4 最近鄰算法——KNN
KNN即最近鄰算法,其主要過(guò)程為:
1. 計(jì)算訓(xùn)練樣本和測(cè)試樣本中每個(gè)樣本點(diǎn)的距離(常見(jiàn)的距離度量有歐式距離,馬氏距離等);
2. 對(duì)上面所有的距離值進(jìn)行排序(升序);
3. 選前k個(gè)最小距離的樣本;
4. 根據(jù)這k個(gè)樣本的標(biāo)簽進(jìn)行投票,得到最后的分類(lèi)類(lèi)別。
如何選擇一個(gè)最佳的K值,這取決于數(shù)據(jù)。一般情況下,在分類(lèi)時(shí)較大的K值能夠減小噪聲的影響,但會(huì)使類(lèi)別之間的界限變得模糊。一個(gè)較好的K值可通過(guò)各種啟發(fā)式技術(shù)來(lái)獲取,比如,交叉驗(yàn)證。另外噪聲和非相關(guān)性特征向量的存在會(huì)使K近鄰算法的準(zhǔn)確性減小。近鄰算法具有較強(qiáng)的一致性結(jié)果,隨著數(shù)據(jù)趨于無(wú)限,算法保證錯(cuò)誤率不會(huì)超過(guò)貝葉斯算法錯(cuò)誤率的兩倍。對(duì)于一些好的K值,K近鄰保證錯(cuò)誤率不會(huì)超過(guò)貝葉斯理論誤差率。
KNN算法的優(yōu)點(diǎn)
1. 理論成熟,思想簡(jiǎn)單,既可以用來(lái)做分類(lèi)也可以用來(lái)做回歸;
2. 可用于非線性分類(lèi);
3. 訓(xùn)練時(shí)間復(fù)雜度為O(n);
4. 對(duì)數(shù)據(jù)沒(méi)有假設(shè),準(zhǔn)確度高,對(duì)outlier不敏感;
5. KNN是一種在線技術(shù),新數(shù)據(jù)可以直接加入數(shù)據(jù)集而不必進(jìn)行重新訓(xùn)練;
6. KNN理論簡(jiǎn)單,容易實(shí)現(xiàn)。
缺點(diǎn)
1. 樣本不平衡問(wèn)題(即有些類(lèi)別的樣本數(shù)量很多,而其它樣本的數(shù)量很少)效果差;
2. 需要大量?jī)?nèi)存;
3. 對(duì)于樣本容量大的數(shù)據(jù)集計(jì)算量比較大(體現(xiàn)在距離計(jì)算上);
4. 樣本不平衡時(shí),預(yù)測(cè)偏差比較大。如:某一類(lèi)的樣本比較少,而其它類(lèi)樣本比較多;
5. KNN每一次分類(lèi)都會(huì)重新進(jìn)行一次全局運(yùn)算;
6. k值大小的選擇沒(méi)有理論選擇最優(yōu),往往是結(jié)合K-折交叉驗(yàn)證得到最優(yōu)k值選擇。
KNN算法應(yīng)用領(lǐng)域
文本分類(lèi)、模式識(shí)別、聚類(lèi)分析,多分類(lèi)領(lǐng)域
3.5 決策樹(shù)
決策樹(shù)的一大優(yōu)勢(shì)就是易于解釋。它可以毫無(wú)壓力地處理特征間的交互關(guān)系并且是非參數(shù)化的,因此你不必?fù)?dān)心異常值或者數(shù)據(jù)是否線性可分(舉個(gè)例子,決策樹(shù)能輕松處理好類(lèi)別A在某個(gè)特征維度x的末端,類(lèi)別B在中間,然后類(lèi)別A又出現(xiàn)在特征維度x前端的情況)。它的缺點(diǎn)之一就是不支持在線學(xué)習(xí),于是在新樣本到來(lái)后,決策樹(shù)需要全部重建。另一個(gè)缺點(diǎn)就是容易出現(xiàn)過(guò)擬合,但這也就是諸如隨機(jī)森林RF(或提升樹(shù)boosted tree)之類(lèi)的集成方法的切入點(diǎn)。另外,隨機(jī)森林經(jīng)常是很多分類(lèi)問(wèn)題的贏家(通常比支持向量機(jī)好上那么一丁點(diǎn)),它訓(xùn)練快速并且可調(diào),同時(shí)你無(wú)須擔(dān)心要像支持向量機(jī)那樣調(diào)一大堆參數(shù),所以在以前都一直很受歡迎。
決策樹(shù)中很重要的一點(diǎn)就是選擇一個(gè)屬性進(jìn)行分枝,因此要注意一下信息增益的計(jì)算公式,并深入理解它。
信息熵的計(jì)算公式如下:
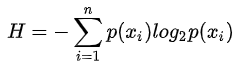
其中的n代表有n個(gè)分類(lèi)類(lèi)別(比如假設(shè)是二類(lèi)問(wèn)題,那么n=2)。分別計(jì)算這2類(lèi)樣本在總樣本中出現(xiàn)的概率
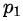
和
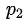
,這樣就可以計(jì)算出未選中屬性分枝前的信息熵。
現(xiàn)在選中一個(gè)屬性
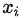
用來(lái)進(jìn)行分枝,此時(shí)分枝規(guī)則是:如果
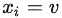
的話,將樣本分到樹(shù)的一個(gè)分支;如果不相等則進(jìn)入另一個(gè)分支。很顯然,分支中的樣本很有可能包括2個(gè)類(lèi)別,分別計(jì)算這2個(gè)分支的熵
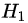
和
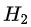
,計(jì)算出分枝后的總信息熵
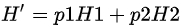
,則此時(shí)的信息增益
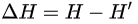
。以信息增益為原則,把所有的屬性都測(cè)試一邊,選擇一個(gè)使增益最大的屬性作為本次分枝屬性。
決策樹(shù)自身的優(yōu)點(diǎn)
1. 決策樹(shù)易于理解和解釋?zhuān)梢钥梢暬治觯菀滋崛〕鲆?guī)則;
2. 可以同時(shí)處理標(biāo)稱(chēng)型和數(shù)值型數(shù)據(jù);
3. 比較適合處理有缺失屬性的樣本;
4. 能夠處理不相關(guān)的特征;
5. 測(cè)試數(shù)據(jù)集時(shí),運(yùn)行速度比較快;
6. 在相對(duì)短的時(shí)間內(nèi)能夠?qū)Υ笮蛿?shù)據(jù)源做出可行且效果良好的結(jié)果。
缺點(diǎn)
1. 容易發(fā)生過(guò)擬合(隨機(jī)森林可以很大程度上減少過(guò)擬合);
2. 容易忽略數(shù)據(jù)集中屬性的相互關(guān)聯(lián);
3. 對(duì)于那些各類(lèi)別樣本數(shù)量不一致的數(shù)據(jù),在決策樹(shù)中,進(jìn)行屬性劃分時(shí),不同的判定準(zhǔn)則會(huì)帶來(lái)不同的屬性選擇傾向;信息增益準(zhǔn)則對(duì)可取數(shù)目較多的屬性有所偏好(典型代表ID3算法),而增益率準(zhǔn)則(CART)則對(duì)可取數(shù)目較少的屬性有所偏好,但CART進(jìn)行屬性劃分時(shí)候不再簡(jiǎn)單地直接利用增益率盡心劃分,而是采用一種啟發(fā)式規(guī)則)(只要是使用了信息增益,都有這個(gè)缺點(diǎn),如RF)。
4. ID3算法計(jì)算信息增益時(shí)結(jié)果偏向數(shù)值比較多的特征。
改進(jìn)措施
1. 對(duì)決策樹(shù)進(jìn)行剪枝。可以采用交叉驗(yàn)證法和加入正則化的方法;
2. 使用基于決策樹(shù)的combination算法,如bagging算法,randomforest算法,可以解決過(guò)擬合的問(wèn)題。
應(yīng)用領(lǐng)域
企業(yè)管理實(shí)踐,企業(yè)投資決策,由于決策樹(shù)很好的分析能力,在決策過(guò)程應(yīng)用較多。
3.5.1 ID3、C4.5算法
ID3算法是以信息論為基礎(chǔ),以信息熵和信息增益度為衡量標(biāo)準(zhǔn),從而實(shí)現(xiàn)對(duì)數(shù)據(jù)的歸納分類(lèi)。ID3算法計(jì)算每個(gè)屬性的信息增益,并選取具有最高增益的屬性作為給定的測(cè)試屬性。C4.5算法核心思想是ID3算法,是ID3算法的改進(jìn),改進(jìn)方面有:- 用信息增益率來(lái)選擇屬性,克服了用信息增益選擇屬性時(shí)偏向選擇取值多的屬性的不足;- 在樹(shù)構(gòu)造過(guò)程中進(jìn)行剪枝;- 能處理非離散的數(shù)據(jù);- 能處理不完整的數(shù)據(jù)。
優(yōu)點(diǎn)
產(chǎn)生的分類(lèi)規(guī)則易于理解,準(zhǔn)確率較高。
缺點(diǎn)
1. 在構(gòu)造樹(shù)的過(guò)程中,需要對(duì)數(shù)據(jù)集進(jìn)行多次的順序掃描和排序,因而導(dǎo)致算法的低效;
2. C4.5只適合于能夠駐留于內(nèi)存的數(shù)據(jù)集,當(dāng)訓(xùn)練集大得無(wú)法在內(nèi)存容納時(shí)程序無(wú)法運(yùn)行。
3.5.2 CART分類(lèi)與回歸樹(shù)
是一種決策樹(shù)分類(lèi)方法,采用基于最小距離的基尼指數(shù)估計(jì)函數(shù),用來(lái)決定由該子數(shù)據(jù)集生成的決策樹(shù)的拓展形。如果目標(biāo)變量是標(biāo)稱(chēng)的,稱(chēng)為分類(lèi)樹(shù);如果目標(biāo)變量是連續(xù)的,稱(chēng)為回歸樹(shù)。分類(lèi)樹(shù)是使用樹(shù)結(jié)構(gòu)算法將數(shù)據(jù)分成離散類(lèi)的方法。
優(yōu)點(diǎn)
1. 非常靈活,可以允許有部分錯(cuò)分成本,還可指定先驗(yàn)概率分布,可使用自動(dòng)的成本復(fù)雜性剪枝來(lái)得到歸納性更強(qiáng)的樹(shù);
2. 在面對(duì)諸如存在缺失值、變量數(shù)多等問(wèn)題時(shí)CART 顯得非常穩(wěn)健。
3.6 Adaboosting
Adaboost是一種加和模型,每個(gè)模型都是基于上一次模型的錯(cuò)誤率來(lái)建立的,過(guò)分關(guān)注分錯(cuò)的樣本,而對(duì)正確分類(lèi)的樣本減少關(guān)注度,逐次迭代之后,可以得到一個(gè)相對(duì)較好的模型。該算法是一種典型的boosting算法,其加和理論的優(yōu)勢(shì)可以使用Hoeffding不等式得以解釋。
優(yōu)點(diǎn)
1. Adaboost是一種有很高精度的分類(lèi)器;
2. 可以使用各種方法構(gòu)建子分類(lèi)器,Adaboost算法提供的是框架;
3. 當(dāng)使用簡(jiǎn)單分類(lèi)器時(shí),計(jì)算出的結(jié)果是可以理解的,并且弱分類(lèi)器的構(gòu)造極其簡(jiǎn)單;
4. 簡(jiǎn)單,不用做特征篩選;
5. 不易發(fā)生overfitting。
缺點(diǎn)
對(duì)outlier比較敏感。
3.7 SVM支持向量機(jī)
支持向量機(jī),一個(gè)經(jīng)久不衰的算法,高準(zhǔn)確率,為避免過(guò)擬合提供了很好的理論保證,而且就算數(shù)據(jù)在原特征空間線性不可分,只要給個(gè)合適的核函數(shù),它就能運(yùn)行得很好。在動(dòng)輒超高維的文本分類(lèi)問(wèn)題中特別受歡迎。可惜內(nèi)存消耗大,難以解釋?zhuān)\(yùn)行和調(diào)參也有些煩人,而隨機(jī)森林卻剛好避開(kāi)了這些缺點(diǎn),比較實(shí)用。
優(yōu)點(diǎn)
1. 可以解決高維問(wèn)題,即大型特征空間;
2. 解決小樣本下機(jī)器學(xué)習(xí)問(wèn)題;
3. 能夠處理非線性特征的相互作用;
4. 無(wú)局部極小值問(wèn)題;(相對(duì)于神經(jīng)網(wǎng)絡(luò)等算法)
5. 無(wú)需依賴(lài)整個(gè)數(shù)據(jù);
6. 泛化能力比較強(qiáng)。
缺點(diǎn)
1. 當(dāng)觀測(cè)樣本很多時(shí),效率并不是很高;
2. 對(duì)非線性問(wèn)題沒(méi)有通用解決方案,有時(shí)候很難找到一個(gè)合適的核函數(shù);
3. 對(duì)于核函數(shù)的高維映射解釋力不強(qiáng),尤其是徑向基函數(shù);
4. 常規(guī)SVM只支持二分類(lèi);
5. 對(duì)缺失數(shù)據(jù)敏感。
對(duì)于核的選擇也是有技巧的(libsvm中自帶了四種核函數(shù):線性核、多項(xiàng)式核、RBF以及sigmoid核):
第一,如果樣本數(shù)量小于特征數(shù),那么就沒(méi)必要選擇非線性核,簡(jiǎn)單的使用線性核就可以了;
第二,如果樣本數(shù)量大于特征數(shù)目,這時(shí)可以使用非線性核,將樣本映射到更高維度,一般可以得到更好的結(jié)果;
第三,如果樣本數(shù)目和特征數(shù)目相等,該情況可以使用非線性核,原理和第二種一樣。
對(duì)于第一種情況,也可以先對(duì)數(shù)據(jù)進(jìn)行降維,然后使用非線性核,這也是一種方法。
SVM應(yīng)用領(lǐng)域
文本分類(lèi)、圖像識(shí)別(主要二分類(lèi)領(lǐng)域,畢竟常規(guī)SVM只能解決二分類(lèi)問(wèn)題)
3.8 人工神經(jīng)網(wǎng)絡(luò)的優(yōu)缺點(diǎn)
人工神經(jīng)網(wǎng)絡(luò)的優(yōu)點(diǎn):
1. 分類(lèi)的準(zhǔn)確度高;
2. 并行分布處理能力強(qiáng),分布存儲(chǔ)及學(xué)習(xí)能力強(qiáng);
3. 對(duì)噪聲神經(jīng)有較強(qiáng)的魯棒性和容錯(cuò)能力;
4. 具備聯(lián)想記憶的功能,能充分逼近復(fù)雜的非線性關(guān)系。
人工神經(jīng)網(wǎng)絡(luò)的缺點(diǎn):
1. 神經(jīng)網(wǎng)絡(luò)需要大量的參數(shù),如網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)、權(quán)值和閾值的初始值;
2. 黑盒過(guò)程,不能觀察之間的學(xué)習(xí)過(guò)程,輸出結(jié)果難以解釋?zhuān)瑫?huì)影響到結(jié)果的可信度和可接受程度;
3. 學(xué)習(xí)時(shí)間過(guò)長(zhǎng),有可能陷入局部極小值,甚至可能達(dá)不到學(xué)習(xí)的目的。
人工神經(jīng)網(wǎng)絡(luò)應(yīng)用領(lǐng)域:
目前深度神經(jīng)網(wǎng)絡(luò)已經(jīng)應(yīng)用與計(jì)算機(jī)視覺(jué),自然語(yǔ)言處理,語(yǔ)音識(shí)別等領(lǐng)域并取得很好的效果。
3.9 K-Means聚類(lèi)
是一個(gè)簡(jiǎn)單的聚類(lèi)算法,把n的對(duì)象根據(jù)他們的屬性分為k個(gè)分割,k< n。算法的核心就是要優(yōu)化失真函數(shù)J,使其收斂到局部最小值但不是全局最小值。
關(guān)于K-Means聚類(lèi)的文章,參見(jiàn)機(jī)器學(xué)習(xí)算法-K-means聚類(lèi)。關(guān)于K-Means的推導(dǎo),里面可是有大學(xué)問(wèn)的,蘊(yùn)含著強(qiáng)大的EM思想。
優(yōu)點(diǎn)
1. 算法簡(jiǎn)單,容易實(shí)現(xiàn) ;
2. 算法速度很快;
3. 對(duì)處理大數(shù)據(jù)集,該算法是相對(duì)可伸縮的和高效率的,因?yàn)樗膹?fù)雜度大約是O(nkt),其中n是所有對(duì)象的數(shù)目,k是簇的數(shù)目,t是迭代的次數(shù)。通常k<
4. 算法嘗試找出使平方誤差函數(shù)值最小的k個(gè)劃分。當(dāng)簇是密集的、球狀或團(tuán)狀的,且簇與簇之間區(qū)別明顯時(shí),聚類(lèi)效果較好。
缺點(diǎn)
1. 對(duì)數(shù)據(jù)類(lèi)型要求較高,適合數(shù)值型數(shù)據(jù);
2. 可能收斂到局部最小值,在大規(guī)模數(shù)據(jù)上收斂較慢;
3. 分組的數(shù)目k是一個(gè)輸入?yún)?shù),不合適的k可能返回較差的結(jié)果;
4. 對(duì)初值的簇心值敏感,對(duì)于不同的初始值,可能會(huì)導(dǎo)致不同的聚類(lèi)結(jié)果;
5. 不適合于發(fā)現(xiàn)非凸面形狀的簇,或者大小差別很大的簇;
6. 對(duì)于”噪聲”和孤立點(diǎn)數(shù)據(jù)敏感,少量的該類(lèi)數(shù)據(jù)能夠?qū)ζ骄诞a(chǎn)生極大影響。
3.10 EM最大期望算法
EM算法是基于模型的聚類(lèi)方法,是在概率模型中尋找參數(shù)最大似然估計(jì)的算法,其中概率模型依賴(lài)于無(wú)法觀測(cè)的隱藏變量。E步估計(jì)隱含變量,M步估計(jì)其他參數(shù),交替將極值推向最大。
EM算法比K-means算法計(jì)算復(fù)雜,收斂也較慢,不適于大規(guī)模數(shù)據(jù)集和高維數(shù)據(jù),但比K-means算法計(jì)算結(jié)果穩(wěn)定、準(zhǔn)確。EM經(jīng)常用在機(jī)器學(xué)習(xí)和計(jì)算機(jī)視覺(jué)的數(shù)據(jù)集聚(Data Clustering)領(lǐng)域。
3.11 集成算法(AdaBoost算法)
AdaBoost算法優(yōu)點(diǎn):
1. 很好的利用了弱分類(lèi)器進(jìn)行級(jí)聯(lián);
2. 可以將不同的分類(lèi)算法作為弱分類(lèi)器;
3. AdaBoost具有很高的精度;
4. 相對(duì)于bagging算法和Random Forest算法,AdaBoost充分考慮的每個(gè)分類(lèi)器的權(quán)重。
Adaboost算法缺點(diǎn):
1. AdaBoost迭代次數(shù)也就是弱分類(lèi)器數(shù)目不太好設(shè)定,可以使用交叉驗(yàn)證來(lái)進(jìn)行確定;
2. 數(shù)據(jù)不平衡導(dǎo)致分類(lèi)精度下降;
3. 訓(xùn)練比較耗時(shí),每次重新選擇當(dāng)前分類(lèi)器最好切分點(diǎn)。
AdaBoost應(yīng)用領(lǐng)域:
模式識(shí)別、計(jì)算機(jī)視覺(jué)領(lǐng)域,用于二分類(lèi)和多分類(lèi)場(chǎng)景
3.12 排序算法(PageRank)
PageRank是google的頁(yè)面排序算法,是基于從許多優(yōu)質(zhì)的網(wǎng)頁(yè)鏈接過(guò)來(lái)的網(wǎng)頁(yè),必定還是優(yōu)質(zhì)網(wǎng)頁(yè)的回歸關(guān)系,來(lái)判定所有網(wǎng)頁(yè)的重要性。(也就是說(shuō),一個(gè)人有著越多牛X朋友的人,他是牛X的概率就越大。)
PageRank優(yōu)點(diǎn)
完全獨(dú)立于查詢,只依賴(lài)于網(wǎng)頁(yè)鏈接結(jié)構(gòu),可以離線計(jì)算。
PageRank缺點(diǎn)
1. PageRank算法忽略了網(wǎng)頁(yè)搜索的時(shí)效性;
2. 舊網(wǎng)頁(yè)排序很高,存在時(shí)間長(zhǎng),積累了大量的in-links,擁有最新資訊的新網(wǎng)頁(yè)排名卻很低,因?yàn)樗鼈儙缀鯖](méi)有in-links。
3.13 關(guān)聯(lián)規(guī)則算法(Apriori算法)
Apriori算法是一種挖掘關(guān)聯(lián)規(guī)則的算法,用于挖掘其內(nèi)含的、未知的卻又實(shí)際存在的數(shù)據(jù)關(guān)系,其核心是基于兩階段頻集思想的遞推算法 。
Apriori算法分為兩個(gè)階段:
1. 尋找頻繁項(xiàng)集;
2. 由頻繁項(xiàng)集找關(guān)聯(lián)規(guī)則。
算法缺點(diǎn):
1. 在每一步產(chǎn)生侯選項(xiàng)目集時(shí)循環(huán)產(chǎn)生的組合過(guò)多,沒(méi)有排除不應(yīng)該參與組合的元素;
2. 每次計(jì)算項(xiàng)集的支持度時(shí),都對(duì)數(shù)據(jù)庫(kù)中 的全部記錄進(jìn)行了一遍掃描比較,需要很大的I/O負(fù)載。
4. 算法選擇參考
之前筆者翻譯過(guò)一些國(guó)外的文章,其中有一篇文章中給出了一個(gè)簡(jiǎn)單的算法選擇技巧:
1. 首當(dāng)其沖應(yīng)該選擇的就是邏輯回歸,如果它的效果不怎么樣,那么可以將它的結(jié)果作為基準(zhǔn)來(lái)參考,在基礎(chǔ)上與其他算法進(jìn)行比較;
2. 然后試試決策樹(shù)(隨機(jī)森林)看看是否可以大幅度提升你的模型性能。即便最后你并沒(méi)有把它當(dāng)做為最終模型,你也可以使用隨機(jī)森林來(lái)移除噪聲變量,做特征選擇;
3. 如果特征的數(shù)量和觀測(cè)樣本特別多,那么當(dāng)資源和時(shí)間充足時(shí)(這個(gè)前提很重要),使用SVM不失為一種選擇。
通常情況下:【GBDT>=SVM>=RF>=Adaboost>=Other…】,現(xiàn)在深度學(xué)習(xí)很熱門(mén),很多領(lǐng)域都用到,它是以神經(jīng)網(wǎng)絡(luò)為基礎(chǔ)的,目前筆者自己也在學(xué)習(xí),只是理論知識(shí)不扎實(shí),理解的不夠深入,這里就不做介紹了,希望以后可以寫(xiě)一片拋磚引玉的文章。
算法固然重要,但好的數(shù)據(jù)卻要優(yōu)于好的算法,設(shè)計(jì)優(yōu)良特征是大有裨益的。假如你有一個(gè)超大數(shù)據(jù)集,那么無(wú)論你使用哪種算法可能對(duì)分類(lèi)性能都沒(méi)太大影響(此時(shí)就可以根據(jù)速度和易用性來(lái)進(jìn)行抉擇)。
-
算法
+關(guān)注
關(guān)注
23文章
4607瀏覽量
92840 -
分類(lèi)器
+關(guān)注
關(guān)注
0文章
152瀏覽量
13179 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8408瀏覽量
132568
原文標(biāo)題:解析|機(jī)器學(xué)習(xí)算法優(yōu)缺點(diǎn)對(duì)比及選擇
文章出處:【微信號(hào):vision263com,微信公眾號(hào):新機(jī)器視覺(jué)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
常見(jiàn)算法優(yōu)缺點(diǎn)比較
HFSS 仿真算法及其應(yīng)用場(chǎng)景詳解:有限元算法、積分方程算法、PO算法
主流的三種RF方案及其優(yōu)缺點(diǎn)對(duì)比分析
常用的無(wú)線傳感器網(wǎng)絡(luò)數(shù)據(jù)融合算法有什么優(yōu)缺點(diǎn)?
ADC的性能參數(shù)及優(yōu)缺點(diǎn)
DMA的傳輸過(guò)程與優(yōu)缺點(diǎn)
國(guó)內(nèi)外聚焦電位器接觸材料的選擇趨勢(shì)及其優(yōu)缺點(diǎn)
常見(jiàn)算法優(yōu)缺點(diǎn)比較





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論