 Facebook的研究人員提出了一個能從真實視頻中抽取可控制主角的模型Vid2Game
Facebook的研究人員提出了一個能從真實視頻中抽取可控制主角的模型Vid2Game
相信大家還記得曾經游戲中的主人公,可以隨著按鍵旋轉跳躍,通過三維/二維模型或者實現錄制好的視頻來響應不同指令的動作。而最近來自Facebook的研究人員提出了一個能從真實視頻中抽取可控制主角的模型Vid2Game,這意味你可以將視頻中喜歡的主人公變成可以在游戲中控制的主角。
讓我們先來看看效果,從真實視頻中抽取的主角被放置到了新背景中,隨著按鍵的控制左右移動揮拍擊球。
黑衣服的運動員被妥妥地安排到了不同的背景中,隨著鍵盤的指令移動。這是怎么做到的呢?為了實現對主體的控制和生成需要解決一下幾個問題:首先需要將主體從環境中分離出來以便在新的任意的背景中生成;由于渲染陰影、反射、運動效果等、這種分離不是二值化的;用戶給出的控制信號任意的x,y位移、如何編碼并將控制量饋入主體生成中;最后需要處理生成序列過程中積累誤差的影響。
那么文章中具體是如何做到的呢?
下面讓我們一起來看看背后的原理。Vid2Game包含了兩個神經網絡和三個主要步驟的工作流程,首先利用第一個神經網絡將當前位姿和控制信號映射到下一時刻的新位姿;隨后利用新位姿和給定的背景輸出希望的幀,包括背景和主體以及主體的mask;最后將生成的主體以背景融合生成最終輸出。這種通用的方法可以被廣泛用于多種不同運動場景中。給定視頻中的主角可以根據用戶的控制,生成在目標背景中運動的視頻。兩個序列形式工作的模型分別是Pose2Pose和Pose2Frame。
Pose2Pose網絡基于用戶的控制序列信號以自回歸的方式操作給定的位姿,實現在特定的域內基于2D控制信號引導人體位姿生成。
通過輸入t-1時刻的位姿和對應物體、在用戶控制序列的操作下生成t時刻的主角位姿和對應物體。上圖中我們可以看到輸入的運動員位姿圖和對應的球拍、同時輸入的還有控制量。我們還可以看到中間的n-2個條件殘差模塊是基于質心位移量進行處理的。在訓練時,質心唯一來自于訓練序列的編碼、而推理時則來自于用戶輸入。
隨后將生成的位姿及給定的背景輸入Pose2Frame將生成高分辨率的真實視頻序列。同樣以運動員作為例子,將運動員位姿和網球拍的序列輸入,模型將生成一個RGB圖像和mask圖像.RGB圖像考慮了運動員在環境中需要包括了陰影、反射等渲染,而mask輔助融合運動員與給定背景。通過mask與生成的rgb相乘得到運動員部分的RGB圖像、再通過背景摳出mask區域隨后融合運動與與給定背景,即得到運動員在新環境中生成的受用戶控制的幀。
對于判別器部分、模型主要關注多尺度情況下二進制閾值主體。其中o為基準圖像f為生成圖像,在放入多尺度判別器前需要進行均值pooling減采樣,。放入VGG分類器中的圖像則保持了原始分辨率用于給出感知損失。Pose2Pose和Pose2Frame的生成器和判別器都使用了pix2pixHD架構來作為基礎網絡,并進行了一系列改進。同時利用了基于DensePose的方法來對位姿進行表示,同時使用了語義分割的方法來對運動員手持物體進行抽取。
通過這樣的方法,就可以在希望的場景中合成你可控制的主角了。這對于未來個性化游戲、虛擬顯示等具有十分重要的意義。從各種視頻中抽取主角、并可以通過鍵盤在游戲中控制真的很棒!
讓我們來跳一支舞吧:
控制你的主角四處漫游:
到任何想去的地方打球:
與龍來一場戰斗吧:
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100715 -
圖像
+關注
關注
2文章
1083瀏覽量
40449 -
Facebook
+關注
關注
3文章
1429瀏覽量
54721
原文標題:Facebook提出Vid2Game模型,幫助你來控制視頻里的主人公動起來~
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
研究人員提出了“Skim-RNN”的概念,用很少的時間進行快速閱讀
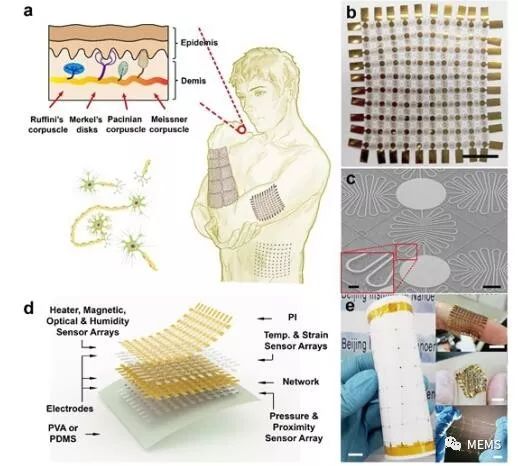
研究人員提出了一種柔性可拉伸擴展的多功能集成傳感器陣列
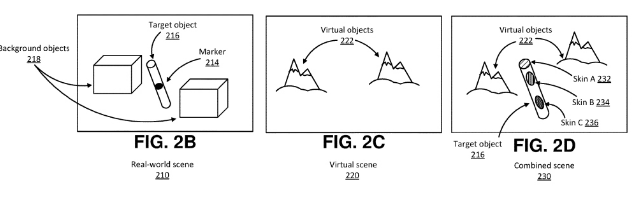
Facebook提出了一種在虛擬現實環境中表征真實世界對象的解決方案
Facebook構建虛擬空間訓練AI
研究人員們提出了一系列新的點云處理模塊

JD和OPPO的研究人員們提出了一種姿勢引導的時尚圖像生成模型
Facebook的研究人員提出了Mesh R-CNN模型

研究人員推出了一種新的基于深度學習的策略
研究人員開發出了一種稱為LB-WayPtNav-DH的機器人導航新框架
研究人員提出了一個名為CommPlan的框架
Facebook向研究人員發布友誼數據
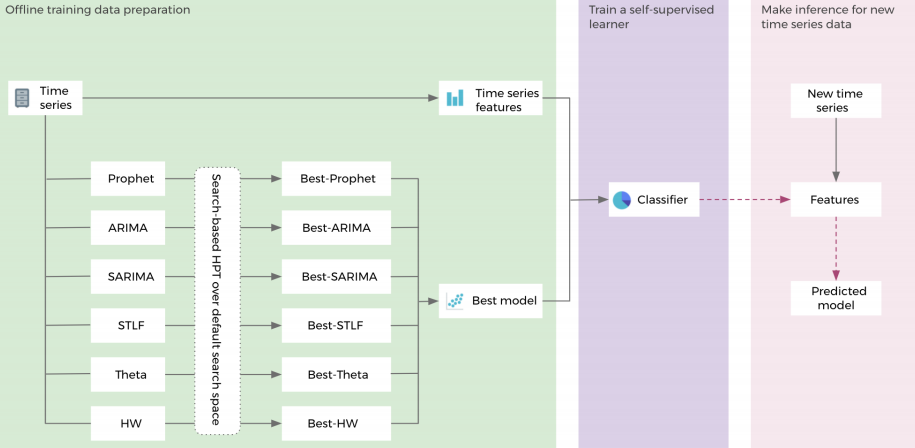
華裔女博士提出:Facebook提出用于超參數調整的自我監督學習框架





 工商網監
工商網監
評論