 華裔科學家成功解碼腦電波 AI直接從大腦中合成語音
華裔科學家成功解碼腦電波 AI直接從大腦中合成語音
通過解碼大腦活動提升語音的清晰度,使用深度學習方法直接從大腦信號中產生口語句子,達到150個單詞,接近正常人水平。
大腦活動能夠解碼成語音了。
說話似乎是一項毫不費力的活動,但它其實是人類最復雜的動作之一。說話需要精確、動態地協調聲道發音器官結構中的肌肉——嘴唇、舌頭、喉部和下頜。當由于中風、肌萎縮側索硬化癥或其他神經系統疾病而導致言語中斷時,喪失說話能力可能是毀滅性的。
來自加州大學舊金山分校的科學家創造了更接近能夠恢復說話功能的腦機接口(brain–computer interface,BCI)。
腦機接口旨在幫助癱瘓患者直接從大腦中“讀取”他們的意圖,并利用這些信息控制外部設備或移動癱瘓的肢體,這項技術目前能夠使癱瘓的人每分鐘最多能打出8個單詞,而加州大學舊金山分享的研究人員開發了一種方法,使用深度學習方法直接從大腦信號中產生口語句子,達到150個單詞,接近正常人水平!
這項研究發表在最新一期《自然》雜志上,作者為Anumanchipalli以及華裔科學家Edward Chang等人。
01.每分鐘能夠生成150單詞,接近正常人類水平
加州大學舊金山分校的研究人員與5名志愿者合作,志愿者們接受了一項被稱為“顱內監測”的實驗,其中電極被用于監測大腦活動,作為癲癇治療的一部分。
許多癲癇患者的藥物治療效果并不好,他們選擇接受腦部手術。在術前,醫生必須首先找到病人大腦中癲癇發作的“熱點”,這一過程是通過放置在大腦內部或表面的電極來完成的,并監測明顯的電信號高峰。
精確定位“熱點”的位置可能需要數周時間。在此期間,患者通過植入大腦區域或其附近的電極來度日,這些區域涉及運動和聽覺信號。這些患者一般會同意利用這些植入物進行額外的實驗。
ECoG電極陣列由記錄大腦活動的顱內電極組成
此次招募的五名志愿者同意測試虛擬語音發生器。每個患者都植入了一兩個電極陣列:圖章大小的、包含幾百個微電極的小墊,放置在大腦表面。
實驗要求參與者背誦幾百個句子,電極會記錄運動皮層中神經元的放電模式。研究人員將這些模式與患者在自然說話時嘴唇,舌頭,喉部和下頜的微小運動聯系起來。然后將這些動作翻譯成口語化的句子。
參與的志愿者大腦中的電極陣列位置
實驗要求母語為英語的人聽這些句子,以測試虛擬語音的流暢性。研究發現,大約70%的虛擬系統生成的內容是可理解的。
最終,這套新系統每分鐘能夠生成150單詞,接近自然講話的語速水平。而以前基于植入物的通信系統每分鐘可以生成大約8個單詞。
02.技術細節:兩階段解碼方法
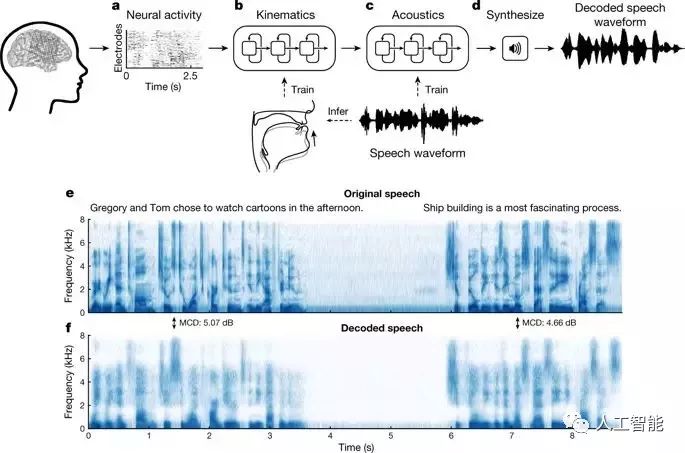
在這項工作中,研究人員使用了一種叫做高密度皮層腦電圖的技術來跟蹤志愿者說話時大腦中控制言語和發音器官運動的區域的活動,志愿者們被要求說了幾百句話。
為了重建話語,Anumanchipalli等人不是將大腦信號直接轉換為音頻信號,而是使用一種兩級解碼的方法。他們首先將神經信號轉換為聲道發音器官運動的表示,然后將解碼的運動轉換為口語句子,如圖1所示。兩次轉換都使用了遞歸神經網絡——一種人工神經網絡,在處理和轉換具有復雜時間結構的數據時特別有效。
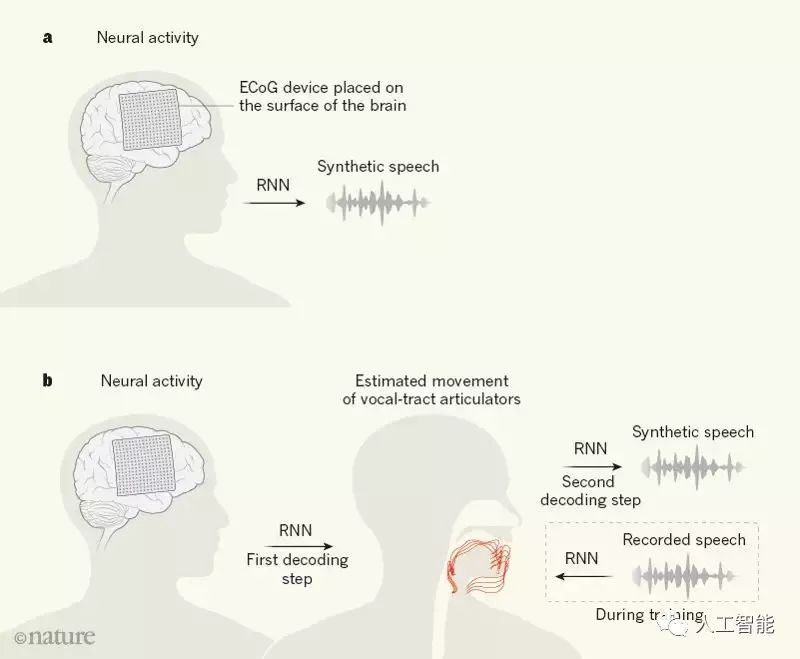
圖1:語音合成的腦機接口
在上圖A中,以前的語音合成研究采用的方法是使用腦電圖(ECoG)設備監測大腦語音相關區域的神經信號,并嘗試將這些信號直接解碼合成語音,使用一種稱為遞歸神經網絡(RNN)的人工神經網絡;
上圖B中,Anumanchipalli等人開發了一種不同的方法,RNN被用于兩階段解碼。其中一個解碼步驟是將神經信號轉換成聲道發聲器官(紅色)的預估運動,涉及到語音生成的解剖結構(嘴唇、舌頭、喉部和下頜)。為了在第一個解碼步驟中進行訓練,作者需要每個人的聲道運動與他們的神經活動關聯起來的數據。
因為無法直接測量每個人的聲道運動,Anumanchipalli等人構建了一個RNN來預估這些運動,其訓練數據是之前收集的大量聲道運動數據和語音錄音。
這個RNN產生的聲道運動估計足以訓練第一個解碼器。第二個解碼步驟將這些估計的動作轉換成合成語音。Anumanchipalli和他的同事的兩步解碼方法產生的口語句子的失真率明顯低于直接解碼方法獲得的句子。
與直接解碼聲學特征相比,作者采用的兩階段解碼方法能明顯減小聲音失真。如果可以獲得跨多種語音條件的海量數據集,那么直接合成可能會接近或優于兩階段解碼的方法。
然而,考慮到現實中數據集的匱乏,解碼的中間階段會將聲道發音器官正常運動功能的信息帶入模型,并限制必須評估的神經網絡模型的可能參數。這種方法似乎使神經網絡能夠實現更高的性能。最終,反映正常運動功能的“仿生”方法可能在復制自然語言典型的快速、高精度通信方面發揮關鍵作用。
03.不能說話的個體也能實現語音合成
在腦機接口(BCI)研究中,包括新興的語音腦機接口領域,開發和采用允許跨研究進行有意義的比較的穩健度量是一項挑戰。例如,重構原始語音的錯誤等度量可能與腦機接口的功能性能(即聽者是否能聽懂合成的語音)幾乎沒有對應關系。
為了解決這個問題,Anumanchipalli等人從語音工程領域出發,開發了易于復制的人類聽眾語音可懂度測量方法。他們在眾包市場Amazon Mechanical Turk上招募用戶,讓志愿者識別合成語音中的單詞或句子。
與重構錯誤或以前使用的自動可懂度測量方法不同,這種方法直接測量語音對人類聽眾的可懂度,而不需要與原始話語進行比較。
Anumanchipalli和他的同事的研究結果為語音合成腦機接口的概念提供了令人信服證據,無論是在音頻重建的準確性方面,還是在聽者對產生的單詞和句子進行分類的能力方面。
然而,在通往臨床可行的語音腦機接口的道路上仍有許多挑戰。
重構語音的可理解性仍遠低于自然語音,腦機接口能否通過收集更大的數據集并繼續開發底層的計算方法來進一步改進還有待觀察。使用記錄局部腦活動的神經接口可能比使用皮層腦電圖記錄的更為有效。例如,在腦機接口研究的其他領域,皮質內微電極陣列通常比皮質腦電圖具有更高的性能。
目前所有語音解碼方法的另一個限制是需要使用語音來訓練解碼器。因此,基于這些方法的腦機接口不能直接應用于無法說話的人。
但是Anumanchipalli和他的同事們發現,當志愿者在不發聲的情況下模仿語音時,語音合成仍然是可行的,盡管語音解碼的準確率要低得多。無法產生語音相關動作的個體是否能夠使用語音合成腦機接口是未來研究的一個問題。
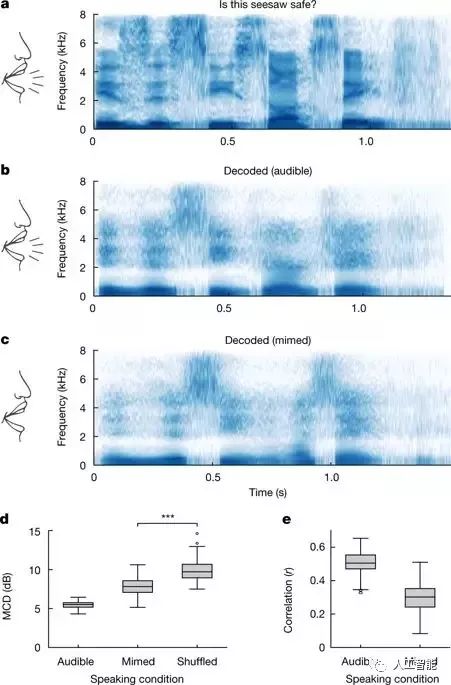
基于神經解碼的無聲模仿語音合成
值得注意的是,在首次對腦機接口進行概念驗證研究以控制健康動物的手臂和手的運動之后,人們對這種腦機接口在癱瘓患者身上的適用性提出了類似的問題。隨后的臨床試驗令人信服地證明,使用腦機接口,人類可以快速交流、控制機械臂、恢復癱瘓肢體的感覺和運動等。
最后,這些令人信服的概念驗證證明了不能說話的個體也能實現語音合成,結合腦機接口在上肢癱瘓患者中的快速進展,研究人員認為應該大力考慮涉及言語障礙患者的臨床研究。
隨著持續的進步,希望更多有語言障礙的人能夠重新獲得自由表達思想的能力,并重新與周圍的世界聯系起來。
華裔科學家解碼,馬斯克腦機接口公司也會有新動作
Nature這篇文章的作者之一是加州大學舊金山分校神經外科教授Edward Chang博士。
Edward Chang
Edward Chang博士的研究重點是言語、運動和人類情感的大腦機制,同時他也是加州大學舊金山分校和加州大學伯克利分校的合作單位——神經工程與假肢中心的聯合負責人。該中心匯集了工程、神經病學和神經外科方面的專家,以開發最先進的生物醫學技術,用以恢復神經系統殘疾患者的功能,如癱瘓和言語障礙。
Edward Chang博士表示,這次在Nature上的研究,“我們通過解碼大腦活動提升語音的清晰度,模擬的語音比從大腦中提取聲音表示的合成語音更準確、更自然。”
人類將大腦與計算機相連的努力越來越多。
上個月,美國一組科學家在biorxiv.org上發表一篇論文,稱找到了快速將電線植入大鼠大腦的方法,論文中描述這個過程是“向人類大腦直接插入計算機潛在系統邁出的重要一步”。
研究人員將他們的系統稱為“縫紉機”(sewing machine),科學家在實驗室中移除一塊老鼠的頭骨并插入一根針頭,將柔性電極送入老鼠的腦組織。
彭博新聞報道,這組科學家與馬斯克的腦機接口公司Neuralink有各種松散關聯。
Neuralink于2016年注冊為加州的一家醫學研究公司,該公司聘請了來自不同大學的幾位知名神經科學家,并與加州大學戴維斯分校的實驗室簽約,對靈長類動物進行研究。
本周三,當Twitter用戶詢問Neurink的進展時,馬斯克說,“可能會在幾個月內宣布一些值得注意的事情。”
馬斯克認為,腦機接口技術能在2021年之前治療嚴重的腦損傷。此外,科學可以通過腦機接口擴大人類的能力。他舉了一個例子:人們可以通過心靈感應來傳達復雜的概念,“你不需要用語言表達”。
人類是否有一天會與機器合并?馬斯克認為,人類已經在某種程度上做到了這一點,因為智能手機等近乎無所不在的技術,因此腦機接口這項工作應該繼續下去。
這可能會導致科幻未來,因為人們可以在腦海中下載外語,你覺得呢?
-
AI
+關注
關注
87文章
30758瀏覽量
268903 -
腦電波
+關注
關注
0文章
52瀏覽量
16996
原文標題:Nature重磅:華裔科學家成功解碼腦電波,AI直接從大腦中合成語音
文章出處:【微信號:worldofai,微信公眾號:worldofai】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
西湖大學:科學家+AI,科研新范式的樣本

ADS1299EEGFE-PDK按照手冊里設置后,無法產生正常的腦電波波形是怎么回事?
AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
《AI for Science:人工智能驅動科學創新》第二章AI for Science的技術支撐學習心得
《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
名單公布!【書籍評測活動NO.44】AI for Science:人工智能驅動科學創新
簡儀高性能平臺在小鼠腦電波實驗中的應用

中國科學家發現新型高溫超導體
天津大學科學家突破人類大腦器官成功驅動機器人
新華社:突破性成果!祝賀我國科學家成功研發這一傳感器!

前OpenAI首席科學家創辦新的AI公司
助力科學發展,NVIDIA AI加速HPC研究

stm32f0怎么不使用語音IC做合成語音?
谷歌DeepMind科學家欲建AI初創公司
飛騰首席科學家竇強榮獲 “國家卓越工程師” 稱號






 工商網監
工商網監
評論