 Tesla“大方”介紹自己的Full Self-Driving (FSD) Computer
Tesla“大方”介紹自己的Full Self-Driving (FSD) Computer
在剛剛結束的Tesla Autonomy活動中,Tesla非常“大方”的介紹了自己的Full Self-Driving (FSD) Computer從系統到芯片的很多細節。從芯片來看,其“透明度”超過了除Google第一代TPU之外所有的AI相關芯片。實際上,和Goolge TPU的情況類似,在這次發布之前,Tesla也做了一定的專利布局,這正好讓我們可以從不同角度更深入的了解Tesla的FSD芯片。
時間線
Tesla自動駕駛芯片負責人Pete Bannon首先介紹了芯片研發的過程:
Feb. 2016:第一個團隊成員入職;
Aug. 2017:第一版流片(經過18個月);
Dec. 2017:芯片返回,點亮;
Apr. 2018:BO Release to manufacturing;
Jul. 2018:Production start;
Dec. 2018:Employee retrofits start;
Mar. 2019:Model S & X production start;
Apr. 2019:Model 3 production start
用Pete的話說,從加入Tesla開始到芯片和系統在實際產品中部署,大約用了3年時間,這可能是他做過的項目中用時最短的了。他把這歸功于Tesla很強的垂直整合和并行工作的能力,還特別提到了Tesla有很強的Power supply design,Signal integrity design,Package design,System software,Board design,Firmware,System validation團隊。這里Tesla給了我們一個參考,即設計,生產和成功部署一顆SoC芯片所需付出的努力和時間。
系統和芯片設計
在具體介紹系統和芯片設計之前,Pete Bannon首先說了項目的前提,“只有一個客戶Tesla”,這就很大程度上降低了芯片需求的復雜性。總結起來,FSD芯片的需求就落到了如下幾點,依次是功耗,算力,Barch size(latency),安全性。在后面的Q&A中,Pete進一步提到Model 3的功耗的目標是每英里250W(Elon Musk對此作了補充,實際的功耗和道路環境有一定關系)。

前面幾個需求主要反映在芯片設計上,而安全性則在系統層面也有很多考慮,比如大量的冗余設計。同一塊板卡上的兩顆芯片的供電和數據通道都是獨立且互為備份的。而一個很有趣的想法是兩顆芯片同時都對同樣的數據進行分析,然后對比分析結果(或者相互驗證),再得出最終結論。
在這個地方Elon Musk還親自插進來講了一下這塊板卡上的任何部分如果出現故障都不會影響基本的汽車的行駛(他在之后的Q&A環節還補充說明了這一點)。
之后Pete Bannon就開始對芯片進行非常詳細的說明。首先是芯片的外觀,硅片和一些總體信息。后面的Q&A環節中透露了該芯片使用的是Samsung的14nm工藝。
然后是SoC芯片的基本組成部分,CPU(12核A72),GPU,各種接口,片上網絡。這些部分都是采用第三方標準IP。
此外還專門強調了一個SAFETY SYSTEM(如下圖所示),是一個獨立的CPU,有最終的控制權。
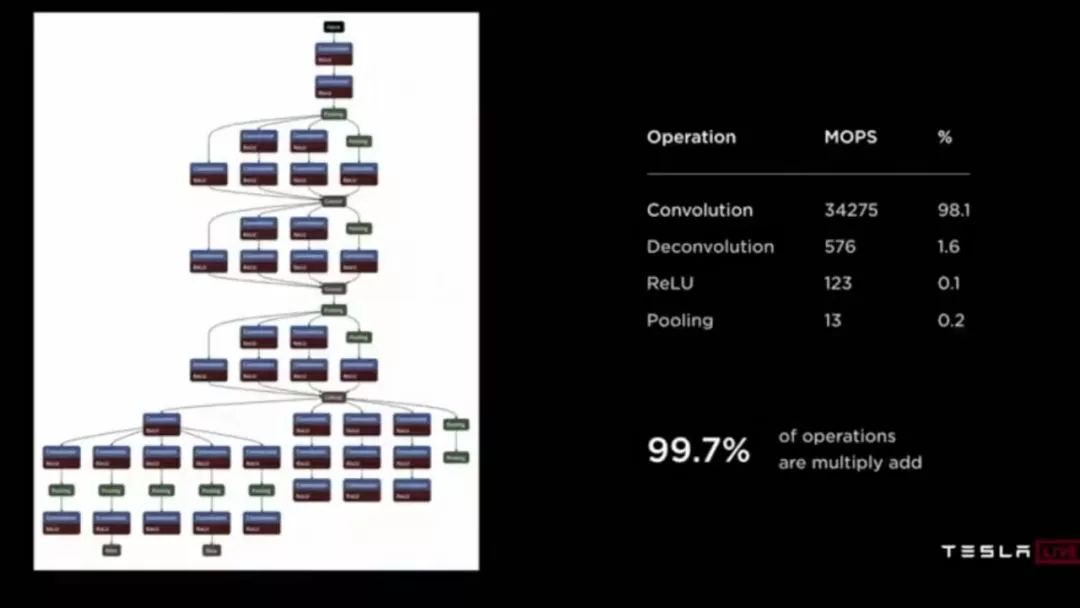
當然,芯片中自研的最重要的部分是Neural Network Processor,也是發布中重點介紹的內容。首先是整體信息,每顆芯片有兩個NNP,每個NNP有一個96x96個MAC的矩陣,32MB SRAM,工作在2GHz。所以一個NNP的處理能力是96x96x2(OPs)x2(GHz) = 36.864TOPS,單芯片72TOPS,板卡144TOPS。
這里比較值得注意的片上SRAM的數量。如果我們對比Google的初代TPU(256 x 256MAC,24MiB SRAM),這個片上存儲的數量是相當高的。從下圖也可以看到NNP中存儲器大概占了總面積3/4以上。Pete Bannon的解釋是為了降低功耗,他們的設計目標是將所有的模型都能存儲在片上。精度的選擇是乘法8bit,加法32bit。之后Pete Bannon介紹了芯片工作的方式,沒有太多新鮮的東西。讀256B activation和128Bweight,經過變形和buffer,組合成96x96的乘加,然后在MAC矩陣中進行運算,最后結果shift out到專門的ReLU和Pool的硬件模塊,然后再以每周期128B的帶寬存回memory。由于MAC矩陣是96x96,所以在把數據輸入給MAC矩陣之前,需要做數據格式的變換。完成這一系列動作,總帶寬需求是1TB/Sec。考慮到所有數據都在片上SRAM中,這個帶寬比較容易滿足。
Pete Bannon還提了一下控制邏輯功耗的問題,認為ICache,Register File和Control邏輯消耗的能量要遠比運算消耗的能量大,所以NNP的設計就盡量簡化了控制邏輯,只做運算。相應的,指令集比較簡單,只有8條指令:DMA Read,DMA Write,Convolution,Deconvolution,Inner-product,Scale,Eltwidth,Stop。編程模型(控制流)也非常簡單,完成一次運算只需配置4個信息。另外也介紹了編譯工具,這個基本也是常見的功能。

最后,Pete Bannon給出了芯片的實際性能指標,2300 幀/秒,72W。當然我們并不知道這是運行什么網絡的結果。如果是講演中給出的如下示例網絡,每幀需要35GOPS,每秒是35x2300=80TOPS,即能達到55%左右的利用率。
到此我們看到了FSD芯片的一些細節,但還不足以充分了解它的架構設計。實際上,在這次公開之前,Tesla是給NNP申請了一系列專利的[2],我們可以從中看到一些更詳細的東西。
專利布局
Tesla目前公開的專利,大體的思路和Google之前給TPU申請專利也是差不多的(Google的神經網絡處理器專利),先申請整體框架和方法的專利,然后是具體運算,數據格式準備,Vector處理,包括下面幾個。
專利和實際實現可能是有很大差別的
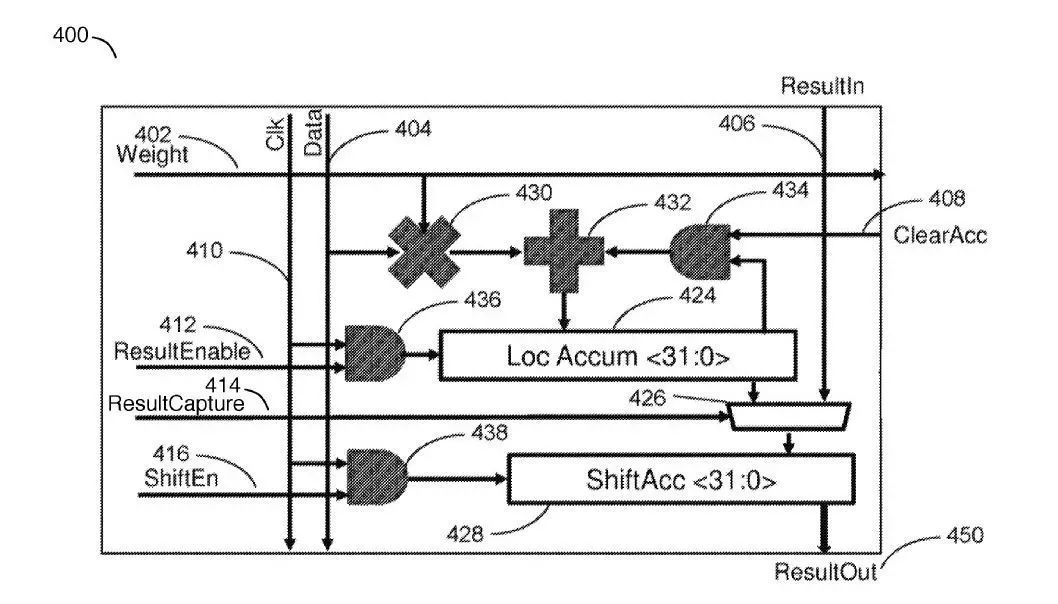
它的基本硬件架構主要是圍繞一個大的矩陣處理器(MATRIX PROCESSOR)做文章
source:Tesla patent “ACCELERATED MATHEMATICAL ENGINE”
Data和Weight分別經過一個FORMATTER進行格式的轉換,存入BUFFER,之后有一個硬件電路讀出提供給矩陣處理器。專利中提到FORMATTER可以用軟件或者硬件實現,它們實際芯片中應該是硬件實現的。由于要有效利用這種規模(96x96)的MAC矩陣,必須把輸入數據排好,這個FORMATTER起到了很大作用。因此他們也專門對它申請了專利(Google也是類似情況),有興趣的同學也可以看看。
在完成了矩陣乘加運算后,結果會移出(shift)矩陣處理器(根據專利里的描述,應該是從上向下逐級移動)進行后續處理,包括累加,ReLU,和Pooling。由Vector Engine和Post-Processing Unit完成。這部分也有專門的專利(申請時間要晚一些),表述上和主架構專利似乎有點不一致。此外就是控制邏輯部分,這部分是一個盡量簡單的設計。
下面我們進入矩陣處理器(MAC Array)內部看看運算單元的設計。
source:Teslapatent “ACCELERATED MATHEMATICAL ENGINE”
對比一下Google的專利中的計算單元,
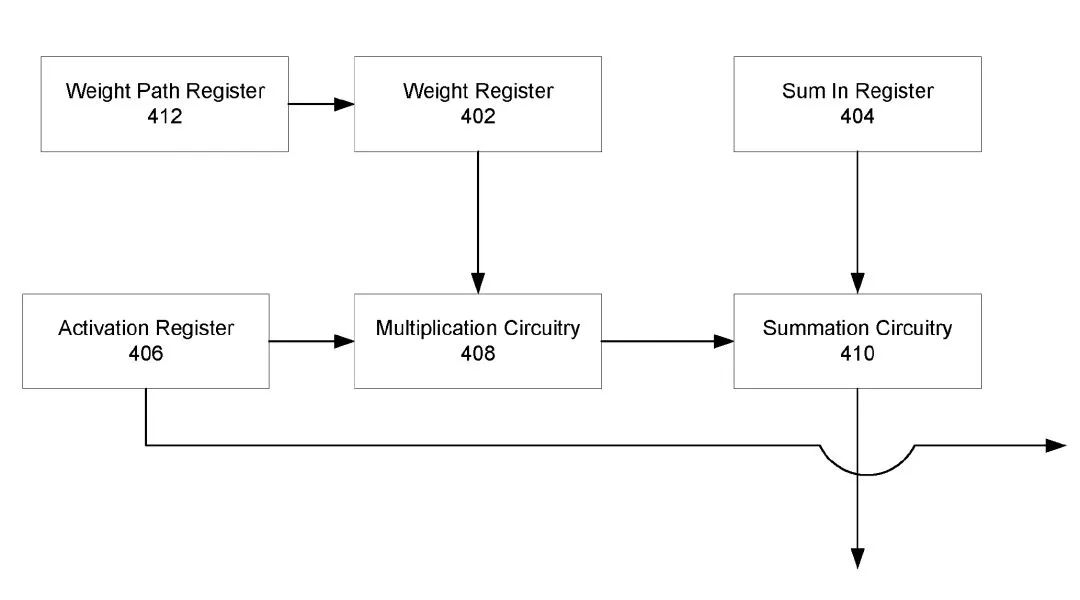
source:Googlepatent “NEURAL NETWORK PROCESSOR”
可以看出主要的區別在于Tesla多了一級累加器ShiftAcc,支持的數據流也能更靈活一些。總得來說,Tesla描述的架構和Google TPU專利描述的NNP("Neural network processor")是類似的,不過看起來在設計和表述上更為完整。在具體實現上,一個主要區別在于,FSD芯片主要使用片上SRAM工作,而不像是Google TPU還需要使用片外的DRAM。當然,還是那句話,專利不代表具體實現,而且Google的專利要早很多。這里只是單純參考一下。
這幾個專利中還有一些有意思的細節,時間關系我每來及細讀。大家感興趣可以自己閱讀一下,有趣的信息也歡迎留言分享。我把這四個專利整理了一下,大家可以在后臺回復“teslapat”獲得下載的鏈接。回復“googlepat”可以獲得Google專利的鏈接。
Q&A環節的花絮
回到Tesla的活動,在芯片發布之后還進行了Q&A環節,這部分其實也很有意思。首先,Elon Musk說了如下一段話(大意),“我們今天之所以要提供如此詳細的信息,就是因為,在一開始,對于Tesla這樣從沒做過芯片的公司來說,要研發一顆世界最先進的芯片看起來是不可能的。我們的目標就是這樣,而且我們的目標不僅僅是領先一點,而是大幅度的領先。”從這段話可以看出,Tesla自研芯片應該是有必要性和能力上的質疑的。對于系統和應用廠商來說,這種質疑也是很正常的。必要性比較容易講,如問答環節所說,Telsa如果每年賣上百萬輛車,而自研芯片能讓整車成本降低,當然就值得去做。而針對芯片研發的能力的質疑,這次發布算是一個回答。所以,雖然這顆芯片目前還談不上世界領先(指標上和Nvidia的對比是不太科學的,這個Nvidia已有回應),Musk也要硬著頭皮去說。從另一個角度,這顆芯片至少可以證明自研的可行性。而且Musk也很認真強調了這套系統的優勢在于它的軟硬件都是專門為Tesla的自動駕駛定制的。對比Nvidia,他是這么說的,“Nvidia is great company, but they have many customers, as they apply their resources, they need to do a generalized solution. We care about one thing so private. It was designed to do that increadibly well and the software was also designed runing on that hardware increadibly well. The combination of hardware and software I think is unbeatable.” 看起來Tesla會在這條路上繼續走下去。在被問道工藝問題的時候,Elon Musk專門提到下一代芯片正在研發當中(已經halfway done)。
在被問道是否使用Lidar,Elon Musk說“lidar is fool's errand, anyone luck reliant on lidar is doomed.”在后面關于神經網絡和軟件的talk里,AI網紅Andrej Karpathy也解釋了這個觀點,"Lidar只是回避了關鍵的圖像識別問題,只是給我們一個技術進步的假想,雖然可以做一些快速DEMO,最終肯定失敗"。
還有一個關于實際路測和仿真的問題,Elon Musk說,“Tesla也做很好的仿真,不過還是很難模擬真實環境發生的各種情況,如果仿真環境能夠模擬真實情況(這里他頓了一下)我們也不知道自己是不是生活在仿真環境中。”好像他確實認真的感知了一下。
總結
Tesla的自動駕駛芯片是FSD系統的最重要部分,其對標的產品應該是Nvidia的Nvidia Xavier SoC芯片(參考Hot Chips 30 - 巨頭們亮“肌肉”中相關部分)。客觀來看,Tesla的芯片和NvidiaXavier SoC芯片在各方面還是有差距的。Tesla的SoC設計中,除了自研的Neural Network Processor部分之外,其它都是用業界標準IP,并沒做太多定制工作,只能說中規中矩。而NNP也是一個比較簡單的架構,也很難說做了很多架構和技術上的創新。從另一個角度來看,這款芯片如果真的大量使用了,那它至少也是合格的。可以看到,Tesla的目標和執行策略是清晰和實際的,這是系統廠商自研芯片的最大優勢。
-
芯片
+關注
關注
455文章
50771瀏覽量
423412 -
FSD
+關注
關注
0文章
95瀏覽量
6113
原文標題:【分析】多角度解析Tesla FSD自動駕駛芯片
文章出處:【微信號:TechSugar,微信公眾號:TechSugar】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
馬斯克突然訪華,特斯拉FSD要落地中國?對國內市場有何影響?
特斯拉正在為FSD套件研發新的停車功能
特斯拉FSD,從全棧自研到智能駕駛的未來

成都匯陽投資關于FSD 有望入華,加速智駕行業發展

特斯拉智能駕駛|從視覺優先的技術路徑到未來的挑戰?
小鵬汽車董事長何小鵬談特斯拉FSD與Robotaxi
特斯拉正準備在中國推送FSD功能
特斯拉中國有望推出FSD系統
特斯拉正與車企洽談FSD系統授權事宜
馬斯克要求員工交付前開啟FSD功能進行試駕
特斯拉FSD自動駕駛系統“將入華”的消息仍在持續發酵
特斯拉FSD進入中國?假消息!






 工商網監
工商網監
評論