") 新手如何入門Python算法?
新手如何入門Python算法?
學(xué)會了Python基礎(chǔ)知識,想進階一下,那就來點算法吧!畢竟編程語言只是工具,結(jié)構(gòu)算法才是靈魂。
新手如何入門Python算法?
幾位印度小哥在GitHub上建了一個各種Python算法的新手入門大全。從原理到代碼,全都給你交代清楚了。為了讓新手更加直觀的理解,有的部分還配了動圖。
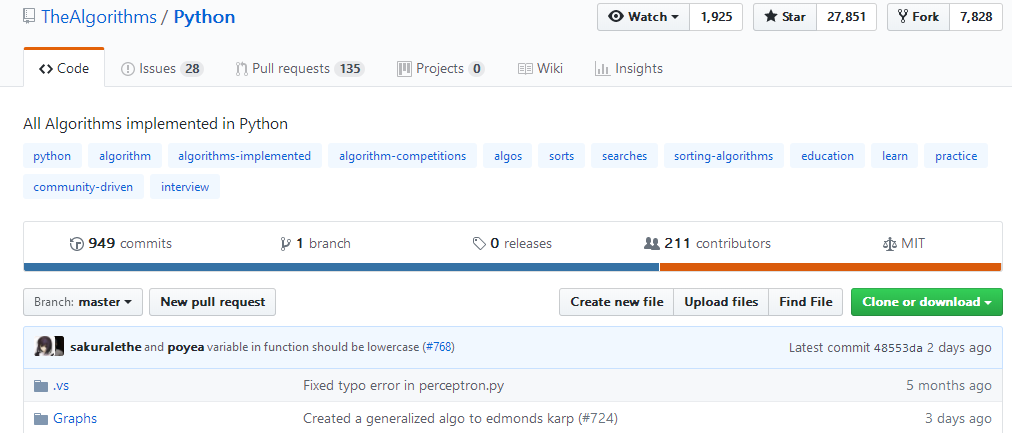
標星已經(jīng)達到2.7W
給出Github地址?
https://github.com/TheAlgorithms/Python
這個項目主要包括兩部分內(nèi)容:一是各種算法的基本原理講解,二是各種算法的代碼實現(xiàn)。
算法的代碼實現(xiàn)
算法的代碼實現(xiàn)給的資料也比較豐富,除了算法基礎(chǔ)原理部分的Python代碼,還有包括神經(jīng)網(wǎng)絡(luò)、機器學(xué)習(xí)、數(shù)學(xué)等等代碼實現(xiàn)。
例如在神經(jīng)網(wǎng)絡(luò)部分,給出了BP神經(jīng)網(wǎng)絡(luò)、卷積神經(jīng)網(wǎng)絡(luò)、全卷積神經(jīng)網(wǎng)絡(luò)以及感知機等。
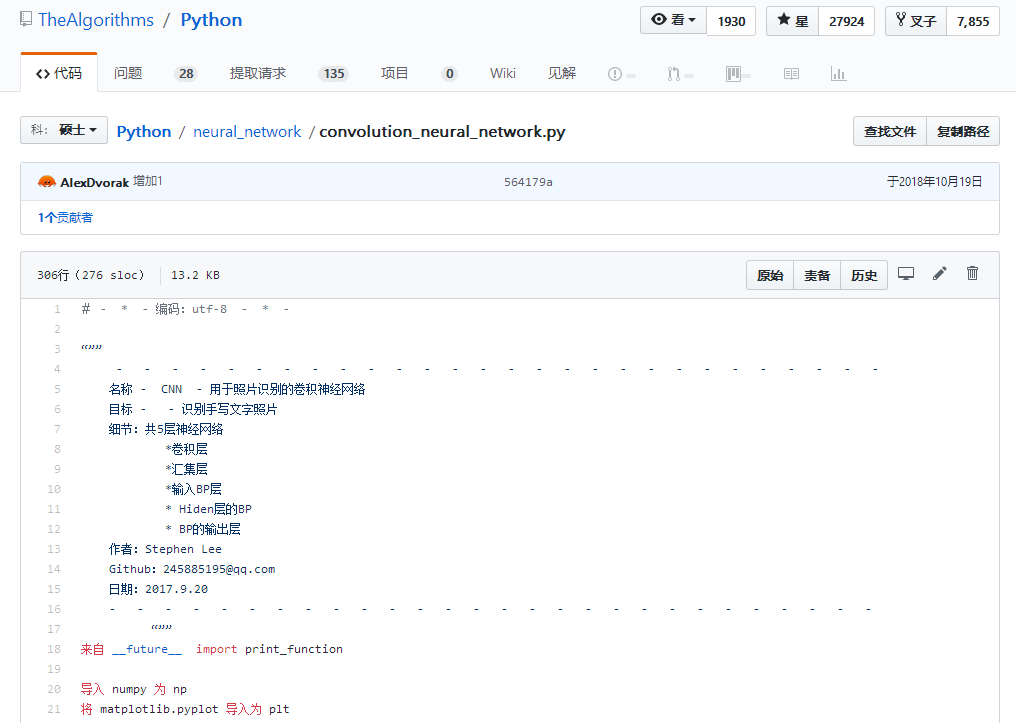
卷積神經(jīng)網(wǎng)絡(luò)代碼示例
代碼以Python文件格式保存在Github上,需要的同學(xué)可以自行保存下載。
再次給出github地址:
https://github.com/TheAlgorithms/Python
算法原理
在算法原理部分主要介紹了排序算法、搜索算法、插值算法、跳躍搜索算法、快速選擇算法、禁忌搜索算法、加密算法等。
當(dāng)然,除了文字解釋之外,還給出了幫助更好理解算法的相應(yīng)資源鏈接,包括維基百科、動畫交互網(wǎng)站鏈接。
例如,在一些算法部分中,其給出的動畫交互鏈接,非常完美幫助理解算法的運行機制。
交互動畫地址:
https://www.toptal.com/developers/sorting-algorithms/bubble-sort
排序算法
冒泡排序
冒泡排序,有時也被稱做沉降排序,是一種比較簡單的排序算法。這種算法的實現(xiàn)是通過遍歷要排序的列表,把相鄰兩個不符合排列規(guī)則的數(shù)據(jù)項交換位置,然后重復(fù)遍歷列表,直到不再出現(xiàn)需要交換的數(shù)據(jù)項。當(dāng)沒有數(shù)據(jù)項需要交換時,則表明該列表已排序。
桶排序算法
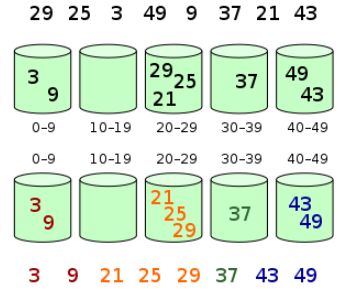
桶排序(Bucket sort) 或所謂的箱排序,是一個 排序算法 ,工作的原理是將數(shù)組分到有限數(shù)量的桶子里。每個桶子再個別排序,有可能再使用別的排序算法或是以遞歸方式繼續(xù)使用桶排序進行排序。
雞尾酒排序
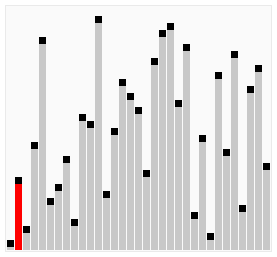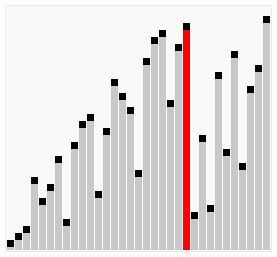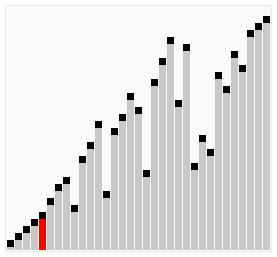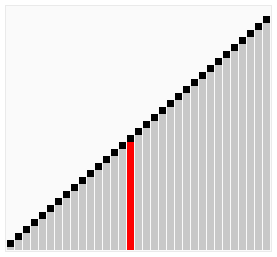
雞尾酒排序,也就是定向冒泡排序,雞尾酒攪拌排序,攪拌排序(也可以視作選擇排序的一種變形),漣漪排序,來回排序或快樂小時排序,都是冒泡排序的一種變形。此算法與冒泡排序的不同處在于排序時是以雙向在序列中進行排序。
譯者注:
雞尾酒排序等于是冒泡排序的輕微變形。不同的地方在于從低到高然后從高到低,而冒泡排序則僅從低到高去比較序列里的每個元素。他可以得到比冒泡排序稍微好一點的性能,原因是冒泡排序只從一個方向進行比對(由低到高),每次循環(huán)只移動一個項目。
以序列(2,3,4,5,1)為例,雞尾酒排序只需要訪問一次序列就可以完成排序,但如果使用冒泡排序則需要四次。但是在隨機數(shù)序列的狀態(tài)下,雞尾酒排序與冒泡排序的效率都很差勁。
插入排序

插入排序(Insertion Sort)是一種簡單直觀的排序算法。它的工作原理是通過構(gòu)建有序序列,對于未排序數(shù)據(jù),在已排序序列中從后向前掃描,找到相應(yīng)位置并插入。插入排序在實現(xiàn)上,通常采用in-place排序的額外空間的排序,因而在從后向前掃描過程中,需要反復(fù)把已排序元素逐步向后挪位,為最新元素提供插入空間。
歸并排序
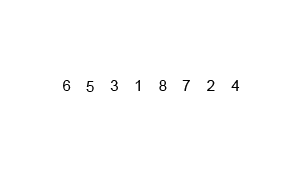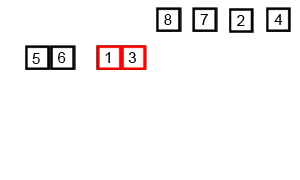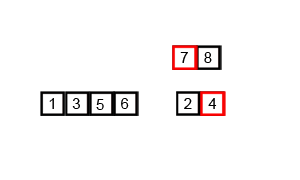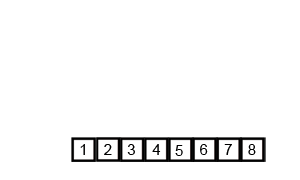
歸并排序(Merge sort,或mergesort),是創(chuàng)建在歸并操作上的一種有效的排序算法,效率為O(n log n)(大O符號)。1945年由約翰·馮·諾伊曼首次提出。該算法是采用分治法(Divide and Conquer)的一個非常典型的應(yīng)用,且各層分治遞歸可以同時進行。
堆(Heap)
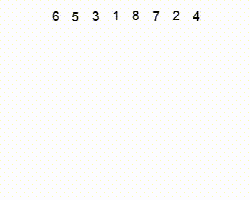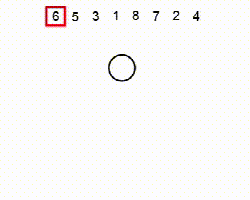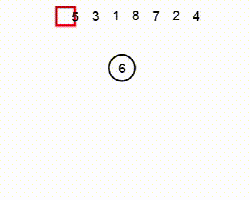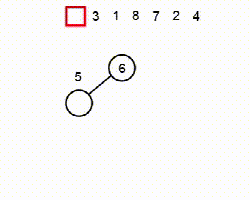
堆(Heap)是一種基于比較的排序算法。它可以被認為是一種改進的選擇排序。它將其輸入劃分為已排序和未排序的區(qū)域,并通過提取最大元素,將其移動到已排序區(qū)域來迭代縮小未排序區(qū)域。
譯者注:
Heap 始于 J._W._J._Williams 在 1964 年發(fā)表的堆排序(heap sort),當(dāng)時他提出了二叉堆樹作為此算法的數(shù)據(jù)結(jié)構(gòu)。
在隊列中,調(diào)度程序反復(fù)提取隊列中第一個作業(yè)并運行,因為實際情況中某些時間較短的任務(wù)將等待很長時間才能結(jié)束,或者某些不短小,但具有重要性的作業(yè),同樣應(yīng)當(dāng)具有優(yōu)先權(quán)。堆即為解決此類問題設(shè)計的一種數(shù)據(jù)結(jié)構(gòu)。
基數(shù)排序
基數(shù)排序(Radix sort)是一種非比較型整數(shù)排序算法,其原理是將整數(shù)按位數(shù)切割成不同的數(shù)字,然后按每個位數(shù)分別比較。由于整數(shù)也可以表達字符串(比如名字或日期)和特定格式的浮點數(shù),所以基數(shù)排序也不是只能使用于整數(shù)。基數(shù)排序的發(fā)明可以追溯到1887年赫爾曼·何樂禮在打孔卡片制表機(Tabulation Machine)上的貢獻。
選擇排序

選擇排序(Selection sort)是一種簡單直觀的排序算法。它的工作原理如下。首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再從剩余未排序元素中繼續(xù)尋找最小(大)元素,然后放到已排序序列的末尾。以此類推,直到所有元素均排序完畢。
Shell排序
ShellSort是插入排序的一種推廣,允許交換相距很遠的項。思路是安排元素列表,以便從任何地方開始,考慮到每個第n個元素都會給出一個排序列表。這樣的列表叫做h排序。等效地,可以被認為是h交錯列表,每個元素都是單獨排序的。
拓撲
拓撲排序或有向圖的拓撲排序是其頂點的線性排序,使得對于從頂點u到頂點v的每個有向邊uv,u在排序中位于v之前。例如,圖的頂點可以表示要執(zhí)行的任務(wù),并且邊可以表示一個任務(wù)必須在另一個之前執(zhí)行的約束;在這個應(yīng)用程序中,拓撲排序只是任務(wù)的有效序列。當(dāng)且僅當(dāng)圖形沒有有向循環(huán)時,即,如果它是有向非循環(huán)圖,則拓撲排序是可能的(DAG)。任何DAG都具有至少一個拓撲排序,并且已知算法用于在線性時間內(nèi)構(gòu)建任何DAG的拓撲排序。
時間復(fù)雜折線圖
比較排序算法的復(fù)雜性(冒泡排序,插入排序,選擇排序)
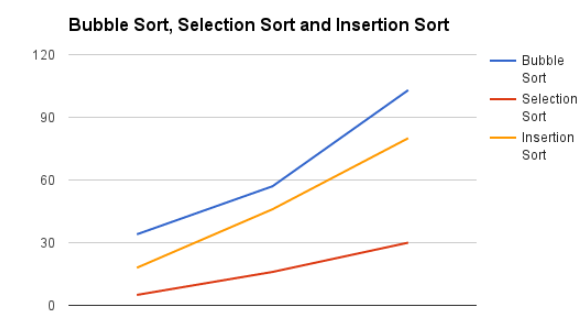
比較排序算法:
Quicksort是一種非常快速的算法,但實現(xiàn)起來相當(dāng)棘手。Bubble sort是一種慢速算法,但很容易實現(xiàn)。為了對小數(shù)據(jù)集進行排序,冒泡排序可能是一個更好的選擇。
搜索算法
線性搜索
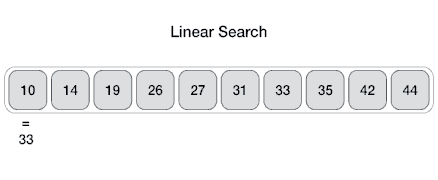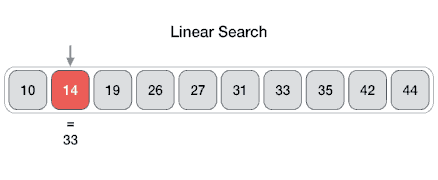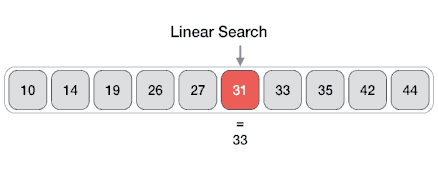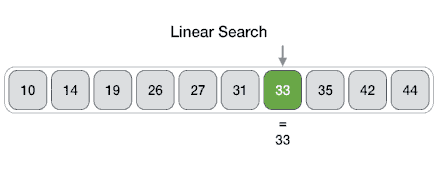
線性搜索或順序搜索是用于在列表中查找目標值的方法。它按順序檢查列表中的每個元素的目標值,直到找到匹配或直到搜索完所有元素。
假設(shè)一個數(shù)組中有N個元素,最好的情況就是要尋找的特定值就是數(shù)組里的第一個元素,這樣僅需要1次比較就可以。而最壞的情況是要尋找的特定值不在這個數(shù)組或者是數(shù)組里的最后一個元素,這就需要進行N次比較。
Binary 二進制搜索
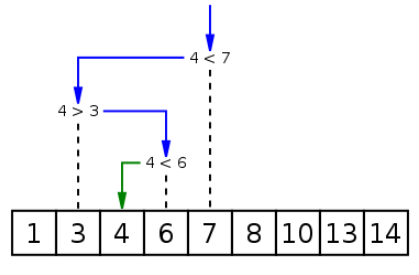
二進制搜索,也稱為半間隔搜索或?qū)?shù)搜索,用于查找已排序數(shù)組中目標值的位置。它將目標值與數(shù)組的中間元素進行比較,如果它們不相等,則目標的一半被消除,并且在剩下的一半上繼續(xù)搜索直到成功。
插值搜索
插值搜索是一種用于搜索已按照鍵值的數(shù)值排序的數(shù)組中鍵的算法。
最先由WW Peterson在1957年描述。插值搜索類似于人們在電話目錄中搜索名稱的方法(用于訂購書籍條目的關(guān)鍵值):在每個步驟中,算法計算剩余搜索空間中的位置,基于搜索空間邊界處的鍵值和所尋找的鍵的值,通常可以通過線性插值來尋找項目。
相比之下,二進制搜索總是選擇剩余搜索空間的中間,丟棄一半或另一半,這取決于在估計位置找到的密鑰與所尋找的密鑰之間的比較。剩余的搜索空間縮小到估計位置之前或之后的部分。線性搜索僅使用相等性,因為它從一開始就逐個比較元素,忽略任何排序。
平均插值搜索使得log(log(n))比較(如果元素均勻分布),其中n是要搜索的元素的數(shù)量。在最壞的情況下(例如,鍵的數(shù)值以指數(shù)方式增加),它可以構(gòu)成O(n)比較。
在插值順序搜索中,插值用于查找正在搜索的項目附近的項目,然后使用線性搜索來查找確切項目。
跳轉(zhuǎn)搜索
跳轉(zhuǎn)搜索是指有序列表的搜索算法。它首先檢查所有項目的Lkm,其中K∈N,并且m是塊大小,直到找到大于搜索關(guān)鍵字的項目。為了在列表中找到搜索關(guān)鍵字的確切位置,在子列表L[(k-1)m,km]上執(zhí)行線性搜索。
m的最優(yōu)值是√n,其中n是列表L的長度。因為算法的兩個步驟最多都是√n項,所以算法在O(√n)時間內(nèi)運行。這比線性搜索更好,但比二分搜索差。優(yōu)于后者的優(yōu)點是跳轉(zhuǎn)搜索只需要向后跳一次,而二進制可以向后跳轉(zhuǎn)到記錄n次。
在最終執(zhí)行線性搜索之前,可以通過在子列表上執(zhí)行多級跳轉(zhuǎn)搜索來修改算法。對于k級跳躍搜索,第l級的最佳塊大小ml(從1開始計數(shù))是n(k1)/k。修改后的算法將執(zhí)行k個向后跳轉(zhuǎn)并在O(kn1/(k+ 1))時間內(nèi)運行。
快速選擇算法
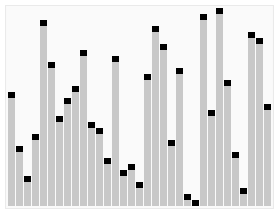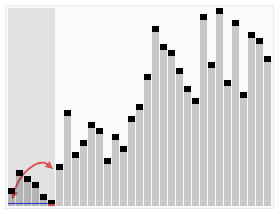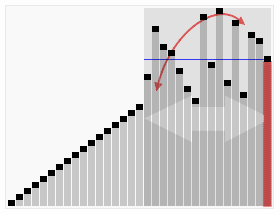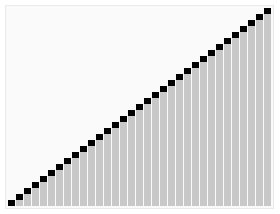
快速選擇(Quicksort)是一種從無序列表找到第k小元素的選擇算法。它從原理上來說與快速排序有關(guān)。與快速排序一樣都由托尼·霍爾提出的,因而也被稱為霍爾選擇算法。同樣地,它在實際應(yīng)用是一種高效的算法,具有很好的平均時間復(fù)雜度,然而最壞時間復(fù)雜度則不理想。快速選擇及其變種是實際應(yīng)用中最常使用的高效選擇算法。
快速選擇的總體思路與快速排序一致,選擇一個元素作為基準來對元素進行分區(qū),將小于和大于基準的元素分在基準左邊和右邊的兩個區(qū)域。不同的是,快速選擇并不遞歸訪問雙邊,而是只遞歸進入一邊的元素中繼續(xù)尋找。這降低了平均時間復(fù)雜度,從O(n log n)至O(n),不過最壞情況仍然是O(n2)。
禁忌搜索
禁忌搜索(Tabu Search,TS,又稱禁忌搜尋法)是一種現(xiàn)代啟發(fā)式算法,由美國科羅拉多大學(xué)教授Fred Glover在1986年左右提出的,是一個用來跳脫局部最優(yōu)解的搜索方法。其先創(chuàng)立一個初始化的方案;基于此,算法“移動”到一相鄰的方案。經(jīng)過許多連續(xù)的移動過程,提高解的質(zhì)量。
密碼
凱撒密碼
凱撒密碼,也稱為凱撒密碼,移位密碼,凱撒代碼或凱撒移位,是最簡單和最廣為人知的加密技術(shù)之一。
它是一種替換密碼,其中明文中的每個字母都被字母表中的一些固定數(shù)量的位置的字母替換。例如,左移3,D將被A替換,E將變?yōu)锽,依此類推。
該方法以Julius Caesar的名字命名,最初是他在私人通信中使用了它。由Caesar密碼執(zhí)行的加密步驟通常作為更復(fù)雜的方案的一部分,例如Vigenère密碼,并且仍然在ROT13系統(tǒng)中具有現(xiàn)代應(yīng)用。與所有單字母替換密碼一樣,Caesar密碼很容易破解,在現(xiàn)代實踐中基本上沒有通信安全性。
Vigenère密碼
Vigenère密碼是一種通過使用基于關(guān)鍵字字母的一系列交織的凱撒密碼來加密字母文本的方法。它是一種多字母替代形式。
Vigenère密碼該方法最初由Giovan Battista Bellaso在其1553年的書“La cifra del”中提出。然而,該計劃后來在19世紀被誤用于BlaisedeVigenère,現(xiàn)在被廣泛稱為“Vigenère密碼”。
雖然該密碼易于理解和實施,但三個世紀以來它一直抵制所有打破密碼的企圖,因此也被稱為這lechiffreindéchiffrable(法語為“難以理解的密碼”)。Friedrich Kasiski是第一個在1863年發(fā)表破譯Vigenère密碼的通用方法。
轉(zhuǎn)置密碼
轉(zhuǎn)置密碼是一種加密方法,通過該加密方法,明文單元(通常是字符或字符組)所保持的位置根據(jù)常規(guī)系統(tǒng)移位,使得密文構(gòu)成明文的排列。也就是說,單位的順序改變(明文被重新排序)。
在數(shù)學(xué)上,雙字符函數(shù)用于加密字符的位置和用于解密的反函數(shù)。
RSA (Rivest–Shamir–Adleman)
RSA加密算法是一種非對稱加密算法。在公開密鑰加密和電子商業(yè)中RSA被廣泛使用。RSA是1977年由羅納德·李維斯特(Ron Rivest)、阿迪·薩莫爾(Adi Shamir)和倫納德·阿德曼(Leonard Adleman)一起提出的。當(dāng)時他們?nèi)硕荚诼槭±砉W(xué)院工作。RSA就是他們?nèi)诵帐祥_頭字母拼在一起組成的。
1973年,在英國政府通訊總部工作的數(shù)學(xué)家克利福德·柯克斯(Clifford Cocks)在一個內(nèi)部文件中提出了一個與之等效的算法,但該算法被列入機密,直到1997年才得到公開。
ROT13
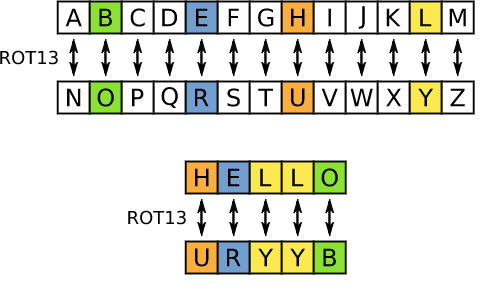
ROT13(“旋轉(zhuǎn)13個位置”,有時用連字符ROT-13)是一個簡單的字母替換密碼,用字母表后面的第13個字母替換一個字母。ROT13是古羅馬開發(fā)的Caesar密碼的特例。
因為基本拉丁字母中有26個字母(2×13),所以ROT13是自身的反轉(zhuǎn),也就是說,要撤消ROT13需要相同的算法,因此可以使用相同的動作進行編碼和解碼。該算法幾乎不提供加密安全性,并且經(jīng)常被引用為弱加密的典型示例。
-
算法
+關(guān)注
關(guān)注
23文章
4615瀏覽量
93000 -
編程語言
+關(guān)注
關(guān)注
10文章
1945瀏覽量
34785 -
python
+關(guān)注
關(guān)注
56文章
4797瀏覽量
84777
原文標題:Github標星2w+,熱榜第一,如何用Python實現(xiàn)所有算法
文章出處:【微信號:BigDataDigest,微信公眾號:大數(shù)據(jù)文摘】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
Python快速入門方法



Python的Anaconda入門指南
Python新手們,快把算法練起來






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論