") 人工智能最后一公里,Google和英偉達誰能跑得贏?
人工智能最后一公里,Google和英偉達誰能跑得贏?
Google Coral Edge TPU和NVIDIA Jetson Nano大比拼!本文從分別對兩款最新推出的EdgeAI芯片做了對比,分析了二者各自的優(yōu)劣勢。
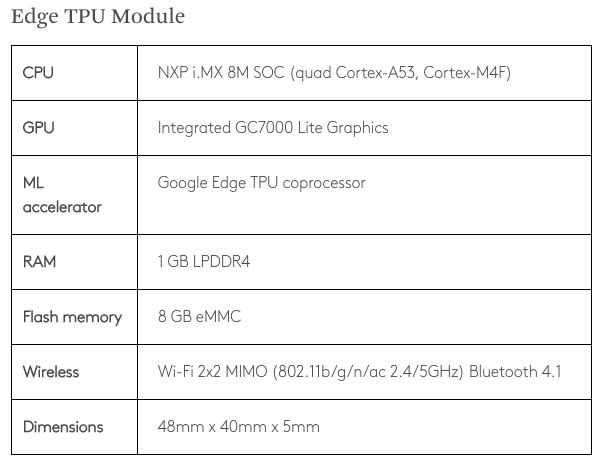
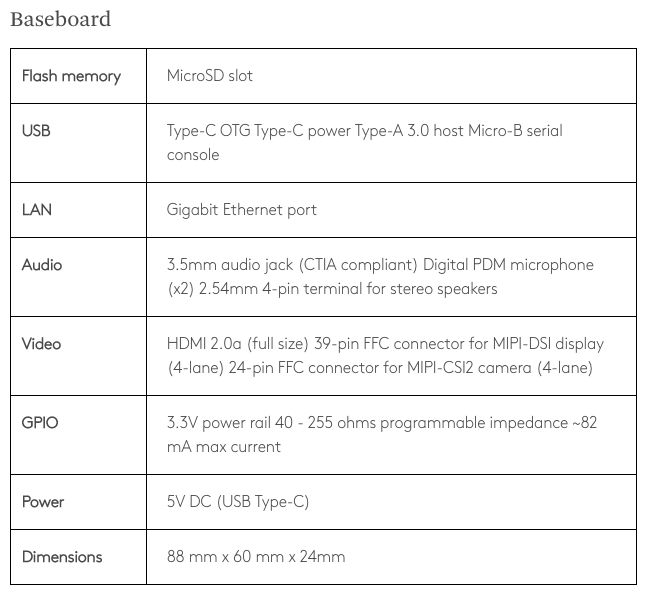
Google剛剛在3月份推出了Coral Edge TPU,是一款售價不到1000元人民幣的開發(fā)板(Coral Dev Board),由Edge TPU模塊和 Baseboard 組成。參數(shù)如下:
英偉達同樣在上個月發(fā)布了最新的NVIDIA Jetson Nano,Jetson Nano是一款類似于樹莓派的嵌入式電腦設備,其搭載了四核Cortex-A57處理器,GPU則是擁有128個NVIDIA CUDA核心的NVIDIA麥克斯韋架構顯卡,內(nèi)存4GB LPDDR4,存儲則為16GB eMMC 5.1,支持4K 60Hz視頻解碼。
目前位置并沒有太多關于這兩款產(chǎn)品的評測報告。今天新智元為大家?guī)硪黄删W(wǎng)友Sam Sterckval對兩款產(chǎn)品的評測,除此以外他還測試了i7-7700K + GTX1080(2560CUDA),Raspberry Pi 3B +,以及一個2014年的MacBook pro包含一個i7-4870HQ(沒有支持CUDA的內(nèi)核)。
Sam使用MobileNetV2作為分類器,在imagenet數(shù)據(jù)集上進行預訓練,直接從Keras使用這個模型,后端則使用TensorFlow。使用GPU的浮點權重,以及CPU和Coral Edge TPU的8bit量化tflite版本。
首先,加載模型以及一張喜鵲圖像。先執(zhí)行1個預測作為預熱,Sam發(fā)現(xiàn)第一個預測總是比隨后的預測更能說明問題。然后Sleep 1秒,確保所有的線程的活動都終止,然后對同一圖像進行250次分類。
對所有分類使用相同的圖像,能夠確保在整個測試過程中保持接近的數(shù)據(jù)總線。
對比結(jié)果
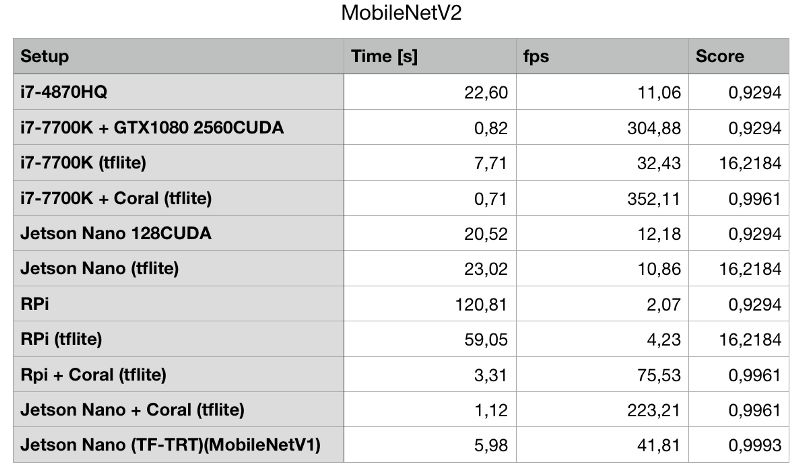
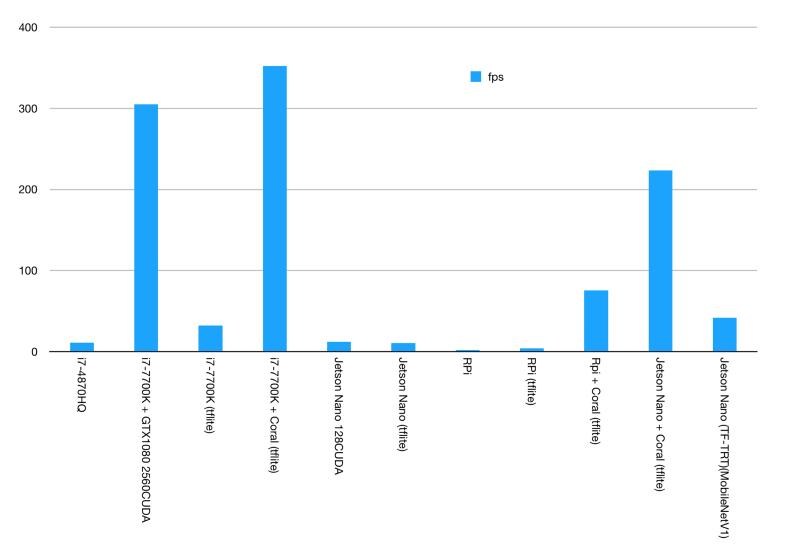
先來看最終的結(jié)果:
線性刻度,F(xiàn)PS
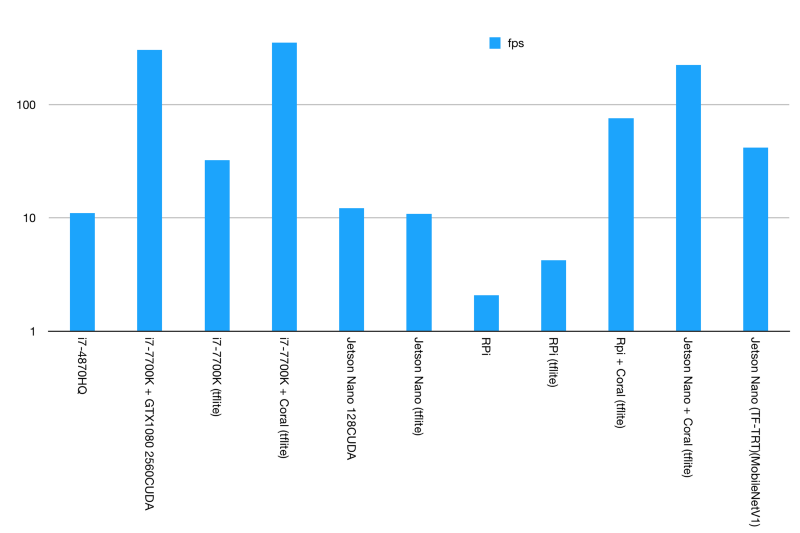
對數(shù)刻度,F(xiàn)PS
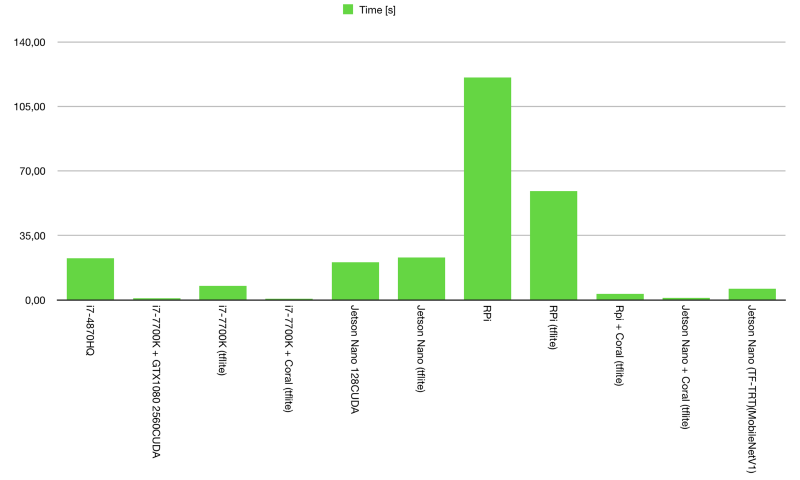
線性刻度,推理時間(250x)
Sam發(fā)現(xiàn)使用CPU的量化tflite模型得分是不同的,但似乎它總是返回與其它產(chǎn)品相同的預測結(jié)果,他懷疑模型有點奇怪,但能確保它不會影響性能。
對比分析
第一個柱狀圖中我們可以看到有3個比較突出的數(shù)據(jù),其中兩個2個是由Google Coral Edge TPU USB加速器實現(xiàn)的,第3個是由英特爾i7-7700K輔助NVIDIA GTX1080實現(xiàn)。
我們再仔細對比一下就會發(fā)現(xiàn),GTX1080實際上完全無法跟Google的Coral對飚。要知道GTX1080的最大功率為180W,而Coral Edge TPU只有2.5W。
NVIDIA Jetson Nano的得分并不高。雖然它有一個支持CUDA的GPU,但實際上并沒比那臺2014年MBP的i7-4870HQ快太多,但畢竟還是比這款四核,超線程的CPU要快。
然而相比i7 50W的能耗,Jetson Nano平均能耗始終保持在12.5W,也就是說功耗降低75%,性能提升了10%。
NVIDIA Jetson Nano
盡管Jetson Nano并沒有在MobileNetV2分類器中表現(xiàn)出令人印象深刻的FPS率,但它的優(yōu)勢非常明顯:
它很便宜,能耗低,更重要的是,它運行TensorFlow-gpu或任何其他ML平臺的操作,和我們平時使用的其他設備一樣。只要我們的腳本沒有深入到CPU體系結(jié)構中,就可以運行與i7 + CUDA GPU完全相同的腳本,也可以進行訓練!Sam強烈希望NVIDIA應該使用TensorFlow預加載L4T。
來源:NVIDIA
Google Coral Edge TPU
Sam毫不掩飾的表達了他對Google Coral Edge TPU的精心設計以及高效率的喜愛。下圖我們可以對比Edge TPU有多小。
Penny for scale,來源:谷歌
Edge TPU就是所謂的“ASIC”(專用集成電路),這意味著它具有FET等小型電子部件,以及能夠直接在硅層上燒制,這樣它就可以加快在特定場景下的推力速度。但Edge TPU無法執(zhí)行反向傳播。
Google Coral Edge TPU USB加速器
下圖顯示了Edge TPU的基本原理。
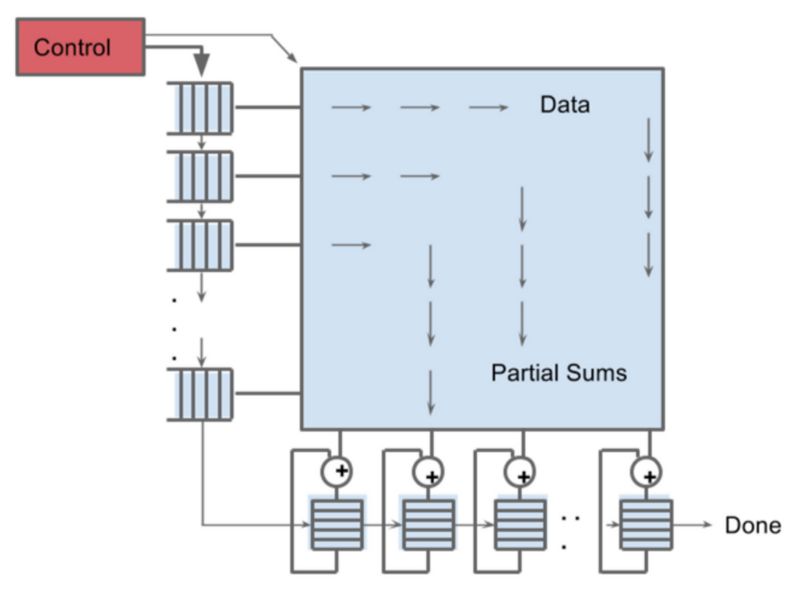
來源:谷歌
像MobileNetV2這樣的網(wǎng)絡主要由后面帶有激活層的卷積組成。公式如下:
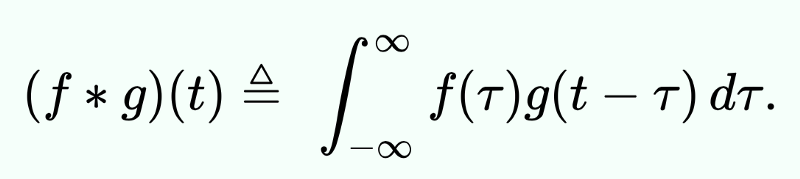
卷積
這意味著將圖像的每個元素(像素)與內(nèi)核的每個像素相乘,然后將這些結(jié)果相加,以創(chuàng)建新的“圖像”(特征圖)。這正是Edge TPU的主要工作。將所有內(nèi)容同時相乘,然后以瘋狂的速度添加所有內(nèi)容。這背后沒有CPU,只要你將數(shù)據(jù)泵入左邊的緩沖區(qū)就可以了。
我們看到Coral在性能/瓦特的對比中,差異如此大的原因,它是一堆電子設備,旨在完成所需的按位操作,基本上沒有任何開銷。
總結(jié)
為什么GPU沒有8位模型?
GPU本質(zhì)上被設計為細粒度并行浮點計算器。而Edge TPU設計用于執(zhí)行8位操作,并且CPU具有比完全位寬浮點數(shù)更快的8位內(nèi)容更快的方法,因為它們在很多情況下必須處理這個問題。
為何選擇MobileNetV2?
主要原因是,MobileNetV2是谷歌為Edge TPU提供的預編譯模型之一。
Edge TPU還有哪些其他產(chǎn)品?
它曾經(jīng)是不同版本的MobileNet和Inception,截至上周末,谷歌推出了一個更新,允許我們編譯自定義TensorFlow Lite模型。但僅限于TensorFlow Lite模型。而反觀Jetson Nano就沒有這方面的限制。
Raspberry Pi + Coral與其他人相比
為什么連接到Raspberry Pi時Coral看起來要慢得多?因為Raspberry Pi只有USB 2.0端口。
i7-7700K在Coral和Jetson Nano上的速度都會更快一些,但仍然無法和后兩者比肩。因此推測瓶頸是數(shù)據(jù)速率,不是Edge TPU。
來源:NVIDIA
-
芯片
+關注
關注
455文章
50732瀏覽量
423247 -
人工智能
+關注
關注
1791文章
47208瀏覽量
238284 -
英偉達
+關注
關注
22文章
3771瀏覽量
90994
原文標題:最新千元邊緣AI芯片比拼:谷歌Coral和英偉達Jetson誰更厲害?
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關推薦
軟銀升級人工智能計算平臺,安裝4000顆英偉達Hopper GPU
解決驗證“最后一公里”的挑戰(zhàn):芯神覺Claryti如何助力提升調(diào)試效率







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論