") 聊一聊聊天“機(jī)器人的落地及進(jìn)階實(shí)戰(zhàn)”
聊一聊聊天“機(jī)器人的落地及進(jìn)階實(shí)戰(zhàn)”
近年來,聊天機(jī)器人技術(shù)及產(chǎn)品得到了快速的發(fā)展。聊天機(jī)器人作為人工智能技術(shù)的殺手級應(yīng)用,發(fā)展得如火如荼,各種智能硬件層出不窮。
本次公開課中,AI科技大本營聯(lián)合電子工業(yè)出版社博文視點(diǎn)邀請到上海瓦歌智能科技有限公司總經(jīng)理,狗尾草科技人工智能研究院院長邵浩老師,他將在3月21日的公開課中為大家講解聊天機(jī)器人落地及進(jìn)階實(shí)戰(zhàn)。
本課程將全面闡述聊天機(jī)器人的技術(shù)框架及工程實(shí)現(xiàn)細(xì)節(jié),并對于聊天機(jī)器人的下一代范式:虛擬生命,進(jìn)行了詳細(xì)的剖析,同時,聚焦知識圖譜在實(shí)現(xiàn)認(rèn)知智能過程中的重要作用,給出了知識圖譜的落地實(shí)踐。
本課程適合工程一線的研發(fā)人員,可以通過本課程了解聊天機(jī)器人的實(shí)現(xiàn)細(xì)節(jié)。適合高校學(xué)生,可以通過本課程學(xué)習(xí)聊天機(jī)器人的技術(shù)框架及典型算法。
以下為公開課速記整理
邵浩:今天跟大家聊一聊聊天“機(jī)器人的落地及進(jìn)階實(shí)戰(zhàn)”。我是來自深圳狗尾草智能科技有限公司的邵浩,現(xiàn)在負(fù)責(zé)公司人工智能研究院的工作,主要是做聊天機(jī)器人相關(guān)產(chǎn)品。

今天想跟大家聊的內(nèi)容包括這幾個方面,包括以下幾個部分:
第一部分,跟大家講一講聊天機(jī)器人總體產(chǎn)生的背景和技術(shù)架構(gòu);
第二部分,會跟大家聊一聊聊天機(jī)器人在工程實(shí)現(xiàn)的方方面面,這里我會配合一些代碼,跟大家解釋一下它每個模塊、每個功能是怎么實(shí)現(xiàn)的,希望大家聽完這部分之后,可以自己動手去搭一個聊天機(jī)器人;
第三部分,想跟大家聊一聊知識圖譜在虛擬生命中的應(yīng)用及技術(shù)路徑,并會簡單介紹虛擬生命,也就是我們發(fā)現(xiàn)聊天機(jī)器人的種種問題之后,想著是不是有更好的辦法去解決聊天機(jī)器人所面臨的很多問題;
最后一部分,花5-10分鐘時間跟大家聊聊工程落地的其他問題。
簡單介紹就到這里,我們言歸正傳。
聊天機(jī)器人概述
首先介紹一下背景。大家現(xiàn)在對人工智能的感覺是什么樣子?無論是AlphaGo,還是AlphaGo Zero,戰(zhàn)勝人類最頂尖的圍棋選手;還是Project Debater,一個參加人類辯論賽的機(jī)器人,在今年1月份創(chuàng)造了不俗的成績;還是波士頓動力這種行云流水般的機(jī)器人和機(jī)器狗,它也是人工智能非常好的一個應(yīng)用,而且像OpenAI曾經(jīng)在去年DOTA2比賽中也很厲害。DeepMind最近在搞《星際爭霸2》的比賽,人工智能正在突破一項(xiàng)又一項(xiàng)人類的想象空間,所以我們對人工智能現(xiàn)在有一個非常直觀的印象是什么?人工智能是上天入地?zé)o所不能的,所以我們會覺得,無論是媒體中現(xiàn)在所說到的機(jī)器人覺醒,還是人類毀滅,就變成了非常自然的一個事情。
我們?nèi)绻麕е@樣的感覺去看聊天機(jī)器人的話是什么樣的呢?我們有什么樣的使用感受?各位同學(xué)可能跟我一樣,凡是有這個聊天機(jī)器人產(chǎn)品,我們大概用了1、2天,在新鮮感過去之后,就發(fā)現(xiàn)這個東西再也不會開了,或者再也不會跟它聊天了,到底什么原因造成這種現(xiàn)象?除了誤識音、準(zhǔn)確率不高之外,我們對這些問題還是很寬容的。但是我們上次在媒體上看到一篇報道——外國用戶使用亞馬遜的Echo音箱的時候發(fā)生了什么事?他晚上正在睡覺,突然這個燈亮起來了,然后冷笑了兩聲!這個太恐怖、太嚇人了、太毛骨悚然了!如果是我碰到這種情況,在大半夜時這個音箱突然自己笑了,除了拔掉它的插頭,把它從樓上面扔下去摔得粉碎之外,也沒有什么好的辦法解我的心頭之恨,所以我們可以看到這個聊天機(jī)器人產(chǎn)品實(shí)在表現(xiàn)不佳。
說到聊天機(jī)器人產(chǎn)品為什么做得這么差?我作為一個從業(yè)者還是很寬容的,因?yàn)槲抑懒奶鞕C(jī)器人的邊界在什么地方,所以我在問聊天機(jī)器人產(chǎn)品的時候就在想:這個聊天機(jī)器人產(chǎn)品可能這個地方技術(shù)有問題,所以我不去問或者盡量避免去問它。但是普通的用戶對聊天機(jī)器人產(chǎn)品是沒有那么寬容的,我花了那么多錢買這個聊天機(jī)器人音箱,我希望的是可以跟我自然對話的機(jī)器人,但是這個達(dá)不到之后,他就會埋怨開發(fā)者。
用戶一般對我們這個產(chǎn)品的寬容度真的是很低的,他們覺得你們技術(shù)做得真的很差,其實(shí)我們行業(yè)從業(yè)者們覺得很委屈的,這個事情不能怪我們,是根據(jù)技術(shù)現(xiàn)在發(fā)展的程度所決定的。像微軟亞洲研究院副院長周明老師曾經(jīng)說過,語言智能是人工智能皇冠上的明珠,如果我們把這個美女當(dāng)作我們所有的技術(shù)的話,人工智能就是她頭上的這頂皇冠,而語言智能就是皇冠上的這顆明珠。什么意思?自然語言處理本身就是非常難的事!
我舉個簡單的例子,大家就明白了,比如我說一句話叫“明明明明明白白白喜歡他,但是他就是不說。”我問同學(xué)們,是誰喜歡誰?是誰又不說?這句話很難。我再說一句話,比如“我沒有看見他拿了你的錢包”,如果我們在不同的語氣、不同音調(diào)和重音的情況下,這句話的含義是完全不一樣的。比如說“我沒有看見他拿了你的錢包”(重音在“看見”上),這個意思就是我沒有看見他拿了你的錢包,我可能聽別人說他拿了你的錢包,但是我沒有親眼見到,或者“我沒有看見他拿了你的錢包”(重音在“錢包”上),就是說他拿了你的別的什么東西,但是他沒有拿了你的錢包。
所以我們在理解一句話時,它其實(shí)是跟上下文,跟說話者的世界觀、說話者的情緒、所在的環(huán)境、聽者的世界觀都是非常相關(guān)的,一句“你好嗎?”或者一句“吃了嗎?”在不同人物中的對話的含義是完全不一樣的,所以NLP技術(shù)本身就是非常難的事,
當(dāng)然,還是要做,為什么要做呢?
我曾經(jīng)在其他的報告也說過,微軟在2016年就提出這樣一個口號,叫“對話即平臺”,它認(rèn)為語言是人類交互最自然的方式,從遠(yuǎn)古時代開始,人類就用語言進(jìn)行狩獵時的互相協(xié)作、互相呼應(yīng),在自己豐收時,在村子里跟大家八卦八卦,促進(jìn)大家的友誼,所以語言是人類最自然的一種交互方式。但是受限于硬件和軟件,我們之前跟電腦基本上是用鍵盤和鼠標(biāo)進(jìn)行交互的,所以我們現(xiàn)在深度學(xué)習(xí)、大數(shù)據(jù)、GPU的硬件提升之后,可以直接使用語言跟機(jī)器進(jìn)行交互了,這也是為什么2016年微軟提出“對話即平臺”的這個概念。
聊天機(jī)器人生態(tài)技術(shù)體系
我們看一下聊天機(jī)器人怎樣分類的,它可以分為三個大的生態(tài)體系:一是框架,二是產(chǎn)品,三是平臺。
怎么理解?Echo是一種產(chǎn)品,Apple的Siri是一種產(chǎn)品,公子小白是一種產(chǎn)品,IBM Watson是一種產(chǎn)品,小冰也是一種聊天機(jī)器人產(chǎn)品。這些產(chǎn)品有不同的展現(xiàn)形式,比如Siri的載體是手機(jī)、微信或者微博;我們有一款音箱,它的載體是它的硬件,這些產(chǎn)品一定要有一個載體去進(jìn)行承載,這個載體就叫做聊天機(jī)器人的平臺,這個平臺可能包括像微信、LINE、MSN等等這樣一些平臺。我們可以理解為是利用這個框架來造這個產(chǎn)品的一個平臺,國外的有Alexa、LUIS、Wit,國內(nèi)有一些比如像ruyi、UNIT都屬于聊天機(jī)器人的框架。
我們再往產(chǎn)品這個方向看,產(chǎn)品主要分為兩大類方向,第一大類叫被動交互,第二大類叫主動交互。所謂被動交互就是我問它答,我跟它說一句,它跟我說一句,這叫被動交互。我們剛才講到了被動交互,被動交互其實(shí)分為好幾種。
聊天機(jī)器人的工程實(shí)踐(代碼解釋)
接下來的代碼實(shí)戰(zhàn)環(huán)節(jié),會跟大家從閑聊、到任務(wù)對話、到問答,跟大家完全梳理一下聊天機(jī)器人的所有分類。很多聊天機(jī)器人都做不到主動交互,因?yàn)樗枰軓?qiáng)的知識圖譜知識和場景設(shè)計(jì),比如在你心情不好時給你推薦一個什么音樂,這是主動交互方面,現(xiàn)在做得不是特別好。安利一下,我們出了一本書,叫《聊天機(jī)器人技術(shù)原理與應(yīng)用》,感興趣的同學(xué)們可以看一下。
現(xiàn)在開始進(jìn)入實(shí)戰(zhàn)環(huán)節(jié),我從最簡單的開始,不需要有任何知識儲備,就可以去做一個聊天機(jī)器人,一直到我們自己去搭一個聊天機(jī)器人的框架,并且利用Python去實(shí)現(xiàn)這個聊天機(jī)器人。
快速上手
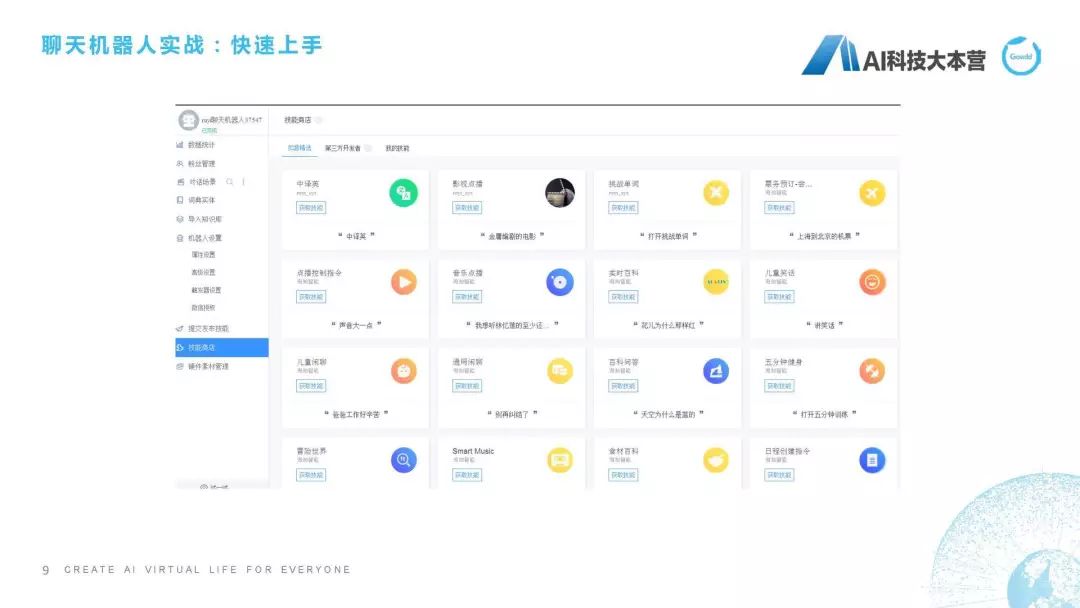
第一步帶大家看一下這個“快速上手”。我給大家準(zhǔn)備的是這個例子,大家可以看一下我的網(wǎng)頁,我給大家準(zhǔn)備的例子是一個叫ruyi的平臺,它的網(wǎng)址是ruyi.ai,打開這個網(wǎng)頁以后有一個叫“魔戒”的技能插件工具,這個時候它上面有一句話叫“我要產(chǎn)機(jī)器人”,登陸一下,我們就可以利用它的平臺去造一個機(jī)器人了。這里可以看到我現(xiàn)在建了很多聊天機(jī)器人,我可以新建一個,為了節(jié)省時間,我直接管理我現(xiàn)有的聊天機(jī)器人。可以讓機(jī)器人具有不能的技能,在技能商店里可以讓機(jī)器人擁有中譯英的技能、影視點(diǎn)播技能、挑戰(zhàn)單詞技能、兒童閑聊的技能,點(diǎn)擊“獲取技能”,它就可以直接部署,部署之后我就可以直接跟它聊天了,這個功能已經(jīng)嵌入進(jìn)去了。還有一種,是我們可以在對話場景里去建立一些新的意圖,這個意圖相當(dāng)于你配了一些語料,然后它回答一些特定的語料,比如我這里建立了一個新意圖叫“寒暄”,這個意思就是當(dāng)用戶說“Hi”或者“Hello”或者“你好”的時候,機(jī)器人回答是“Hi”/“Hello”/“你好,好久不見。”這個ruyi機(jī)器人如果我們按照這個技能去設(shè)置一下,我們可以試一下,比如我說“Hello”,它就會說“你好,好久不見”,我再說一句“Hello”,它會隨機(jī)在這兩個回復(fù)里選擇一個進(jìn)行回復(fù)。其實(shí)大家不需要任何基礎(chǔ)知識,就可以去造一個自己的聊天機(jī)器人,我們是利用ruyi.ai的平臺去做這個事情,這是最簡單的操作方法。
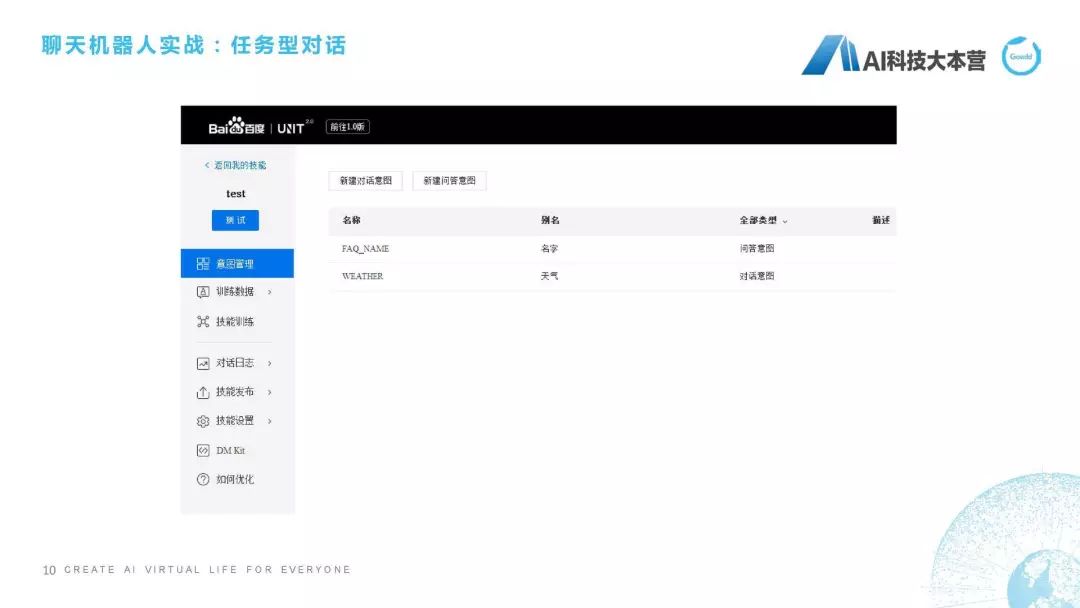
接下來,我們再講稍微難一點(diǎn)的一個平臺。這個平臺叫做百度的UNIT,百度的UNIT現(xiàn)在做得很好,我們?nèi)タ匆幌逻@個百度UNIT怎么用的,網(wǎng)址是unit.baidu.com,這個很漂亮,鼠標(biāo)移動過去有一些很炫的效果。進(jìn)入UNIT之后,還是為了節(jié)省時間,我不直接去新建一個機(jī)器人了,我直接在我今天下午建好的機(jī)器人上進(jìn)行一個測試,我建了一個叫“測試”的機(jī)器人,它同樣跟ruyi一樣可以添加一些技能,比如我可以添加打電話、電影、天氣、機(jī)票、閑聊等等這樣一些技能,而且它還有一個比較好的功能是什么?我可以自定義去配一些技能,比如在我的技能里可以配一個叫test的功能,我在這個test里設(shè)置了一個“天氣”,就是問天氣的意圖、對話。
怎么去做這個事呢?講這個平臺時,我為什么說它比剛才的那個ruyi稍微難了一點(diǎn)?它這里面需要牽扯到我們對槽位的理解。我們先不解釋什么叫槽位,我們先看一下我設(shè)定這個意圖是怎么設(shè)定的。我設(shè)定這個意圖叫“weather”,它的別名是“天氣”。它怎么做呢?我設(shè)計(jì)一個詞槽叫“city(城市)”,也就是說當(dāng)我在問機(jī)器人一個問題時,我必須把“城市”這個詞槽的信息告訴機(jī)器人,如果我沒有告訴機(jī)器人的話,它就會自動的反問說“你在哪個城市?”這個時候我們?nèi)绻ミ@樣設(shè)置的話,在我說到比如“今天上海天氣如何”時,它就可以說“現(xiàn)在播報上海的天氣情況”,它會在會話過程中檢查我是不是已經(jīng)有了“ctiy”這樣一個槽位。這就是我們講了非常簡單的兩個平臺。
剛才我提到為了用UNIT需要去了解這個槽位是什么意思。槽位是什么意思?我再跟大家詳細(xì)解釋一下。我們看一下這樣一個對話,比如說我現(xiàn)在在辦公室,跟大家講這個話題,我很困,我跟這個聊天機(jī)器人說“能不能幫我訂一杯星巴克的咖啡送到辦公室”,聊天機(jī)器人可能回復(fù)說“好的,點(diǎn)你最愛喝的大杯美式可以嗎?”它其實(shí)就是個任務(wù)型對話,任務(wù)型對話就是為了滿足特定的任務(wù)指標(biāo),比如訂票、訂咖啡、訂餐。在任務(wù)型對話里,一般會牽扯槽位提取和填充,槽位就是在這個任務(wù)里所需要的這些關(guān)鍵信息。
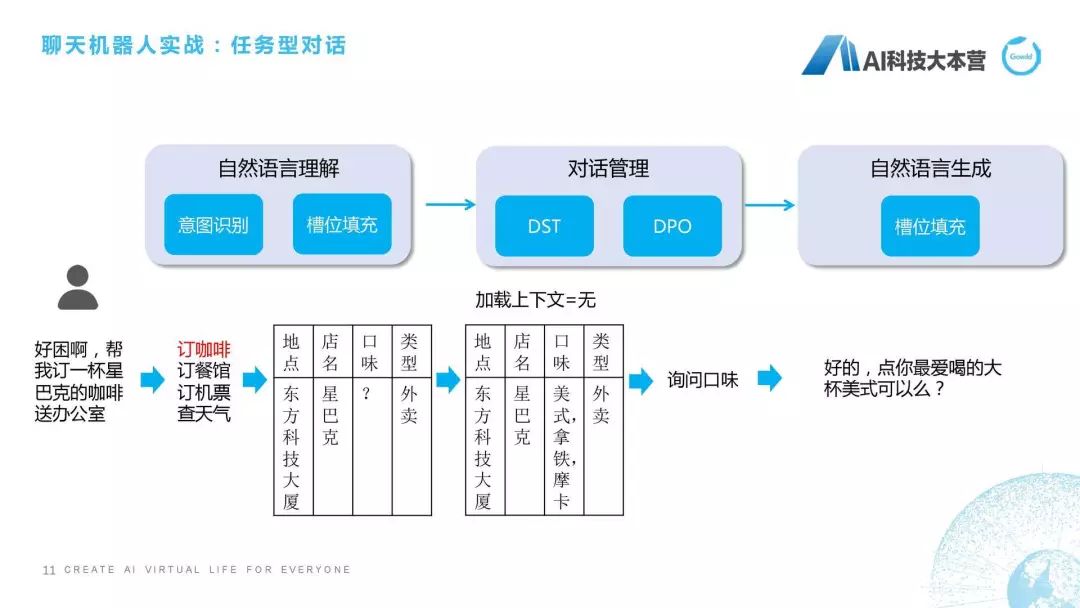
我們看一下它的處理流程,當(dāng)這句話進(jìn)來之后我們首先會在NLU自然語言理解部分做個意圖識別,可以用規(guī)則的方法去做,可以用分類器的方法去做,也可以用現(xiàn)有的深度學(xué)習(xí)方法去做,這都沒有問題的。如果我們判斷這句話的意圖是訂咖啡,接下來要做的什么事情?接下來要做的就是把咖啡需要的這些槽位,如地點(diǎn)、店名、口味、類型填進(jìn)去,這個方法里面又牽扯到很多自然語言處理的技術(shù),這里就不是我們這次課的重點(diǎn)關(guān)注內(nèi)容,我們只關(guān)注我可以在這個句子里去抽取到這些信息。比如說地點(diǎn),它是東方科技大廈,是根據(jù)我GPS定位,定位到我是東方科技大廈,店名是星巴克,類型是外賣。因?yàn)槲艺f的是“幫我訂一杯送到辦公室”,并沒有說口味,機(jī)器人在這一步時并不知道我想要什么口味的咖啡,這時就有問題了,不知道什么口味怎么幫你點(diǎn)呢?這個對話現(xiàn)在進(jìn)入到我們所說的“對話管理”模塊,對話管理分為兩部分,第一部分叫DST,第二部分叫DPO(以前我們叫DPL)。DST的意思就是“對話狀態(tài)跟蹤”,DPO的意思是“對話策略優(yōu)化”。DST所做的事情就是跟蹤它的狀態(tài),并且看一下有沒有上下文,可能他在上文里直接說“我想喝美式”,這就不需要再去猜測用戶口味了,如果我們發(fā)現(xiàn)這個上下文是沒有的話,我就需要去猜測他的口味到底是什么,這里我直接寫了,它可能根據(jù)用戶之前點(diǎn)的咖啡的偏好,我直接排了個序,美式第一,拿鐵第二,摩卡第三。這時它就需要做一個決策了,這時是要反問用戶喝什么口味呢?還是直接給用戶回復(fù)一句話,幫他點(diǎn)一個默認(rèn)的咖啡呢?這里就需要跟產(chǎn)品的設(shè)定來進(jìn)行回復(fù)。
我們不希望聊天機(jī)器人在功能型對話中有太多的多輪交互,我們希望一句話就能夠理會我什么意思。就跟皇帝和太監(jiān)一樣,皇帝一個眼神,這個太監(jiān)就知道馬上要做什么事情,這個是最棒的。但是聊天機(jī)器人沒有那么聰明,我們盡可能的讓產(chǎn)品設(shè)計(jì)得比較聰明。那怎么設(shè)計(jì)?比如這句話就是設(shè)計(jì)場景,我們知道用戶最喜歡喝美式,這句話可能就說“那我點(diǎn)你最愛喝的大杯美式可以嗎?”這一方面詢問了用戶的口味,另一方面又節(jié)省了對話輪數(shù),這是任務(wù)型對話的處理流程。當(dāng)然,最后自然語言生成時也需要用槽位把這句話生成出來,這是我們所說的任務(wù)型對話的基本概念。理解這個東西,就理解了我們在UNIT進(jìn)行天氣槽位的填充。
聊天機(jī)器人三種不同形態(tài)的實(shí)現(xiàn)
接下來我們開始介紹聊天機(jī)器人三種不同的形態(tài)是怎么去實(shí)現(xiàn)的。檢索式機(jī)器人最簡單的做法是什么?比如用戶對這個產(chǎn)品說“你穿的衣服好漂亮”。機(jī)器人會回復(fù)“謝謝你的贊美”,它一般是怎么做的?當(dāng)你說“你穿的衣服好漂亮”的時候,它會在一個很大的語料庫里去搜索,搜索這里面哪一句話跟我現(xiàn)在問的問句是最接近的,然后把最近這句話的回復(fù)直接回復(fù)給用戶,這個看起來是不是很簡單?所以其實(shí)如果你掌握了檢索式方法的話,就完全可以做一個非常棒的機(jī)器人。只要你寫足夠多的語料,用更好的相似度算法,這個聊天機(jī)器人就會表現(xiàn)得非常好。但這個情況只出現(xiàn)在單輪的過程中,如果在多輪的情況下,檢索式的方法肯定就掛掉了。這里最關(guān)鍵的是什么東西?最關(guān)鍵的是匹配。
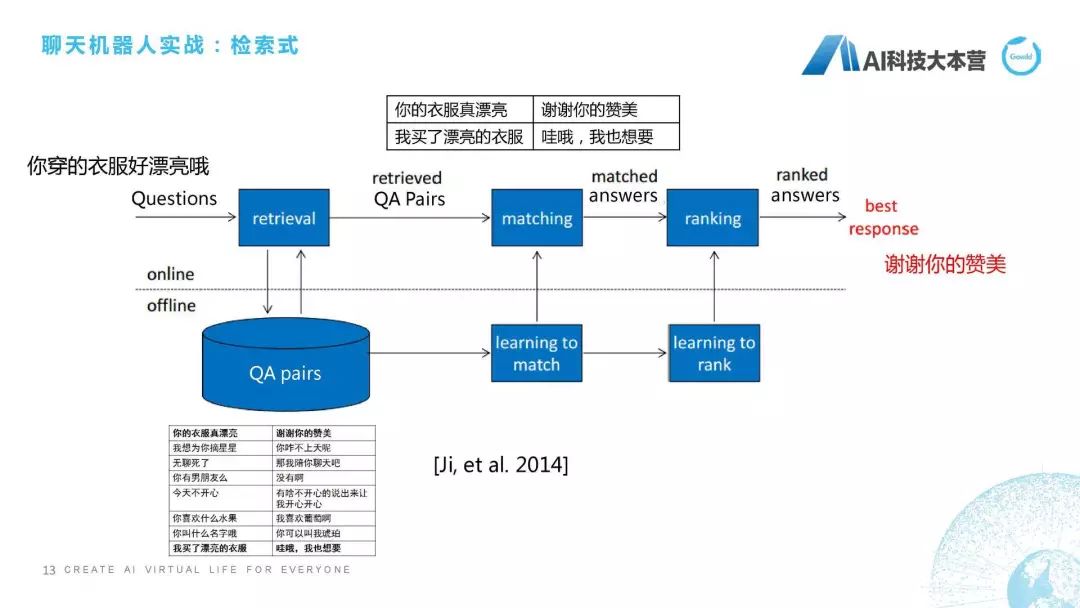
我們再看一下它基本的技術(shù)流程是怎么走的,比如我說剛才那句話“你穿得衣服好漂亮”。它是作為一個問句,我們就需要做一個retrieval,這個retrieval是搜索,我們從大量文件語料對里去搜索跟我這句話最接近的一些句子,并且把這個候選集給篩選出來,有了候選集之后,我們就會做一個排序,這兩句話到底哪句話跟我這句話的相似度最高,然后我再把它這句話的回復(fù)來回復(fù)給用戶,這是它基本的檢索式的流程,這用2014年一篇論文中提到的經(jīng)典模型,我就直接拿來用了。
(1) 基于文本相似度
接下來開始介紹基于文本相似度、基于語義相似度以及基于深度學(xué)習(xí)的檢索式方法,也就是說對于檢索式方法,我們現(xiàn)在這里說3種比較基本的技術(shù)。

第一種,基于文本相似度的方法。什么叫文本相似度?舉個例子“你穿的衣服好漂亮哦”,“你的衣服真漂亮”這兩句話,大家直面上感覺非常相似,它怎么相似?因?yàn)樗淖帧⑺脑~有很多重合,這就是文本相似度的直觀感受。我們知道文本相似度算法有很經(jīng)典的比如邊際距離、TF-IDF、BM25,這種都是非常經(jīng)典的算法,我這里對算法部分就不做更多深入的描述了,大家如果感興趣的話,推薦大家去聽一個課程CS 224N,這個課程是斯坦佛大學(xué)Christopher Manning教授零幾年上的一門課,應(yīng)該就是叫NLP(自然語言處理)這門課,它對經(jīng)典的自然語言處理算法都做了非常好的解釋。
那么我們一般的做法是,這種相似度算法一般是用到字符串匹配,我們知道字符串匹配的速度一般非常慢,但是我們可以借助相似度的檢索引擎提升它的搜索效率。這里有兩個,一個叫ElasticSearch(ES),另一個叫HNSW,如果感興趣的話,大家可以在后面課程的PDF、PPT里去看一下這兩個項(xiàng)目。

接下來實(shí)戰(zhàn)里是用這個基于ES相似度檢索引擎,給大家實(shí)現(xiàn)一個檢索式的聊天機(jī)器人,我這里列的基本是核心的代碼,就不在這里給大家演示了,PPT可能看得更清楚一點(diǎn)。ES怎么去用?這個很簡單,我們直接去Import這個ElasticSearch,首先要配置一下ES的信息,信息包括什么?它的主機(jī)IP,比如說我這里是172.27.1.203,端口號是9201,然后數(shù)據(jù)庫名稱是什么?我們把它起了一個叫similarity_chat,它的表名稱叫什么?比如我們起個名字叫“qa_corpus”。
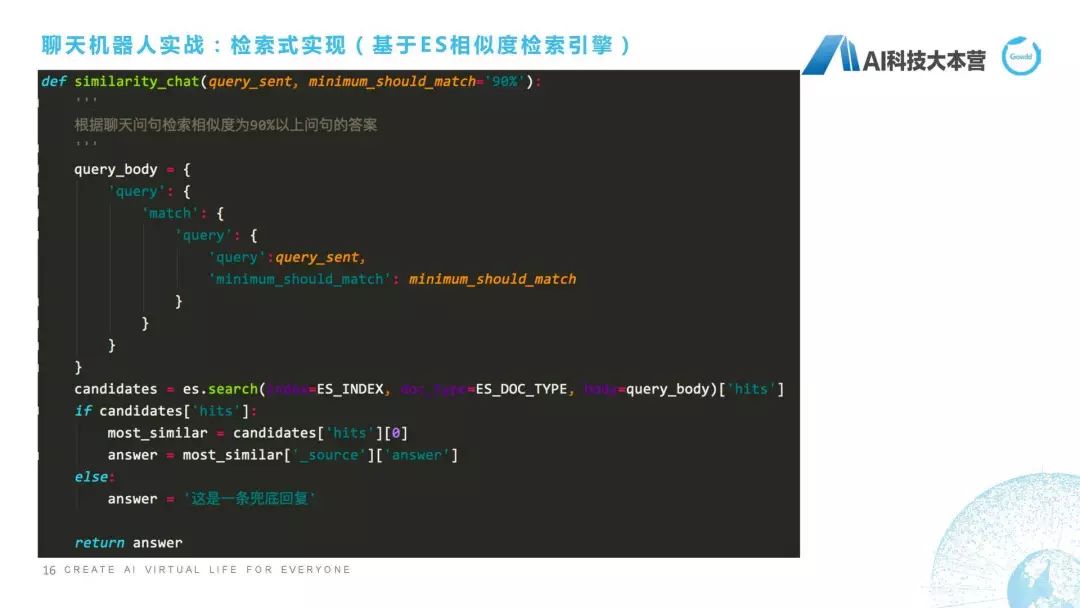
接下來就是正常的流程了,比如我們首先要初始化一個對象,小寫的es這個對象,這個對象里所有信息是來源于我們剛才配置的es信息,這里面是端口號和IP。接下來我們想往這個es里去添數(shù)據(jù),因?yàn)槲覀兿氚堰@樣一批數(shù)據(jù)添加到es里去,13頁里這些數(shù)據(jù),怎么去添呢?這里我們define一個方法,這個方法叫insert_one_data,就是我們插入一條問答語料,怎么去插入?一個問答語料包括兩部分,一個叫Query,一個叫Answer,就是一個Q,一個A,然后我們會調(diào)用一個es的index方法,這個index方法其實(shí)是直接封裝好的插入語料的方法。它是怎么去做?如果這個數(shù)據(jù)庫不存在的話,它會直接生成一個新的叫這個名稱的數(shù)據(jù)庫,并且建立一個表叫“qa_corpus”。然后對于每一條數(shù)據(jù),除了Query和Answer,這是兩列數(shù)據(jù),一個Query,一個Answer,還自動生成一個id,相當(dāng)于我們最后生成的數(shù)據(jù)是三列數(shù)據(jù),第一列是Query,第二列是Answer,第三列是id,這是我們預(yù)先存了這樣一些句子。
接下來要做什么事?接下來要做檢索,我們來了一個問句之后,定義了一個方法叫“similarity_chat”,我們對這個問句進(jìn)行檢索,跟我剛才數(shù)據(jù)庫里哪一句話最接近,然后我們?nèi)藶樵O(shè)置了一個90%的閾值。相似度為90%以上的答案返回作為最好的候選答案。Body的格式就是query還有這個minimum_should_match,就是它90%的值。然后我們用es這個search的方法去找到它的候選集,找到候選集之后去比較這個閾值,如果所有的閾值都低于我們設(shè)計(jì)的90%的話,它就直接返回一個兜底回復(fù),比如else,answer這是一條兜底回復(fù),然后return answer,這是我們的整個實(shí)現(xiàn)方法。
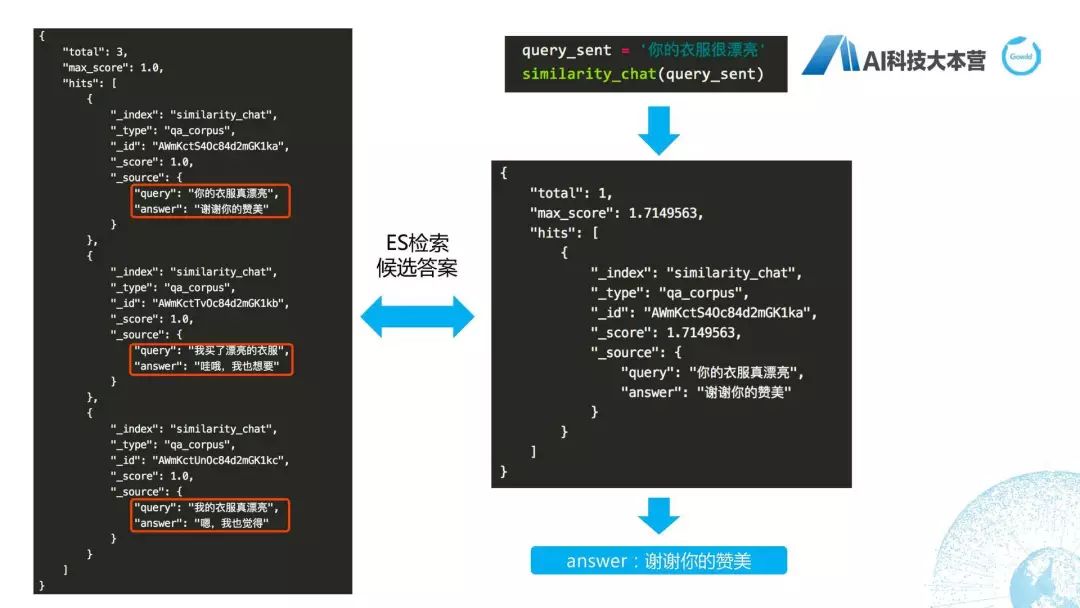
具體流程在上面看一下,首先,左邊這個圖是我們插入的三條語料,插入三條語料的Query和Answer分別是“你的衣服真漂亮”、“謝謝你的贊美”,然后還有這兩句。我們現(xiàn)在有一個query_sent是“你的衣服很漂亮”,我們調(diào)用剛才我們已經(jīng)設(shè)定好的“similarity_chat”這個方法把這個query_sent灌進(jìn)去,然后檢索出最好的句子是第一個。也就是說我們其實(shí)在這里直接利用了ES默認(rèn)的相似度的分值的計(jì)算方法,這個計(jì)算方法在這里其實(shí)可以跟大家說一下,大家可以在里面去改自己的計(jì)算方法,因?yàn)槲覀冎榔ヅ涠鹊姆种凳强梢宰约喝プ龊芏嗟膬?yōu)化的。所以,這里面大家可以根據(jù)自己的實(shí)際情況去調(diào)整分值的計(jì)算方法,然后做一個比較個性化的自己的檢索引擎,最后得到這個答案是“謝謝你的贊美”,整體的用ES作為檢索式的方法就簡單跟大家介紹到這里。

簡單總結(jié)一下,基于ES相似度檢索引擎的優(yōu)勢在于什么呢?文本相似度它本身是具有一定泛化支持的,比如你加一個語氣詞“啊”或者“哦”,或者加一個逗號、加一個標(biāo)點(diǎn),它都可以在相似度檢索方面起到比較好的泛化效果。當(dāng)然,這個泛化它本身又是一個比較重要的一個可以單獨(dú)拎出來講的模塊。比如我們現(xiàn)在常用的方法叫機(jī)器翻譯,我們可以用機(jī)器翻譯的方法對大量語句進(jìn)行泛化的設(shè)計(jì),使我們的聊天機(jī)器人可以支持更多泛化語句。第二點(diǎn)優(yōu)勢,ES里自帶的BM25算法有很多權(quán)重可以調(diào)整,在短文本的情況下比邊際距離還要合理得很多。
劣勢也很明顯,我舉兩個例子,大家就很明白了,比如說“你好漂亮”、“我覺得你很好看”,大家看看這個文本相似度,它里面哪幾個字是一樣的?“你”是一樣的“好”是一樣的,其他字都不一樣,語義相似但是文本字符不是很相似的情況下,這個文本相似度算法可能就沒有那么好,但它語義是非常相似的。第二種情況是否定詞怎么辦?比如“我喜歡你”和“我不喜歡你”它的意思是完全相反的,但是在文本相似度檢索時,如果我們沒有對否定字進(jìn)行限制,它這兩個得分是非常高的,“我喜歡你”和“我不喜歡你”的得分是非常高的,這個情況就非常難以應(yīng)對。我們一般的處理方法是什么?第一種方法是規(guī)則,比如說我可以設(shè)定一些否定詞的過濾規(guī)則,遇見“不”的情況下跟原有句子是相反的意思,或者怎么樣利用文本語義相似度的方法來去進(jìn)行相似度的檢索,我們接下來跟大家講第二塊,就是基于語義相似度怎么去做。
(2) 基于語義相似度

第二種,基于語義相似度。語義相似度一般來說是三步走,我這里列的三條是三步走策略,第一步,先要把一個句子中單詞變成向量化的表示,向量化表示的方法實(shí)在太多了,而且有很多人講過專項(xiàng)的talk,這里我就不講嵌入式怎么做的了,如果感興趣的話可以讀一下Word2vec這種原始論文,或者看一下我們現(xiàn)在這種ELMo、Transformer、Bert這些語言模型的動態(tài)詞向量是怎么做的。詞向量這塊我就不去解釋了。詞向量的輸出就是把一個單詞變成一個向量,比如變成一個200維或者300維的向量,這是單詞的向量表示。
第二步是做句子的向量表示,比如剛才我舉的例子“我喜歡你”它是三個詞,我、喜歡、你,我們把這三個詞的向量拿過來之后怎么把句子的向量做出來,這就需要有一些方法,比如加和平均,比如向量極值,比如最近用得比較多的FastText、Skip-Thought、Quick-Thoughts,這都是非常好用的一些方法,大家可以具體的情況去把句子的向量表示出來。其實(shí)可以用一些預(yù)訓(xùn)練的向量,比如騰訊應(yīng)該有一個預(yù)訓(xùn)練好的大規(guī)模語料上的向量,大家可以拿來用。
第三步是計(jì)算向量距離,我們有了兩個句子的向量之后,下一步就要去計(jì)算它的相似度,也就是它的向量距離。一般的做法可能采用歐氏距離或者余弦相似度,也就是說我們得到一個分值。或者基于深度學(xué)習(xí)的一些方法,也是延續(xù)著剛才我們PPT里講計(jì)算文本相似度的語義相似度的方法。在匹配算法方面,我這邊只列了一些最早提出來的或者最經(jīng)典的算法,如果大家感興趣的話,這后面還有非常多論文可以去讀,包括最近也新出很多這方面的論文。
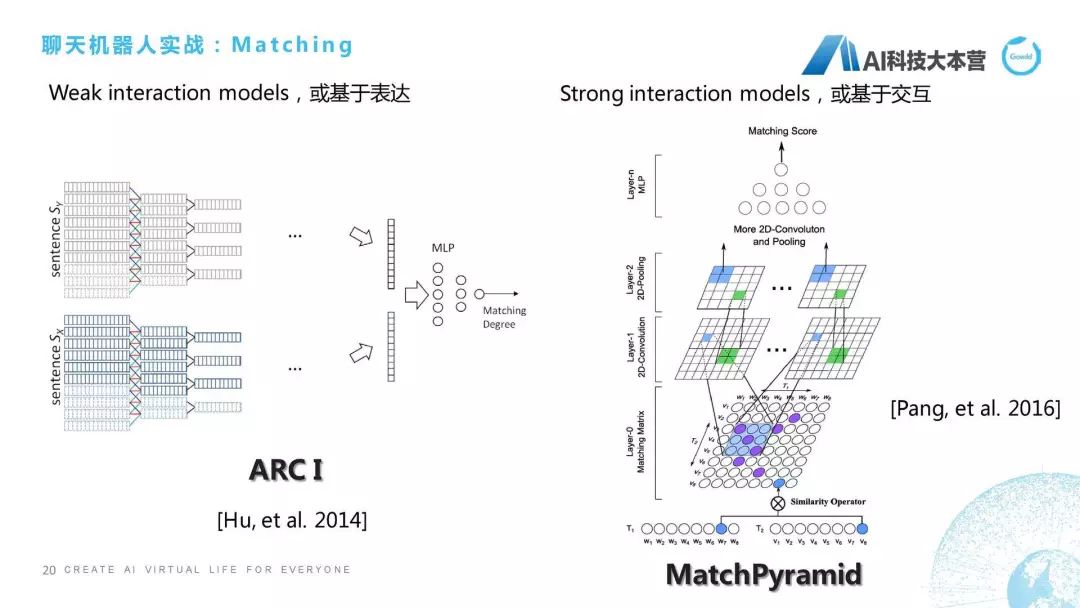
我們從最早的講,2014年華為的諾亞方舟實(shí)驗(yàn)室這篇論文中提出兩種算法,一種算法是基于表達(dá)的,一種算法是基于交互的。兩者最大的區(qū)別在于對于句子算相似度的時候,基于表達(dá)的算法是對這兩個句子分別進(jìn)行卷積、池化,進(jìn)行向量化之后通過多層感知機(jī)得到它的匹配度。像MatchPyramid這種算法就是基于交互的,這種算法一開始就把兩個句子給揉起來了。我們相當(dāng)于一種是分開去算,兩個兄弟先分開,然后最后再分家產(chǎn);還有這種兩個兄弟先揉在一起了,揉成一個矩陣,這里面有一些相似度的Operator,大家看原始論文時,Operator是有兩種,一個是點(diǎn)乘,一個是最大化。我們把這個句子里面的比如這8個詞,每一個詞都進(jìn)行一個相似度的操作,就變成了8×8的矩陣,然后在此之上我們做卷積、池化這樣的操作,通過最后的多層感知器得到它最后的分值。所以基本上只有這兩個方向,一個叫基于表達(dá)的Matching方法,一個叫基于交互的Matching方法。大家感興趣的話可以深入的去看一下論文。
(3) 基于深度學(xué)習(xí)
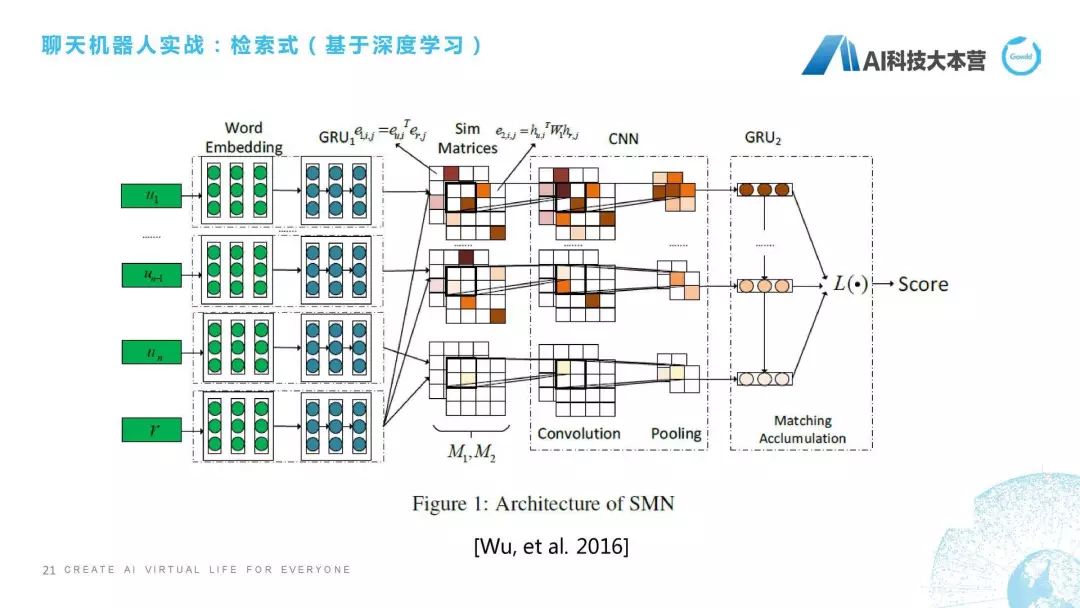
第三種,檢索式還有一種是基于深度學(xué)習(xí)的檢索式方法。這個我選了一篇比較經(jīng)典的論文,跟大家簡單講一下它的思想。微軟小冰團(tuán)隊(duì)在2016年提出一個方法,它不僅考慮詞級別的,還考慮句子級別的相似度。什么意思呢?簡單解釋一下,我們這里有4個句子:u(1)、u(n-1)、u(n)、r,中間還有很多句子,我們假定它是4個句子,它現(xiàn)在想算u跟r相似度,怎么算呢?它會把每個詞做個嵌入,也就是做向量化,然后把這個詞跟r的這個詞直接做點(diǎn)乘,也就是得到M2這個矩陣,得到這個矩陣之后通過對句子做GRU,它最后得到的隱狀態(tài)我們做一下余弦相似度計(jì)算,得到的是M1這個矩陣,所以M1和M2這兩個矩陣分別代表詞和句層面的相似度,再往后就是通過CNN,還有一個GRU,最后得到一個Score。這個就是我們有一些基于深度學(xué)習(xí)的檢索式方法,我也不深入進(jìn)行介紹了。剛才已經(jīng)跟大家講完了基于文本相似度的、基于語義相似度的、基于深度學(xué)習(xí)的檢索式方法。
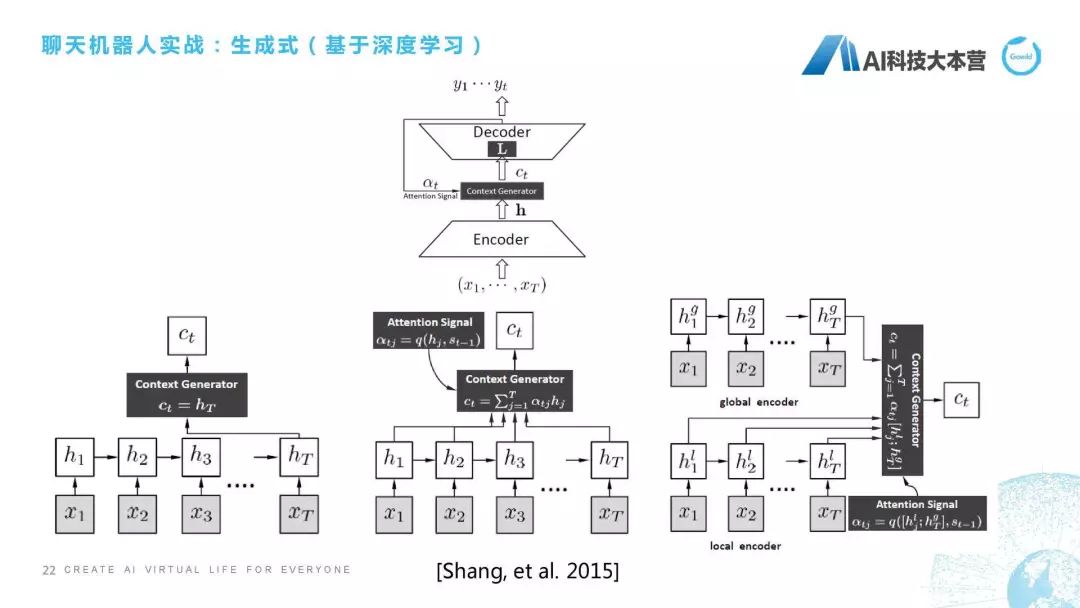
(4) 基于生成式的深度學(xué)習(xí)方法
第四種,跟大家聊一下基于生成式的深度學(xué)習(xí)方法。這是最早一篇論文,應(yīng)該也是華為做的一篇論文,他們當(dāng)時做的是怎樣通過一句話直接生成它最后的這個回復(fù),就是通過x(1)到x(t),直接生成y(1)到y(tǒng)(t),他們提出三種不同的方法。有一個是直接從這個隱狀態(tài)得到它的context,還有一種方法是里面加了attention,采用加權(quán)的方式利用這個attention來得到最后的句子,還有一個是有一個contextAttention,還有一個詞層面的Attention,它們稱之為是local和global這兩個Attention生成的回復(fù)。在這后面也出現(xiàn)了很多生成式的方法,因?yàn)檫@個talk是基于實(shí)戰(zhàn)的,所以我們對理論方面不做過多的深入解釋。
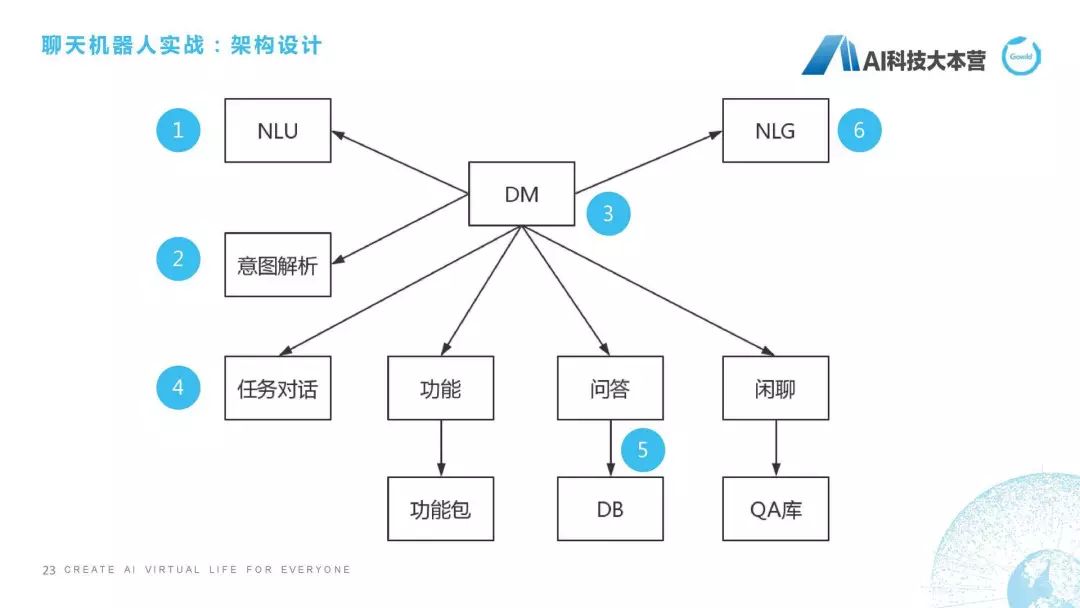
架構(gòu)設(shè)計(jì)
最后來到最復(fù)雜的一塊了,如果我們想從0到1利用自己的Python代碼去創(chuàng)造一個聊天機(jī)器人,應(yīng)該怎么去做?第一步,要先把架構(gòu)給設(shè)計(jì)出來。這個聊天機(jī)器人的架構(gòu)應(yīng)該分幾個部分,我們肯定是要用Python去寫一個DM(對話管理)這個模塊,然后這個模塊會接收自然語言理解(NLU)的一些信息,同時,它會對句子進(jìn)行一個意圖解析,同時它會根據(jù)意圖解析的結(jié)果選擇一項(xiàng)功能,比如它是任務(wù)對話,還是功能對話,還是問答,還是閑聊,它有不同的處理方式,最后回復(fù)的時候我們還有一個NLG的模塊,這就是整個聊天機(jī)器人簡單的一個架構(gòu)。

接下來這個序號是我要跟大家把這幾個模塊全過一遍:第一個,NLU,第二個,意圖解析,第三,DM,第四,任務(wù)對話,第五,問答,第六,NLG。為什么不講功能和閑聊?功能假定可以直接使用ruyi、UNIT的技能包,我們這里面就不做開發(fā)了。我剛才也講過了閑聊,我們直接用檢索式的方法做閑聊,我們用很多語料庫直接做檢索式的閑聊就結(jié)束了。這是我們說的架構(gòu)設(shè)計(jì)。
NLU
第一點(diǎn),NLU怎么做。讓大家失望了,NLU里沒有代碼,為什么沒有代碼?因?yàn)楹芏嚅_源的項(xiàng)目在做NLU的事情,NLU其實(shí)非常多的模塊,至少我們現(xiàn)在用的模塊就有十幾、二十個,這里包括什么?分詞、詞性標(biāo)注、依存、情感分析、實(shí)體鏈接、實(shí)體發(fā)現(xiàn)、語義消歧、主體識別、句子有效性判斷等等,這個并不是一節(jié)課能講完的。但我建議大家,如果你真的想以簡單的方式去實(shí)現(xiàn)一個聊天機(jī)器人的話,我們?yōu)槭裁从泻玫臇|西不用呢?Jieba分詞是很好的一個開源項(xiàng)目,中科院還有一個NLPIR,哈工大有一個LTP,斯坦佛有CoreNLP,我們還有最經(jīng)典的NLTK的包,還有HanLP、AllenNLP。在NLU這塊如果自己做的話實(shí)在是非常煩,比如分詞、依存自己做的話,這個時間就花費(fèi)得太多了,最好的辦法是我用別人的東西,我去加一些自己的個性化,這就是我NLU所要跟大家講的內(nèi)容。
意圖分類
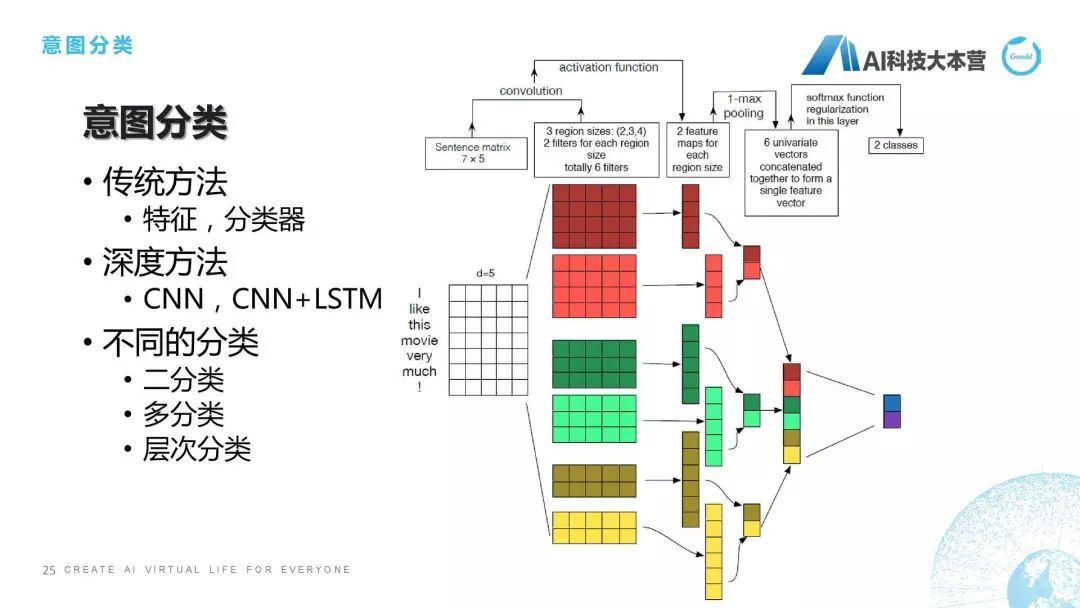
第二點(diǎn),意圖分類。想跟大家聊一下意圖分類最容易實(shí)現(xiàn)的方法,整個方法的分類其實(shí)是有幾種的,比如:傳統(tǒng)方法,傳統(tǒng)方法里面我們可以用特征,用一些分類器,然后直接對這個意圖,比如我們用決策樹或者SVM直接對句子進(jìn)行分類。當(dāng)然還可以用深度方法,比如CNN或者CNN+LSTM來進(jìn)行分類。右邊這個圖給的就是這樣一個深度分類的方法,它是對一個句子進(jìn)行了一個embedding之后,I是一個單詞,它是一個5維的向量,這是一個舉例,然后它每個詞都有一個向量,這個矩陣拿過來之后,我們就會有一些卷積、池化的操作,最后得到的是二分類的一個結(jié)果,這也是利用深度學(xué)習(xí)的方法去做的。但是我們在工程中還需要考慮什么呢?還需要考慮我們到底是二分類、多分類,還是層次分類。二分類很簡單,1和0。多分類也很簡單,比如情感里面有“正中負(fù)”。層次分類就比較復(fù)雜了,比如我們的產(chǎn)品里共有五層分類,300多種意圖,所以我在做的時候,用什么方法才能保證它有比較高的RECALL。這就是我們在工程中所需要做的問題,其實(shí)是很復(fù)雜的事情。
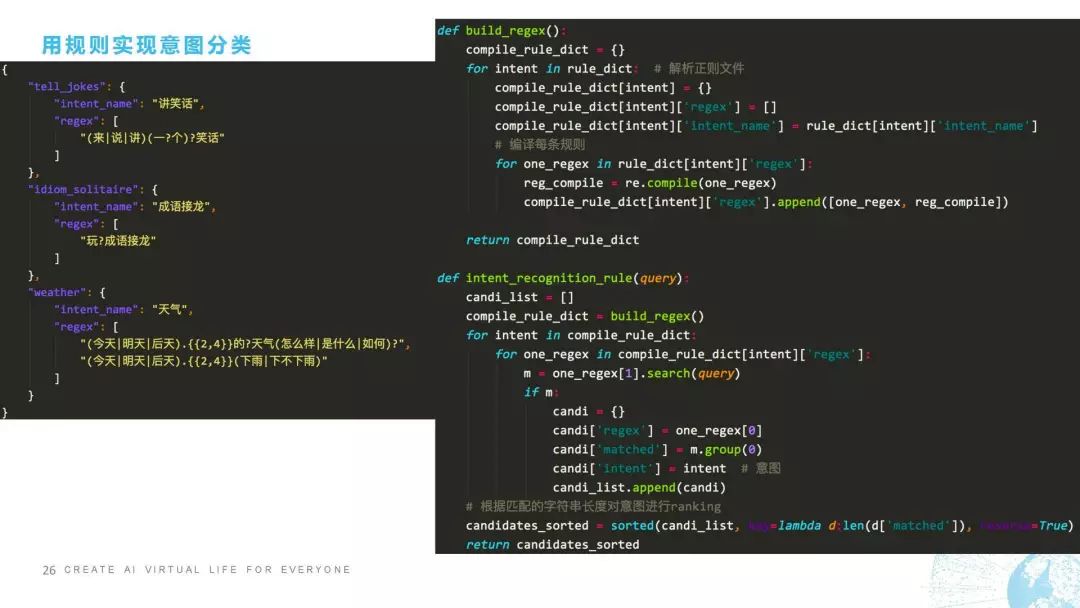
接下來我跟大家聊怎樣用規(guī)則方法實(shí)現(xiàn)意圖分類,用規(guī)則方法實(shí)現(xiàn)意圖分類是非常準(zhǔn)確的,但是它缺點(diǎn)在于我們要對每一個句子都進(jìn)行規(guī)則的覆蓋,而且當(dāng)規(guī)則實(shí)在是太多的時候模型就會變得非常難維護(hù),這是它的缺點(diǎn)。我們來看一下規(guī)則怎么去做,比如我這里舉了一個事例是三種不同的意圖,一個是“講笑話”,一個叫“成語接龍”,還有一個叫“天氣”。它所對應(yīng)的規(guī)則是這樣寫的,比如“來一個笑話”這可以覆蓋,“說一個笑話”可以覆蓋,“講笑話”也可以覆蓋,“說笑話”也可以覆蓋,這是一個規(guī)則,剩下的是同理。
怎么去做呢?我們看一下,右邊有兩個函數(shù),第一個函數(shù)叫build,第二個函數(shù)叫intent_recognition。這個函數(shù)的作用是正則編譯,正則編譯大家應(yīng)該也很清楚,我們對正則表達(dá)式進(jìn)行預(yù)編譯的話,可以有效加快正則的匹配速度,這個是編譯,我就不講了。第二個是在意圖分類的上面,如果有query進(jìn)來之后,candidate_list一開始是空的,然后我們把正則編譯之后,從正則里面去選擇正則對這個句子進(jìn)行匹配,匹配之后我們會對匹配到的字符串的長度對意圖進(jìn)行ranking。也就是說它可能匹配到不同的意圖,這個時候我們就需要根據(jù)它匹配的字符串的長度來對意圖進(jìn)行排序,最后把所有的candidate進(jìn)行排序之后輸出,這是我們在用規(guī)則實(shí)現(xiàn)意圖分類時的一段代碼。
神藥:fastText
如果大家不想那么麻煩,還有一種包治百病的神藥叫fastText,是在2018年廣泛地被工程界所采用的一種分類方法。當(dāng)然,現(xiàn)在這個方法被Bert和ELMo、Transformer這種更先進(jìn)的算法所替代,也不是超越吧,大家還是一起做,有時做一些Stacking方法時去用,我們也會用到Bert或者新的GPT這種算法。但是fastText本身對意圖分類的效果是非常明顯的,而且它由于是基于字符子串的,所以它的性能也非常高,它不僅速度快,性能也非常高,所以在2018年我們笑稱fastText是“包治百病的神藥”,這個神藥對工程界的分類起到非常大的促進(jìn)作用。

我們看一下fastText怎么用,很簡單!它的代碼是非常簡單的,我們只需要準(zhǔn)備帶有分類標(biāo)簽的數(shù)據(jù)集就行了。分類數(shù)據(jù)集這里是已經(jīng)分好詞的,比如這句話的label是weather,這句話的label是music,這句話的label是news,我們準(zhǔn)備了幾萬條的數(shù)據(jù)集,把它分為測試集、驗(yàn)證集、訓(xùn)練集,之后我們就import fasttext,然后定義一個訓(xùn)練函數(shù),定義一個預(yù)測函數(shù),訓(xùn)練函數(shù)的話比如直接用train_supervised就行了,然后我們還可以算它的precision,recall還有F1,這是訓(xùn)練。用的時候怎么用?我們把model提出來,然后去predict這個sentence的label,然后return這個label就結(jié)束了。fasText是非常好用的一個算法。
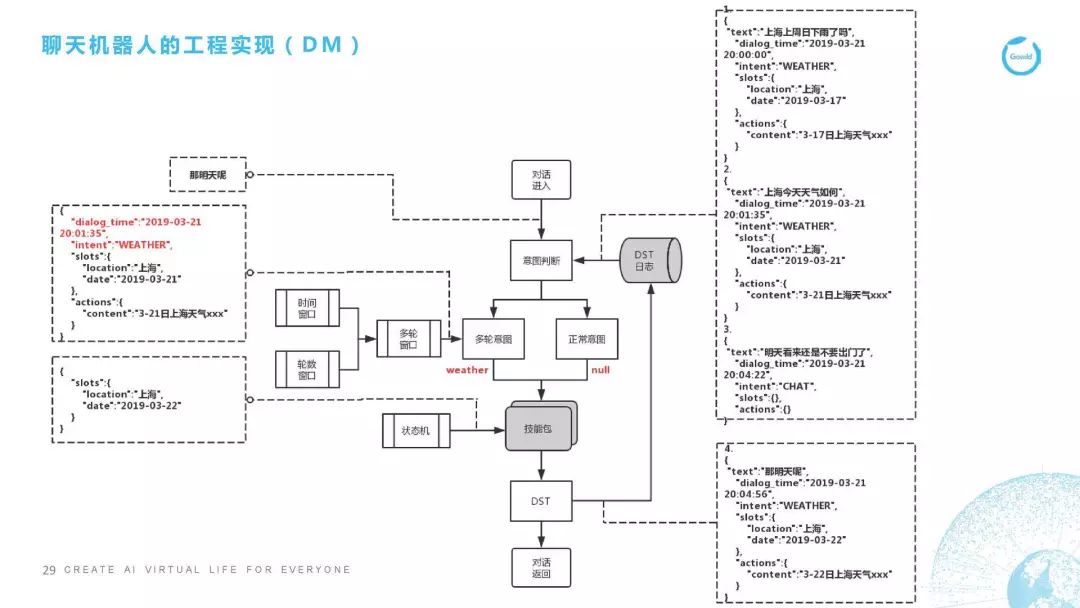
DM(對話管理)
第三點(diǎn),下面這個部分開始講DM。DM的代碼在這里沒有貼,因?yàn)檫@個實(shí)在是太復(fù)雜了。我跟大家講一下整個框架是怎么實(shí)現(xiàn)的,DM是對對話進(jìn)行控制,很多情況下是對多輪對話進(jìn)行控制。我這里舉了個典型的多輪對話,這里舉的例子是天氣,我這里列了1、2、3,是用戶在前三輪所說的一些話,比如說用戶第一句說“上海上周日下雨了嗎?”它的對話時間是3月21號的8點(diǎn),它的意圖是天氣,地點(diǎn)是上海,時間是2019年3月17號,因?yàn)樗巧现苋障掠炅嗣础N覀兂槿∵@些信息之后,就會給它回復(fù)一個3月17號的上海天氣是什么樣子,它下雨了沒有。這是用戶問的第一句話,以下是同理的。
用戶第二句話問的是“上海今天的天氣如何”,所以它最后的回復(fù)是3月21號的上海天氣。第三句話用戶說了一個不相干的,用戶覺得好像今天天氣很差,怎么辦呢,他說了一句“明天就不要出門了吧”,這個時候我們開始說重點(diǎn)的了。重點(diǎn)就是用戶當(dāng)在第四句話時說“那明天呢,怎么辦?”我們看一下它的處理流程,“那明天呢”這句話進(jìn)入了意圖分析之后,我們發(fā)現(xiàn)這句話的正常意圖分值是非常低的,也就是說它不像是個正常的意圖,在意圖判斷時我們已經(jīng)加載了上下文,也就是說它上文的日志,這時我們用分類器模型判斷或者用一些規(guī)則,判斷它可能是屬于某個多輪意圖。這個多輪意圖是屬于哪一個呢?我們就要去找這個窗口,這里面有兩個窗口,一個叫時間窗口,一個叫輪數(shù)窗口,比如輪數(shù)窗口我們這里設(shè)定的是3輪,3輪內(nèi)的內(nèi)容都會抓取,時間窗口是5分鐘,5分鐘內(nèi)的數(shù)據(jù)都會抓取,這些數(shù)據(jù)都抓取之后,我們判斷它確實(shí)是天氣意圖下面的一句話。這句話有了之后我們填充槽位,“那明天呢”我們判斷他是在問天氣,那這個天氣的槽位信息是什么?明天是時間信息,那地點(diǎn)是哪里?地點(diǎn)我們直接沿用上一輪他問這個天氣的地點(diǎn)的槽位信息。所以最后我們的槽位信息其實(shí)是“上海”是地點(diǎn),時間是“3月22號”,就是明天上海的天氣是怎么樣的。這里面用狀態(tài)機(jī),然后去決定我們接下來要做什么樣的操作,這里會經(jīng)過DST的步驟。同時,我們在回復(fù)之后也把這些日志加入到日志的log數(shù)據(jù)庫里去,最后會返回一個對話,這是DM的操作流程。
基于特定任務(wù)的對話實(shí)例
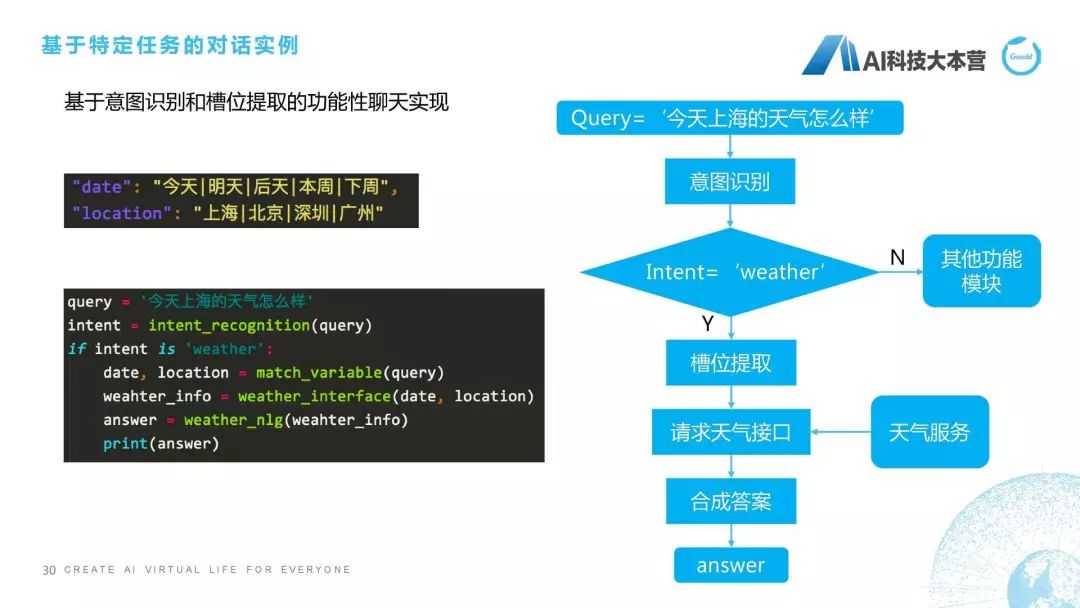
第四點(diǎn),接下來是基于特定任務(wù)的對話實(shí)例,特定任務(wù)代碼非常多,沒辦法貼全,那么就貼一下最基本的這樣一些模塊。比如說我們會對槽位首先進(jìn)行一個限制,比如date是時間的槽位里包括“今天|明天|后天|本周|下周”等等,地點(diǎn)包括“北京|上海|深圳|廣州”這樣一些地點(diǎn),當(dāng)有這樣的問句之后,我們首先會進(jìn)行意圖識別,intent-recogniton,我們會對這個query進(jìn)行意圖識別,如果這個intent是weather的時候,它就先進(jìn)入到一個槽位提取,我們提取的槽位是根據(jù)weather下面的槽位信息去提的,它需要包括時間和地點(diǎn),所以我們有這樣一個函數(shù)去抽它的時間和地點(diǎn)信息。接下來,槽位提取之后我們就要請求天氣接口了,這時比如我們用的是新浪天氣,新浪天氣有個服務(wù),我們就需要用這個date和location去請求新浪天氣的這個服務(wù),返回當(dāng)前的這樣一個天氣的情況,叫weather-info,有了這個weather-info之后我們再用NLG模塊成一個回復(fù),得到這個anwser,這就是基于我們特定任務(wù)對話實(shí)現(xiàn)的簡單流程。
問答模塊
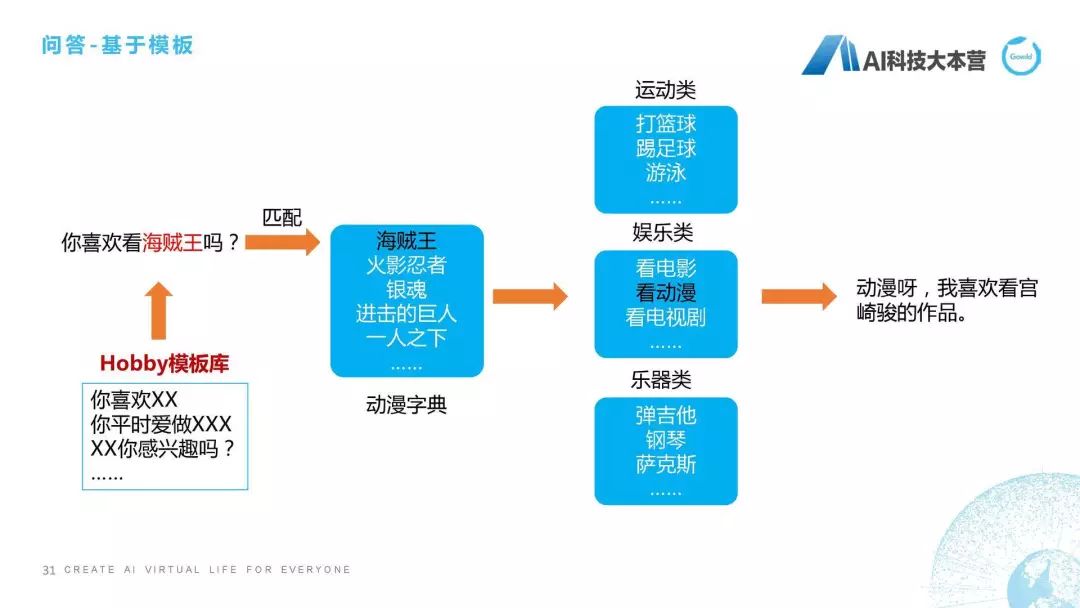
第五點(diǎn),接下來介紹剛才模塊里的問答模塊。簡單跟大家說一下基于模塊的問答方式,還有更多的,比如基于語義解析超出了本次課程的范圍。那基于模板怎么做?比如用戶問了“你喜歡看海賊王嗎?”這句話用模板的處理方式就是先去匹配這個模板庫,它會在模板庫里去匹配這句話跟誰是最相近的。匹配完之后我們會有一個動漫字典,它是屬于海賊王,海賊王屬于娛樂類的動漫的類型,所以最后給一個相應(yīng)的回復(fù)語句。
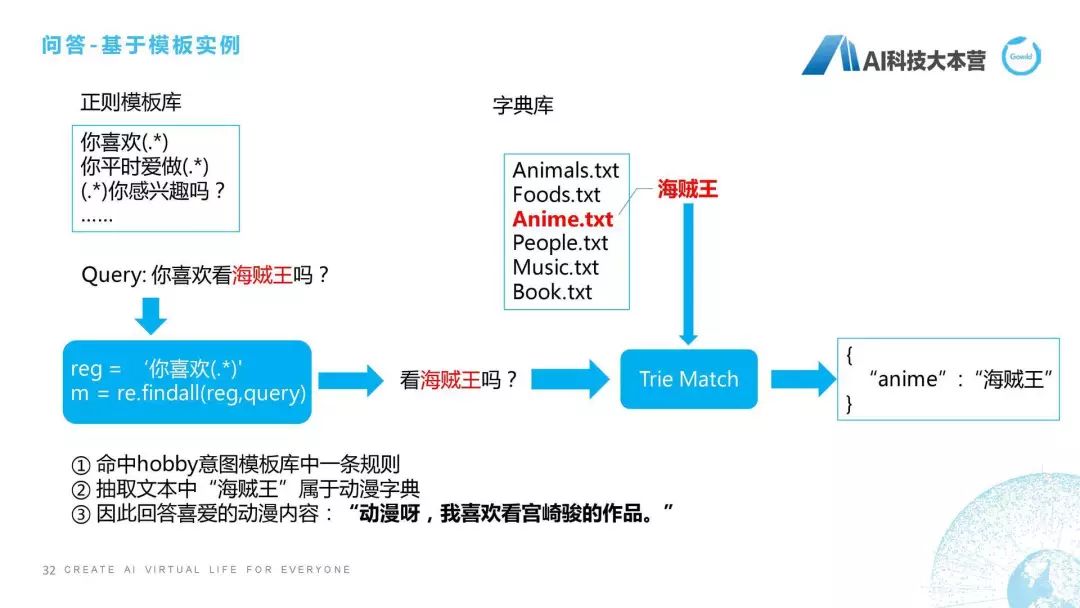
怎么去做?是這樣的流程,它的做法是這樣子的,我們首先維護(hù)了一套正則模板庫,比如“你喜歡(.*)”,這個正則模板庫大概幾千條或者幾百條,當(dāng)有一個問句進(jìn)來時,它會匹配正則模板庫里的所有正則,比如它匹配的正則最后匹配到了“你喜歡”的這樣一個句子,然后把“你喜歡”后面的這一部分都抽取出來,也就是說“看海賊王嗎?”這幾個字符全抽取出來作為候選。候選里面肯定包括一些形容詞、標(biāo)點(diǎn)符號、無意義的詞,怎么去刪掉它們呢?我們采用了一種方法叫TrieMatch的方法,其實(shí)可以用最常匹配的這種方法去進(jìn)行匹配,我們最后匹配到字典里的叫“海賊王”的字典庫,然后我們把“海賊王”關(guān)鍵詞抽取到文本中,“海賊王”屬于動漫字典,然后再給用戶進(jìn)行一個回復(fù),這是這邊的一個簡單說明。
自然語言生成(NLG)實(shí)例
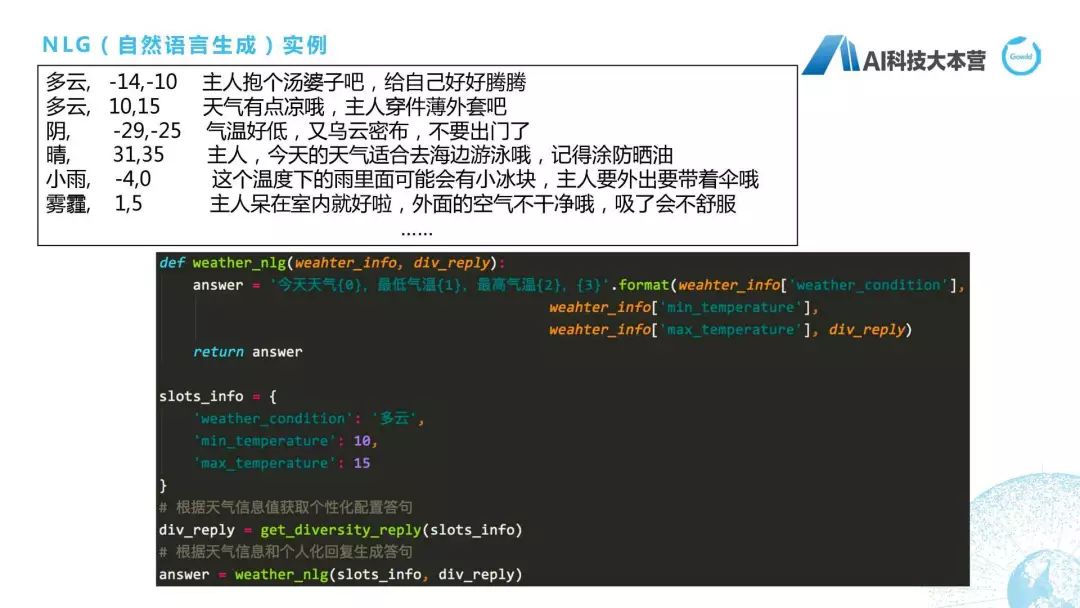
最后,講一下自然語言生成。也就是說我們機(jī)器人在回復(fù)時,不可能讓它只是回復(fù)我們查到的答案。以天氣為例,天氣最后的結(jié)果一般是氣溫,還有天氣的狀況。所以我不可能直接回復(fù)用戶說“多云,10度、15度”,我肯定要回復(fù)非常自然的句子。它的做法是這樣子的:比如我們對于整個NLG在天氣回復(fù)里是這樣設(shè)計(jì)的,它的Answer包括四個部分,第一個部分叫“今天的天氣是什么”,第二個部分叫“最低氣溫是什么”,第三個部分叫“最高氣溫是什么”,第四個部分叫“個性化的回復(fù)語料”。我們可以看到,當(dāng)我們有這樣一個slots_info的時候,我們有“多云,10-15”度時,我們就直接可以把這4個信息拼成一句話,這句話可能是“今天的天氣是多云,最低氣溫是10度,最高氣溫15度,天氣有點(diǎn)涼哦,主人穿件薄外套吧”,這就是自然語言生成,我們利用槽位填充來做的模塊的具體實(shí)現(xiàn),其實(shí)也算一段偽代碼。
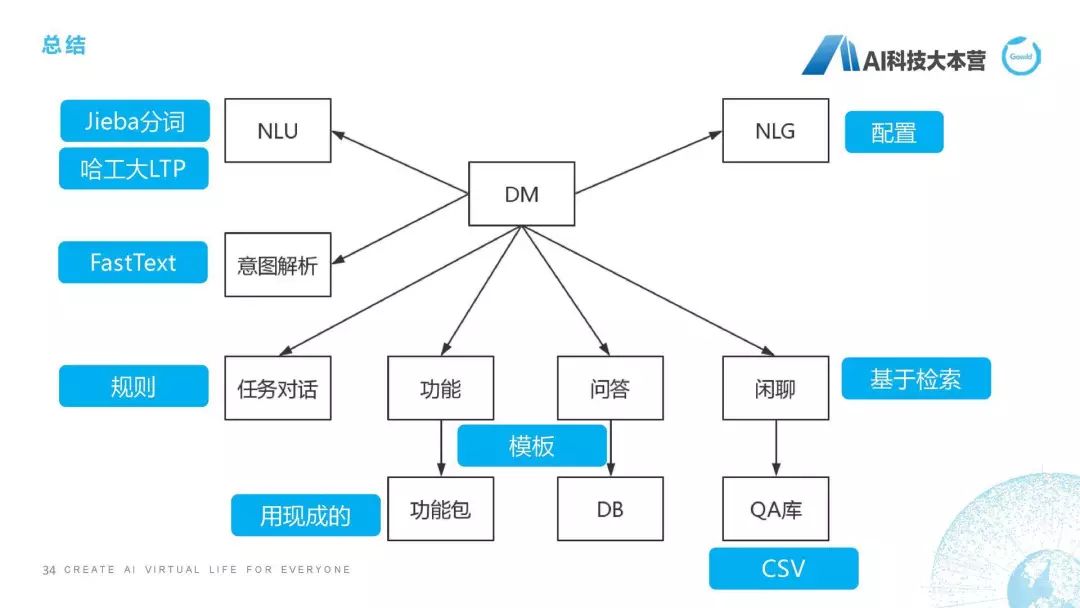
總結(jié)一下,我們整個框架怎么實(shí)現(xiàn)呢?首先,NLU,我們用Jieba分詞、哈工大的LTP;意圖解析我們可以用FastText或者Bert;NLG我們用配置的方法去做;DM我們用Python自己去寫;任務(wù)對話我們用規(guī)則去實(shí)現(xiàn);功能模塊我們用現(xiàn)成的;問答模塊我們用模板;閑聊模塊我們是用基于檢索的方法,這樣就可以非常簡單的去實(shí)現(xiàn)一個聊天機(jī)器人。今天的主要部分就講到這些。
知識圖譜在虛擬生命中的應(yīng)用及技術(shù)路徑
接下來跟大家聊一聊關(guān)于知識圖譜方面的信息,聊天機(jī)器人這塊基本的技術(shù)方面跟大家聊得差不多了。
講講圖靈測試。聊天機(jī)器人現(xiàn)在表現(xiàn)是非常差的,但是在2014年仍然通過了圖靈測試,圖靈測試本身是圖靈在1950年代發(fā)明的測試,它是測試機(jī)器人是不是能蒙騙人類,它的測試方法是在5分鐘之內(nèi),我一個人,這有一堵墻,不知道對面是一個電腦還一個人,我跟它對話5分鐘,如果參與測試的人30%都被騙了,那么就說這個計(jì)算機(jī)通過了圖靈測試。其實(shí)這個測試標(biāo)準(zhǔn)是非常主觀的,我們可以利用很多trick去繞過這樣的一些設(shè)置。所以說其實(shí)圖靈測試并不能真正反映機(jī)器人的智能程度,因?yàn)閳D靈測試的來源是什么?大家可能聽過這個故事,圖靈是個同性戀者,所以說圖靈測試是每一個在英國的同性戀在1950年代必須通過的日常測試,也就是說作為一個同性戀,你能不能裝成一個異性戀,其實(shí)這是圖靈測試最先緣起的原由,其實(shí)是很悲慘的一個故事,最后圖靈由于被接受化學(xué)閹割,然后抑郁而去自殺的,非常可惜的一個事情。所以我們講這些的原因是在于,我們覺得哪怕是聊天機(jī)器人它通過了圖靈測試,并不能代表它真正具有智能的一個效果。
所以我們接下來就會想:既然這個聊天機(jī)器人做得這么差,怎么去提升它的體驗(yàn)感和效果?我們想到的一種方法是給聊天機(jī)器人賦予人格和IP化,比如大白,比如R2D2,比如外星人,好像就是叫AI,這個電影,《西部世界》,我們是不是能把這些形象放到聊天機(jī)器人里去,這是我們想要做的事情。
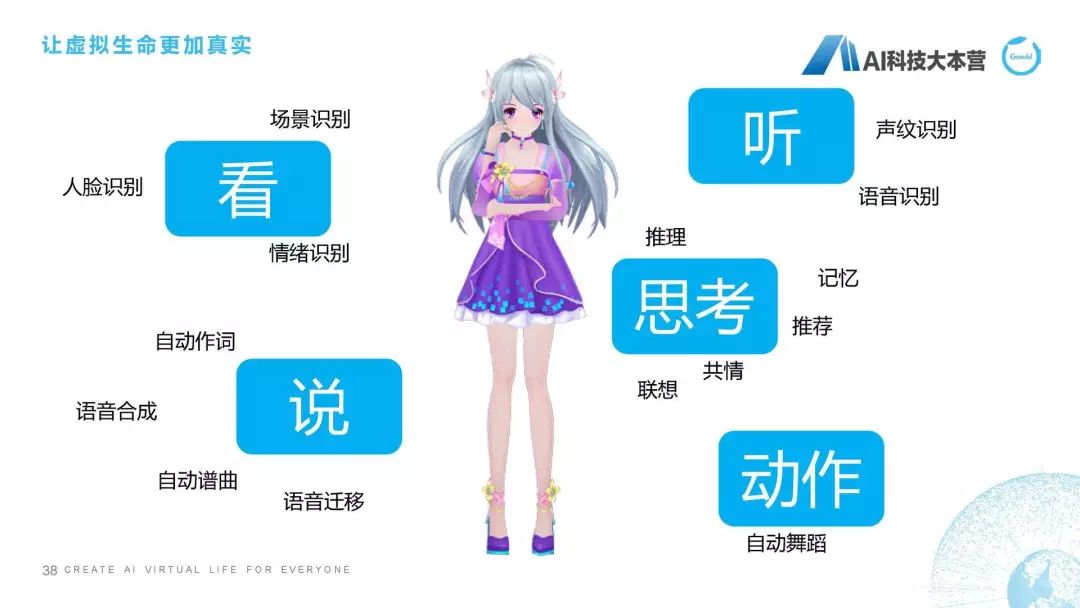
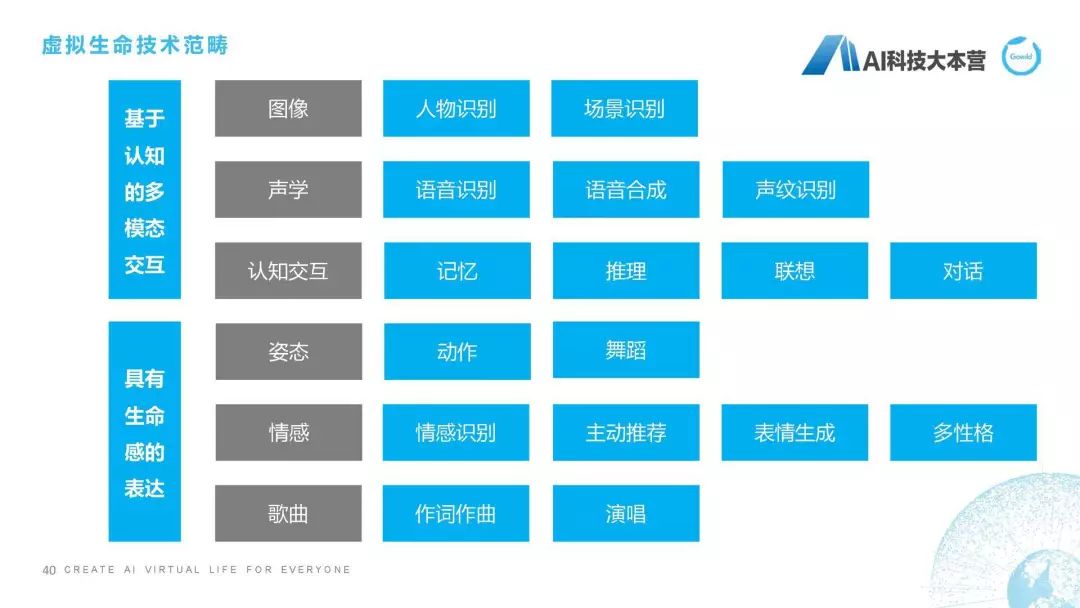
我們曾經(jīng)做的一個第二代產(chǎn)品,就是怎樣讓一個聊天機(jī)器人更加具有生命感的表達(dá),視頻因?yàn)闀r間關(guān)系就不播放了。所以我們對虛擬生命有一個比較完整的定義,我們把它稱之為“虛擬生命”,它除了具有聊天機(jī)器人最基本的能力之外,它還具有比如看、聽、說、思考、動作等這樣一些方面的能力,這是我們對虛擬生命期望的效果。定義是我們希望它以多形態(tài)和多模態(tài)進(jìn)行交互,具備強(qiáng)大的感知和認(rèn)知能力,并進(jìn)一步實(shí)現(xiàn)自我認(rèn)知和自我進(jìn)化。這是我們對虛擬生命總體的技術(shù)進(jìn)行的總結(jié),可以看到除了圖像、聲學(xué)和認(rèn)知交互之外,我們還具備像姿態(tài)、情感、作詞作曲、演唱、多性格、情感識別、主動推薦等各方面的能力。
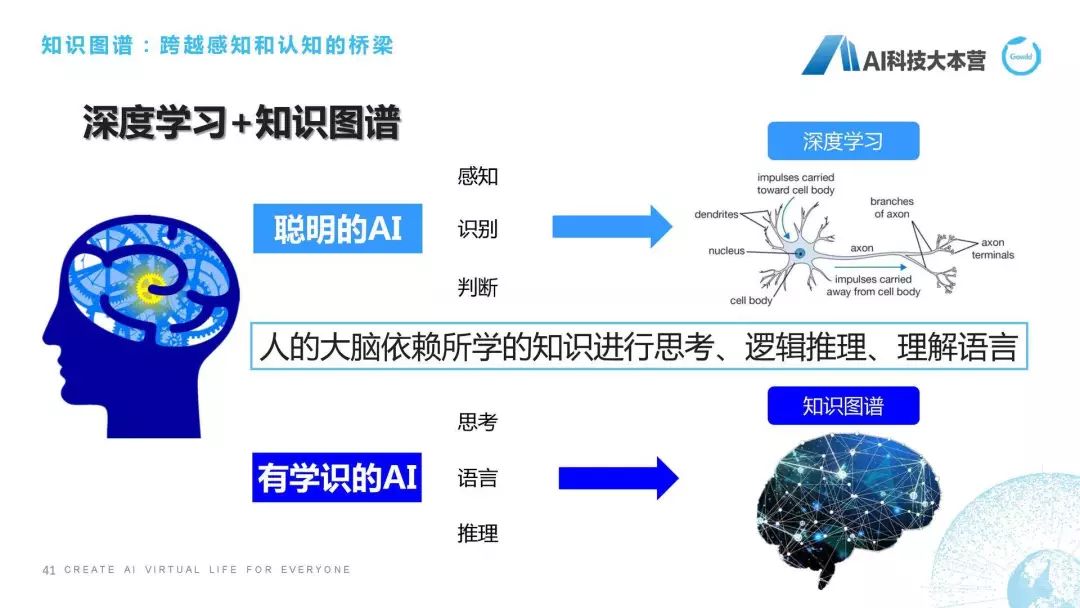
怎么樣去實(shí)現(xiàn)這些能力?我們前面這些鋪墊都是為了引出我們接下來要講的這塊內(nèi)容,叫“知識圖譜”,怎么樣真正的讓聊天機(jī)器人擁有自己思考、理解、推理能力,也就是我們正在研究的知識圖譜技術(shù)所要帶給我們可以期望的東西。我們知道,現(xiàn)在是深度學(xué)習(xí)和大數(shù)據(jù)的時代,深度學(xué)習(xí)和大數(shù)據(jù)利用它的算力、利用它的數(shù)據(jù),可以在感知層面,比如圖像識別、語音識別、語音合成做到非常好的效果,但是碰到有一些需要思考的問題深度學(xué)習(xí)肯定是要掛掉的。舉個簡單的例子,比如肖仰華老師曾經(jīng)舉個經(jīng)典的例子叫“我把雞蛋放到籃子里,是雞蛋大還是籃子大?”這個問題對于深度學(xué)習(xí)來講是非常難以解決的,因?yàn)樗痪邆涑WR和推理,所以雞蛋大還是籃子大的這個問題它就回答不了。另外,我還可以問一個問題,叫“姚明的妻子的女兒的媽媽的老公的國籍是什么?”我想現(xiàn)在的聊天機(jī)器人無一例外都會被繞暈的,因?yàn)橐γ鞯钠拮拥呐畠旱膵寢尩睦瞎鋵?shí)就是姚明,但是機(jī)器人是沒有辦法去理解這么復(fù)雜的一段信息的。但這個時候如果我們擁有了這樣一套豐富的知識圖譜之后,我們其實(shí)就可以進(jìn)行推理,包括常識推理這方面的內(nèi)容。

知識圖譜全流程
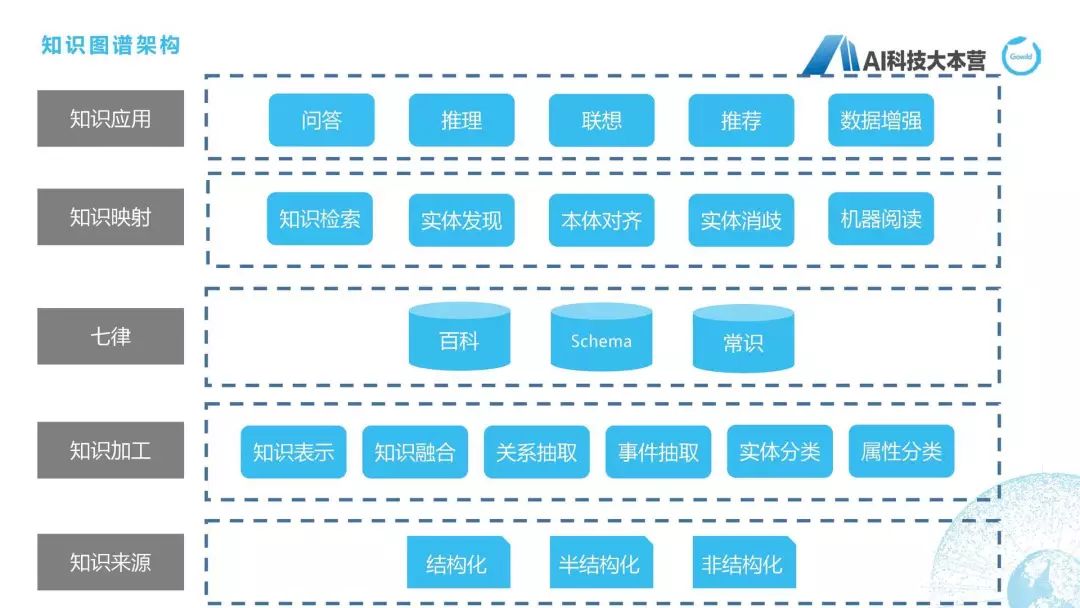
接下來我們就開始介紹知識圖譜整體的全流程,知識圖譜的全流程在這張圖上寫得比較清楚。最下面是對于三種不同類型的數(shù)據(jù)(結(jié)構(gòu)化、半結(jié)構(gòu)化、非結(jié)構(gòu)化)進(jìn)行數(shù)據(jù)加工,這里用到知識表示、知識融合、關(guān)系抽取、事件抽取、實(shí)體分類、屬性分類等各種方法去建立起自己的知識圖譜,我們自己的知識圖譜叫“七律”,所以我這里把“七律”這兩個字寫上來了。當(dāng)我們建立了這些知識圖譜之后,在上層就可以想象出它可以做很多應(yīng)用,比如問答、推理、聯(lián)想、推薦,等等,但做這些應(yīng)用之前我們還需要有一步中間層,叫“知識映射層”,比如我們需要做知識檢索、本體對齊、實(shí)體消歧、機(jī)器閱讀這方面的事情,才能夠使得這個知識圖譜能夠真正的變成知識應(yīng)用。
知識來源
首先說一下知識來源,我們的來源來自百度、互動百科、知乎、新浪、維基、萌娘百科。為什么要有萌娘百科呢?我們自己做的產(chǎn)品是一個偏向二次元和娛樂化的,所以在建立知識圖譜的時候一定要根據(jù)自己的領(lǐng)域去建立知識圖譜,萌娘百科給我們帶來很多關(guān)于二次元的百科知識,這是我們非常有用的一些知識,所以我們?nèi)ソ⒘艘惶灼蚨卧倪@樣一套知識圖譜。
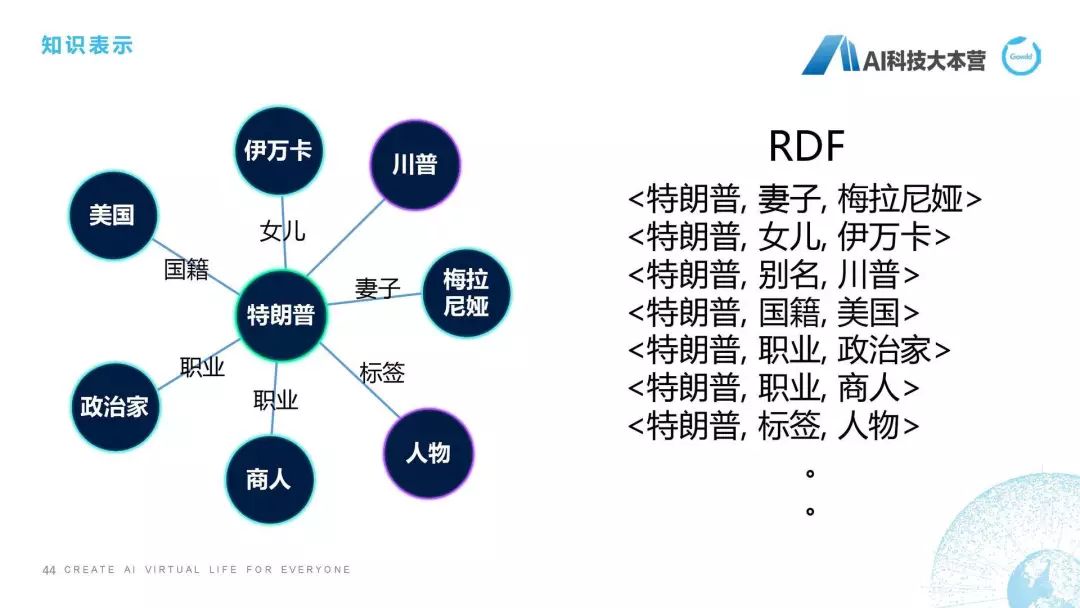
知識表示
然后是知識表示,我們都知道知識要去進(jìn)行存儲的話要有一定的表示方式,我們除了比較直觀的圖表示,還有這種RDF的表示方式,大家可以理解它是一個三元組,比如特朗普的妻子是梅拉尼婭,特朗普的女兒是伊萬卡,其實(shí)是兩個實(shí)體,特朗普和梅拉尼婭中間的關(guān)系是妻子關(guān)系,特朗普的妻子是梅拉尼婭,這就是我們對知識進(jìn)行表示。所以在我們最底層對知識進(jìn)行處理之后,我們接下來對知識需要進(jìn)行一個表示。
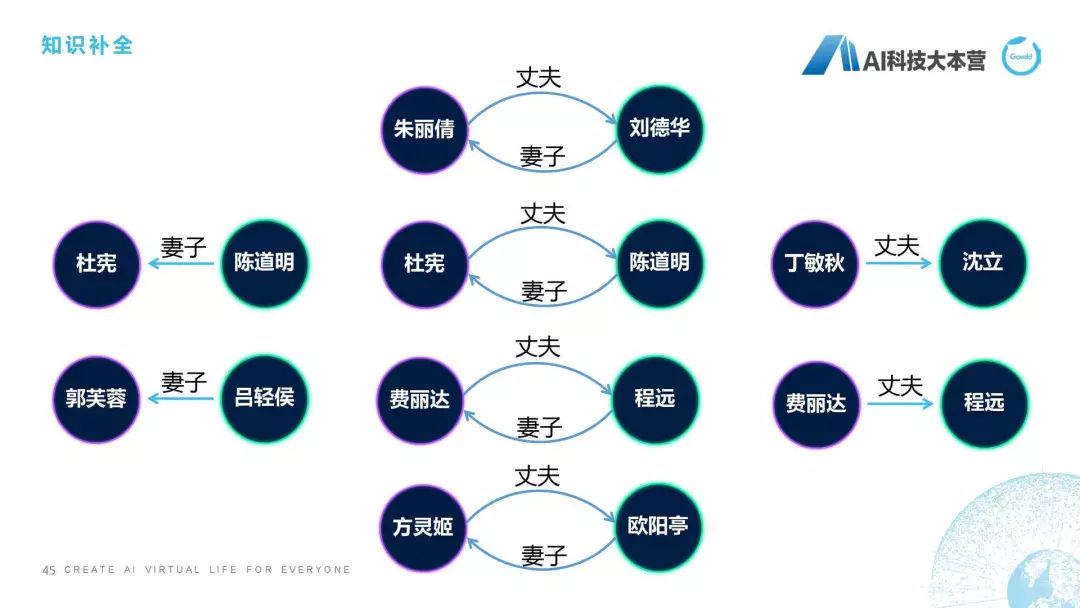
知識補(bǔ)全
然后這個PPT跟大家聊的是知識補(bǔ)全,知識補(bǔ)全是怎么做的呢?給大家舉個例子,比如陳道明的妻子是杜憲,我們在百科里去查陳道明這個詞條,我們會發(fā)現(xiàn)它有一個信息是妻子是杜憲,但是我們查杜憲的時候發(fā)現(xiàn)杜憲并沒有一個邊指向陳道明,那如果我們有了一套知識體系,它會限定如果一個人是另外一個人的丈夫,那么這個人肯定是這個人的妻子,這個邏輯應(yīng)該不會錯吧?這個也可能會錯,為什么呢?兩個人如果都是男性,或者兩個人如果都是女性的話,這個就有問題了。但我們假定這個不存在,我們假定如果一個人是一個人的妻子,那么這個人肯定是另外一個人的丈夫。所以有了這套知識體系之后,我們就可以補(bǔ)上一條邊,比如杜憲的丈夫是陳道明,這條邊就可以自動補(bǔ)上了,費(fèi)麗達(dá)的丈夫是程遠(yuǎn),那么程遠(yuǎn)的妻子就是費(fèi)麗達(dá),用這樣一些手段可以舉行知識補(bǔ)全,這也是預(yù)處理時需要去做的一個事情。
知識擴(kuò)展
什么叫知識擴(kuò)展?就是我們把一些不存在的關(guān)系學(xué)習(xí)到并且加入到知識圖譜里去。我舉的這個例子可能不恰當(dāng),因?yàn)檫@個關(guān)系是已經(jīng)存在的了,我只是說一下這個方法是怎么做的。
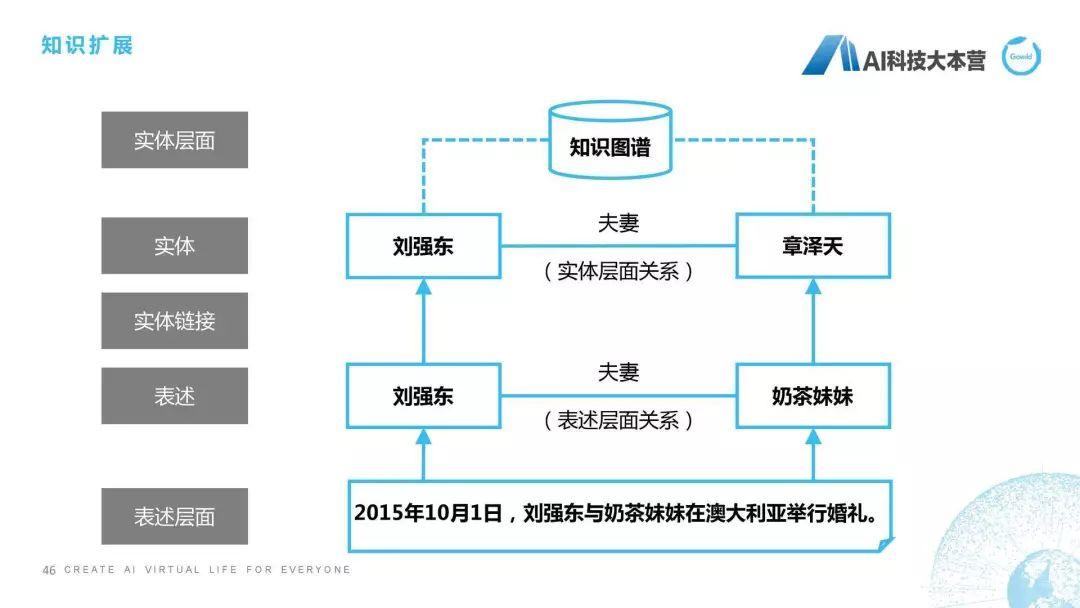
“2015年10月1號,劉強(qiáng)東與奶茶妹妹在澳大利亞舉行婚禮”,這個句子它里面是有一個關(guān)系存在的,是什么關(guān)系?劉強(qiáng)東和奶茶妹妹是夫妻關(guān)系,然后我們接下來通過實(shí)體鏈接,在數(shù)據(jù)庫里找到奶茶妹妹其實(shí)真名是章澤天,那這樣我們就可以直接在劉強(qiáng)東和章澤天之間建立起一個夫妻關(guān)系,并且把這個知識擴(kuò)展到我們已有的知識圖譜中,這個就是我們所說的知識擴(kuò)展方面的內(nèi)容。
新知識發(fā)現(xiàn)

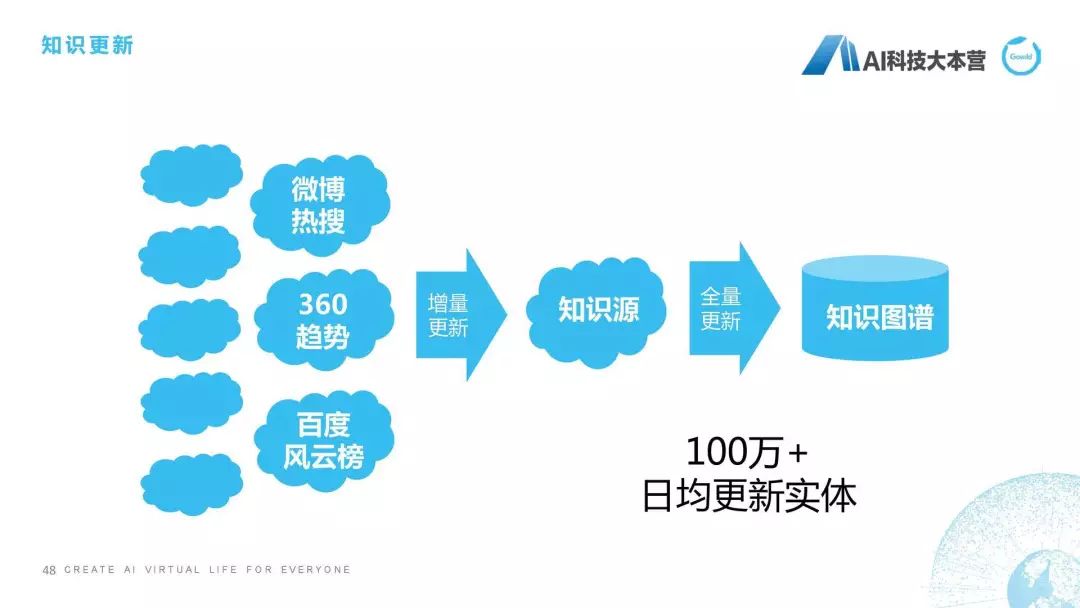
新知識發(fā)現(xiàn)也是我們要做的一個事情,因?yàn)槲覀冎乐R的變化實(shí)在是太快了,我們最近有很多熱點(diǎn)知識不斷刷新我們的認(rèn)知。比如“御三家”什么意思?原本是指德川本家之外的三大家族,現(xiàn)在可能會指這個,比如亞洲表情包御三家:姚明、金館長、兵庫北,這種御三家。還有“隔壁老王”,隔壁老王以前就是指隔壁老王,現(xiàn)在它有一個含義還叫“親生爸爸”,這個也是新知識發(fā)現(xiàn),我們要去找的一些東西。“祭天”也是前年挺火的,暴風(fēng)影音那個事,但是我覺得挺有趣的,祭天是通過殺死程序員、產(chǎn)品經(jīng)理等,來留住用戶的一種儀式。它其實(shí)也是老詞的一個新的解釋,其實(shí)我們在新知識發(fā)現(xiàn)時,就需要去發(fā)現(xiàn)這樣一些新的知識,有了這些新知識之后怎么辦?后面就是更新。我們有兩種更新方式,第一種更新方式是增量,當(dāng)我們發(fā)現(xiàn)這樣的熱詞之后,我們會對它以及它周邊的實(shí)體進(jìn)行增量更新;另外一種是全量更新,比如我們定期一個月對知識圖譜進(jìn)行全范圍的更新,因?yàn)樗拇鷥r是相當(dāng)大的,所以知識更新也是我們知識圖譜整個構(gòu)建鏈條中不可或缺的一部分來保證知識圖譜的新鮮度。
基于知識圖譜的問答
基于知識圖譜的問答是知識圖譜的一種應(yīng)用,這里面跟大家舉的例子是這個基于語義解析的知識圖譜的問答。我們可以看到,整個問答里綜合了自然語言處理的各種模塊,也綜合了我們在知識圖譜里所涉及到的知識領(lǐng)域。
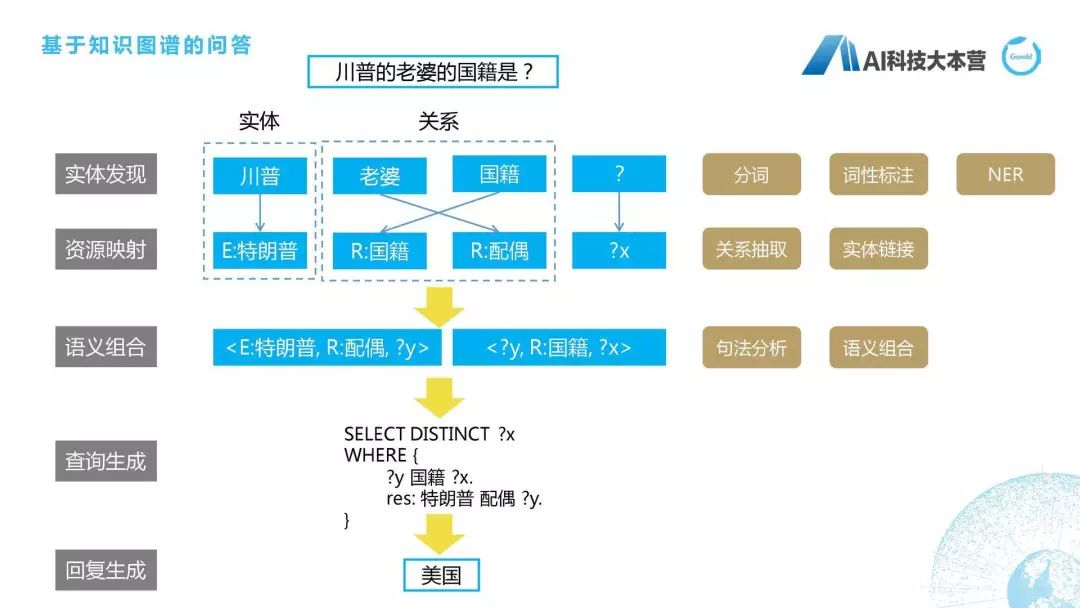
川普的老婆的國籍是什么?首先我們實(shí)體會抽取到“川普”,“川普”是指四川普通話?還是指特朗普?這里我們就需要有一個映射,有一個實(shí)體的消歧,最后我們得到它是指特朗普。“老婆”對應(yīng)的標(biāo)準(zhǔn)叫法是“配偶”,“國籍”是“國籍”,“?”是“?X”,我們就會把這個語義進(jìn)行組合,比如特朗普的配偶是“?y”“?y”的國籍是“?x”,而我們最后一個查的是“?x”,所以它就會這樣寫,“SELECT DISTINCT?X”WHERE,限定條件是什么?“?y”的國籍是“?x”,并且限制特朗普的配偶是“?y”,最后我們得到特朗普的配偶是梅拉尼婭,梅拉尼婭的國籍是美國,所以最后得到的答案是“美國”,具體的細(xì)節(jié)可以去研究一下基于語義解析的知識圖譜。用到很多技術(shù),包括分詞、詞性標(biāo)注、NER、關(guān)系抽取,等等,也不是我們這節(jié)課所討論的范圍。
工程落地的其他問題
我們感覺掌握了很多NLP知識,掌握了很多KG技術(shù),又有了一些工程的手段,就覺得我可以做成非常棒的產(chǎn)品。但正如這幅圖給大家看到的一樣,這是一個什么鳥,我也忘了是野鴨還是什么,它在落地冰面時滑到了,真正落地跟我們想象的有時是完全不一樣的。所以在工程落地時有很多因素是需要考慮的,這里面不僅僅是技術(shù)的問題,技術(shù)可能只是占我們整個產(chǎn)品化的一個非常小的部分。我們需要考慮這個產(chǎn)品賣給誰、怎么賣,然后我們還需要考慮整個系統(tǒng)的性能架構(gòu)。
我們是采用檢索式的閑聊問答,還是做多模態(tài)的交互問答,同時我們還要考慮它軟硬件投入、人力投入和市場行情是什么樣的。尤其是現(xiàn)在聊天機(jī)器人本身就是一個已經(jīng)不是紅海市場,已經(jīng)是血海市場了,大家在這個市場上真的是打得頭破血流,如果大家還是想以簡單的聊天機(jī)器人的形式來進(jìn)入市場的話,就會面臨什么樣的競爭?就會面臨49元的小米小愛音箱,就會面臨79元的天貓精靈,就會面臨199元的小米的小愛同學(xué),還有299元百度的小度在家。所以怎么樣做工程化和產(chǎn)品化,也是需要我們在商業(yè)的邏輯上思考的問題。
結(jié)語
最后耽誤大家2分鐘,簡單講一下我們做的是什么,我們做的是事情是聊天機(jī)器人,具體的歷程就不跟大家說了,首先是公子小白。我們在2018年8月份推出了這樣一款新的產(chǎn)品叫琥珀,它是全息投影的智能聊天音箱,2019年5月份會和全職高手合作,給大家推出一版葉修版本的琥珀機(jī)器人,我們期待用戶可以通過機(jī)器人跟葉修直接進(jìn)行交互,然后看它的一些動作。2019年12月份,也就是今年年底,我們會推出一個男性明星,這個男性明星應(yīng)該是我們現(xiàn)在國內(nèi)流量前10的一個男明星,小鮮肉級別的男明星,也希望大家來關(guān)注我們的產(chǎn)品。
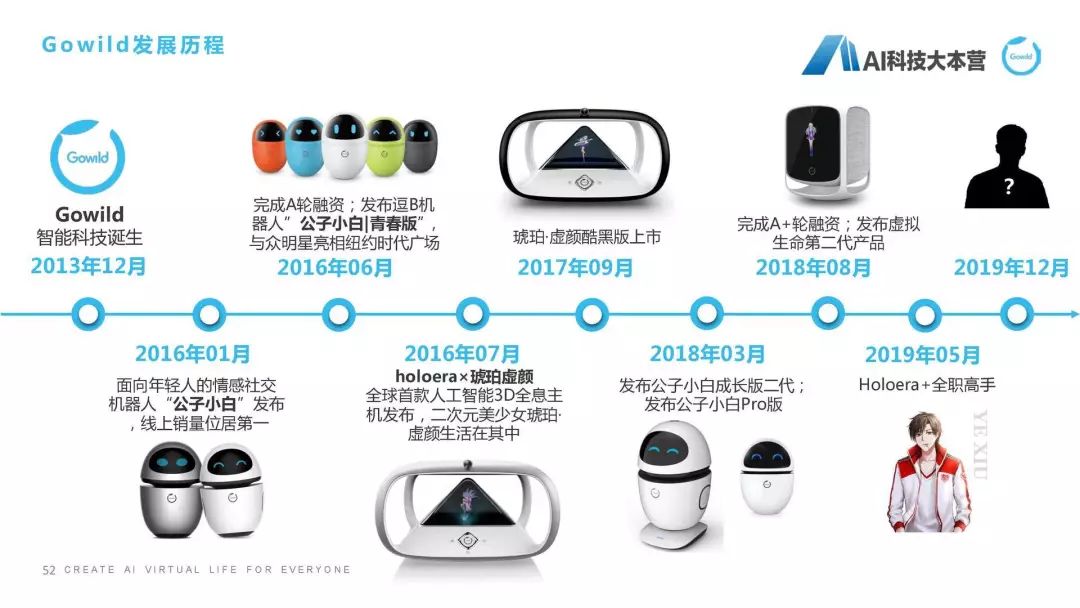
我們的人工智能研究院是在上海成立的,專家還包括張民老師、王昊奮博士,我們的成員來自于各個知名大學(xué),跟蘇大、華東師范大學(xué)等也建立了聯(lián)合實(shí)驗(yàn)室,也推出了一款叫“虛擬生命引擎”(GAVE)的引擎。
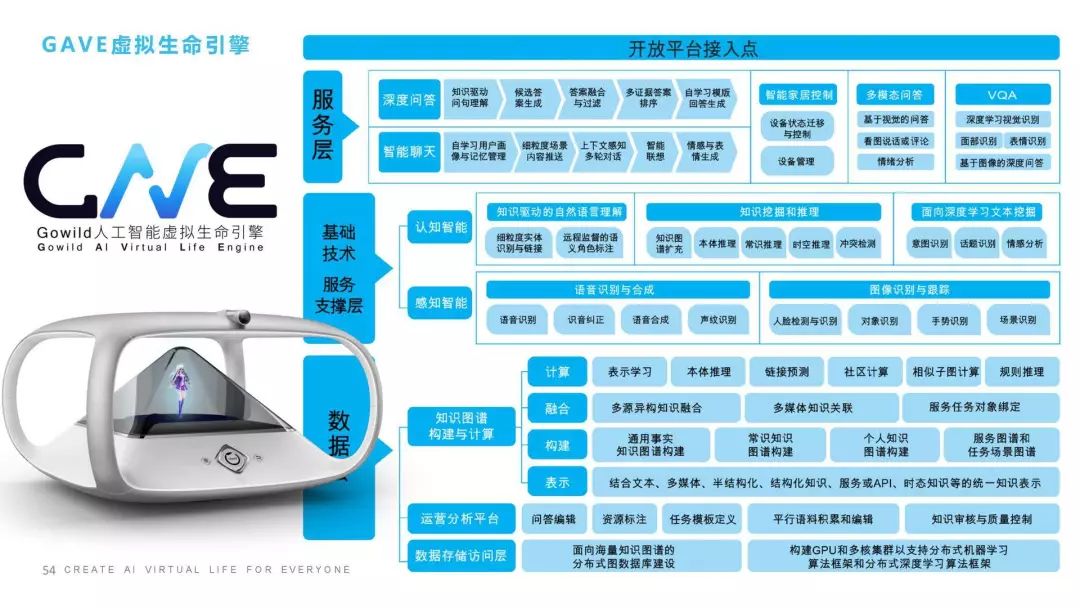
這是我的最后一頁,再跟大家聊兩句,我們整個虛擬生命的引擎包括幾個層面:我們在數(shù)據(jù)層其實(shí)做了很多事情,包括知識圖譜,包括基礎(chǔ)的數(shù)據(jù)分析和運(yùn)營平臺;中間層里我們會做一些基于認(rèn)知智能的、感知智能的,比如聲音、圖像、人臉識別、情緒識別,還包括像推理、聯(lián)想、記憶、情感這樣一些認(rèn)知智能;服務(wù)層我們會有聊天、智能家居、多模態(tài)問答等等;最后我們還可以提供開放平臺的接入點(diǎn),讓大家方便的接入到我們的一些功能。
感謝大家的支持,我的課程就講到這。
Q&A
提問1:一個對話系統(tǒng)包括這么多內(nèi)容,用端到端的系統(tǒng)好,還是分成一步一步來做比較好?感覺工程量好大。
邵浩:看你什么目的吧,如果你是為了做研究目的的話,那肯定是端到端了,如果寫論文的話肯定是要端到端,這個是毋庸置疑的。工程方面還是要好用,所以工程方面的原則是盡可能用最簡單的方法來得到效果;如果不行,我們再想其他的辦法。
剛才我說到分兩個層面,如果你想學(xué)工程的話,就還用這些規(guī)則自己動手實(shí)踐去做;如果你想做論文研究,你就還是去專注于論文和端到端的系統(tǒng)。
提問2:老師,知識圖譜在對話系統(tǒng)中重要嗎?現(xiàn)在用得多嗎?
邵浩:重要,但現(xiàn)在用得不多,為什么?你說的這個是知識圖譜在對話系統(tǒng)中。知識圖譜在問答系統(tǒng)中還是蠻重要的,我們在基于知識圖譜的問答里還是大量使用知識圖譜,但是在其他的功能模塊,剛才我講到了,比如閑聊,比如任務(wù)對話,那知識圖譜用得并不多。而且工程界對知識圖譜的使用也不是特別多。
提問3:DM中slot中如果命中Keyword,但沒有返回日期和時間,會返回相應(yīng)的問題給用戶,請用戶補(bǔ)充日期和時間,請問這個問題也是人工設(shè)定的嗎?
邵浩:這個問題是在我們?nèi)プ鲞@個任務(wù)之前就已經(jīng)設(shè)定好的,比如天氣我會給它幾個槽位,一個叫“時間”,一個叫“日期”。訂票我會給它幾個槽位:出發(fā)地、目的地、出發(fā)時間、航班、機(jī)場。所以其實(shí)你可以任務(wù)它是人工設(shè)定的,這個問題簡單回答,就是人工設(shè)定的。
提問4:如果目標(biāo)是從非關(guān)系數(shù)據(jù)庫中對知識進(jìn)行存儲、抽取、推理,請問這個存儲是存儲在SQL還是noSQL比較好?
邵浩:像JENA、MongoDB、Dom4J,我們在工程中要根據(jù)具體場景選擇不同的數(shù)據(jù)庫的實(shí)現(xiàn)方式,。說實(shí)話,現(xiàn)在MySQL在某些場景下真的非常好用,還有MongoDB和ES,這種數(shù)據(jù)庫有時真的比圖數(shù)據(jù)庫的效率要高非常多。所以要根據(jù)具體的工程場景要實(shí)現(xiàn)什么樣的功能去決定。
提問5:對目前的算法應(yīng)用效果還不如正則或者模板效果好,那怎樣去選擇呢?
邵浩:它是一種融合性方法,我們在自己的聊天機(jī)器人系統(tǒng)中也有大量的,但是我們會設(shè)計(jì)一些多層的策略。比如說我們在意圖識別時會做一些策略,意圖前面我們會有一些規(guī)則,規(guī)則如果能覆蓋的精確性問題那最好,如果覆蓋不了的,我們用深度學(xué)習(xí)方法去進(jìn)行意圖分類時還會采用融合方法(Stacking),我們會在融合之后綜合評判是不是要選取得分最高的那個模型最后明確意圖。
而且我們在做這個事情的時候一般都是返回top3或者top5,同時我們在后面模塊如果發(fā)現(xiàn)這個意圖進(jìn)行不下去了,我們還有一個“拒識”模塊,我們即便是走通了也會把它“拒識”掉,這個要根據(jù)產(chǎn)品的效果去選擇的。
提問6:意圖識別全靠人工編輯所有意圖規(guī)則在進(jìn)行判斷嗎?還有其他方法嗎?
邵浩:我剛才舉的例子是用規(guī)則來進(jìn)行意圖識別的,但我后面有一個PPT還講到,意圖識別其實(shí)是一種融合性方法,所以可以你先有規(guī)則,然后后面再用一些深度學(xué)習(xí)方法,剛才我說的fastText也可以做這種意圖分類,但需要有大量的數(shù)據(jù)做監(jiān)督學(xué)習(xí)。
提問7:怎樣自動化測試聊天機(jī)器人的效果?
邵浩:這個要看一下評測標(biāo)準(zhǔn)。我們自己內(nèi)部會有自己的評測標(biāo)準(zhǔn),這個評測標(biāo)準(zhǔn)包含幾百項(xiàng)測試,比如它的識音,它的識音還要分幾米,比如近場識音、遠(yuǎn)場識音,然后它對話過程中的輪數(shù)、學(xué)習(xí)時間、對話的自然度、語音的自然度,等等,都會作為聊天機(jī)器人的測試效果。所以現(xiàn)在工程界并沒有一個非常準(zhǔn)確的、嚴(yán)格的測試聊天機(jī)器人的效果的方法。如果你們想去參考的話,學(xué)術(shù)界有很多這種聊天機(jī)器人的評測,非常多的評測,大家可以去看一下,我們那本書也有一章寫了測評的方法。
提問8:意圖識別后的分類用哪種方式好?自上而下直接分發(fā)到domain或者bot,還是中控先分發(fā)、后收集反饋?
邵浩:每一家bot的做法都不太一樣,你說的domain其實(shí)是一種兩層次分類,我們是一種五層次分類。我們的做法會采用一個兩層策略,我們先做一個粗分類,然后有一個topK的結(jié)果,然后把這個topK的結(jié)果分發(fā)給K個子模塊進(jìn)行執(zhí)行,每個子模塊相當(dāng)于是一種競爭關(guān)系,它們在執(zhí)行完這些問題之后,給我了DM一個反饋。比如我是音樂模塊,我給我的DM反饋就是我覺得我做得最好,我給自己打10分,你愿意不愿意接受我這種分值。然后DM就會中控再決定我收集到的這些,比如我在500毫秒收集到所有模塊的反饋之后,再決定選擇哪個模塊進(jìn)行最后的返回。所以這塊最后還是根據(jù)每家bot的系統(tǒng)不太一樣。
提問9:圖靈測試如果不能體現(xiàn)聊天機(jī)器人的先進(jìn)性,那么通過哪種測試來測試性能呢?
邵浩:這個跟剛才我說的那個問題一樣,學(xué)術(shù)界是有比較多評測數(shù)據(jù)的比賽,大家可以關(guān)注一下這些比賽,看一下理論界是怎么做的。
提問10:在意圖識別中如果遇到一個query有多個意圖,該怎么處理比較好?
邵浩:我們其實(shí)是有topK,會以它最后的分值來判斷。
提問11:NLU會做預(yù)處理嗎?
邵浩:會的,肯定會做的,而且都是單獨(dú)模塊,比如語氣詞、標(biāo)準(zhǔn)化,都是單獨(dú)模塊去做的。
提問12:詞義消歧怎么做?
邵浩:詞義消歧有各種不同的方法,有基于規(guī)則的,還有基于熱度的。比如基于熱度,比如我們在講“737”時,它可能指737-800,也可能指737max,這時我們可能根據(jù)社交媒體的熱度,來判斷最近最火的新聞是737max飛機(jī)失事,這時我們就可以利用熱度進(jìn)行消歧。消歧的方法還有很多種,我們可以利用上下文、熱度、貢獻(xiàn)詞,這個都可以去用的。
提問13:在垂直領(lǐng)域進(jìn)行對話,利用知識圖譜,性能是否會有提升?
邵浩:肯定會有的,因?yàn)槲覀円沧鲞^很多類似于政府的垂直項(xiàng)目、醫(yī)療的垂直項(xiàng)目,利用知識圖譜會大大提升它的問答效果,這個肯定會的。
提問14:機(jī)器人處理的鏈路很長,如何平衡響應(yīng)速度和鏈路模塊的質(zhì)量?
邵浩:這個問題提得很好,因?yàn)槲覀儸F(xiàn)在聊天機(jī)器人里有一個非常嚴(yán)重的問題叫“錯誤傳遞”,如果你串行模塊多的話,它的錯誤傳遞下來就會非常差。我們平衡時要根據(jù)具體情況,比如我們會設(shè)置一個“超時”,有些模塊并行處理時,我們會選擇沒有超時并且效果最好的那個處理。
提問15:如何衡量情感方面的好壞?
邵浩:我們自己有一個三層體系,大概27種判斷標(biāo)準(zhǔn),這個可能也會根據(jù)具體的情況來具體判斷吧,沒有辦法給出一個標(biāo)準(zhǔn)的指標(biāo)。
提問16:有什么指標(biāo)來判定閑聊回答的優(yōu)點(diǎn)?
邵浩:最直接的一個指標(biāo)就是看看用戶愿意不愿意跟你聊,小冰其實(shí)提出了很多指標(biāo),比如用戶跟你進(jìn)行對話的輪數(shù)作為一個指標(biāo)。
提問17:多輪意圖分類是怎么實(shí)現(xiàn)的?
邵浩:我剛才在PPT里應(yīng)該說得比較清楚,“那明天呢”它沒有走到正常意圖里,它正常意圖得分會非常低,它低于我們的域值,所以我們要么丟棄它,要么拒識,要么判斷它是不是多輪的,如果它走到多輪里,我們會利用多輪的狀態(tài)機(jī)進(jìn)行它后面的問答。
提問18:檢索問答琥珀是否有用問題答案的匹配方法,還是只用問題和問題的匹配方法?
邵浩:這個問題問得比較好,我們兩種都用。因?yàn)槭裁矗恳驗(yàn)槲覀兊膌og數(shù)據(jù)是非常多的,這個可能又涉及到我們比較底層的東西,我就不多說了。我們兩種方法都會用,而且問題到答案的這種方法,有時是把問題通過其他的方式生成答案之后再進(jìn)行匹配的,這個方法是很有效的,建議大家去嘗試一下。
-
人工智能
+關(guān)注
關(guān)注
1792文章
47425瀏覽量
238956 -
大數(shù)據(jù)
+關(guān)注
關(guān)注
64文章
8897瀏覽量
137523 -
聊天機(jī)器人
+關(guān)注
關(guān)注
0文章
339瀏覽量
12332
原文標(biāo)題:聊天機(jī)器人落地及進(jìn)階實(shí)戰(zhàn) | 公開課速記
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
自然語言處理在聊天機(jī)器人中的應(yīng)用
馬斯克旗下xAI計(jì)劃推出Grok聊天機(jī)器人獨(dú)立應(yīng)用
NLP技術(shù)在聊天機(jī)器人中的作用
ChatGPT 與傳統(tǒng)聊天機(jī)器人的比較
Meta人工智能聊天機(jī)器人進(jìn)軍新市場,挑戰(zhàn)ChatGPT
Snapchat聊天機(jī)器人集成谷歌Gemini技術(shù)
Meta將推出音頻版聊天機(jī)器人
地瓜機(jī)器人與廣和通深度合作,共驅(qū)智能機(jī)器人商用落地

地瓜機(jī)器人與廣和通深度合作,共驅(qū)智能機(jī)器人商用落地

AI聊天機(jī)器人Grok向歐洲X平臺Premium會員開放
Anthropic在歐洲推出Claude聊天機(jī)器人
揭秘聊天機(jī)器人的“大腦”-大語言模型





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論