 東京工業大學開發AI預測系統 可預測0.5秒后的動作
東京工業大學開發AI預測系統 可預測0.5秒后的動作
預測這件事情的重要性不言而喻。畢竟如果你比別人提前知道信息就能夠搶占先機。
先不說搶占先機這件事情,如果你能夠預測的對方接下來的動作,至少下面這種情況不會發生。
現在,通過人工智能或許能夠改善一些。
近日,東京工業大學研究小組發布了一套格斗訓練系統“FuturePose”,通過深度學習能預測 0.5 秒后對手的動作。
在這項研究中,研究人員開發了一套系統,通過從一個 RGB 相機捕獲的圖像中,從 30 fps(1幀= 1/30秒)圖像中預測15幀后,即0.5秒后的動作,然后進行戰斗訓練。對戰對手不同裝束,而受訓者可以戴 VR 頭盔來同時觀察對手的當前姿勢和預測的0.5秒后的姿勢。
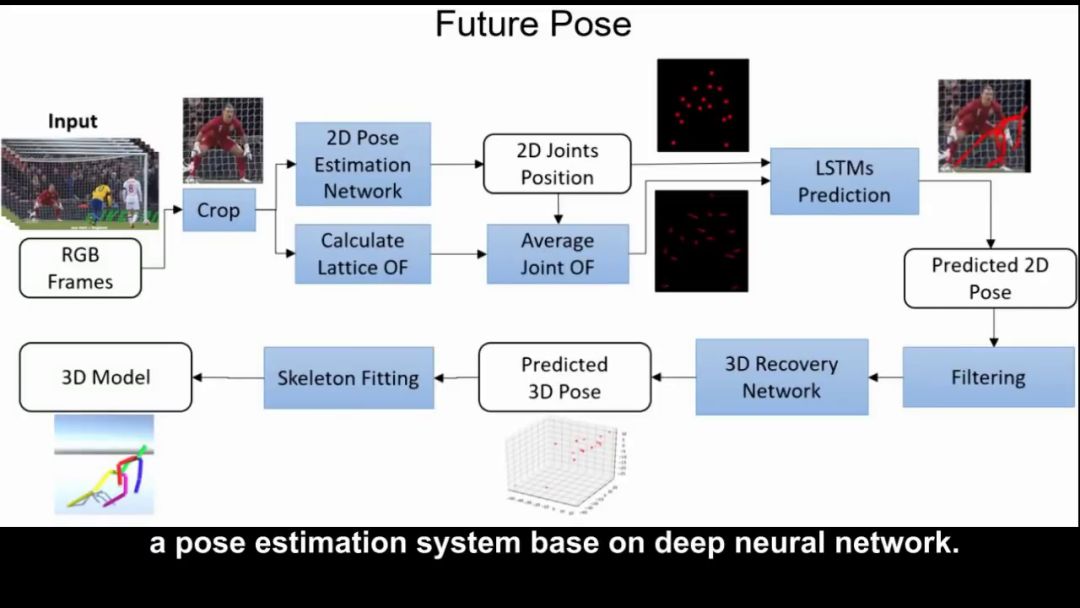
首先,通過殘差網絡(學習輸出減去輸入殘差的機器學習)來分析RGB圖像,以估計對手的2D位置。該位置輸入到 LSTM(可以學習長時序列數據的模型)以學習時序特征,并且預測未來的2D位置。
之后用網格光流(為向量來視覺化表示物體移動。通過將物體網格化減少計算量),將我們使用晶格光流(它表示物體的運動作為視覺表示中的矢量。物體的復雜性通過晶格簡化以減少計算量),將位置信息轉換成了人便于看的“運動”表示。
在視頻中,研究者分別進行了走路、跳躍以及拳擊等動作進行了測試?
從上面可以看出,通過這種方式預測的姿勢由紅色骨架模型表示,同時人體運動的預測可以實時可視化。雖然0.5秒看起來很短,但實際上在早期的一些格斗游戲中,同樣 30 fps中因為一幀而導致勝負的情況也有,所以15幀可以說是一個很大的優勢。
之后在實驗中,讓佩戴了HTC Vive的用戶在沒有預測和有預測兩種情況下進行測試。結果是,沒有預測平均反應時間是0.62秒,而有預測的響應是大約0.41秒,這表明有預測的情況更容易避開攻擊。
此外,在實際實驗視頻中,確實反應速度會增加,但在現實情況下,因為大腦處理視覺信息到身體反應存在時滯,因此會造成還差一點點就能躲開但是沒躲開的感覺。雖然總能在超能力戰斗漫畫中看到“我能在幾秒內看到未來”的敵人,但到底0.5秒還是太短了,可能還是得需要10多秒。
此外,該研究也適用于在線視頻,實驗證明它也可以預測足球守門員的動作和舞蹈的動作。于是我們就可以期待各種各樣的應用,比如觀眾在0.5秒前預測守門員是向左還是向右撲,還有在跳交際舞的時候通過預判對方的動作,讓舞蹈更流暢。
-
AI
+關注
關注
87文章
30761瀏覽量
268905
原文標題:先發制人!東京工業大學開發AI預測系統,可預測0.5秒后的動作
文章出處:【微信號:BigDataDigest,微信公眾號:大數據文摘】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
湖南工業大學選購我司同步熱分析儀,助力科研與教學創新

河南工業大學選購我司同步熱分析儀,助力科研與教學創新
中科億海微與西北工業大學智能微系統應用創新中心揭牌

遼寧工業大學選購我司HS-DR-5導熱系數測試儀

西北工業大學OpenHarmony技術俱樂部正式揭牌成立

CASAIM與北京工業大學合作開展鋼桁梁鋼材三維掃描試驗,研究高服役期鋼材銹蝕特征及力學性能退化規律
齊魯工業大學(山東省科學院)2021級自動化與物聯網生產實習正式開班!

工業大數據云平臺在設備預測性維護中的作用
泰瑞達與合肥工業大學“半導體測試技術聯合實驗室”

感謝湖北工業大學對我司高低溫試驗箱的認可

谷東科技與北京工業大學合作共研AR光波導高分子材料

河南工業大學選購我司HS-DR-5導熱系數測試儀

科學家利用AI預測核聚變反應堆裂變模式,避免重啟反應堆
2024款鴻蒙OS 最新HarmonyOS Next_HarmonyOS4.0系列教程分享
哈爾濱工業大學選購我司HS-DR-5導熱系數測試儀






 工商網監
工商網監
評論