 Cache的基本概念與工作原理
Cache的基本概念與工作原理
1.背景知識
隨著 CPU 技術的飛速發展,常用的處理器飛奔在越來越高的頻率之上,雖然處理器的速度越來越快,但是與之相匹配的存儲器的速度卻沒有獲得相應的提升,這大大限制了 CPU 的處理性能。而我們本系列文檔所介紹的主角 Cache 技術就是用來解決這個難題的。
在 ARM 發布 Cortex-M7 架構之后,微控制器領域也出現了頻率高達數百兆的芯片,如 ST 的 STM32F7 系列和 NXP 的 i.MX RT 系列芯片,這些芯片內的處理器都自帶 cache,在合理配置下可以表現出十分強悍的數據處理性能。那么什么是 cache?如何利用這一新特性編寫高性能的程序?又有什么要注意的地方嗎?你可能會有上述這些疑問,別擔心,本系列文章將會為你一一解答。
本系列文章分為三篇,第一篇為 《cache 的基本概念與工作原理》,講解 cache 相關的基礎知識。第二篇為《STM32F7 Cache 介紹與實戰》,講解如何在 STM32F7 系列芯片上使用 cache,并編寫程序進行性能測試。第三篇為《Cache 的一致性問題與使用技巧》,將會介紹 cache 的數據一致性問題和使用 cache 過程中的一些技巧。下面我們從 cache 的基礎知識開始,了解這一強大的特性吧。
2. 計算機的層次結構存儲系統
想要理解 cache 的工作原理,就必須要了解計算機系統中數據的存儲方式。
在計算機中程序執行時所有的指令和數據都是從存儲器中取出來執行的。存儲器是計算機系統中的重要組成部分,相當于計算機的倉庫,用來存放各類程序及其處理的數據。因此存儲器的容量和性能應當隨著處理器的速度和性能的提高而通過提高,以保持系統性能的平衡。
然而在過去的 20 多年中,隨著時間的推移,處理器和存儲器在性能發展上的差異越來越大,存儲器在容量尤其是訪問延時方面的性能增長越來越跟不上處理器性能發展的需要。為了縮小存儲器和處理器兩者之間在性能方面的差距,通常在計算機內部采用層次化的存儲器體系結構。
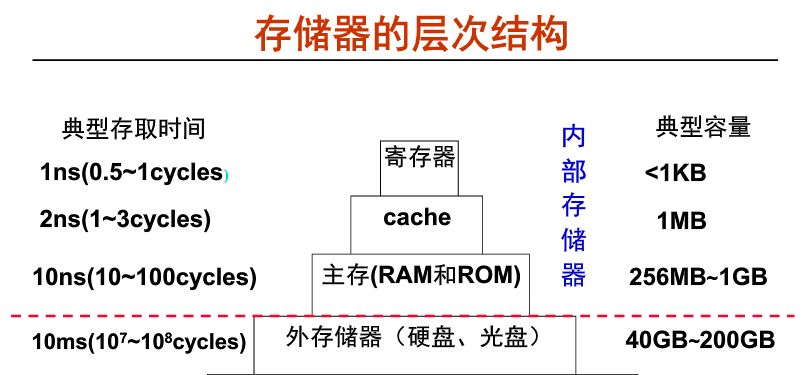
從上圖可以看到,速度越快則容量越小、越靠近 CPU。CPU 可以直接訪問內部存儲器。而外部存儲器的信息則要先取到主存,然后才能被 CPU 訪問。CPU 執行指令時,需要的操作數大部分來自寄存器,當需要對存儲器進行讀寫操作時,先訪問 cache ,如果不在 cache 中,則訪問主存,如果不在主存中,則訪問硬盤。此時,操作數從硬盤中讀出送到主存,然后從主存送到 cache。
數據使用時,一般只在相鄰兩層之間復制傳送,而且總是從慢速存儲器復制到快速存儲器。傳送的單位是一個定長塊,因此需要確定定長塊的大小,并且在相鄰兩層間建立塊之間的映射關系。
在我們接觸的嵌入式系統中,具體的存取時間和存儲容量的大小可能和上圖不符,但是不同層級之間的量級對比還是一致的。
3. 為什么需要 Cache?
由于 CPU 和主存所使用的半導體器件工藝不同,兩者速度上的差異導致快速的 CPU 等待慢速的存儲器,為此需要想辦法提高 CPU 訪問主存的速度。除了提高 DRAM 芯片本身的速度和采用并行結構技術以外,加快 CPU 訪存速度的主要方式之一是在 CPU 和主存之間增加高速緩沖器,也就是我們主角 Cache。
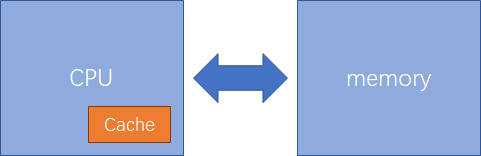
Cache 位于 CPU 和內存之間,可以節省 CPU 從外部存儲器讀取指令和數據的時間。
4. 基本概念
程序訪問的局部性
對大量典型程序運行情況分析的結果表明,在較短的時間間隔內,程序產生的地址往往集中在存儲空間的一個很小范圍,這種現象稱為程序訪問的局部性。這種局部性可細分為時間局部性和空間局部性。時間局部性是指被訪問的某個存儲單元在一個較短的時間間隔很可能又被訪問。空間的局部性是指訪問的某個存儲單元的臨近單元在一個較短的時間間隔內很可能也被訪問。
Instruction Cache
指令 cache 只被用于緩存指令,從外部存儲器讀取指令需要很長時間,如果外部存儲器是 flash,那么 CPU 可能需要 50-100ns 才能獲得指令。
Data Cache
數據 cache 只被用于緩存數據,和指令 cache 類似,CPU 要花費很長時間才能從外部的 SRAM 或者 SDRAM 取回數據。
5. 工作原理
cache 是一種小容量高速緩沖存儲器,由快速的 SRAM 組成,直接制作在 CPU 芯片內,速度較快,幾乎與 CPU 處于同一個量級。在 CPU 和主存之間設置 cache,總是把主存中被頻繁訪問的活躍程序塊和數據塊復制到 cache 中。由于程序訪問的局部性,大多數情況下,CPU 可以直接從 cache 中直接取得指令和數據,而不必訪問慢速的主存。
為了方便 cache 和主存間交換信息,cache 和主存空間都被劃分為相等的區域。例如將主存中一個 512 個字節的區域稱作一個塊(block),cache 中存放一個主存塊的區域稱作行(line)。
cache 的行有效位
系統啟動時,每個 cache 行都為空,其中的信息無效,只有 cache 行中裝入了主存塊之后才有效。為了說明 cache 行中的信息是否有效,某一個行都有一個有效位。通過將一行的有效位清零來淘汰這一行中所存儲的主存快的操作稱為沖刷,也就是我們常說的刷 cache。
CPU 在 cache 中的訪問過程
在 CPU 執行程序過程中,需要從主存取指令或寫數據時,先檢查 cache 中有沒有要訪問的信息,若有,就直接在 cache 中讀寫,而不用訪問主存儲器。若沒有,再從主存中把當前訪問信息所在的一個一個主存塊復制到 cache 中。因此,cache 中的內容是主存中部分內容的副本。下圖展示了帶 cache 的 CPU 執行一次訪存操作的過程。
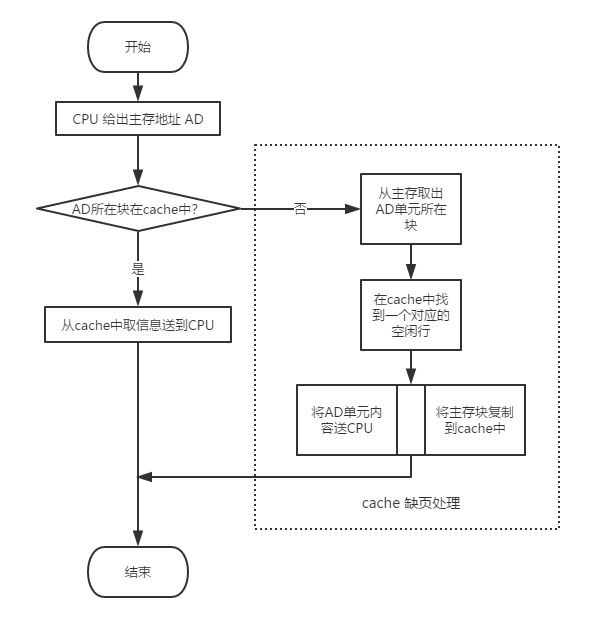
cache 與主存的平均訪問時間
如上圖所示的訪存過程中,需要判斷所訪問的信息是否在 cache 中。若 CPU 訪問單元的主存塊在 cache 中,則稱cache 命中(hit),命中的概率稱為命中率 p(hit rate)。若不在 cache 中,則為不命中(miss),其概率為缺失率(miss rate)。命中時,CPU 在 cache 中直接存取信息,所用的時間開銷就是cache 的訪問時間 Tc,稱為命中時間。缺失時,需要從主存讀取一個主存塊送 cache,并同時將所需信息送 CPU,因此所用時間為主存訪問時間 Tm,和cache 訪問時間 Tc之和。通常把從主存讀入一個主存塊到 cache 的時間Tm 稱為缺頁損失。
CPU 在 cache 和主存層次的平均訪問時間為:
Ta = p * Tc + (1 - p) * (Tm + Tc) = Tc + (1 - p) * Tm
由于程序訪問的局部性特點,cache 的命中率可以達到很高,接近于 1。因此,雖然缺頁損失所耗費的時間遠遠大于命中時間,但最終的平均訪問時間仍可接近 cache 的訪問時間。
cache 的映射方式
cache 行中的信息取自主存中的某個塊。將主存塊復制到 cache 行時,主存塊和 cache 行之間必須遵循一定的映射規則。這樣 CPU 在要訪問某個主存單元時,可以依據映射規則到 cache 對應的行中查找要訪問的信息,而不用在整個 cache 中查找。
根據不同的映射規則,主存塊和 cache 行之間有以下三種映射方式。
目前我們常見的 CPU 一般都采用的組相連的映射方式,組相連的映射方式將前兩種映射方式取長補短,獲得了優異的性能和較低的硬件實現難度。在這里不再展開仔細描述,感興趣的小伙伴可以通過搜索閱讀相關內容來了解其中的細節。
直接映射(direct):每個主存塊映射到 cache 的固定行中。
全相連映射(full associate):每個主存塊映射到 cache 的任意行中。
組相連映射(set associate):每個主存塊映射到 cache 的固定組的任意行中。
值得注意的是,cache 對程序員在編寫高級或低級語言程序時是透明的,因此程序員無需了解 cache 是否存在或者如何設置,感覺不到 cache 的存在。但是對 cahche 的深入了解有助于編寫出高效的程序!
-
cpu
+關注
關注
68文章
10855瀏覽量
211594 -
Cache
+關注
關注
0文章
129瀏覽量
28332
原文標題:Cache 的基本概念與工作原理
文章出處:【微信號:RTThread,微信公眾號:RTThread物聯網操作系統】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
關于cache和cache_line的一個概念問題
操作系統原理基本概念
介紹SRv6獨有的工作原理和相關概念
變頻器&逆變器工作原理基本概念
Cache的工作原理
工業機器人傳感器的測量基本概念和工作原理與傳感器應用的資料說明






 工商網監
工商網監
評論