 2019年冬季CS224N最新課程:基于深度學習的自然語言處理
2019年冬季CS224N最新課程:基于深度學習的自然語言處理
本筆記基于斯坦福大學2019年冬季CS224N最新課程:基于深度學習的自然語言處理,希望可以接觸到最前沿的進展。
主要內容
這一節主要討論自然語言處理中的旗艦任務:機器翻譯。
神經機器翻譯之前機器翻譯早期機器翻譯:1950s統計機器翻譯:1990s-2010s對齊很復雜對齊學習SMT解碼SMT特點神經機器翻譯序列到序列模型用途廣泛條件語言模型NMT訓練貪心解碼窮舉搜索解碼柱搜索解碼終止條件最終修正NMT優點NMT缺點機器翻譯評測機器翻譯進展NMT仍然存在問題NMT研究仍在繼續注意力序列到序列的瓶頸問題注意力注意力很厲害注意力應用廣泛注意力變體下節預告閱讀更多
神經機器翻譯之前
講神經機器翻譯之前,先來看看機器翻譯的歷史。
機器翻譯
機器翻譯任務是將一種語言(原始語言)的句子x翻譯成另一種語言(目標語言)的句子y。
例如:
x: L'homme est né libre, et partout il est dans les fers
y: Man is born free, but everywhere he is in chains
早期機器翻譯:1950s
機器翻譯研究始于1950年初。
1954 年,美國喬治敦大學(Georgetown University) 在 IBM 公司協同下, 用 IBM-701計算機首次完成了英俄機器翻譯試驗,向公眾和科學界展示了機器翻譯的可行性,從而拉開了機器翻譯研究的序幕。
中國開始這項研究也并不晚, 早在1956年,國家就把這項研究列入了全國科學工作發展規劃,課題名稱是“機器翻譯、自然語言翻譯規則的建設和自然語言的數學理論”。1957 年,中國科學院語言研究所與計算技術研究所合作開展俄漢機器翻譯試驗,翻譯了9 種不同類型的較為復雜的句子。
早期機器翻譯大都基于規則,并使用雙語詞典。
統計機器翻譯:1990s-2010s
核心思想:從數據中學習概率模型。
假定翻譯方向是從法語到英語。
給定法語句子x,那么目標就是找到最佳英語句子y:
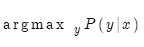
也就是找到概率分布P。
通常的做法是使用貝葉斯法則,將上式分解成兩項,便于分別學習: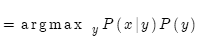
其中:
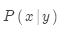 是翻譯模型,是關于詞語和短語如何翻譯的模型,考查的是忠實度。翻譯模型從平行數據中學習;
是翻譯模型,是關于詞語和短語如何翻譯的模型,考查的是忠實度。翻譯模型從平行數據中學習;
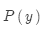 是語言模型,是關于如何書寫正確英語的模型,考查的是流暢度。語言模型從單語數據中學習。之前已經學過。
是語言模型,是關于如何書寫正確英語的模型,考查的是流暢度。語言模型從單語數據中學習。之前已經學過。
那么如何學習翻譯模型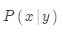 ?
?
首先需要平行語料庫。
舉世聞名的羅賽塔石碑就是一個早期的平行語料庫。
羅賽塔石碑
在這個石碑上,同一文本被書寫成了三種語言。而這恰恰成了19世紀人們破解古埃及文的關鍵。如果你在倫敦,不妨親自去大英博物館看一看這個平行語料庫。
當然,我們需要的平行語料庫要大得多,遠非一塊石碑所能寫下。
有了大規模平行語料庫后,如何從中學習翻譯模型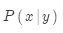 ?
?
方法是進一步分解。實際上我們希望考慮:
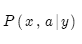
其中a是對齊,即法語句子x和英語句子y之間的詞語對齊。
所謂對齊就是句對之間詞語的對應。
對齊很復雜
無對應
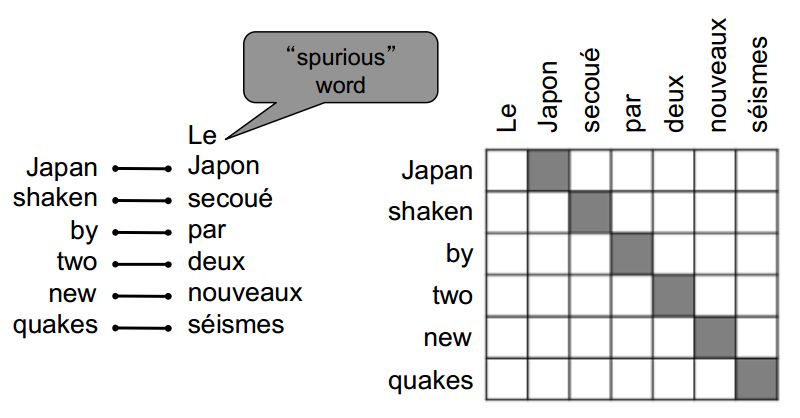
無對應
多對一
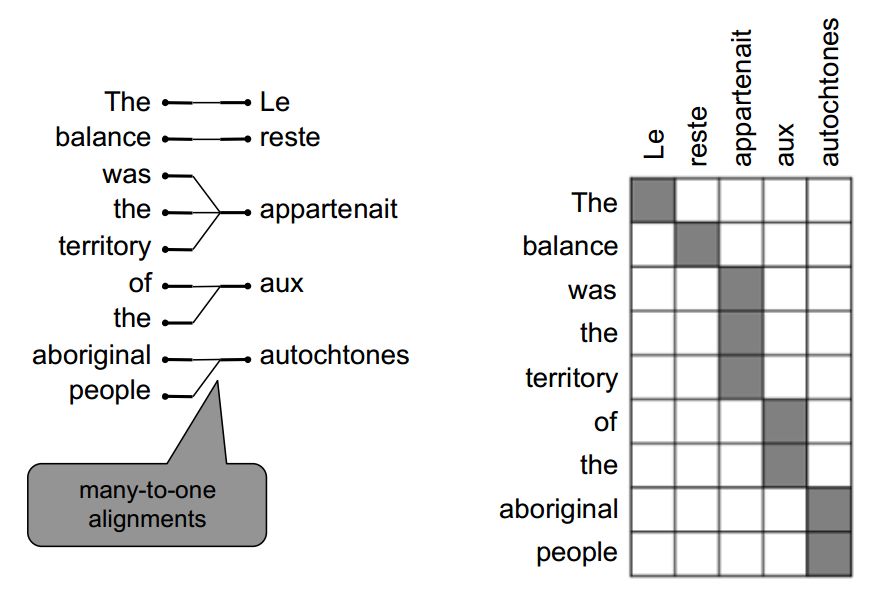
多對一
一對多(這樣的詞稱為能產詞)
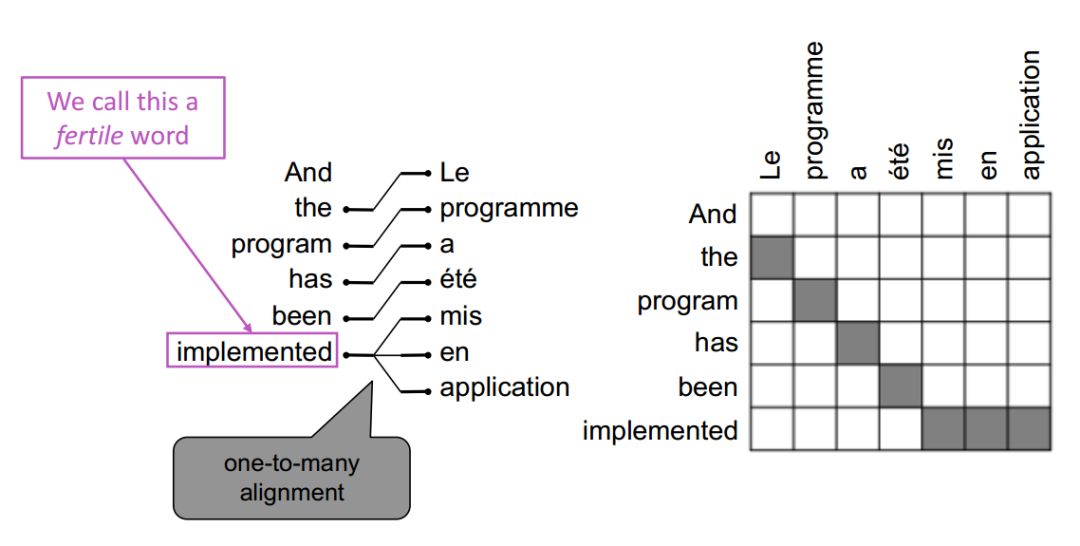
一對多
一對很多
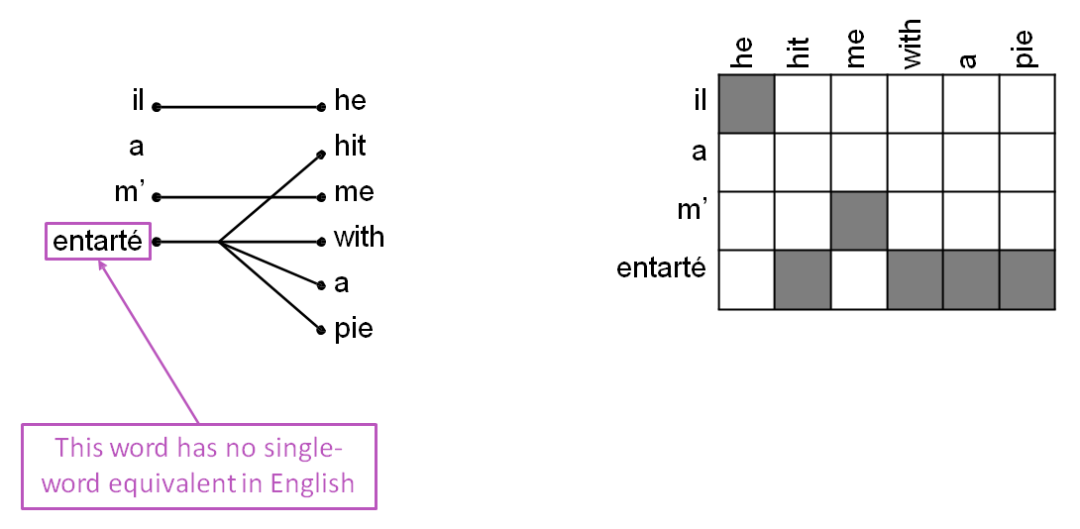
一對很多
多對多(短語對齊)
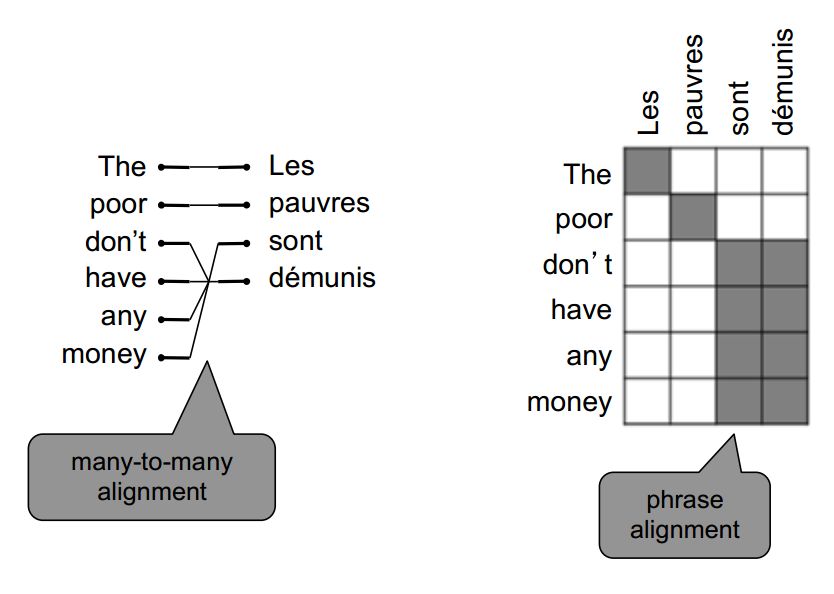
多對多
對齊學習
學習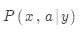 就是學習多種因素的組合,包括:
就是學習多種因素的組合,包括:
詞語對齊的概率(同時取決于詞語在句子中的位置)
詞語具有特定能產度(對應詞的個數)的概率
等等
所有這些都是從平行數據中學習。
SMT解碼
有了翻譯模型和語言模型后,如何計算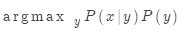 ?
?
一種暴力解法就是枚舉每一個可能的y,然后計算概率。很明顯,這樣做的計算代價非常高。
解決辦法:使用啟發式搜索算法找到最佳翻譯,忽略掉概率非常低的翻譯。
這一過程稱為解碼。
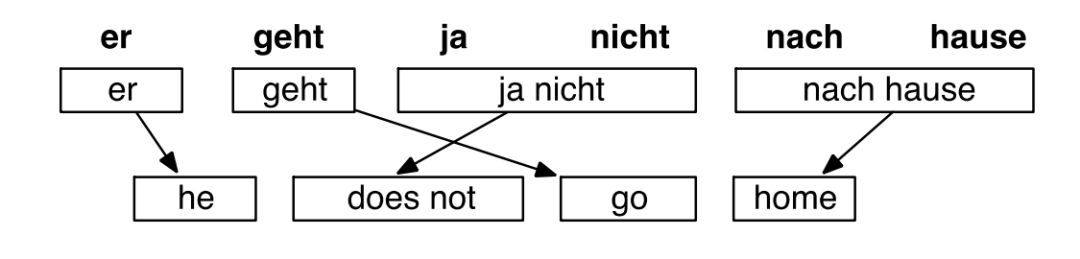
SMT示例
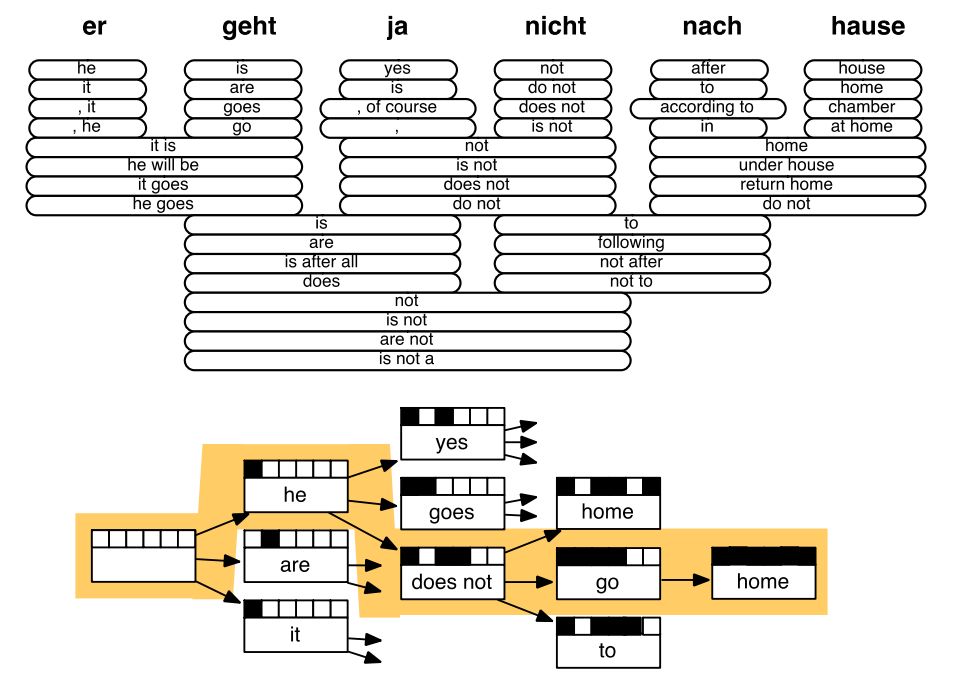
SMT解碼示例
SMT特點
曾經是個非常熱門的研究領域
最好的系統都極其復雜
有很多單獨設計的子系統
大量的特征工程
需要收集和整理大量的外部資源,例如平行短語表
需要大量人力維護
直到2014年,神經機器翻譯橫空出世!
神經機器翻譯
神經機器翻譯(NMT)是一種只使用神經網絡做機器翻譯的方法。
這種神經網絡稱為序列到序列結構(seq2seq),包括兩個RNN。
序列到序列模型
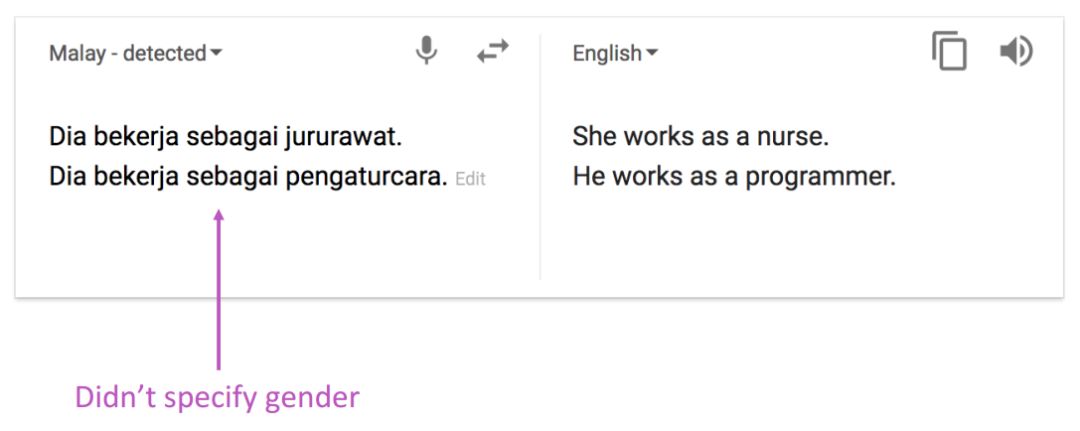
序列到序列模型由兩個RNN組成:編碼器RNN和解碼器RNN。
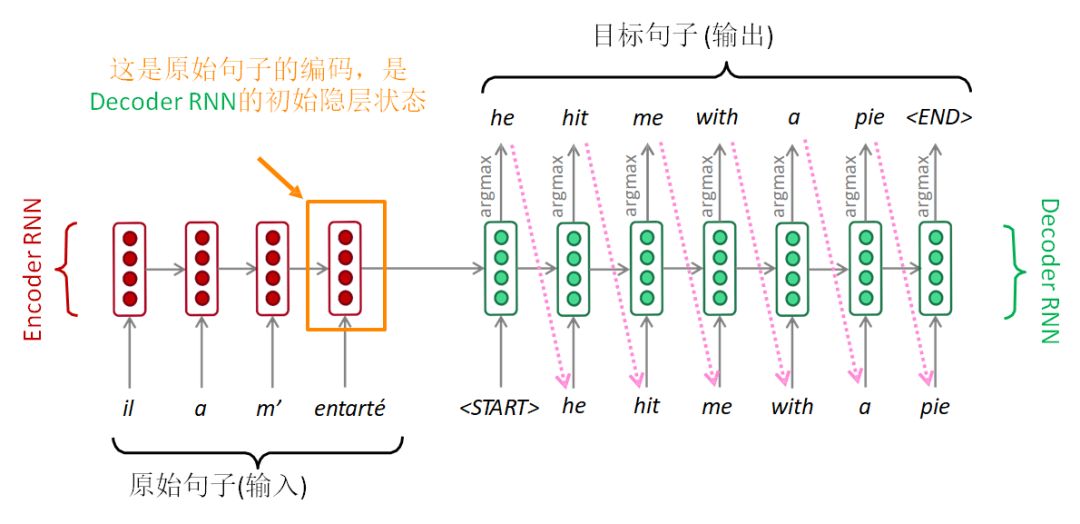
Seq2Seq
編碼器RNN通過最后的隱層狀態對原始句子進行編碼。原始句子的編碼就是解碼器RNN的初始隱層狀態。這相當于將原始句子編碼傳入解碼器RNN。
解碼器RNN相當于語言模型,根據前面的編碼一步一步來生成目標句子。
注意:上圖顯示的是測試模型,解碼器的輸出作為下一步的輸入,進而生成文本。
另外,每種語言各有一個單獨的詞表和詞嵌入。
用途廣泛
序列到序列模型不僅僅用于機器翻譯。很多其他NLP任務本質上也是序列到序列。
摘要生成(長文本-->短文本)
對話(上一句話-->下一句話)
句法分析(輸入文本-->輸出句法分析序列)
代碼生成(自然語言-->Python代碼)
條件語言模型
序列到序列模型屬于條件語言模型。
說它是語言模型,因為解碼器所做的就是預測目標句子y的下一個詞
說它是條件的,因為解碼器的預測是以原始句子x為條件的
NMT的強大之處在于它直接計算概率P(y|x):
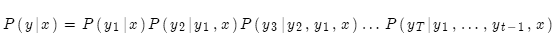
即給定原始句子x和當前所有的目標詞語,計算下一個目標詞語。
NMT訓練
如何訓練一個NMT系統?
首先要有一個大的平行語料庫。
將原始句子送入編碼器RNN,然后將目標句子送入解碼器RNN,同時編碼器RNN最終隱層狀態會傳入解碼器RNN的初始隱層狀態。在解碼器RNN的每一步會產生下一個單詞的概率分布,進而通過交叉熵計算損失。將每一步損失加總取平均,就得到了整個句子的損失。
如下圖所示:
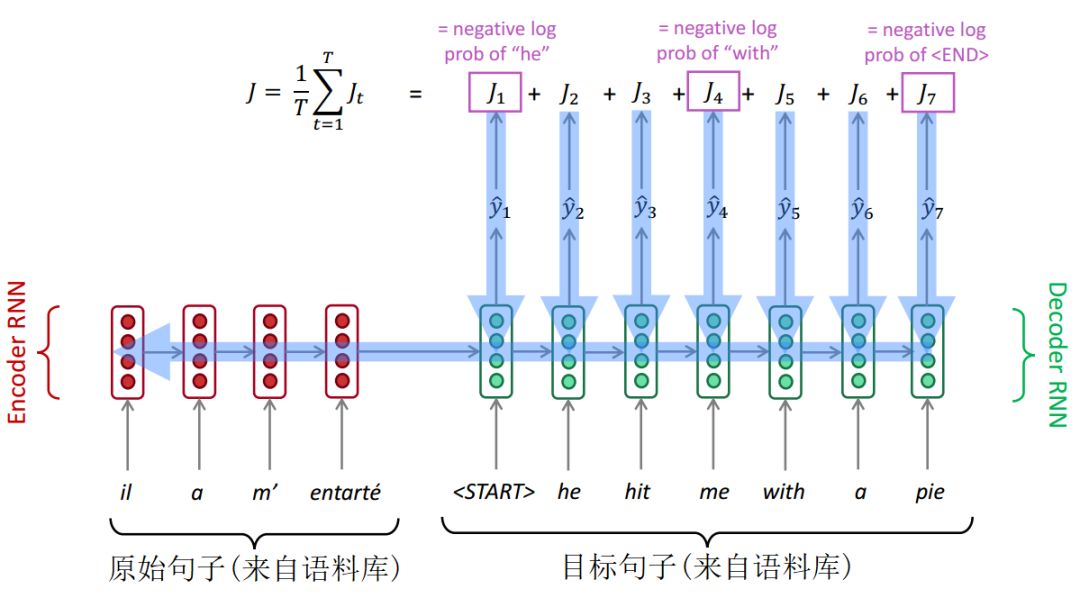
NMT訓練
Seq2Seq作為整個系統進行優化。反向傳播方式為"端到端",一端連接最終損失,一端連接編碼器RNN的開始。反向傳播穿過了整個系統。
注意,訓練期間,解碼器的輸入來自語料庫。解碼器每一步的輸出僅僅用于計算損失,不會送入下一步輸入。
貪心解碼
我們看到,對解碼器的每一步輸出求argmax,就能生成(或解碼)目標句子。
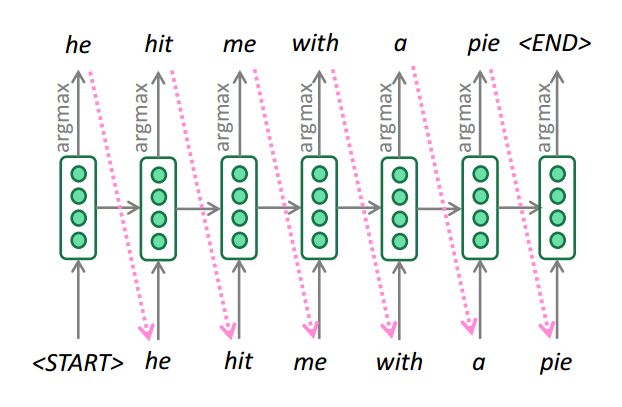
貪心解碼
這就是貪心解碼(在每一步取概率最高的詞)
貪心解碼的問題是每一步取概率最高的詞并不必然導致整個句子概率最高!
貪心解碼無法取消上一步決策。
例如,輸入是il a m’entarté (he hit me with a pie )
he_
he hit_
he hit a___
糟糕!解碼到第3步時,概率最高的詞是a,這不是想要的結果,現在想回到上一步,怎么辦?
這就是貪心解碼的問題,無法返回上一步。
窮舉搜索解碼
我們的目標其實是找到使下述概率最大的翻譯y(長度T):
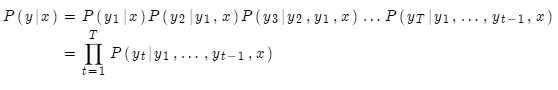
我們可以計算所有可能的序列y,這意味著解碼器在每一步t,都要追蹤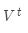 個可能的未完成翻譯。計算代價非常高。我們需要高效的搜索算法。
個可能的未完成翻譯。計算代價非常高。我們需要高效的搜索算法。
柱搜索解碼
核心思想:在解碼器的每一步,只追蹤k個概率最高的翻譯(亦稱為假設)。k就是柱搜索的大小(一般是5-10)。
我們使用對數概率作為假設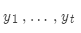 的分值:
的分值:
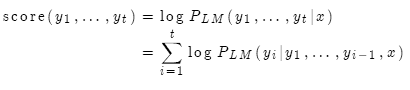
分值都是負數,數值越大越好。我們只搜索分值高的假設,在每一步,只追蹤前k個。

柱搜索解碼
柱搜索不能保證找到最優解,但效率要遠遠高于窮舉搜索。
終止條件
在貪心搜索中,解碼的終止條件是
例如:
在柱搜索中,不同的假設可能會在不同的時間步產生
如果一個假設已經產生
繼續通過柱搜索探索其他假設。
通常,柱搜索的終止條件是:
達到時間步T(T是事先預定的數值)
已經得到至少n個完整的假設(n是事先預定的數值)
最終修正
現在我們有了完成的假設列表。如何選擇分值最高的一個?
列表中每一個假設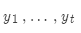 都有一個分值
都有一個分值
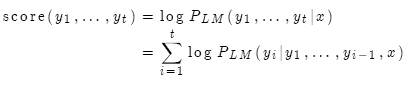
問題在于假設越長,分值越低。
修正:用長度作歸一化。
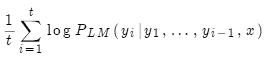
NMT優點
與SMT相比,NMT具有很多優點:
效果更好
更流暢
更充分利用上下文
更充分利用短語相似度
單個神經網絡,端到端優化
無須針對子系統進行逐個優化
人工參與更少
無特征工程
適用于所有語言對
NMT缺點
與SMT相比:
NMT可解釋性差
難以調試
NMT難以控制
無法指定翻譯規則或原則
安全問題
機器翻譯評測
目前比較流行的自動評測方法是IBM提出的BLEU(bilingual evaluation understudy)算法。
BLEU的核心思想就是機器翻譯的譯文越接近人工翻譯的結果,它的翻譯質量就越高。BLEU如何定義機器翻譯與參考譯文之間的相似度?
n元文法精度(通常是一、二、三、四元文法)
對過于簡短的譯文作懲罰
BLEU非常有用,但并非完美無缺
一句話有多種有效的翻譯方式
如果與人工翻譯的n元文法重疊度低,即使翻譯再好,BLEU也會偏低
機器翻譯進展
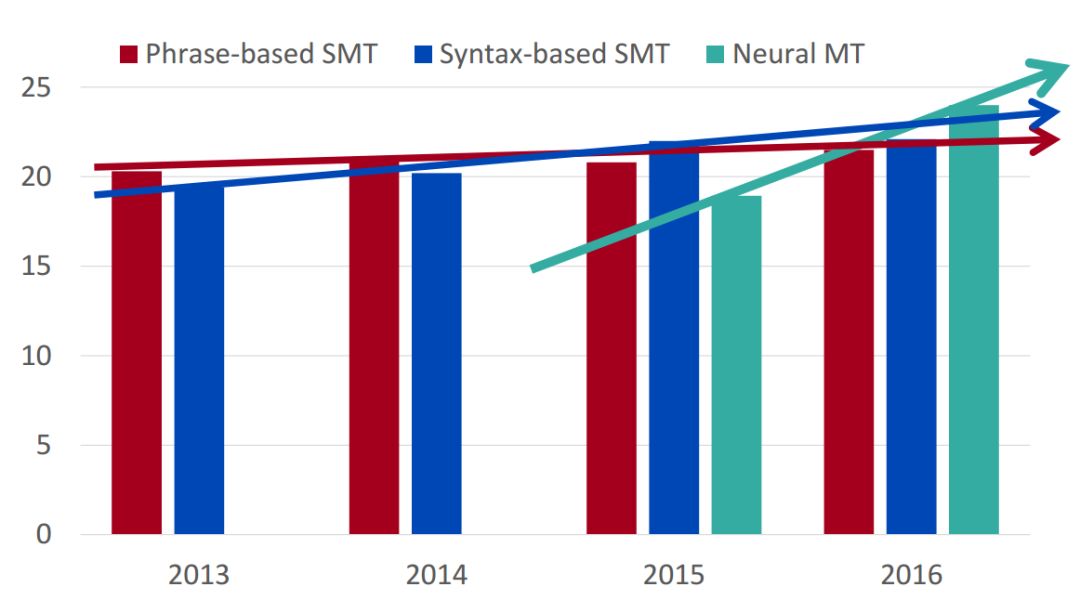
機器翻譯進展
2014年,神經機器翻譯只是非常邊緣的研究范疇;但在2016年,神經機器翻譯已經成為主流的標準方法。
2014年,第一篇seq2seq論文發布
2016年,谷歌翻譯從SMT切換到NMT
僅僅兩年,NMT實現驚人逆襲!
SMT系統,需要數以百計的工程師,經年累月,方能搭建;而NMT系統,只需幾個工程師幾個月內就能搭建,而且效果反超SMT。
NMT仍然存在問題
NMT雖然大獲成功,但仍然存在很多問題:
未登錄詞
訓練數據和測試數據領域不匹配
長文本上下文問題
有些語言對數據量不夠
利用常識仍然困難

沒有常識
NMT學到了數據中的偏見
數據偏見
不可解釋的系統會做一些莫名其妙的事情
不可解釋
NMT研究仍在繼續
NMT是深度自然語言處理的旗艦任務。
NMT研究引領了NLP深度學習的很多創新
2019年,NMT研究仍在蓬勃發展
研究人員發現了上面標準seq2seq的很多改進方法,其中有一項改進如此不可或缺,已經成為新的標準方法。那就是Attention(注意力)
注意力
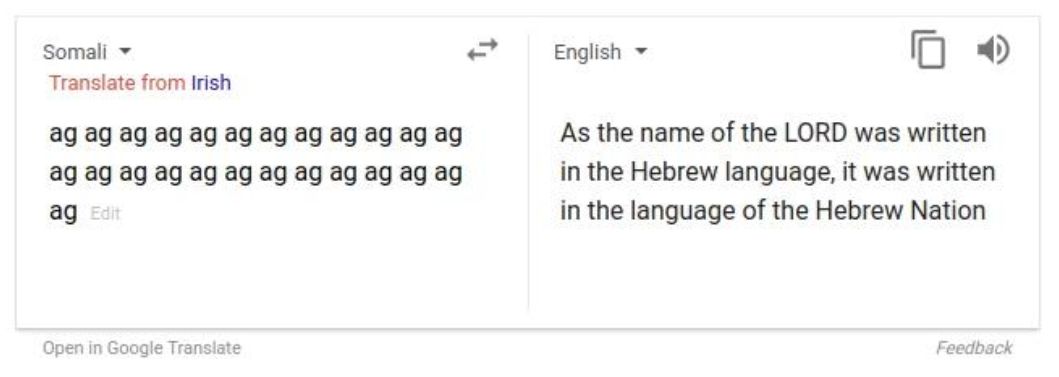
序列到序列的瓶頸問題
信息瓶頸問題
在編碼器RNN的最后一步,這里的隱層狀態需要獲得原始句子的所有信息。這就存在信息瓶頸的問題。
注意力
注意力的核心思想是在解碼器的每一步,都與編碼器直接相連,以便對原始句子的特定部分進行關注。先上圖。
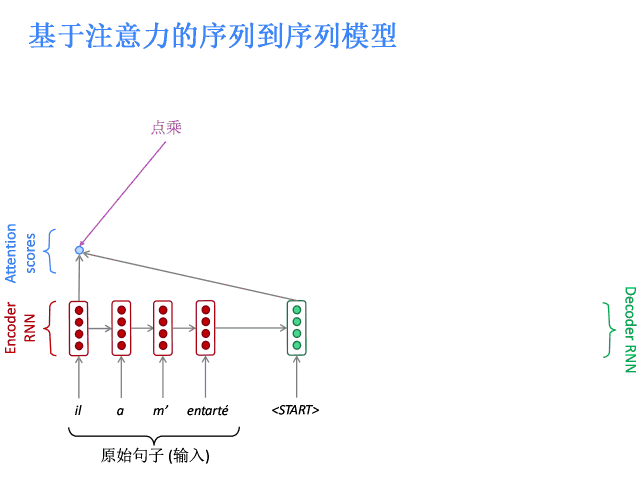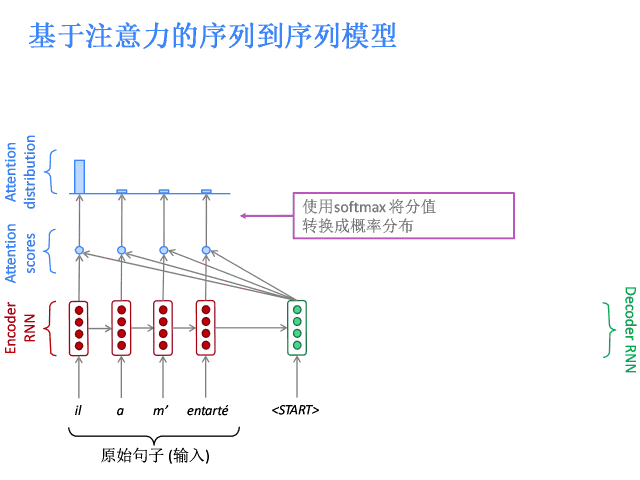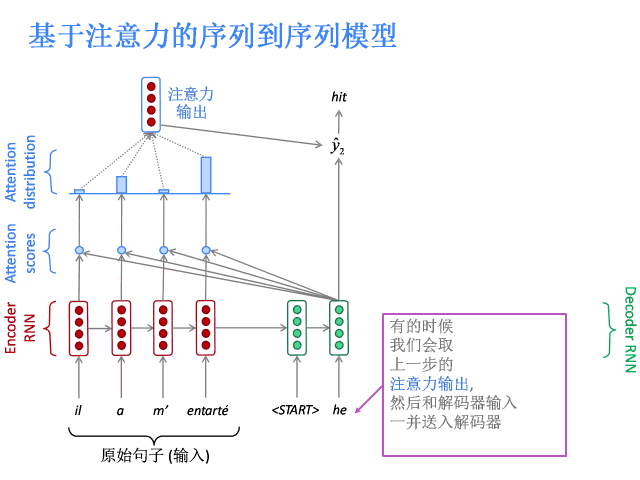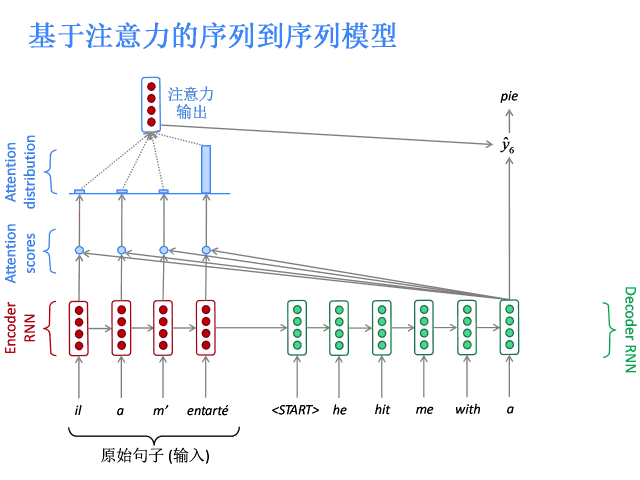
基于注意力的序列到序列模型
編碼器隱層狀態為:
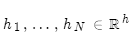
到第t時間步,解碼器的隱層狀態為:
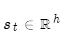
此步的注意力分值為:
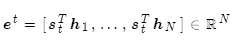
使用softmax獲得該步的注意力分布:
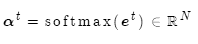
然后使用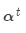 對編碼器的隱層狀態加權求和,獲得注意力輸出
對編碼器的隱層狀態加權求和,獲得注意力輸出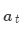 :
:
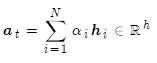
最后,將注意力輸出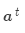 和編碼器隱層狀態
和編碼器隱層狀態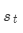 拼接:
拼接:
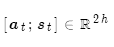
后續過程就與普通Seq2Seq一樣了。
注意力很厲害
注意力允許解碼器關注原始句子的特定部分,顯著提高了NMT效果
注意力允許解碼器直接查看原始句子,解決了信息瓶頸的問題
注意力提供了遙遠狀態的捷徑,有助于緩解梯度消失的問題
注意力提供了某種可解釋性:
查看注意力分布,可以了解解碼器所關注的內容
免費自動實現了軟對齊,無需單獨訓練一套對齊系統
注意力應用廣泛
已經看到,注意力可以大大改善機器翻譯的效果。
然而不僅于此,注意力同樣適用于很多其他神經網絡結構和很多其他任務。
注意力的廣義定義:
給定一組向量值(value)和一個向量查詢(query),注意力就是根據向量查詢來計算向量值加權求和。
例如在seq2seq+attention模型中,每個解碼器隱層狀態就是查詢,它會去關注編碼器的所有隱層狀態(值)。
加權求和就是對數值中的信息進行選擇性摘取,查詢決定了需要關注哪些數值。
注意力可根據某些表示(查詢)將任意一組表示(值)轉換為固定大小的表示。
注意力變體
假設有若干值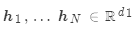 和一個查詢
和一個查詢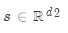 。
。
注意力通常包括:
計算注意力分值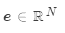
用softmax獲得注意力分布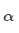 :
:
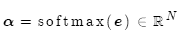
使用注意力分布計算值的加權求和,這就是注意力輸出(亦稱為語境向量):
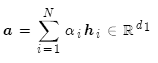
這里注意力分值計算有若干種方法:
基本點乘: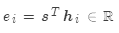
矩陣乘法: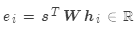 ,其中
,其中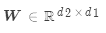 是權重矩陣
是權重矩陣
加法: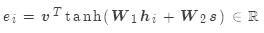
其中:
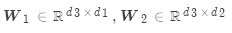 是權重矩陣
是權重矩陣
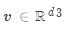 是權重向量
是權重向量
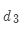 是注意力的維度,是超參數
是注意力的維度,是超參數
總結一下:我們學習了機器翻譯的歷史、神經機器翻譯的序列到序列模型和注意力機制。
-
機器翻譯
+關注
關注
0文章
139瀏覽量
14914 -
深度學習
+關注
關注
73文章
5507瀏覽量
121272 -
自然語言處理
+關注
關注
1文章
619瀏覽量
13581
原文標題:機器翻譯、Seq2Seq、注意力(CS224N-2019-8)
文章出處:【微信號:gh_b11486d178ef,微信公眾號:語言和智能】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【推薦體驗】騰訊云自然語言處理
什么是人工智能、機器學習、深度學習和自然語言處理?
從語言學到深度學習NLP,一文概述自然語言處理
深度學習與自然語言處理的工作概述及未來發展
自然語言處理的優點有哪些_自然語言處理的5大優勢
斯坦福AI Lab主任、NLP大師Manning:將深度學習應用于自然語言處理領域的領軍者
自然語言處理(NLP)的學習方向
基于深度學習的自然語言處理對抗樣本模型





 工商網監
工商網監
評論