 Reddit熱議MIT新發現 對抗樣本是有意義的數據特征
Reddit熱議MIT新發現 對抗樣本是有意義的數據特征
對抗樣本不是Bug, 它們實際上是有意義的數據分布特征。來自MIT的最新研究對神經網絡的對抗樣本問題給出了非常新穎的解釋和實驗論證。
“對抗樣本”(adversarial examples)幾乎可以說是機器學習中的一大“隱患”,其造成的對抗攻擊可以擾亂神經網絡模型,造成分類錯誤、識別不到等錯誤輸出。
對抗樣本揭示了神經網絡的脆弱性和不可解釋性。例如,一張簡單的涂鴉貼紙(對抗性補丁)就可能“迷惑”自動駕駛系統,導致AI模型對交通標志被錯誤分類,甚至將自動駕駛系統 “騙” 進反車道;也可能“欺騙”AI檢測系統,讓最先進的檢測系統也無法看到眼前活生生的人。
但是,對抗樣本真的是bug嗎?
來自MIT的多位研究人員給出了否定的回答。他們通過一系列嚴謹的實驗,證明:對抗樣本不是Bug, 它們是特征(Adversarial Examples Are Not Bugs, They Are Features)。

這篇觀點新穎的論文今天在Reddit上引起熱議,讀者紛紛表示論文“巧妙又簡單,怎么沒人早些想到這個方向”,“非常有趣的工作”……
實驗的一個理念圖
作者表示:“我們證明了對抗性樣本并不是奇怪的像差或隨機的偽影,相反,它們實際上是有意義的數據分布特征(即它們有助于模型泛化),盡管這些特征不易覺察。”
研究人員通過一系列實驗證明:
(a)你可以根據嵌入到錯誤標記的訓練集中的這些不易覺察的特征學習,并泛化到真正的測試集;
(b)你可以刪除這些不易覺察的特征,并“穩健地”泛化到真正的測試集(標準訓練)。
接下來,我們解讀下這篇論文。
一顆叫做Erm的遙遠星球,生活著Nets族人
過去幾年里,對抗樣本在機器學習社區中得到了極大的關注。關于如何訓練模型使它們不易受到對抗樣本攻擊的工作有很多,但所有這些研究都沒有真正地面對這樣一個基本問題:為什么這些對抗樣本會出現?
到目前為止,流行的觀點一直是,對抗樣本源于模型的“怪異模式”,只要我們在更好的訓練算法和更大規模的數據集方面取得足夠的進展,這些bug最終就會消失。常見的觀點包括,對抗樣本是輸入空間高維的結果,或者是有限樣本現象的結果。
本文將提供一個新的視角,解釋出現對抗樣本的原因。不過,在深入討論細節之前,讓我們先給大家講一個小故事:
一顆叫做Erm的星球
我們的故事開始于Erm,這是一個遙遠的星球,居住著一個被稱為Nets的古老的外星種族。
Nets是一個奇怪的物種:每個人在社會等級中的位置取決于他們將32×32像素圖像(對Nets來說毫無意義)分類為10個完全任意的類別的能力。
這些圖像來自一個名為See-Far的絕密數據集,Nets族的居民們是無法事先看到數據集中的圖像的。
隨著Nets人的成長和智慧的增長,他們開始在See-Far中發現越來越多的模式。這些外星人發現的每一個新模式都能幫助他們更準確地對數據集進行分類。由于提高分類精度具有巨大的社會價值,外星人為最具預測性的圖像模式賦予了一個名稱——TOOGIT。
一個TOOGIT, 可以高度預測一張 "1" 的圖像。Nets對TOOGIT非常敏感。
最強大的外星人非常善于發現模式,因此他們對TOOGIT在See-Far圖像中的出現極為敏感。
不知何故(也許是在尋找See-Far分類技巧),一些外星人獲得了人類寫的機器學習論文。有一個圖像特別引起了外星人的注意:
一個 "對抗樣本"?
這個圖是比較簡單的,他們認為:左邊是一個“2”,中間有一個GAB pattern,表明圖案是“4”——不出意料,左邊的圖片添加一個GAB,導致了一個新圖像,在Nets看來,這個新圖像就對應于“4”類別。
根據論文,原始圖像和最終圖像明明完全不同,卻被分類為相同。Nets人對此無法理解。困惑之余,他們翻遍了人類的論文,想知道還有哪些有用的模式是人類沒有注意到的……
我們可以從Erm星球學到什么?
正如Erm這個名字所暗示的,這個故事不是只想說外星人和他們奇怪的社會結構:Nets發展的方式喻指我們訓練機器學習模型的方式。
尤其是,我們最大限度地提高了準確性,而沒有納入關于分類的類、物理世界或其他與人類相關的概念的許多先前背景。
這個故事的結果是,外星人能夠意識到,人類認為毫無意義的對抗性擾動(adversarial perturbation),實際上是對See-Far分類至關重要的模式。因此,Nets的故事應該讓我們思考:
對抗性擾動真的是不自然、而且沒有意義的嗎?
一個簡單的實驗
為了研究這個問題,我們先做了一個簡單的實驗:
我們從一個標準數據集(如CIFAR10)的訓練集中的圖像開始:
我們從每個(x, y)到“下一個”類y+1(或0,如果y是最后一個類),合成一個有針對性的對抗性樣本
然后,我們通過將這些對抗性樣本與其對應的目標類進行標記,構建一個新的訓練集:
現在,由此產生的訓練集與原始訓練集相比,不知不覺地受到了干擾,但是標簽已經改變了——因此,對人類來說,它的標簽看起來是完全錯誤。事實上,這些錯誤的標簽甚至與“置換”假設一致(即每只狗都被貼上貓的標簽,每只貓都被貼上鳥的標簽,等等)。
我們用“錯誤標記的數據集”來訓練一個新的分類器(不一定與第一個分類器的架構相同)。這個分類器在原始(未修改的)測試集(即標準CIFAR-10測試集)上的表現如何呢?
值得注意的是,我們發現得到的分類器實際上只有中等的精度(例如CIFAR上,精度只有44%)!盡管訓練輸入僅通過不可察覺的擾動與它們的“真實”標簽相關聯,并且與通過所有可見特性匹配的不同(現在是不正確的)標簽相關聯。
這是怎么回事?
對抗樣本概念模型
剛剛描述的實驗建立了標準模型的對抗性擾動,作為目標類的模式預測。也就是說,僅訓練集中的對抗性干擾就能對測試集做出適度準確的預測。
從這個角度來看,人們可能會想:也許這些模式與人類用來對圖像進行分類的模式(比如耳朵、胡須、鼻子)并沒有本質上的不同!
這正是我們的假設——存在著各種各樣的輸入特征可以預測標簽,而其中只有一些特征是人類可以察覺的。
更準確地說,我們認為數據的預測特征可以分為“robust”和“non-robust”特征。
Robust features(魯棒性特征)對應于能夠預測真實標簽的模式,即使在某些人為預先定義的擾動集造成對抗性擾動的情況下。
相反,non-robust features(非魯棒性特征)對應的模式雖然具有預測性,但在預先定義的擾動集會被攻擊者“翻轉”,造成指示的分類錯誤。(正式的定義請參閱論文)
由于我們總是只考慮不影響人類分類性能的擾動集,所以我們希望人類只依賴于robust features。然而,當目標是最大化 (標準) 測試集的準確性時,non-robust features 可以和 robust features 一樣有用。
事實上,這兩種類型的特性是完全可以互換的。如下圖所示:
從這個角度來看,本文中的實驗描述了一些相當簡單的過程。在原始訓練集中,輸入的魯棒性和非魯棒性特征都是可以預測的。當實驗中加入小的對抗性擾動時,不能顯著影響魯棒性特征,但對非魯棒性特征的改變是允許的。例如,每只狗的圖像現在都保留了狗的魯棒性特征(因此這些圖像在我們看來是狗),但非魯棒性特征更接近貓。
在重新標記訓練集之后,我們的設置使魯棒性特征實際上指向了錯誤的方向(即具有 “狗” 的魯棒性特征的圖片被標記為 “貓”),在這種情況下,實際上只有非魯棒特征為泛化提供了正確的指導。
總之,魯棒和非魯棒特征都可以用于預測訓練集,但只有非魯棒性特征才會導致對原始測試集的泛化:
因此,在該數據集上訓練的模型實際上能夠泛化到標準測試集的事實表明:存在足以用其實現良好泛化的非魯棒性特征。而且,即使有強大的魯棒性預測特征的存在,深度神經網絡仍要依賴于這些非魯棒性特征,。
高魯棒性模型能否學習高魯棒性特征?
實驗證明,對抗性擾動不是毫無意義的信號,而是直接對應于對泛化至關重要的擾動性特征。同時,關于對抗性示例相關文章顯示,通過強大的優化,可以獲得面向對抗性擾動更具魯棒性的模型。
因此,一個自然而然的問題就是:能否驗證高魯棒性模型實際上依賴于高魯棒性的特征?為了測試這一點,我們建立了一種方法,盡量將輸入僅限于模型敏感的特征(對于深度神經網絡而言,就是倒數第二層激活的特征)。由此創建一個新的訓練集,該訓練集僅限于包含已經訓練過的高魯棒性模型使用的特征:
然后,我們在沒有對抗訓練的情況下在結果數據集上訓練模型,發現得到的模型具有非常高的準確性和魯棒性!這與標準訓練集的訓練形成鮮明對比,后者訓練出的模型雖然準確,但非常脆弱。
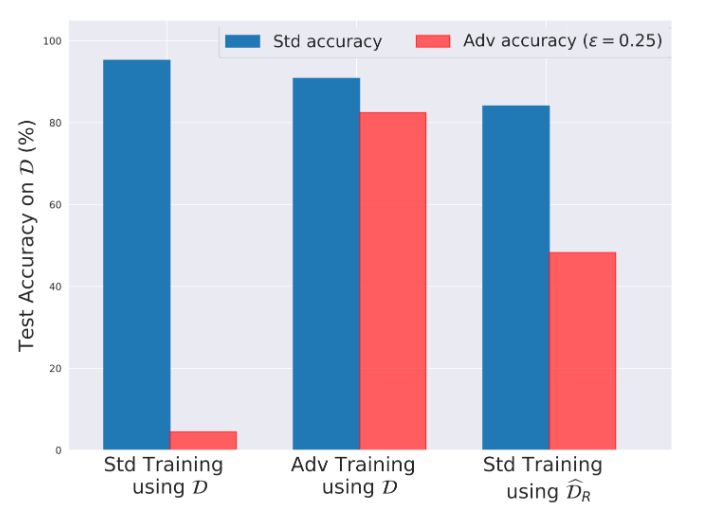
CIFAR-10 測試集(D)上測試的標準精度和魯棒性精度。左:在 CIFAR-10(D)上正常訓練;中:在 CIFAR-10(D)上的對抗性訓練;右:在我們重新構建的數據集上正常訓練。
結果表明,魯棒性(和非魯棒性)實際上可以作為數據集本身的屬性出現。特別是,當我們從原始訓練集中去除了非魯棒性特征時,可以通過標準(非對抗性)訓練獲得高魯棒性的模型。這進一步證明,對抗性實例是由于非魯棒性特征而產生的,而且不一定與標準訓練框架相關聯。
可遷移性
這一變化的直接后果是,對抗性實例的可轉移性不再需要單獨的解釋。具體來說,既然我們將對抗性漏洞視為源自數據集特征的直接產物(而不是訓練單個模型時的個別現象),我們自然希望類似的表達模型也能夠找到并利用這些特征來實現分類精度的提升。
為了進一步研究這個想法,我們研究了在不同架構下對類似非魯棒性特征的學習,與這些特征間的對抗性實例的可轉移性的相關性:
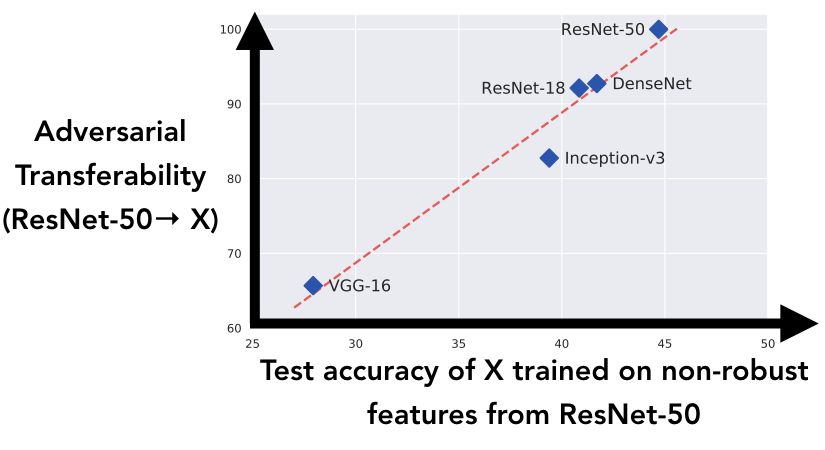
我們生成了在第一個實驗中描述的數據集(用目標類別標記的對抗性實例的訓練集),使用 ResNet-50 構建對抗性實例。我們可以將結果數據集視為將所有 ResNet-50 的非強健功能 “翻轉” 到目標類別上。然后在此數據集上訓練上圖中的五個架構,并在真實測試集上記錄泛化性能:這與測試架構僅用 ResNet-50 的非魯棒性特征進行泛化的程度相對應。
結果表明,正如本文關于對抗性實例的新觀點中所述,模型能夠獲得 ResNet-50 數據集引入的非魯棒性特征,這與 ResNet-50 到標準模型之間的對抗性可轉移性有很強的相關性。
啟示
本文中的討論和實驗將對抗性實例視為純粹以人為中心的現象。從分類任務表現的角度來看,模型沒有理由更偏好魯棒性特征。畢竟,魯棒性的概念是人類指定的。因此,如果我們希望模型主要依賴于魯棒性特征,需要通過將先驗知識結合到框架或訓練過程中來明確解釋這一點。
從這個角度來看,對抗性訓練(以及更廣泛的魯棒性優化)可以被認為是一種將所需的不變性結合到學習模型中的工具。比如,高魯棒性訓練可以被視為通過不斷地 “翻轉” 來破壞非魯棒特征的預測性,從而引導訓練的模型不再依賴非魯棒性特征。
同時,在設計可解釋性方法時,需要考慮標準模型對非魯棒性特征的依賴性。特別是,對標準訓練模型預測的任何 “解釋” 應該選擇要么突出這些特征(會導致對人類而言的意義不明確),要么全部隱藏(會導致不完全忠實于模型的決策過程)。因此,如果我們想要獲得既對人類有意義,又忠實于模型可解釋性方法,那么僅靠訓練后的處理基本上是不行的,還需要在訓練過程中進行必要的干預。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100720
原文標題:Reddit熱議MIT新發現:對抗樣本不是bug,而是有意義的數據特征!
文章出處:【微信號:aicapital,微信公眾號:全球人工智能】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

Reddit測試人工智能問答功能Reddit Answers
騰訊對Reddit進行多次股票拋售
日月光舉辦2023年度最佳供應商頒獎典禮
雙電源無擾動快切裝置的小型化設計是否有意義?

esp32啟用ble后用自己的iOS app能夠發現service,但沒有發現service里面的特征,為什么?
通過強化學習策略進行特征選擇

TLF35584處于待機狀態時,能否通過SPI命令獲取其狀態?
OpenAI與Reddit達成合作,共同推進AI技術發展
OpenAI與Reddit建立合作伙伴關系
Reddit與OpenAI達成合作,引入問答內容及AI功能
消息稱Reddit與谷歌達成協議
干貨!收藏!一文講清楚數據治理到底是什么?





 工商網監
工商網監
評論