") 網(wǎng)絡(luò)處理器的應(yīng)用場景
網(wǎng)絡(luò)處理器的應(yīng)用場景
這一篇談下網(wǎng)絡(luò)處理器。
曾幾何時(shí),網(wǎng)絡(luò)處理器是高性能的代名詞。為數(shù)眾多的核心,強(qiáng)大的轉(zhuǎn)發(fā)能力,定制的總線拓?fù)洌瑢S玫牡闹噶詈臀⒔Y(jié)構(gòu),許多優(yōu)秀設(shè)計(jì)思想沿用至今。Tilera,F(xiàn)reescale,Netlogic,Cavium,Marvell各顯神通。但是到了2018年,這些公司卻大多被收購,新聞上也不見了他們的身影,倒是交換芯片時(shí)不時(shí)冒出一些新秀。
隨著移動(dòng)互聯(lián)網(wǎng)的興起,網(wǎng)絡(luò)設(shè)備總量實(shí)際上是在增加的。那為什么網(wǎng)絡(luò)芯片反而沒聲音了呢?究其原因有幾點(diǎn):
第一, 電信行業(yè)利潤率持續(xù)減少。10年之前,F(xiàn)reescale的65納米雙核處理器,可以賣到40美金。如今同樣性能的28納米芯片,10美金都賣不到。而網(wǎng)絡(luò)處理器的量并不大,低端有百萬片已經(jīng)挺不錯(cuò)了,高端更是可能只有幾萬片。這使得工程費(fèi)用無法均攤到可以忽略的地步,和手機(jī)的動(dòng)輒幾億片沒法比。而單價(jià)上,和服務(wù)器上千美金的售價(jià)也沒法比。這就使得網(wǎng)絡(luò)處理器陷入一個(gè)尷尬境地。
第二, IP模式的興起。利潤的減少導(dǎo)致芯片公司難以維持專用處理器設(shè)計(jì)團(tuán)隊(duì)。電信行業(yè)的開發(fā)周期普遍很長,而網(wǎng)絡(luò)處理器從立項(xiàng)到上量,至少需要5年時(shí)間,供貨周期更是長達(dá)15年。一個(gè)成熟的CPU團(tuán)隊(duì),需要80人左右,這還不算做指令集和基礎(chǔ)軟件的,全部加上超過100人。這樣的團(tuán)隊(duì)開銷每年應(yīng)該在2000萬刀。2000萬刀雖然不算一個(gè)很大的數(shù)字,可如果芯片毛利是40%,凈利可能只有10%,也就是要做到2億美金的銷售額才能維持。這還只是CPU團(tuán)隊(duì),其余的支出都沒包含。通常網(wǎng)絡(luò)芯片公司銷售額也就是5億美金,在利潤不夠維持處理器研發(fā)團(tuán)隊(duì)后,只能使用通用的IP核,或者對(duì)原有CPU設(shè)計(jì)不做改動(dòng)。另外,還要擔(dān)心其他高利潤公司來挖人。以Freescale為例,在使用PowerPC的最后幾年,改了緩存設(shè)計(jì)后,甚至連驗(yàn)證的工程師都找不到了。
第三, 指令集的集中化。在五年前,網(wǎng)絡(luò)處理器還是MIPS和PowerPC的世界,兩個(gè)陣營后各有幾家在支持。當(dāng)時(shí)出現(xiàn)了一個(gè)很有趣的現(xiàn)象,做網(wǎng)絡(luò)設(shè)備的OEM公司會(huì)主動(dòng)告訴芯片公司,以后的世界,是x86和ARM指令集的世界,為了軟件的統(tǒng)一,請(qǐng)改成ARM指令集。在當(dāng)時(shí),ARM指令集在網(wǎng)絡(luò)界似乎只有Marvell一家在使用。而五年之后的現(xiàn)在,PowerPC和MIPS基本退出舞臺(tái),只有一些老產(chǎn)品和家用網(wǎng)關(guān)還有它們的身影。
在網(wǎng)絡(luò)處理器領(lǐng)域,ARM并無技術(shù)和生態(tài)優(yōu)勢:技術(shù)上,MIPS大都是單核多線程的,支持自定義的指令集,對(duì)一些特定的網(wǎng)絡(luò)包處理添加新指令。而PowerPC很早就使用了Cache
Stashing等專用優(yōu)化技術(shù),ARM直到近兩年才支持。即使使用了ARM指令集,Cavium和Netlogic還是自己設(shè)計(jì)微結(jié)構(gòu)。生態(tài)上,電信產(chǎn)品的應(yīng)用層軟件,都是OEM自定義的。底層操作系統(tǒng),Linux和VxWorks,對(duì)MIPS和PowerPC的支持并不亞于ARM。而中間層的軟件,虛擬機(jī)和數(shù)據(jù)轉(zhuǎn)發(fā),NFV等,網(wǎng)絡(luò)芯片公司之前也并不是依靠ARM來維護(hù)的。贏得網(wǎng)絡(luò)處理器市場還真是ARM的意外之喜。
第四, OEM公司自研芯片的崛起。思科,華為,中興等公司,早就開始自己做技術(shù)含量高的高端芯片,或者量大的低端芯片。對(duì)于高端產(chǎn)品,只有使用自研芯片才能搶到第一個(gè)上市,對(duì)于低端產(chǎn)品,就主要是成本考慮了。
讓我們看看網(wǎng)絡(luò)處理器到底能應(yīng)用在哪些場景:
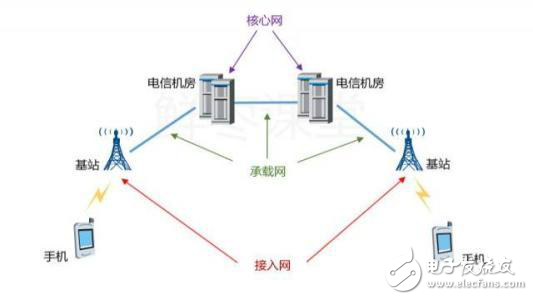
首先,是終端設(shè)備(手機(jī)/基站,wifi,光纖/Cable/ADSL等),連接到接入網(wǎng),然后再匯聚到核心網(wǎng)。就節(jié)點(diǎn)吞吐量而言,大致可以分為幾類:
第一, 在終端,吞吐量在1Gbps級(jí)別,可以是手機(jī),可以是光纖,可以是有線電視,也可以是Wifi,此時(shí)需要小型家庭路由器,無需專用網(wǎng)絡(luò)加速器,對(duì)接口有需求,比如ATM,光纖,以太網(wǎng)或者基帶芯片。
第二, 在基站或者邊緣數(shù)據(jù)中心,吞吐量在1Tbps級(jí)別,此時(shí)需要邊緣路由器,基站還需要FPGA或者DSP做信號(hào)處理。
第三, 在電信端,吞吐量遠(yuǎn)大于1Tbps,此時(shí)需要核心路由器,由專用芯片做轉(zhuǎn)發(fā)。
以上場景中,低端的只需要1-2核跑所有的數(shù)據(jù)面和控制面程序就行;對(duì)于中端應(yīng)用,控制面需要單核能力強(qiáng)的處理器,數(shù)據(jù)面需要能效高,核數(shù)眾多的處理器和網(wǎng)絡(luò)加速器;高端路由器需要專用asic進(jìn)行數(shù)據(jù)面處理,同時(shí)使用單核能力強(qiáng)的處理器做控制面。
這其中比較有爭議的是中端的數(shù)據(jù)面處理。對(duì)中斷路由器來說,業(yè)務(wù)層的協(xié)議處理,毫無疑問的該使用通用處理器;而一些計(jì)算密集的功能,比如模板檢測,加解密,壓縮,交換等,還是用asic做成模塊比較合適;對(duì)于隊(duì)列管理,保序,優(yōu)先級(jí)管理,資源管理等操作,就見仁見智了。從能效和芯片面積上來說,通用處理器做這些事肯定不是最優(yōu)的,但是它設(shè)計(jì)容錯(cuò)性高,擴(kuò)展性好,產(chǎn)品設(shè)計(jì)周期短,有著專用加速器無法取代的強(qiáng)項(xiàng)。硬件加速器本身會(huì)有bug,需要多次流片才能成熟,這非常不利于新產(chǎn)品的推廣,而通用處理器方案就能大大減少這個(gè)潛在風(fēng)險(xiǎn)。專用網(wǎng)絡(luò)加速器還有個(gè)很大的缺點(diǎn),就是很難理解和使用,OEM如果要充分發(fā)揮其性能,一定需要芯片公司配合,把現(xiàn)有代碼移植,這其中的推廣時(shí)間可能需要幾年。不過有時(shí)候芯片公司也樂見其成,因?yàn)檫@樣一來,至少能把這一產(chǎn)品在某種程度上和自己捆綁一段時(shí)間。
再進(jìn)一步,有些任務(wù),如路由表的查找,適合用單核性能高的處理器來實(shí)現(xiàn);有些任務(wù),如包的業(yè)務(wù)代碼,天然適合多線程,用多個(gè)小核處理更好。這就把通用處理器部分也分化成兩塊,大核跑性能需求強(qiáng)的代碼,小核跑能效比需求強(qiáng)的代碼。大小核之間甚至可以運(yùn)行同一個(gè)SMP操作系統(tǒng),實(shí)現(xiàn)代碼和數(shù)據(jù)硬件一致性。事實(shí)上,有些網(wǎng)絡(luò)處理器的加速器,正是用幾十上百個(gè)小CPU堆起來的。
在網(wǎng)絡(luò)芯片上,有兩個(gè)重要的基本指標(biāo),那就是接口線速和轉(zhuǎn)發(fā)能力。前者代表了接口能做到的數(shù)據(jù)吞吐量上限,后者代表了處理網(wǎng)絡(luò)包的能力。

如上圖,以太網(wǎng)包最小的長度是64字節(jié),這只是數(shù)字部分的長度。考慮到PHY層的話,還有8字節(jié)的Preamble和開始標(biāo)志,外加幀間分隔,總共84字節(jié)。
對(duì)于1Gbps的以太網(wǎng),能夠發(fā)送的以太網(wǎng)包理論上限是1.45Mpps(Million Packet Per Second)。相應(yīng)的,處理器所能處理的包數(shù)只需要1.45Mpps,超出這個(gè)數(shù)字的能力是無用的。線速一定時(shí),以太網(wǎng)包越大,所需的處理能力越低,所以在衡量處理器能力的時(shí)候,需用最小包;而在衡量網(wǎng)絡(luò)接口能力的時(shí)候,需要用最大包,來使得幀間浪費(fèi)的字段達(dá)到最小比例。
下面是Freescale的LX2160網(wǎng)絡(luò)處理器的指標(biāo):
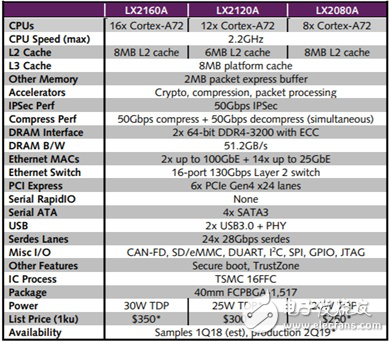
我們可以看到,共有24個(gè)28Gbps的Serdes口,對(duì)應(yīng)的,2個(gè)100G以太網(wǎng)口需要8個(gè)Serdes口,而14個(gè)25G以太網(wǎng)口需要14個(gè)Serdes口,共22×25=550Gbps的吞吐率,最大需要800Mpps的處理能力。分散到16個(gè)核,每個(gè)核需要50Mpps的轉(zhuǎn)發(fā)能力,對(duì)應(yīng)到2.2Ghz的處理器,也就是44個(gè)時(shí)鐘周期處理一個(gè)包。事實(shí)上,這是不現(xiàn)實(shí)的。通常,一個(gè)包經(jīng)過Linux協(xié)議棧,即使什么都不做,也需要1500個(gè)時(shí)鐘周期,就算使用專業(yè)轉(zhuǎn)發(fā)軟件,至少也需要80個(gè)左右。所以,最小64字節(jié)包只是一個(gè)衡量手段,跑業(yè)務(wù)的時(shí)候肯定需要盡量使用大包。
所以,在定義網(wǎng)絡(luò)處理器的規(guī)格時(shí),需要在線速和處理能力上做平衡。

上圖是Freescale的LX2160網(wǎng)絡(luò)處理器內(nèi)部模塊圖。按照之前的線速和處理能力來看,可以分為三塊:
第一, 處理器部分。這里是16個(gè)A72核,每兩個(gè)放在一個(gè)組里,分配1MB二級(jí)緩存。在手機(jī)上,通常是四個(gè)核放在一組,這里為什么是兩個(gè)?因?yàn)榫W(wǎng)絡(luò)處理主要是針對(duì)包的各種處理,更偏重于IO和訪存的能力,而不僅僅是計(jì)算。在處理包時(shí),不光是網(wǎng)絡(luò)包的數(shù)據(jù)需要讀進(jìn)處理器,還需要讀入各種參數(shù),來完成對(duì)包的處理。這些參數(shù)針對(duì)每個(gè)包會(huì)有所不同,緩存可能是放不下的,需要從內(nèi)存讀取。這就造成了需要相對(duì)較大的帶寬。在架構(gòu)篇,我們定量計(jì)算過,當(dāng)只有一個(gè)處理器在做數(shù)據(jù)讀取的時(shí)候(假設(shè)都不在緩存),瓶頸在核的對(duì)外接口BIU,而四個(gè)核同時(shí)讀取,瓶頸在ACE接口。這就是每組內(nèi)只放兩個(gè)核而不是四個(gè)的原因。而處理器總的核數(shù),很大程度上決定了網(wǎng)絡(luò)處理器的包處理能力。
第二, 接口部分。網(wǎng)絡(luò)處理器通常會(huì)把控制器(以太網(wǎng),SATA,PCIe等)和高速串行總線口Serdes復(fù)用,做成可配置的形式,提高控制器利用率,節(jié)省面積。這里使用了24對(duì)差分線,每條通道支持25Gbps。高速串行總線設(shè)計(jì)也是一個(gè)難點(diǎn),經(jīng)常會(huì)有各種串?dāng)_,噪聲,抖動(dòng)等問題,搞不好就得重新流片。(推薦閱讀:又見山人:為什么串口比并口快?)
第三, 網(wǎng)絡(luò)加速器,上圖中的WRIOP和QB-Man屬于網(wǎng)絡(luò)加速器。這是網(wǎng)絡(luò)處理器精華的設(shè)計(jì),其基本功能并不復(fù)雜,如下圖:

一個(gè)包從以太網(wǎng)進(jìn)來,如果沒有以太網(wǎng)加速器,那會(huì)被以太網(wǎng)控制器用DMA的方式放到內(nèi)存,然后就丟給CPU了。而硬件加速器的作用,主要是對(duì)包的指定字段進(jìn)行分析,打時(shí)間戳,然后分類并分發(fā)到特定的隊(duì)列。而這些隊(duì)列,在經(jīng)過重映射后,會(huì)提供給CPU來處理。這其中還牽涉到隊(duì)列關(guān)系,優(yōu)先級(jí),限速,排序,內(nèi)存管理等功能。加解密模塊可以看作獨(dú)立的模塊。就我所見,網(wǎng)絡(luò)加速器需要和所有處理器之和相近的面積。
我們來看看一個(gè)包到底在網(wǎng)絡(luò)處理器會(huì)經(jīng)歷哪些步驟:
首先,CPU調(diào)用以太網(wǎng)驅(qū)動(dòng),設(shè)置好入口(Ingress)描述符。以太網(wǎng)控制器根據(jù)描Ingress述符將Serdes傳來的包,DMA到指定內(nèi)存地址,然后設(shè)置標(biāo)志位,讓CPU通過中斷或者輪詢的方式接收通知。然后CPU把包頭或者負(fù)載讀取到緩存,做一定操作,然后寫回到出口(Egress)描述符所指定的內(nèi)存,并再次設(shè)置標(biāo)志位,通知以太網(wǎng)控制器發(fā)包。Ingress和Egress包所存放的地址是不同的。以太網(wǎng)控制器根據(jù)Egress描述符將包發(fā)送到Serdes,并更新描述符狀態(tài)。

將上述步驟實(shí)現(xiàn)到上圖的系統(tǒng)中,并拆解成總線傳輸,是這樣的(假定代碼及其數(shù)據(jù)在一二級(jí)緩存中):
1. CPU寫若干次以太網(wǎng)控制器(10-40GbE)的寄存器(Non-cacheable)
2. CPU讀若干次以太網(wǎng)控制器(10-40GbE)的狀態(tài)寄存器(Non-cacheable)
3. 以太網(wǎng)控制器(10-40GbE)進(jìn)行若干次DMA,將數(shù)據(jù)從PHY搬到內(nèi)存
4. CPU從內(nèi)存讀入所需包頭數(shù)據(jù),做相應(yīng)修改
5. CPU寫入內(nèi)存所需數(shù)據(jù)
6. CPU寫若干次以太網(wǎng)控制器(10-40GbE)的寄存器(Non-cacheable)
7. 以太網(wǎng)控制器(10-40GbE)進(jìn)行若干次DMA,將數(shù)據(jù)從內(nèi)存搬到PHY,并更新內(nèi)部寄存器
8. CPU讀若干次以太網(wǎng)控制器(10-40GbE)的狀態(tài)寄存器(Non-cacheable)
以上8步所需時(shí)間通常為:
1. 1x以太網(wǎng)寄存器訪問延遲 。假定為20ns。
2. 1x以太網(wǎng)寄存器訪問延遲。假定為20ns。
3. 以太網(wǎng)控制器寫入DDR的延遲。假設(shè)是最小包,64字節(jié)的話,延遲x1。如果是大包,可能存在并發(fā)。但是和第一步中CPU對(duì)寄存器的寫入存在依賴關(guān)系,所以不會(huì)小于延遲x1。假定為100ns。
4. CPU從DDR讀入數(shù)據(jù)的延遲。如果只需包頭,那就是64字節(jié),通常和緩存行同樣大小,延遲x1。假定為100ns。
5. CPU寫入DDR延遲x1。假定為100ns。
6. 1x以太網(wǎng)寄存器訪問延遲 。假定為20ns。
7. 以太網(wǎng)從DDR把數(shù)據(jù)搬到PHY,延遲至少x1。假定為100ns。
8. 1x以太網(wǎng)寄存器訪問延遲。假定為20ns。
2和3,7和8是可以同時(shí)進(jìn)行的,取最大值。其余的都有依賴關(guān)系,可以看做流水線上的一拍。其中4,5和6都在CPU上先后進(jìn)行,針對(duì)同一包的處理,它們無法并行(同一CPU上的不同包之間這幾步是可以并行的)。當(dāng)執(zhí)行到第6步時(shí), CPU只需要將所有非cacheable的寫操作,按照次序發(fā)出請(qǐng)求即可,無需等待寫回應(yīng)就可以去干別的指令。這樣,可以把最后一步的 所流水線中最大的延遲縮小到100+20+100共220ns以下的某個(gè)值。當(dāng)然,因?yàn)锳RM處理器上non-cacheable的傳輸,在對(duì)內(nèi)部很多都是強(qiáng)制排序的,無法并行,總線也不會(huì)提早發(fā)送提前回應(yīng)(early response),所以總延遲也就沒法減少太多。
上面的計(jì)算意味著,CPU交換一下源和目的地址,做一下簡單的小包轉(zhuǎn)發(fā),流水后每個(gè)包所需平均延遲是220ns。同時(shí),增大帶寬和CPU數(shù)量并不會(huì)減少這個(gè)平均延遲,提高CPU頻率也不會(huì)有太大幫助,因?yàn)檠舆t主要耗費(fèi)在總線和DDDR的訪問上。提高總線和DDR速度倒是有助于縮短這個(gè)延遲,不過通常能提高的頻率有限,不會(huì)有成倍提升。
那還有什么辦法嗎?一個(gè)最直接的辦法就是增加SRAM,把SRAM作為數(shù)據(jù)交換場所,而不需要到內(nèi)存。為了更有效的利用SRAM,可以讓以太網(wǎng)控制器只把包頭放進(jìn)去,負(fù)載還是放在放DDR,描述符里面指明地址即可。這個(gè)方法的缺點(diǎn)也很明顯:SRAM需要單獨(dú)的地址空間,需要特別的驅(qū)動(dòng)來支持。不做網(wǎng)絡(luò)轉(zhuǎn)發(fā)的時(shí)候,如果是跑通用的應(yīng)用程序,不容易被利用,造成面積浪費(fèi)。
第二個(gè)方法是增加系統(tǒng)緩存,所有對(duì)DDR的訪問都要經(jīng)過它。它可以只對(duì)特殊的傳輸分配緩存行,而忽略其余訪問。好處是不需要獨(dú)立的地址空間,缺點(diǎn)是包頭和負(fù)載必須要指定不同的緩存分配策略。不然負(fù)載太大,會(huì)占用不必要的緩存行。和SRAM一樣,包頭和負(fù)載必須放在不同的頁表中,地址不連續(xù)。
在有些處理器中,會(huì)把前兩個(gè)方法合成,對(duì)一塊大面積的片上內(nèi)存,同時(shí)放緩存控制器和SRAM控制器,兩種模式可以互切。
第三個(gè)方法,就是在基礎(chǔ)篇提到的Cache stashing,是對(duì)第二種方法的改進(jìn)。在這里,包頭和負(fù)載都可以是cacheable的,包頭被以太網(wǎng)控制器直接塞到某個(gè)CPU的私有緩存,而負(fù)載則放到內(nèi)存或者系統(tǒng)級(jí)緩存。在地址上,由于緩存策略一致,它們可以是連續(xù)的,也可以分開。當(dāng)CPU需要讀取包頭時(shí),可以直接從私有緩存讀取,延遲肯定短于SRAM,系統(tǒng)緩存或者DDR。再靈活一點(diǎn),如果CPU需要更高層協(xié)議的包頭,可以在以太網(wǎng)控制器增加Cache sashing的緩存行數(shù)。由于以太網(wǎng)包的包頭一定排列在前面,所以可以將高層協(xié)議所需的信息也直接送入某個(gè)CPU一二級(jí)私有緩存。對(duì)于當(dāng)中不會(huì)用到的部分負(fù)載,可以設(shè)成non-cacheable的,減少系統(tǒng)緩存的分配。這樣的設(shè)計(jì),需要把整個(gè)以太網(wǎng)包分成兩段,每一段使用不同的地址空間和緩存策略,并使用類似Scatter-Gather的技術(shù),分別做DMA,增加效率。這些操作都可以在以太網(wǎng)控制器用硬件和驅(qū)動(dòng)實(shí)現(xiàn),無需改變處理器的通用性。
此外,有一個(gè)小的改進(jìn),就是增加緩存行對(duì)CPU,虛擬機(jī),線程ID或者某個(gè)網(wǎng)絡(luò)加速器的敏感性,使得某些系統(tǒng)緩存行只為某個(gè)特定ID分配緩存行,可以提高一些效率。
以上解決了CPU讀包頭的問題,還有寫的問題。如果包頭是Cacheable的,不必等待寫入DDR之后才收到寫回應(yīng),所以時(shí)間可以遠(yuǎn)小于100ns。至于寫緩存本身所需的讀取操作,可以通過無效化某緩存行來避免,這在基礎(chǔ)篇有過介紹。這樣,寫延遲可以按照10-20ns計(jì)算。
以太網(wǎng)控制器看到Egress的寄存器狀態(tài)改動(dòng)之后,也不必等待數(shù)據(jù)寫到DDR,就可以直接讀。由于存在ACE/ACE-lite的硬件一致性,數(shù)據(jù)無論是在私有緩存,系統(tǒng)緩存還是DDR,都是有完整性保證的。這樣一來,總共不到50ns的時(shí)間就可以了。同理,Ingress通路上以太網(wǎng)控制器的寫操作,也可以由于緩存硬件一致性操作而大大減少。
相對(duì)于第二種方法,除了延遲更短,最大的好處就是,在私有緩存中,只要被cache stashing進(jìn)來的數(shù)據(jù)在不久的將來被用到,不用擔(dān)心被別的CPU線程替換出去。Intel做過一些研究,這時(shí)間是200ns。針對(duì)不同的系統(tǒng)和應(yīng)用,肯定會(huì)不一樣,僅作參考。
讓我們重新計(jì)算下此時(shí)的包處理延遲:
原來的第四步,CPU讀操作顯然可以降到10ns之下。
訪問寄存器的時(shí)間不變。
CPU寫延遲可以按照10-20ns計(jì)算。
總時(shí)間從220降到了50ns以下,四倍。
不過,支持Cache Stashing需要AMBA5的CHI協(xié)議,僅僅有ACE接口是不夠的。CPU,總線和以太網(wǎng)控制器需要同時(shí)支持才能生效。如果采用ARM的CPU設(shè)計(jì),需要最新的A75/A55才有可能。總線方面,A75/A55自帶的ACP端口可用于20GB以下吞吐量的Cache Stashing,適合簡單場景,而大型的就需要專用的CMN600總線以支持企業(yè)級(jí)應(yīng)用了。還有一種可能,就是自己做CPU微架構(gòu)和總線,就可以避開CHI/ACE協(xié)議的限制了。
Intel把cache stashing稱作Direct Cache Access,并且打通了PCIe和以太網(wǎng)卡,只要全套采用Intel方案,并使用DPDK軟件做轉(zhuǎn)發(fā),就可以看到80時(shí)鐘周期,30-40ns的轉(zhuǎn)發(fā)延遲。其中,DPDK省卻了Linux協(xié)議棧2000時(shí)鐘周期左右的額外操作,再配合全套硬件機(jī)制,發(fā)揮出CPU的最大能力。
這個(gè)40ns,其實(shí)已經(jīng)超越了很多網(wǎng)絡(luò)硬件加速器的轉(zhuǎn)發(fā)延遲。舉個(gè)例子,F(xiàn)reescale前幾年基于PowerPC的網(wǎng)絡(luò)處理器,在內(nèi)部其實(shí)也支持Cache Stashing。但是其硬件的轉(zhuǎn)發(fā)延遲,卻達(dá)到了100ns。究其原因,是因?yàn)樵谑褂昧擞布铀倨骱螅渲械年?duì)列管理相當(dāng)復(fù)雜,CPU為了拿到隊(duì)列管理器分發(fā)給自己的包,需要設(shè)置4次以上的寄存器。并且,這些寄存器操作無法合并與并行,使得之前的8步中只需20ns的寄存器操作,變成了80ns,超越CPU的數(shù)據(jù)操作延遲,成為整個(gè)流水中的瓶頸。結(jié)果在標(biāo)準(zhǔn)的純轉(zhuǎn)發(fā)測試中,硬件轉(zhuǎn)發(fā)還不如x86軟件來的快。
除了減少延遲,系統(tǒng)DDR帶寬和隨之而來的功耗也可以減少。Intel曾經(jīng)做過一個(gè)統(tǒng)計(jì),如果對(duì)全部的包內(nèi)容使用cache,對(duì)于256字節(jié)(控制包)和1518字節(jié)(大包),分別可以減少40-50%的帶寬。如下圖:

當(dāng)然,由于芯片緩存大小和配置的不同,其他的芯片肯定會(huì)有不同結(jié)果。
包轉(zhuǎn)發(fā)只是測試項(xiàng)中比較重要的一條。在加入加解密,壓縮,關(guān)鍵字檢測,各種查表等等操作后,整個(gè)轉(zhuǎn)發(fā)延遲會(huì)增加至幾千甚至上萬時(shí)鐘周期。這時(shí)候,硬件加速器的好處就顯現(xiàn)出來了。也就是說,如果一個(gè)包進(jìn)來按部就班的走完所有的加速器步驟,那能效比和性能面積比自然是加速器高。但是,通常情況下,很多功能都是用不到的,而這些不常用功能模塊,自然也就是面積和成本。
整理完基本數(shù)據(jù)通路,我們來看看完整的網(wǎng)絡(luò)加速器有哪些任務(wù)。以下是標(biāo)準(zhǔn)的Ingress通路上的處理流程:

主要是收包,分配和管理緩沖,數(shù)據(jù)搬移,字段檢測和分類,隊(duì)列管理和分發(fā)。
Egress通路上的處理流程如下:

主要是隊(duì)列管理和分發(fā),限速,分配和管理緩沖,數(shù)據(jù)搬移。
在Ingress和Egress共有的部分中,最復(fù)雜的模塊是緩沖管理和隊(duì)列管理,它們的任務(wù)分別如下:
緩沖管理:緩沖池的分配和釋放;描述符的添加和刪除;資源統(tǒng)計(jì)與報(bào)警;
隊(duì)列管理:維護(hù)MAC到CPU的隊(duì)列重映射表,入隊(duì)和出隊(duì)管理;包的保序和QoS;CPU緩存的預(yù)熱,對(duì)齊;根據(jù)預(yù)設(shè)的分流策略,均衡每個(gè)CPU的負(fù)載
這些任務(wù)大部分都不是純計(jì)算任務(wù),而是一個(gè)硬件化的內(nèi)存管理和隊(duì)列管理。事實(shí)上,在新的網(wǎng)絡(luò)加速器設(shè)計(jì)中,這些所謂的硬件化的部分,是由一系列專用小核加C代碼完成的。因此,完全可以再進(jìn)一步,去掉網(wǎng)絡(luò)加速器,使用SMP的多組通用處理器來做純軟件的隊(duì)列和緩沖管理,只保留存在大量計(jì)算或者簡單操作的硬件模塊掛在總線上。
再來看下之前的芯片模塊,我們保留加解密和壓縮引擎,去除隊(duì)列和緩存管理QB-Man,把WRIOP換成A53甚至更低端的小核,關(guān)鍵字功能檢測可以用小核來實(shí)現(xiàn)。
網(wǎng)絡(luò)處理上還有一些小的技術(shù),如下:
Scattter Gather:前文提過,這可以處理分散的包頭和負(fù)載,直接把多塊數(shù)據(jù)DMA到最終的目的地,CPU不用參與拷貝操作。這個(gè)在以太網(wǎng)控制器里可以輕易實(shí)現(xiàn)。
Checksum:用集成在以太網(wǎng)控制器里面的小模塊對(duì)數(shù)據(jù)包進(jìn)行校驗(yàn)和編碼,每個(gè)包都需要做一次,可以用很小的代價(jià)來替代CPU的工作。
Interrupt aggregation:通過合并多個(gè)包的中斷請(qǐng)求來降低中斷響應(yīng)的平均開銷。在Linux和一些操作系統(tǒng)里面,響應(yīng)中斷和上下文切換需要毫秒級(jí)的時(shí)間,過多的中斷導(dǎo)致真正處理包的時(shí)間變少。這個(gè)在以太網(wǎng)控制器里可以輕易實(shí)現(xiàn)。
Rate limiter:包發(fā)送限速,防止某個(gè)MAC口發(fā)送速度超過限速。這個(gè)用軟件做比較難做的精確,而以太網(wǎng)控制器可以輕易計(jì)算單位時(shí)間內(nèi)的發(fā)送字節(jié)數(shù),容易實(shí)現(xiàn)。
Load balancing, Qos:之前主要是在闡述如何對(duì)單個(gè)包進(jìn)行處理。對(duì)于多個(gè)包,由于網(wǎng)絡(luò)包之間天然無依賴關(guān)系,所以很容易通過負(fù)載均衡把他們分發(fā)到各個(gè)處理器。那到底這個(gè)分發(fā)誰來做?專門分配一個(gè)核用軟件做當(dāng)然是可以的,還可以支持靈活的分發(fā)策略。但是這樣一來,可能會(huì)需要額外的拷貝,Cache stashing所減少的延遲優(yōu)勢也會(huì)消失。另外一個(gè)方法是在每一個(gè)以太網(wǎng)控制器里設(shè)置簡單的隊(duì)列(帶優(yōu)先級(jí)的多個(gè)Ring buffer之類的設(shè)計(jì)),和CPU號(hào),線程ID或者虛擬機(jī)ID綁定。以太網(wǎng)控制器在對(duì)包頭里的目的地址或者源地址做簡單判斷后,可以直接塞到相應(yīng)的緩存或者DDR地址,供各個(gè)CPU來讀取。如果有多個(gè)以太網(wǎng)控制器也沒關(guān)系,每一個(gè)控制器針對(duì)每個(gè)CPU都可以配置不同的地址,讓CPU上的軟件來決定自己所屬隊(duì)列的讀取策略,避免固化。
把這個(gè)技術(shù)用到PCIe的接口和網(wǎng)卡上,加入虛擬機(jī)ID的支持,就成了srIOV。PCIe控制器直接把以太網(wǎng)數(shù)據(jù)DMA到虛擬機(jī)所能看到的地址(同時(shí)也可使用Cache stashing),不引起異常,提高效率。這需要虛擬機(jī)中所謂的穿透模式支持IO(或者說外設(shè))的虛擬化,在安全篇中有過介紹,此處就不再展開。同樣的,SoC內(nèi)嵌的以太網(wǎng)處理器,在增加了系統(tǒng)MMU之后,同樣也可以省略PCIe的接口,實(shí)現(xiàn)虛擬化,直接和虛擬機(jī)做數(shù)據(jù)高效傳輸。
解決了負(fù)載均衡的問題,接下去就要看怎么做包的處理了。有幾種經(jīng)典的方法:
第一是按照包來分,在一個(gè)核上做完某一特征數(shù)據(jù)包流所有的任務(wù),然后發(fā)包。好處是包的數(shù)據(jù)就在本地緩存,壞處是如果所有代碼都跑在一個(gè)核,所用到的參數(shù)可能過多,還是需要到DDR或者系統(tǒng)緩存去取;也有可能代碼分支過多,CPU里面的分支預(yù)測緩沖不夠大,包處理程序再次回到某處代碼時(shí),還是會(huì)產(chǎn)生預(yù)測失敗。
第二是按照任務(wù)的不同階段來分,每個(gè)核做一部分任務(wù),所有的包都流過每一個(gè)核。優(yōu)缺點(diǎn)和上一條相反。
第三種就是前兩者的混合,每一組核處理一個(gè)特定的數(shù)據(jù)流,組里再按照流水分階段處理。這樣可以根據(jù)業(yè)務(wù)代碼來決定靈活性。
在以上的包處理程序中,一定會(huì)有一些操作是需要跨核的,比如對(duì)路由表的操作,統(tǒng)計(jì)數(shù)據(jù)的更新等。其中的一個(gè)重要原則就是:能不用鎖就不要用鎖,用了鎖也需要使用效率最高的。
舉個(gè)例子,如果需要實(shí)現(xiàn)一個(gè)計(jì)數(shù)器,統(tǒng)計(jì)N個(gè)CPU上最終處理過的包。首先,我們可以設(shè)計(jì)一個(gè)緩存行對(duì)齊的數(shù)據(jù)結(jié)構(gòu),包含若N+1個(gè)計(jì)數(shù)器,其中每一個(gè)計(jì)數(shù)器占據(jù)一行。每個(gè)CPU周期性的寫入自己對(duì)應(yīng)的那個(gè)計(jì)數(shù)器。由于計(jì)數(shù)器占據(jù)不同緩存行,所以寫入操作不會(huì)引起額外的Invalidation,也不會(huì)把更新過的數(shù)據(jù)踢到DDR。最后,有一個(gè)獨(dú)立的線程,不斷讀取前面N個(gè)計(jì)數(shù)器的值,累加到第N+1個(gè)計(jì)數(shù)器。在讀取的時(shí)候,不會(huì)引起Invalidation和eviction。此處不需要軟件鎖來防止多個(gè)線程對(duì)同一變量的操作,因?yàn)榇颂幱?jì)數(shù)器的寫和讀并不需要嚴(yán)格的先后次序,只需要保證硬件一致性即可。
在不得不使用鎖的時(shí)候,也要保證它的效率。軟件上的各種實(shí)現(xiàn)這里就不討論了,在硬件上,Cacheable的鎖變量及其操作最終會(huì)體現(xiàn)為兩種形式:
第一, exclusive Access。原理是,對(duì)于一個(gè)緩存行里的變量,如果需要更新,必須先讀然后寫。當(dāng)進(jìn)行了一次讀之后,進(jìn)入鎖定狀態(tài)。期間如果有別的CPU對(duì)這個(gè)變量進(jìn)行訪問,鎖定狀態(tài)就會(huì)被取消,軟件必須重復(fù)第一步;如果沒有,就成功寫入。這個(gè)原理被用來實(shí)現(xiàn)spinlock函數(shù)。根據(jù)硬件一致性協(xié)議MESI,處在兩個(gè)CPU中的線程,同時(shí)對(duì)某一個(gè)變量讀寫的話,數(shù)據(jù)會(huì)不斷在各自的私有緩存或者共享緩存中來回傳遞,而不會(huì)保持在最快的一級(jí)緩存。這樣顯然降低效率。多個(gè)CPU組之間的exclusive Access效率更低。
第二, 原子操作。在ARMv8.2新的原子操作實(shí)現(xiàn)上,修改鎖變量的操作可以在緩存控制器上實(shí)現(xiàn),不需要送到CPU流水線。這個(gè)緩存可以使私有緩存,也可以是共享的系統(tǒng)緩存。和exclusive access相比較,省去了鎖定狀態(tài)失敗后額外的輪詢。不過這個(gè)需要系統(tǒng)總線和CPU的緩存支持本地更新操作,不然還是要反復(fù)讀到每個(gè)CPU的流水線上才能更新數(shù)據(jù)。我在基礎(chǔ)篇中舉過例子,這種做法反而可能引起總線掛起,降低系統(tǒng)效率。
如果一定要跑Linux系統(tǒng),那么一定要減少中斷,內(nèi)核切換,線程切換的時(shí)間。對(duì)應(yīng)的,可以采用輪詢,線程綁定CPU和用戶態(tài)驅(qū)動(dòng)來實(shí)現(xiàn)。此外,還可以采用大頁表模式,減少頁缺失的時(shí)間。這樣,可以把標(biāo)準(zhǔn)Linux內(nèi)核協(xié)議棧的2000左右時(shí)鐘周期縮到幾十納秒,這也就是DPDK和商業(yè)網(wǎng)絡(luò)轉(zhuǎn)發(fā)軟件效率高的原因。
最后稍稍談下固態(tài)存儲(chǔ)。企業(yè)級(jí)的固態(tài)硬盤存儲(chǔ)芯片,芯片基本結(jié)構(gòu)如下:
如上圖,芯片分為前端和后端兩塊,前端處理來自PCIe的命令和數(shù)據(jù),并把數(shù)據(jù)塊映射到最終nand顆粒。同時(shí),還要做負(fù)載均衡,磨損均衡,垃圾回收,陣列控制等工作,略過不表。這些都是可以用通用處理器來完成的,差不多每1M的隨機(jī)IOPS需要8個(gè)跑在1GHz左右的A7處理器來支撐,每TB的NAND陣列,差不多需要1GB的DDR內(nèi)存來存放映射表等信息。其余的一些壓縮,加解密等,可以通過專用模塊完成。后端要是作為ONFI的接口控制器,真正的從NAND里面讀寫數(shù)據(jù),同時(shí)做LDPC生成和校驗(yàn)。
如果單看前端,會(huì)發(fā)現(xiàn)其實(shí)和網(wǎng)絡(luò)處理非常像,查表,轉(zhuǎn)發(fā),負(fù)載均衡,都能找到對(duì)應(yīng)的功能。不同的是,存儲(chǔ)的應(yīng)用非常固定,不需要錯(cuò)綜復(fù)雜的業(yè)務(wù)流程,只需處理幾種類型的命令和數(shù)據(jù)塊就可以了。
一個(gè)存儲(chǔ)系統(tǒng)的硬件成本,閃存才是大頭,占據(jù)了85%以上,還經(jīng)常缺貨。而閃存系統(tǒng)的毛利并不高,這也導(dǎo)致了固態(tài)存儲(chǔ)控制器價(jià)格有限,哪怕是企業(yè)級(jí)的芯片,性能超出消費(fèi)類幾十倍,也無法像服務(wù)器那樣擁有高利潤。
一個(gè)潛在的解決方法,是把網(wǎng)絡(luò)也集成到存儲(chǔ)芯片中,并且跑Linux。這樣,固態(tài)硬盤由原來插在x86服務(wù)器上的一個(gè)PCIe設(shè)備,搖身一變成為一個(gè)網(wǎng)絡(luò)節(jié)點(diǎn),從而省掉了原來的服務(wù)器芯片及其內(nèi)存(可別小看內(nèi)存,它在一臺(tái)服務(wù)器里面可以占到三分之一的成本)。
如上圖,可以把SPDK,DPDK,用戶態(tài)驅(qū)動(dòng)和用戶態(tài)文件系統(tǒng)運(yùn)行在一個(gè)芯片中,讓一個(gè)網(wǎng)絡(luò)包進(jìn)來,不走內(nèi)核網(wǎng)絡(luò)協(xié)議棧和文件系統(tǒng),直接從網(wǎng)絡(luò)數(shù)據(jù)變成閃存上的文件塊。在上層,運(yùn)行類似CEPH之類的軟件,把芯片實(shí)例化成一個(gè)網(wǎng)絡(luò)存儲(chǔ)節(jié)點(diǎn)。大致估算一下,這樣的單芯片方案需要16核A53級(jí)別的處理器,運(yùn)行在1.5GHz以下,在28納米上,可以做到5-10瓦,遠(yuǎn)低于原來的服務(wù)器。
不過這個(gè)模式目前也存在著很大的問題。真正做存儲(chǔ)芯片的公司,并不敢花大力氣去推這種方案,因?yàn)樗鼱可娴搅舜鎯?chǔ)系統(tǒng)的基礎(chǔ)架構(gòu)變化,超出芯片公司的能力范疇,也不敢冒險(xiǎn)去做這些改動(dòng)。只有OEM和擁有大量數(shù)據(jù)中心互聯(lián)網(wǎng)公司才能去定義,不過卻苦于沒有合適的單芯片方案。而且數(shù)據(jù)中心未必看得上省這點(diǎn)成本,畢竟成本大頭在服務(wù)器芯片,內(nèi)存以及機(jī)架電源。
-
處理器
+關(guān)注
關(guān)注
68文章
19259瀏覽量
229653 -
網(wǎng)絡(luò)處理器
+關(guān)注
關(guān)注
0文章
48瀏覽量
13952
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
NanoEdge AI的技術(shù)原理、應(yīng)用場景及優(yōu)勢
RISC-V適合什么樣的應(yīng)用場景
淺談國產(chǎn)異構(gòu)雙核RISC-V+FPGA處理器AG32VF407的優(yōu)勢和應(yīng)用場景
頻率計(jì)數(shù)器的技術(shù)原理和應(yīng)用場景
倍頻器的技術(shù)原理和應(yīng)用場景
消息隊(duì)列的應(yīng)用場景
ARM處理器的相關(guān)資料分享
網(wǎng)絡(luò)處理器,什么是網(wǎng)絡(luò)處理器
網(wǎng)絡(luò)處理器中處理單元的設(shè)計(jì)

一顆基于應(yīng)用場景抽象出來的,面向多層神經(jīng)網(wǎng)絡(luò)處理的AI芯片
基于RISC-V指令集Egret系列處理器的性能及應(yīng)用場景
網(wǎng)絡(luò)音頻模塊有哪些應(yīng)用場景?

dsp和嵌入式微處理器的區(qū)別是什么
盛顯科技:投影融合處理器主要的應(yīng)用場景有哪些?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論