 僅會一點點python就能自己搭建一個神經網絡!
僅會一點點python就能自己搭建一個神經網絡!
僅會一點點python也能自己搭建一個神經網絡!谷歌開發者博客的 Codelabs 項目上面給出了一份教程,不只是教你搭建神經網絡,還給出四個實驗案例,手把手教你如何使用 keras、TPU、Colab。
想要真的了解深度學習,除了看視頻,拿數據和算力真槍實彈的練手可能比各種理論知識更重要。
編程基礎不好?不會配置環境?本地 GPU 太貴配置太低?訓練速度達不到要求?這些可能都是阻礙你搭建第一個神經網絡的原因。
谷歌開發者博客的 Codelabs 項目上面給出了一份教程(課程鏈接在文末),不只是教你搭建神經網絡,還給出四個實驗案例,手把手教你如何使用 keras、TPU、Colab。
這個練手指南被成為 “僅會一點點 python 也能看懂”,也就是說,基礎再薄弱都可以直接了解哦。
四次實驗均在谷歌的 Collab 上運行,由淺入深、循序漸進。無需進行任何設置,可以用 Chromebook 打開,實驗環境都幫你搭建好了。
是時候搭建一個屬于自己的神經網絡了!
快速開啟!
四次實驗均選擇 TPU 支持,這會使代碼運行速度大大加快,畢竟用了硬件加速。
先教會你如何在 Tensorflow 框架下快速加載數據,然后介紹一些 tf.data.Dataset 的基礎知識,包括 eager 模式以及元組數據集等。
第二部分,手把手教你實現遷移學習,把別人訓練好的模型拿過來直接使用,不用一步一步搭建也能使用強大的神經網絡。除了遷移學習,在這部分還會簡單介紹一些必要的知識點,包括神經元、激活函數等。
第三部分,進入卷積神經網絡部分,在了解卷積層、池化層、Dense 層卷積網絡三個必要的組件之后,你將學會使用 Keras Sequential 模型構建卷積圖像分類器,并使用良好的卷積層選擇來微調模型。
第四部分,進入到更加前沿的部分,在接受了前面三個部分的洗禮之后,在這部分你會實現在 Keras 中利用 TPU 組建現代卷積網絡和實現分類。
和在 Jupyter Notebook 操作方式一樣,同時按住鍵盤的 Shift 和 enter 按鈕,便可以運行代碼。
如果你是首次執行,需要登錄 Google 帳戶進行身份驗證。注意頁面提醒就可以啦~
此 notebook 支持目錄功能,點擊網頁左側的黑色箭頭可以查看。

利用 Colab 上的 TPU 訓練 Keras 模型需要輸入以下代碼?
tpu = tf.contrib.cluster_resolver.TPUClusterResolver(TPU_ADDRESS)strategy = tf.contrib.tpu.TPUDistributionStrategy(tpu)tpu_model = tf.contrib.tpu.keras_to_tpu_model(model, strategy=strategy)tpu_model.fit(get_training_dataset, steps_per_epoch=TRAIN_STEPS, epochs=EPOCHS, validation_data=get_validation_dataset, validation_steps=VALID_STEPS)
本質上是在 keras 中調用 keras_to_tpu_model,部署額外的硬件可以通過增加訓練批次的大小增加訓練過程。需要注意的是目前,Keras 支持僅限于 8 個核心或一個 Cloud TPU。
注:TPU 可以在神經網絡運算上達到高計算吞吐量,同時能耗和物理空間都很小。因為 TPU 從內存加載數據。當每個乘法被執行后,其結果將被傳遞到下一個乘法器,同時執行加法。因此結果將是所有數據和參數乘積的和。在大量計算和數據傳遞的整個過程中,不需要執行任何的內存訪問。
介紹完基本的操作,接下來,看看官方給出的四個實驗。
Tensorflow 入門:tfrecords 和 tf.data
此實驗涉及兩個 tf 的基礎操作,一個是使用 tf.data.Dataset API 導入訓練數據,另一個是使用 TFRecord 格式從 GCS 有效導入訓練數據。
此次實驗使用花卉圖片的數據集,學習的目標是將其分為 5 種類別。使用 tf.data.Dataset API執行數據加載。
Keras 和 Tensorflow 在其所有訓練和評估功能中接受數據集。在數據集中加載數據后,API 會提供對神經網絡訓練數據有用的所有常用功能:
dataset = ... # load something (see below)dataset = dataset.shuffle(1000) # shuffle the dataset with a buffer of 1000dataset = dataset.cache() # cache the dataset in RAM or on diskdataset = dataset.repeat() # repeat the dataset indefinitelydataset = dataset.batch(128) # batch data elements together in batches of 128dataset = dataset.prefetch(-1) # prefetch next batch(es) while training
了解 API 并試著運行:
https://colab.research.google.com/github/GoogleCloudPlatform/training-data-analyst/blob/master/courses/fast-and-lean-data-science/02_Dataset_playground.ipynb
關于鮮花數據集,數據集按 5 個文件夾組織,每個文件夾都包含一種花。文件夾名為向日葵,雛菊,蒲公英,郁金香和玫瑰。數據托管在 Google 云端存儲上的公共存儲區中。
gs://flowers-public/sunflowers/5139971615_434ff8ed8b_n.jpggs://flowers-public/daisy/8094774544_35465c1c64.jpggs://flowers-public/sunflowers/9309473873_9d62b9082e.jpggs://flowers-public/dandelion/19551343954_83bb52f310_m.jpggs://flowers-public/dandelion/14199664556_188b37e51e.jpggs://flowers-public/tulips/4290566894_c7f061583d_m.jpggs://flowers-public/roses/3065719996_c16ecd5551.jpggs://flowers-public/dandelion/8168031302_6e36f39d87.jpggs://flowers-public/sunflowers/9564240106_0577e919da_n.jpggs://flowers-public/daisy/14167543177_cd36b54ac6_n.jpg
tf.data.Dataset 基礎知識
數據通常包含多個文件,此處為圖像,通過調用以下方法創建文件名數據集:
filenames_dataset = tf.data.Dataset.list_files('gs://flowers-public/*/*.jpg')# The parameter is a "glob" pattern that supports the * and ? wildcards.
然后,將函數 “映射” 到每個文件名,這些文件通常導入文件并解碼為內存中的實際數據:
def decode_jpeg(filename):bits = tf.read_file(filename)image = tf.image.decode_jpeg(bits)return imageimage_dataset = filenames_dataset.map(decode_jpeg)# this is now a dataset of decoded images (uint8 RGB format)
有關 tf.data.Dataset 的基礎知識、tf.data.Dataset 和 eager 模式、元組數據集的詳細步驟,請戳:
https://codelabs.developers.google.com/codelabs/keras-flowers-data/#3
但逐個加載圖像很慢,在迭代此數據集時,每秒只可以加載 1-2 個圖像。我們將用訓練的硬件加速器,可以將速率提高很多倍。
快速加載數據
我們將在本實驗中使用的 Tensor Processing Unit(TPU)硬件加速器。Google 云端存儲(GCS)能夠保持極高的吞吐量,但與所有云存儲系統一樣,形成連接時需要來回請求。因此,將數據存儲為數千個單獨的文件并不理想。我們將在少量文件中批量處理它們,并使用 tf.data.Dataset 的強大功能一次性讀取多個文件。
通過加載圖像文件的代碼將它們調整為通用大小,然后將它們存儲在 16 個 TFRecord 文件中,代碼鏈接如下:
https://colab.research.google.com/github/GoogleCloudPlatform/training-data-analyst/blob/master/courses/fast-and-lean-data-science/03_Flower_pictures_to_TFRecords.ipynb
經驗法則是將數據分成幾個(10s 到 100s)的大文件(10s 到 100s 的 MB)。如果有太多文件,例如數千個文件,那么訪問每個文件的時間可能會開始妨礙。如果文件太少,例如一兩個文件,那么就無法并行獲取多個文件的優勢。
TFRecord 文件格式
Tensorflow 用于存儲數據的首選文件格式是基于 protobuf 的 TFRecord 格式。其他序列化格式也可以使用,可以通過以下方式直接從 TFRecord 文件加載數據集:
filenames_dataset = tf.data.Dataset.list_files(FILENAME_PATTERN)tfrecords_dataset = tf.data.TFRecordDataset(filenames,num_parallel_reads = 32)
但你擁有 TFRecords 的數據集時,下一步解碼步驟就是從每個記錄中獲得數據。如前所述,你將使用 Dataset.map,并注意 num_parallel_reads=32 參數。這將從 32 個 TFRecord 文件并行加載數據,可以獲得最佳性能。
在 Keras 中利用遷移學習
本次實驗在 keras 中實現遷移學習,將強大的預訓練模型應用于我們的數據集,不用費力重新訓練模型。此外,本實驗包含有關神經網絡的必要理論解釋。
神經網絡分類器是由幾個層的神經元組成。對于圖像分類,這些可以是 Dense 層,或者更常見的是卷積層。它們通常通過 relu 激活函數激活。最后一層使用與類相同數量的神經元,并使用 softmax 激活。對于分類,交叉熵是最常用的損失函數,將獨熱編碼標簽(即正確答案)與神經網絡預測的概率進行比較。例如,為了最大限度地減少損失,最好選擇具有動量的優化器 AdamOptimizer 并批量訓練圖像和標簽。
對于構建為層序列的模型,Keras 提供了 Sequential API。例如,使用三個 Dense 層的圖像分類器可以在 Keras 中編寫為:
model = tf.keras.Sequential([ tf.keras.layers.Flatten(input_shape=[192, 192, 3]), tf.keras.layers.Dense(500, activation="relu"), tf.keras.layers.Dense(50, activation="relu"), tf.keras.layers.Dense(5, activation='softmax') # classifying into 5 classes])# this configures the training of the model. Keras calls it "compiling" the model.model.compile( optimizer='adam', loss= 'categorical_crossentropy', metrics=['accuracy']) # % of correct answers# train the modelmodel.fit(dataset, ... )
Dense 神經網絡
這是用于分類圖像的最簡單的神經網絡。它由分層排列的 “神經元” 組成。第一層處理輸入數據并將其輸出饋送到其他層。之所以被稱為 “Dense” 是因為每個神經元都連接到前一層中的所有神經元。
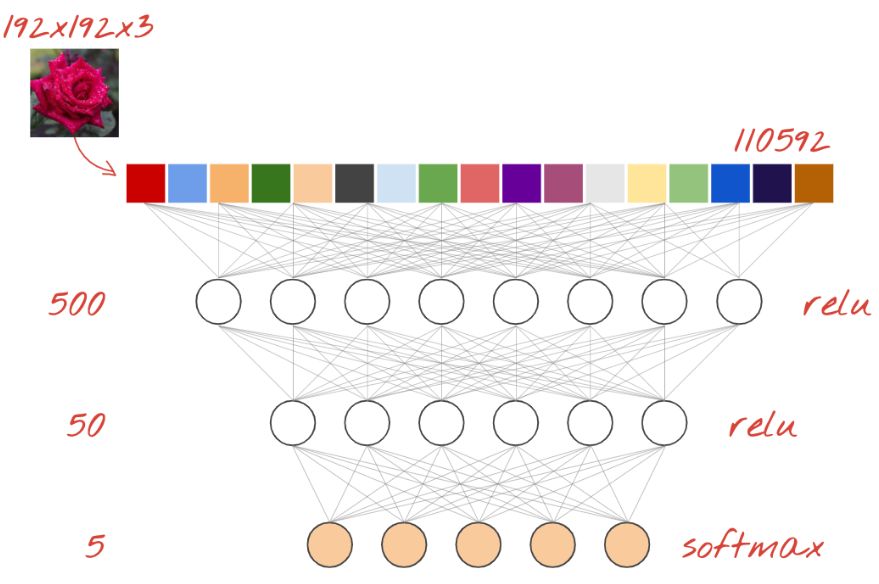
你可以將圖像的所有像素的 RGB 值展開為長矢量并將其用作輸入,從而將圖像輸入到此類網絡中。它不是圖像識別的最佳技術,但我們稍后會對其進行改進。
神經元
“神經元” 計算其所有輸入的并進行加權求和,添加一個稱為 “偏差” 的值,并通過所謂的 “激活函數” 提供結果。權重和偏差最初是未知的。它們將被隨機初始化并通過在許多已知數據上訓練神經網絡來 “學習”。
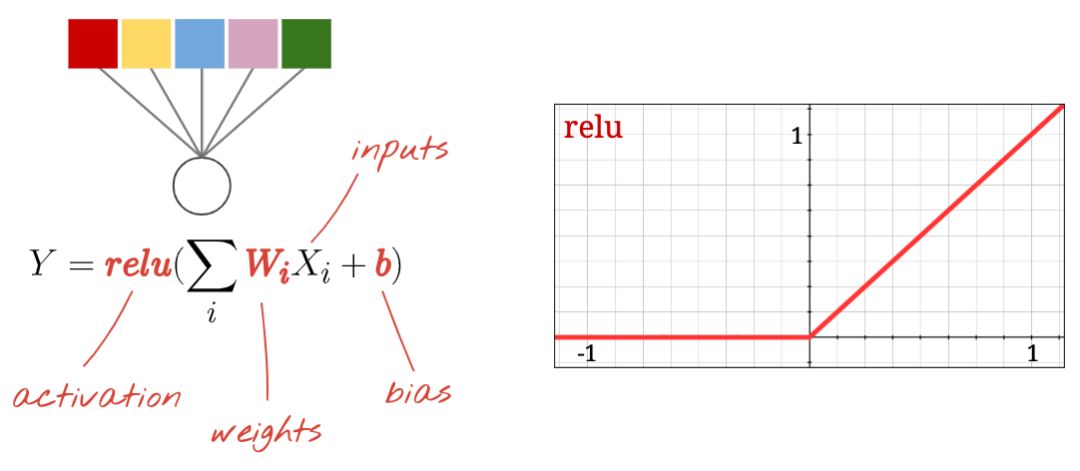
最流行的激活函數被稱為 RELU(Rectified Linear Unit)如上圖所示。
Softmax 激活
我們將花分為 5 類(玫瑰,郁金香,蒲公英,雛菊,向日葵),使用經典 RELU 激活函數。然而,在最后一層,我們想要計算 0 到 1 之間的數字,表示這朵花是玫瑰,郁金香等的概率。為此,我們將使用名為 “softmax” 的激活函數。
在矢量上應用 softmax 函數是通過取每個元素的指數然后歸一化矢量來完成的,通常使用 L1 范數(絕對值之和),使得這些值加起來可以解釋為概率。
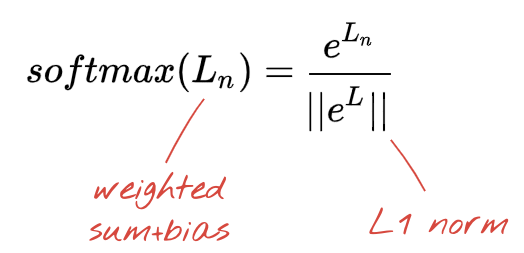
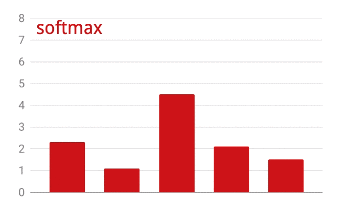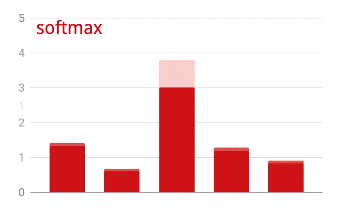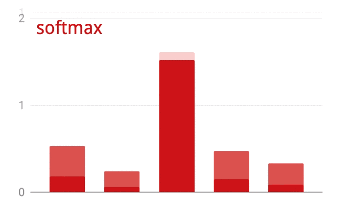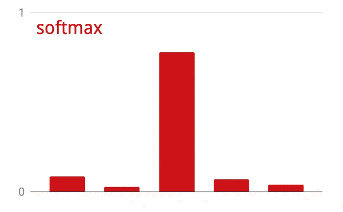
對于圖像分類問題,Dense 層可能是不夠的。但我們也可以另辟蹊徑!有完整的卷積神經網絡可供下載。我們可以切掉它們的最后一層 softmax 分類,并用下載的替換它。所有訓練過的權重和偏差保持不變,你只需重新訓練你添加的 softmax 層。這種技術被稱為遷移學習,只要預先訓練神經網絡的數據集與你的 “足夠接近”,它就可以工作。
請打開下面的 notebook,同時按住 Shift-ENTER 運行代碼:
https://codelabs.developers.google.com/codelabs/keras-flowers-convnets/#0
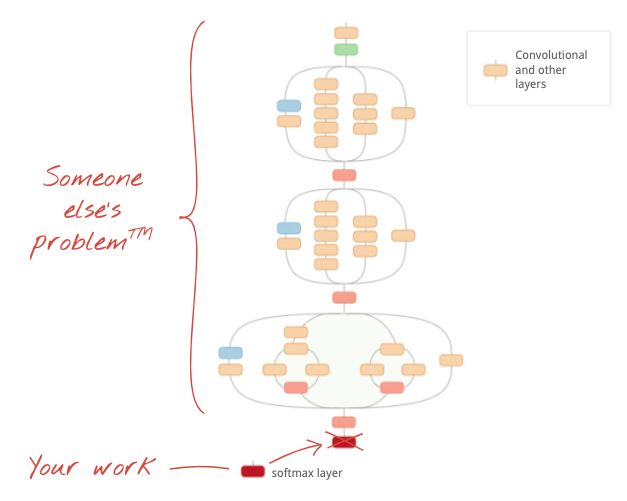
插圖:使用已經訓練過的復雜卷積神經網絡作為黑匣子,僅對分類的最后一層進行再訓練。這是遷移學習。
通過遷移學習,你可以從頂級研究人員已經開發的高級卷積神經網絡架構和大量圖像數據集的預訓練中受益。在我們的案例中,我們將從 ImageNet 訓練的網絡遷移學習。
在 Keras 中,可以從 tf.keras.applications.* 集合中實例化預先訓練的模型。例如,MobileNet V2 是一個非常好的卷積架構,其尺寸合理。通過選擇 include_top=False,你可以獲得沒有最終 softmax 圖層的預訓練模型,以便你可以添加自己的模型:
pretrained_model = tf.keras.applications.MobileNetV2(input_shape=[*IMAGE_SIZE, 3], include_top=False)pretrained_model.trainable = Falsemodel = tf.keras.Sequential([ pretrained_model, tf.keras.layers.Flatten(), tf.keras.layers.Dense(5, activation='softmax')])
另請注意 pretrained_model.trainable = False 設置。它凍結了預訓練模型的權重和偏差,因此你只能訓練 softmax 圖層。這通常針對相對較少的權重并且可以快速完成而無需非常大的數據集。但是,如果你確實擁有大量數據,那么 pretrained_model.trainable = True 可以讓遷移學習更好地工作。然后,經過預先訓練的權重可提供出色的初始值,并且仍可通過訓練進行調整,以更好地適應你的問題。
最后,請注意在 dense softmax 層前插入 Flatten()層。Dense 層對數據的平面向量起作用,但我們不知道這是否是預訓練模型返回的內容,這就是我們需要扁平化的原因。在下一章中,當我們深入研究卷積體系結構時,我們將解釋卷積層返回的數據格式。
在 Keras 中利用 TPU 組建卷積神經網絡
本次實驗,完成三個目標:
使用 Keras Sequential 模型構建卷積圖像分類器。
在 TPU 上訓練 Keras 模型
使用良好的卷積層選擇來微調模型。
卷積將神經網絡將一系列濾波器應用于圖像的原始像素數據以提取和學習更高級別的特征,使得該模型能夠將這些特征用于分類。卷積將神經網絡包含三個組件:
卷積層,將特定數量的卷積濾鏡(convolution filters)應用于圖像。對于每個子區域,圖層執行一組數學運算以在輸出特征映射中生成單個值。
池化層(Pooling layers),負責對由卷積層提取的圖像數據進行下采樣以減少特征映射的維度以提高處理效率。常用的池化算法是最大池化,其提取特征地圖的子區域(例如,2×2 像素的塊),保持它們的最大值并丟棄所有其他值。
Dense 層,對由卷積圖層提取的特征并由共用圖層進行下采樣執行分類。Dense 層是全連接的神經網絡,在 Dense 層中,圖層中的每個節點都連接到前一圖層中的每個節點。
用最大池化做卷積的動畫示例如下?

用 Softmax 激活函數連接分類器,典型的卷積分類器如下?
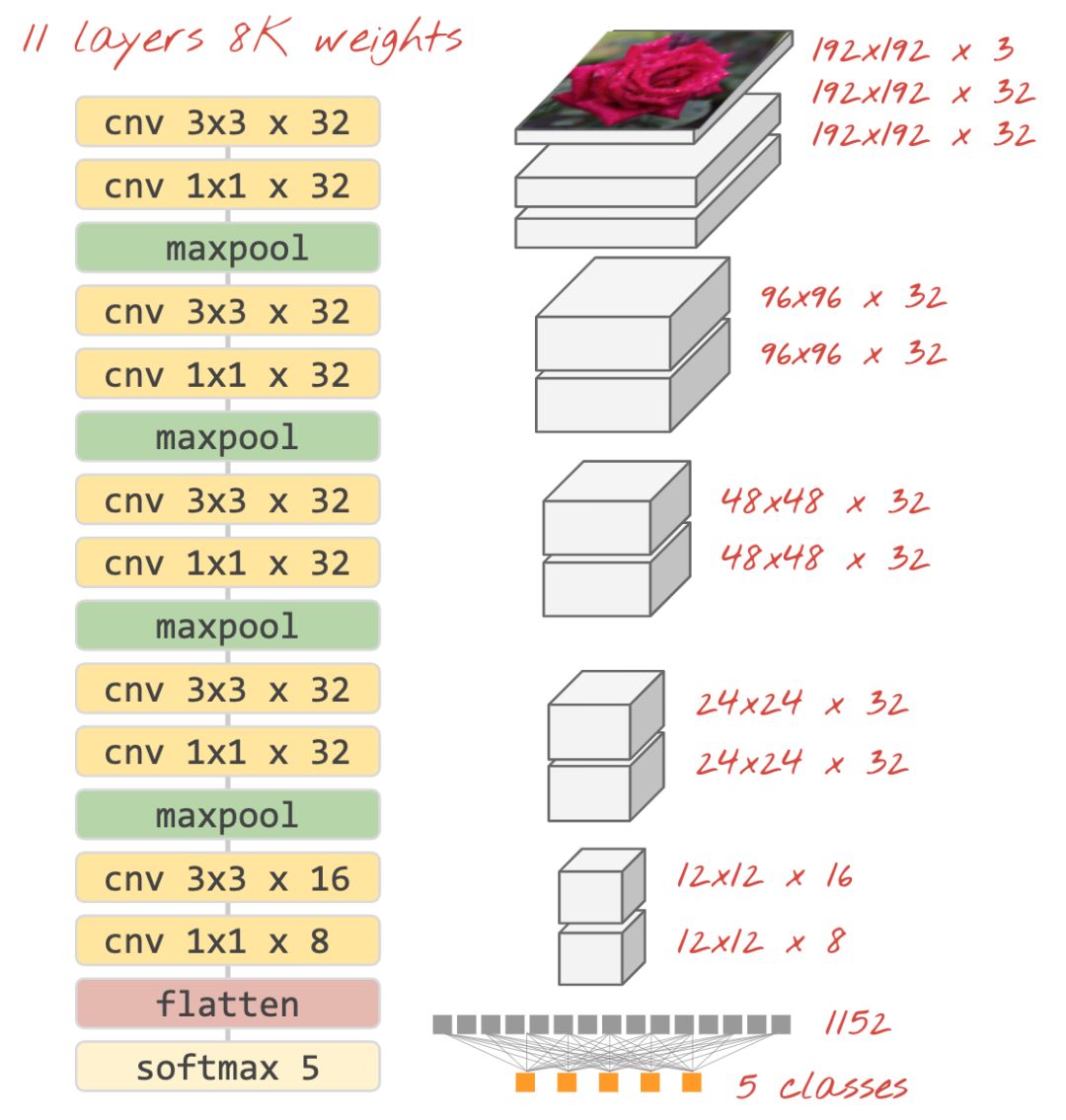
在 keras 中搭建神經網絡代碼如下:
model = tf.keras.Sequential([# input: images of size 192x192x3 pixels (the three stands for RGB channels) tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu', input_shape=[192, 192, 3]), tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(pool_size=2), tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(pool_size=2), tf.keras.layers.Conv2D(kernel_size=3, filters=6, padding='same', activation='relu'), tf.keras.layers.Flatten(),# classifying into 5 categories tf.keras.layers.Dense(5, activation='softmax')])model.compile( optimizer='adam', loss= 'categorical_crossentropy', metrics=['accuracy'])
在搭建的過程中,必須在權重和偏差之間找到適當的平衡點,如果權重太大,神經網絡可能無法代表復雜性,如果參數太多,可能導致過擬合。所以在在 Keras 中,用 model.summary () 函數顯示模型的結構和參數:

具體代碼地址:
https://colab.research.google.com/github/GoogleCloudPlatform/training-data-analyst/blob/master/courses/fast-and-lean-data-science/07_Keras_Flowers_TPU_playground.ipynb
在 Keras 中利用 TPU 組建現代卷積網絡和實現分類
之前三個實驗已經分別介紹了 TPU、遷移學習和卷積網絡,是不是已經覺得很厲害了?別著急,最后的大招來了,本次實驗我們將實現在 Keras 中利用 TPU 組建現代卷積網絡和實現分類。
現代卷積架構(Modern convolutions networks)
簡而言之,從 "Inception" 和 "Inception v2" 開始的現代卷積網絡通常使用 “模塊”,其中在同一輸入上同時嘗試不同的卷積層,它們的輸出被連接并且網絡通過訓練決定哪個層是最有用的。
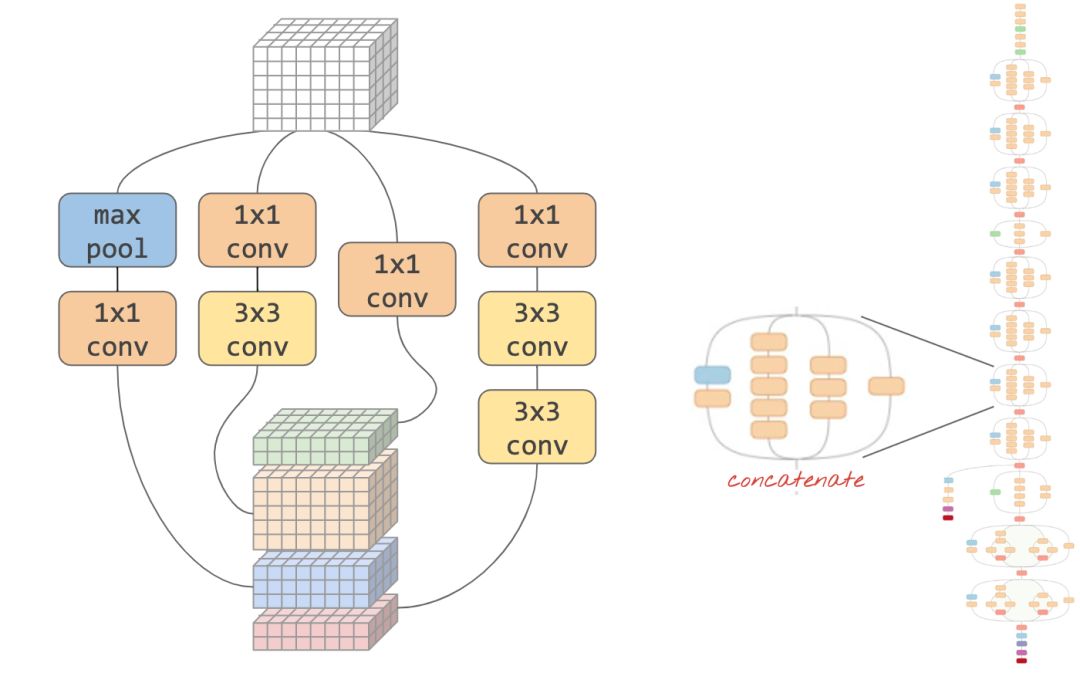
在 Keras 中,要創建數據流可以分支進出的模型,必須使用 “functional” 模型。這是一個例子:
l = tf.keras.layers # syntax shortcuty = l.Conv2D(filters=32, kernel_size=3, padding='same', activation='relu', input_shape=[192, 192, 3])(x) # x=input image# module start: branch outy1 = l.Conv2D(filters=32, kernel_size=1, padding='same', activation='relu')(y)y3 = l.Conv2D(filters=32, kernel_size=3, padding='same', activation='relu')(y)y = l.concatenate([y1, y3]) # output now has 64 channels# module end: concatenation# many more layers ...# Create the model by specifying the input and output tensors.# Keras layers track their connections automatically so that's all that's needed.z = l.Dense(5, activation='softmax')(y)model = tf.keras.Model(x, z)
其他小技巧
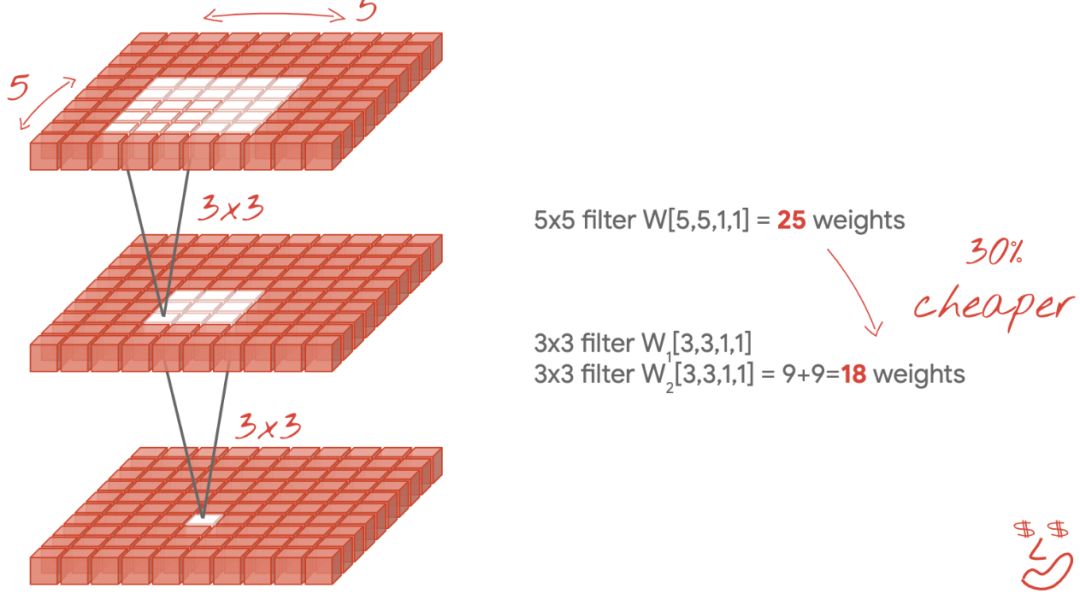
小型 3x3 濾波器
在此圖中,你可以看到兩個連續 3x3濾波器的結果。嘗試追溯哪些數據點對結果有貢獻:這兩個連續的 3x3濾波器計算 5x5 區域的某種組合。它與 5x5 濾波器計算的組合并不完全相同,但值得嘗試,因為兩個連續的 3x3 濾波器比單個 5x5 濾波器效率更高。
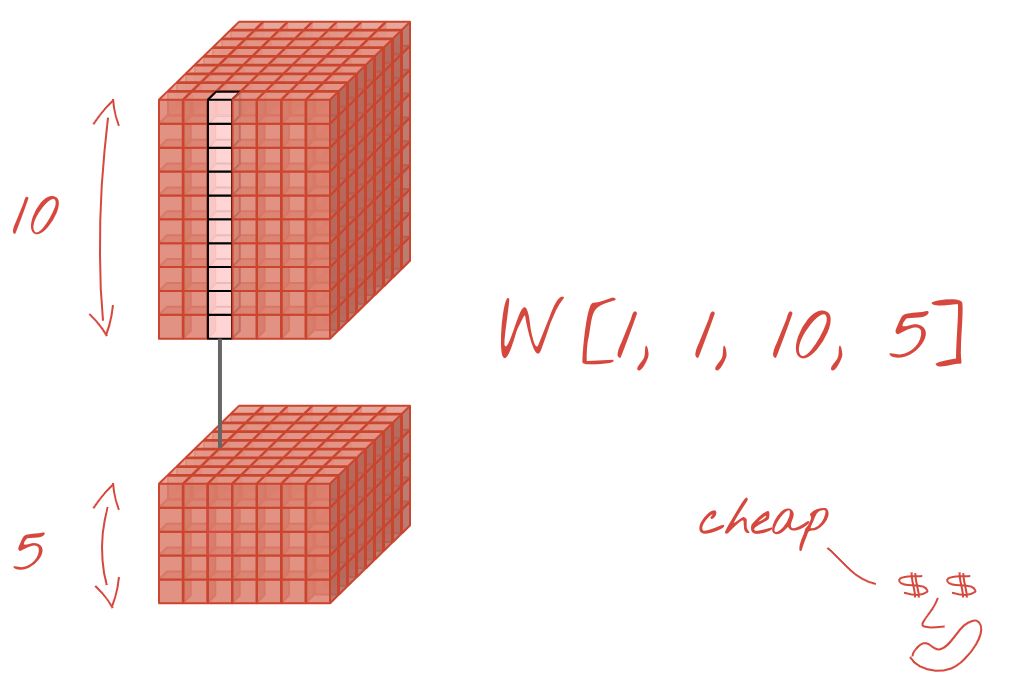
1x1 卷積?
在數學術語中,“1x1” 卷積是常數的乘法,而不是非常有用的概念。但是,在卷積神經網絡中,請記住濾波器應用于數據立方體,而不僅僅是 2D 圖像。因此,“1x1” 濾波器計算 1x1 數據列的加權和(參見圖示),當你在數據中滑動時,你將獲得輸入通道的線性組合。這實際上很有用。如果你將通道視為單個過濾操作的結果,例如 “貓耳朵” 的過濾器,另一個用于 “貓胡須”,第三個用于 “貓眼睛”,則 “1x1” 卷積層將計算多個這些特征的可能線性組合,在尋找 “貓” 時可能很有用。
Squeezenet
將這些想法融合在一起的簡單方法已在 “Squeezenet” 論文中展示,即一種僅使用 1x1 和 3x3 卷積層的卷積模塊設計。
https://arxiv.org/abs/1602.07360
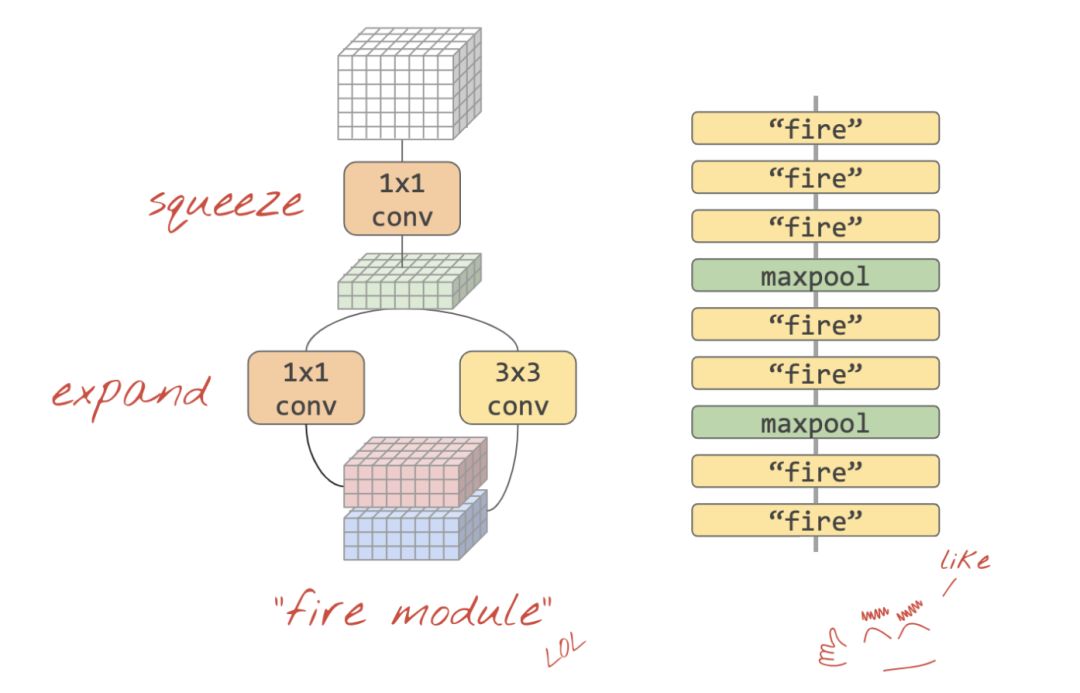
基于 “fire model” 的 squeezenet 架構。它們交替使用 1x1 層,在垂直維度上 “擠壓” 輸入數據,然后是兩個并行的 1x1 和 3x3 卷積層,再次 “擴展” 數據深度。
構建一個受 squeezenet 啟發的卷積神經網絡時,我們就不能直接像上面一樣直接堆疊已有模塊,需要將模型代碼更改為 Keras 的 “功能樣式”,來定義自己的模塊。
想要嘗試 Squeezenet 架構練習的戳以下鏈接:
https://codelabs.developers.google.com/codelabs/keras-flowers-squeezenet/#6
最后,手把手教程運行代碼如下:
https://colab.research.google.com/github/GoogleCloudPlatform/training-data-analyst/blob/master/courses/fast-and-lean-data-science/07_Keras_Flowers_TPU_playground.ipynb
最后,再次給出四個實驗的鏈接,供參考喲~
https://codelabs.developers.google.com/codelabs/keras-flowers-data/#2
https://codelabs.developers.google.com/codelabs/keras-flowers-transfer-learning/#2
https://codelabs.developers.google.com/codelabs/keras-flowers-convnets/#0
https://codelabs.developers.google.com/codelabs/keras-flowers-squeezenet/#0
此項目支持答疑,打開下列網址提交你的問題
https://colab.research.google.com/github/GoogleCloudPlatform/training-data-analyst/blob/master/courses/fast-and-lean-data-science/07_Keras_Flowers_TPU_squeezenet.ipynb
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100714 -
python
+關注
關注
56文章
4792瀏覽量
84627 -
遷移學習
+關注
關注
0文章
74瀏覽量
5559
原文標題:Colab 超火的 Keras/TPU 深度學習免費實戰,有點 Python 基礎就能看懂的快速課程
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
INA301為什么在共模信號給到5V多一點點的時候,偏置電流會突然變大那么多?
什么都感覺會一點點腫么辦,求大神支招
對交流共模電壓的一點點認識
Python2.5安裝教程和Python搭建開發環境的詳細資料免費下載
用Python從頭實現一個神經網絡來理解神經網絡的原理1

用Python從頭實現一個神經網絡來理解神經網絡的原理2

用Python從頭實現一個神經網絡來理解神經網絡的原理3

用Python從頭實現一個神經網絡來理解神經網絡的原理4






 工商網監
工商網監
評論