


預(yù)測(cè)是機(jī)器學(xué)習(xí)算法最重要的一個(gè)研究方向。眾多保險(xiǎn)公司利用機(jī)器學(xué)習(xí)算法為他們的客戶(hù)建立預(yù)測(cè)模型。其中,車(chē)禍預(yù)測(cè)模型是眾多模型里面最難建立的。
車(chē)禍發(fā)生的影響因素多種多樣,變化多端,著實(shí)讓人摸不著頭腦。
與其他商品不同的是,車(chē)禍保單的最終成本在初始銷(xiāo)售時(shí)是未知的。因此,建立一個(gè)合理的定價(jià)機(jī)制是非常具有挑戰(zhàn)的。有些保險(xiǎn)公司嘗試使用統(tǒng)計(jì)方法來(lái)解決這一問(wèn)題:預(yù)測(cè)每個(gè)客戶(hù)的未來(lái)風(fēng)險(xiǎn)。
例如,非常經(jīng)典的汽車(chē)保險(xiǎn)。大部分的保險(xiǎn)公司確定的保險(xiǎn)風(fēng)險(xiǎn)因素有司機(jī)的年齡、他的汽車(chē)配置相關(guān)以及汽車(chē)發(fā)生事故的歷史情況。這也是為什么保險(xiǎn)公司會(huì)在成交汽車(chē)保險(xiǎn)之前需要客戶(hù)提供的詳細(xì)信息的原因。
波蘭華沙大學(xué)經(jīng)濟(jì)科學(xué)系的Kinga Kita-Wojciechowska和斯坦福大學(xué)生物工程系的?ukasz Kidziński利用谷歌Google街景收集相對(duì)應(yīng)的房屋圖像,通過(guò)標(biāo)釋房屋的特征:例如年齡、類(lèi)型以及其它條件。然后與目前最先進(jìn)的保險(xiǎn)風(fēng)險(xiǎn)模型相比,最后發(fā)現(xiàn)用谷歌街景數(shù)據(jù)建立的模型,能夠有效地改進(jìn)了汽車(chē)事故風(fēng)險(xiǎn)預(yù)測(cè)。
作者通過(guò)對(duì)谷歌街景數(shù)據(jù)的研究,發(fā)現(xiàn)下列結(jié)論?
房子的特征與居民的發(fā)生車(chē)禍風(fēng)險(xiǎn)相關(guān),
與谷歌街景的其他研究用途相比,此模型數(shù)據(jù)特征來(lái)自于地址,并不是按照郵政編碼或地區(qū)進(jìn)行匯總,可能存在更為精細(xì)的劃分;
從地址中提取的數(shù)據(jù)(房屋的圖像)可用于保險(xiǎn)和其他行業(yè);
現(xiàn)代數(shù)據(jù)收集和科技技術(shù)允許對(duì)個(gè)人數(shù)據(jù)進(jìn)行前所未有的利用,可能會(huì)超過(guò)立法的發(fā)展速度,并增加個(gè)人隱私威脅。
建模數(shù)據(jù)收集方法與特點(diǎn)
保險(xiǎn)公司之前進(jìn)行的風(fēng)險(xiǎn)建模和定價(jià),通常只使用郵政編碼這一特征。然而匯總到郵政編碼的索賠數(shù)據(jù)仍然太不穩(wěn)定,所以還需要進(jìn)一步地調(diào)整。
另一方面,對(duì)于一些“外人”來(lái)說(shuō),保險(xiǎn)公司客戶(hù)的信息數(shù)據(jù)很難獲得。本文使用的谷歌街景數(shù)據(jù)可以從來(lái)自Google街景的公開(kāi)圖像信息中提取出來(lái)。
圖1.位于同一郵政編碼中不同房屋的示例,根據(jù)當(dāng)前保險(xiǎn)公司的模型,這些房屋的居民具有相同的預(yù)期索賠頻率。
此數(shù)據(jù)集包含20,000條記錄的汽車(chē)保險(xiǎn)數(shù)據(jù)集,數(shù)據(jù)來(lái)源于2012年1月至2015年12月期間收集到在波蘭的保險(xiǎn)投資組合的隨機(jī)樣本。
其中每項(xiàng)記錄均涵蓋汽車(chē)發(fā)動(dòng)機(jī)第三方責(zé)任(MTPL)保險(xiǎn)單的特點(diǎn),包括投保人的地址、風(fēng)險(xiǎn)敞口(定義為一小部分有效年份在2013-2015年期間的保單)以及2013-2015年間發(fā)生的財(cái)產(chǎn)損壞索賠的統(tǒng)計(jì)數(shù)量。保險(xiǎn)公司還提供了這些保單的財(cái)產(chǎn)損失索賠的預(yù)期頻率,是根據(jù)他們目前最好的風(fēng)險(xiǎn)模型進(jìn)行估計(jì)的,是根據(jù)客戶(hù)的郵政編碼進(jìn)行分區(qū)的。

圖2.使用注釋功能將為數(shù)據(jù)庫(kù)中提供的地址,匹配收集谷歌衛(wèi)星視圖和谷歌街景圖像。
對(duì)圖像中可見(jiàn)的房屋中以下特征作了說(shuō)明:居民的年齡、狀況、財(cái)富以及鄰近地區(qū)其他建筑物的類(lèi)型。根據(jù)Fleiss’kappa(屬性型測(cè)量分析)統(tǒng)計(jì)數(shù)據(jù)結(jié)果表明,它們之間大多數(shù)是一致穩(wěn)健的。
繼續(xù)注釋剩余的19,371個(gè)地址(還從本研究的范圍中刪除了129個(gè)地址,因?yàn)樗鼈円词橇硗鈪^(qū)域的,要么是Google地圖找不到的),剩余的都將得到了一組單獨(dú)的、隨機(jī)選擇的地址。
研究者比較了收集到的注釋的分布情況,并在最后對(duì)四個(gè)注釋器進(jìn)行了小的修正,以匹配平均值和標(biāo)準(zhǔn)差。
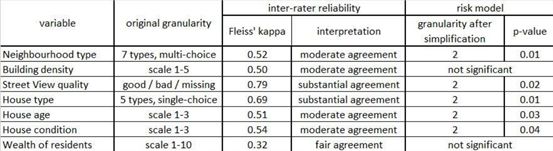
表1。在進(jìn)行了必要的簡(jiǎn)化后,風(fēng)險(xiǎn)模型中對(duì)7個(gè)新創(chuàng)建的變量進(jìn)行了統(tǒng)計(jì)
建模過(guò)程
接下來(lái),估計(jì)一個(gè)廣義線(xiàn)性模型(GLM)來(lái)研究新創(chuàng)建的變量對(duì)于風(fēng)險(xiǎn)預(yù)測(cè)的重要性。
假設(shè)索賠的概率模型如下:
頻率為f,定義為索賠次數(shù)除以風(fēng)險(xiǎn)敞口:
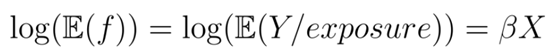
其中,MTPL保險(xiǎn)中的一些財(cái)產(chǎn)損失索賠是服從泊松分布的,X是自變量的向量,也是系數(shù)的向量。
為了對(duì)方法所帶來(lái)的增加值進(jìn)行評(píng)價(jià),引入了三個(gè)模型:
模型A(空模型),其中向量為
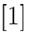
模型B(一流保險(xiǎn)商模型):其中向量為
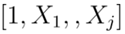
模型C(研究者使用的模型):其中向量為
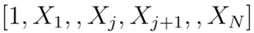
保險(xiǎn)人為數(shù)據(jù)集中的每條記錄提供了模型B的實(shí)現(xiàn)。
該模型是在一個(gè)更大的未對(duì)外披露數(shù)據(jù)集上進(jìn)行估計(jì)的,包含j個(gè)預(yù)測(cè)變量(駕駛員特征、車(chē)輛特征、索賠歷史、地理區(qū)域等)。
利用GLMs的特性,可以將模型C分解為兩個(gè)部分:一個(gè)對(duì)應(yīng)于模型B,另一個(gè)則包含新變量。
因此,模型C為:
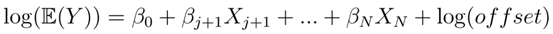
這些系數(shù)的值是否為非零,將表明研究者構(gòu)造的變量為模型提供了額外的預(yù)測(cè)能力。在本研究中新創(chuàng)建的七個(gè)變量中,有五個(gè)對(duì)于預(yù)測(cè)財(cái)產(chǎn)損壞MTPL索賠頻率模型具有重要意義,而在最好的保險(xiǎn)公司模型中使用的許多其它評(píng)級(jí)變量都是重要的(表1)。
通過(guò)觀察a、B、C模型的基尼系數(shù)的顯著變異性,特別是對(duì)于模型A(只包含截距且沒(méi)有選擇其他變量的空模型)在20次重采樣試驗(yàn)中,其變化范圍為20 ~ 38%。將其解釋為證據(jù),即所提供的數(shù)據(jù)集非常小(20,000條記錄),用于構(gòu)建MTPL保險(xiǎn)中的罕見(jiàn)事件,如財(cái)產(chǎn)損失索賠(平均頻率為5%)。
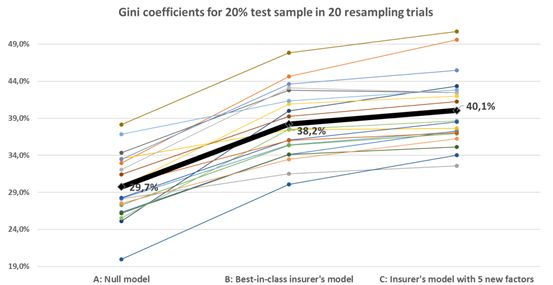
圖3.在20個(gè)自舉試驗(yàn)中獲得的20%的檢驗(yàn)樣本上的基尼系數(shù)(A),從零模型(A)到最好的保險(xiǎn)公司的模型(B)和研究者新建立的變量模型(C)。
盡管數(shù)據(jù)的波動(dòng)性很大,但將五個(gè)簡(jiǎn)單變量加入到保險(xiǎn)公司的模型中,在20次重新采樣試驗(yàn)中的18次中嘗試,提高了它的性能,并提高了基尼系數(shù)的平均水平。提高系數(shù)接近2個(gè)百分點(diǎn)(從38.2%到40.1%)。
通常保險(xiǎn)公司的模型會(huì)運(yùn)用更大的數(shù)據(jù)集,并包含了廣泛的變量選擇(例如駕駛員特征、汽車(chē)特征、索賠歷史和基于客戶(hù)郵政編碼的地理區(qū)域),將基尼系數(shù)與空模型從0~30%提高到0~38%,提高了8個(gè)百分點(diǎn)(見(jiàn)圖3)。
創(chuàng)新之處
通常保險(xiǎn)公司的預(yù)測(cè)模型都是以常規(guī)的特征進(jìn)行預(yù)測(cè)的,比如駕駛車(chē)輛習(xí)慣,索賠歷史和客戶(hù)財(cái)富級(jí)別等特征。
但是文中的模型使用了全新的谷歌街景地圖的特征,比如街景地圖中房屋所在周?chē)h(huán)境,所在區(qū)域的密度,街景的質(zhì)量和房屋類(lèi)型年限等特征,評(píng)測(cè)結(jié)果也是比較令人欣慰,三個(gè)模型的基尼系數(shù)變動(dòng)范圍在20%—38%之間,我們能從圖3中看見(jiàn),經(jīng)過(guò)20次的重采樣實(shí)驗(yàn)得到的結(jié)果:具有街景新特征的模型比使用原有的優(yōu)秀傳統(tǒng)模型還要高出接近2個(gè)百分點(diǎn)。
當(dāng)然由于數(shù)據(jù)樣本量比較少,大概只有2萬(wàn)條左右,所以這也在一定程度上影響了基尼系數(shù)的提升。但是這在預(yù)測(cè)模型的研究方向中,給了我們一個(gè)新的思路,原來(lái)街景地圖的特征會(huì)比傳統(tǒng)的特征更加有效。當(dāng)然未來(lái)肯定還會(huì)有更加有效的特征出現(xiàn),來(lái)幫助我們提升預(yù)測(cè)準(zhǔn)確度。
總結(jié)
從一張房子的圖像中可見(jiàn)的特征預(yù)測(cè)發(fā)生車(chē)禍的風(fēng)險(xiǎn),而且獨(dú)立于經(jīng)常使用的變量,如年齡或郵政編碼。
這一發(fā)現(xiàn)邁出了一大步。它不僅提供了更為精確的風(fēng)險(xiǎn)預(yù)測(cè)模型,而且還說(shuō)明了社會(huì)科學(xué)的一種新方法。
在這種方法中,真實(shí)世界中的細(xì)粒度數(shù)據(jù)可以經(jīng)過(guò)大規(guī)模收集后進(jìn)行分析。從保險(xiǎn)公司的實(shí)際情況來(lái)看,給出的實(shí)驗(yàn)結(jié)果是顯著的。研究者使用的模型中的5個(gè)變量包含了來(lái)自不完全注釋的一些偏差,與保險(xiǎn)公司在其最佳風(fēng)險(xiǎn)模型中已經(jīng)使用的眾多變量帶來(lái)的8個(gè)百分點(diǎn)的改進(jìn)相比,基尼系數(shù)提高了近2個(gè)百分點(diǎn)。
保險(xiǎn)行業(yè)可能很快就會(huì)被銀行效仿,因?yàn)楸kU(xiǎn)風(fēng)險(xiǎn)模型與信用風(fēng)險(xiǎn)之間存在著已被證明的相關(guān)性。從谷歌街景(GoogleStreetView)中提取有價(jià)值信息的方法本身,不僅為金融業(yè)提供了各種機(jī)會(huì)。
此方法和深層次的學(xué)習(xí)技術(shù)可以使它在一個(gè)大規(guī)模自動(dòng)化的模型中進(jìn)行。同時(shí),這種做法引起了人們對(duì)存儲(chǔ)在公開(kāi)可用的Google街景、Microsoft Bing Streetside、Mapillary或類(lèi)似的私有數(shù)據(jù)集中的數(shù)據(jù)隱私的擔(dān)憂(yōu)。
-
谷歌
+關(guān)注
關(guān)注
27文章
6231瀏覽量
108001 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8500瀏覽量
134503
原文標(biāo)題:斯坦福最新研究:看圖“猜車(chē)禍”,用谷歌街景數(shù)據(jù)建立車(chē)禍預(yù)測(cè)新模型
文章出處:【微信號(hào):BigDataDigest,微信公眾號(hào):大數(shù)據(jù)文摘】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
預(yù)測(cè)性維護(hù)實(shí)戰(zhàn):如何通過(guò)數(shù)據(jù)模型實(shí)現(xiàn)故障預(yù)警?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論