 干貨 | 人臉識別技術全面總結:從傳統方法到深度學習
干貨 | 人臉識別技術全面總結:從傳統方法到深度學習
人臉識別是指能夠識別或驗證圖像或視頻中的主體的身份的技術。首個人臉識別算法誕生于七十年代初 [1,2]。自那以后,它們的準確度已經大幅提升,現在相比于指紋或虹膜識別 [3] 等傳統上被認為更加穩健的生物識別方法,人們往往更偏愛人臉識別。讓人臉識別比其它生物識別方法更受歡迎的一大不同之處是人臉識別本質上是非侵入性的。比如,指紋識別需要用戶將手指按在傳感器上,虹膜識別需要用戶與相機靠得很近,語音識別則需要用戶大聲說話。相對而言,現代人臉識別系統僅需要用戶處于相機的視野內(假設他們與相機的距離也合理)。這使得人臉識別成為了對用戶最友好的生物識別方法。這也意味著人臉識別的潛在應用范圍更廣,因為它也可被部署在用戶不期望與系統合作的環境中,比如監控系統中。人臉識別的其它常見應用還包括訪問控制、欺詐檢測、身份認證和社交媒體。
當被部署在無約束條件的環境中時,由于人臉圖像在現實世界中的呈現具有高度的可變性(這類人臉圖像通常被稱為自然人臉(faces in-the-wild)),所以人臉識別也是最有挑戰性的生物識別方法之一。人臉圖像可變的地方包括頭部姿勢、年齡、遮擋、光照條件和人臉表情。圖 1 給出了這些情況的示例。
主成分分析
線性判別分析
人臉識別系統通常由以下構建模塊組成:

很多人認為人臉表征是人臉識別系統中最重要的組件,這也是本論文第二節所關注的重點。
深度學習方法
卷積神經網絡(CNN)是人臉識別方面最常用的一類深度學習方法。深度學習方法的主要優勢是可用大量數據來訓練,從而學到對訓練數據中出現的變化情況穩健的人臉表征。這種方法不需要設計對不同類型的類內差異(比如光照、姿勢、面部表情、年齡等)穩健的特定特征,而是可以從訓練數據中學到它們。深度學習方法的主要短板是它們需要使用非常大的數據集來訓練,而且這些數據集中需要包含足夠的變化,從而可以泛化到未曾見過的樣本上。幸運的是,一些包含自然人臉圖像的大規模人臉數據集已被公開 [9-15],可被用來訓練 CNN 模型。除了學習判別特征,神經網絡還可以降維,并可被訓練成分類器或使用度量學習方法。CNN 被認為是端到端可訓練的系統,無需與任何其它特定方法結合。
用于人臉識別的 CNN 模型可以使用不同的方法來訓練。其中之一是將該問題當作是一個分類問題,訓練集中的每個主體都對應一個類別。訓練完之后,可以通過去除分類層并將之前層的特征用作人臉表征而將該模型用于識別不存在于訓練集中的主體 [99]。在深度學習文獻中,這些特征通常被稱為瓶頸特征(bottleneck features)。在這第一個訓練階段之后,該模型可以使用其它技術來進一步訓練,以為目標應用優化瓶頸特征(比如使用聯合貝葉斯 [9] 或使用一個不同的損失函數來微調該 CNN 模型 [10])。另一種學習人臉表征的常用方法是通過優化配對的人臉 [100,101] 或人臉三元組 [102] 之間的距離度量來直接學習瓶頸特征。
自組織映射
上面提到的方法都未能取得突破性的成果,主要原因是使用了能力不足的網絡,且訓練時能用的數據集也相對較小。直到這些模型得到擴展并使用大量數據 [107] 訓練后,用于人臉識別的首個深度學習方法 [99,9] 才達到了當前最佳水平。尤其值得一提的是 Facebook 的 DeepFace [99],這是最早的用于人臉識別的 CNN 方法之一,其使用了一個能力很強的模型,在 LFW 基準上實現了 97.35% 的準確度,將之前最佳表現的錯誤率降低了 27%。研究者使用 softmax 損失和一個包含 440 萬張人臉(來自 4030 個主體)的數據集訓練了一個 CNN。本論文有兩個全新的貢獻:(1)一個基于明確的 3D 人臉建模的高效的人臉對齊系統;(2)一個包含局部連接的層的 CNN 架構 [108,109],這些層不同于常規的卷積層,可以從圖像中的每個區域學到不同的特征。在那同時,DeepID 系統 [9] 通過在圖塊(patch)上訓練 60 個不同的 CNN 而得到了相近的結果,這些圖塊包含十個區域、三種比例以及 RGB 或灰度通道。在測試階段,會從每個圖塊提取出 160 個瓶頸特征,加上其水平翻轉后的情況,可形成一個 19200 維的特征向量(160×2×60)。類似于 [99],新提出的 CNN 架構也使用了局部連接的層。其驗證結果是通過在這種由 CNN 提取出的 19200 維特征向量上訓練一個聯合貝葉斯分類器 [48] 得到的。訓練該系統所使用的數據集包含 202599 張人臉圖像,來自 10177 位名人 [9]。
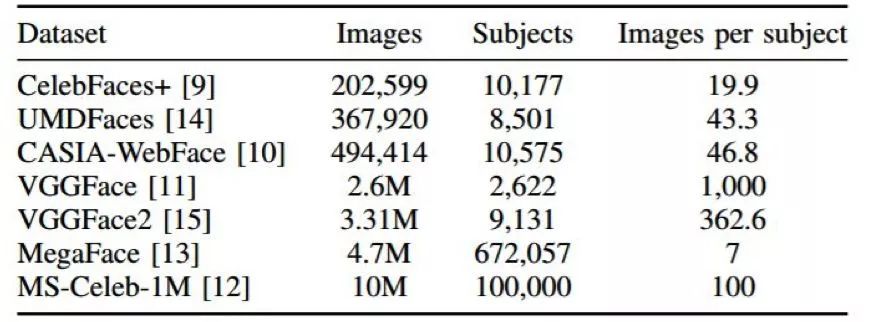
對于基于 CNN 的人臉識別方法,影響準確度的因素主要有三個:訓練數據、CNN 架構和損失函數。因為在大多數深度學習應用中,都需要大訓練集來防止過擬合。一般而言,為分類任務訓練的 CNN 的準確度會隨每類的樣本數量的增長而提升。這是因為當類內差異更多時,CNN 模型能夠學習到更穩健的特征。但是,對于人臉識別,我們感興趣的是提取出能夠泛化到訓練集中未曾出現過的主體上的特征。因此,用于人臉識別的數據集還需要包含大量主體,這樣模型也能學習到更多類間差異。[110] 研究了數據集中主體的數量對人臉識別準確度的影響。在這項研究中,首先以降序形式按照每個主體的圖像數量對一個大數據集進行了排序。然后,研究者通過逐漸增大主體數量而使用訓練數據的不同子集訓練了一個 CNN。當使用了圖像數量最多的 10000 個主體進行訓練時,得到的準確度是最高的。增加更多主體會降低準確度,因為每個額外主體可用的圖像非常少。另一項研究 [111] 研究了更寬度的數據集更好,還是更深度的數據集更好(如果一個數據集包含更多主體,則認為它更寬;類似地,如果每個主體包含的圖像更多,則認為它更深)。這項研究總結到:如果圖像數量相等,則更寬的數據集能得到更好的準確度。研究者認為這是因為更寬度的數據集包含更多類間差異,因而能更好地泛化到未曾見過的主體上。表 1 展示了某些最常用于訓練人臉識別 CNN 的公開數據集。
用于人臉識別的 CNN 架構從那些在 ImageNet 大規模視覺識別挑戰賽(ILSVRC)上表現優異的架構上取得了很多靈感。舉個例子,[11] 中使用了一個帶有 16 層的 VGG 網絡 [112] 版本,[10] 中則使用了一個相似但更小的網絡。[102] 中探索了兩種不同類型的 CNN 架構:VGG 風格的網絡 [112] 和 GoogleNet 風格的網絡 [113]。即使這兩種網絡實現了相當的準確度,但 GoogleNet 風格的網絡的參數數量少 20 倍。更近段時間,殘差網絡(ResNet)[114] 已經成為了很多目標識別任務的最受偏愛的選擇,其中包括人臉識別 [115-121]。ResNet 的主要創新點是引入了一種使用捷徑連接的構建模塊來學習殘差映射,如圖 7 所示。捷徑連接的使用能讓研究者訓練更深度的架構,因為它們有助于跨層的信息流動。[121] 對不同的 CNN 架構進行了全面的研究。在準確度、速度和模型大小之間的最佳權衡是使用帶有一個殘差模塊(類似于 [122] 中提出的那種)的 100 層 ResNet 得到的。
選擇用于訓練 CNN 方法的損失函數已經成為近來人臉識別最活躍的研究領域。即使使用 softmax 損失訓練的 CNN 已經非常成功 [99,9,10,123],但也有研究者認為使用這種損失函數無法很好地泛化到訓練集中未出現過的主體上。這是因為 softmax 損失有助于學習能增大類間差異的特征(以便在訓練集中區別不同的類),但不一定會降低類內差異。研究者已經提出了一些能緩解這一問題的方法。優化瓶頸特征的一種簡單方法是使用判別式子空間方法,比如聯合貝葉斯 [48],就像 [9,124,125,126,10,127] 中所做的那樣。另一種方法是使用度量學習。比如,[100,101] 中使用了配對的對比損失來作為唯一的監督信號,[124-126] 中還結合使用了分類損失。人臉識別方面最常用的度量學習方法是三元組損失函數 [128],最早在 [102] 中被用于人臉識別任務。三元組損失的目標是以一定余量分開正例對之間的距離和負例對之間的距離。從數學形式上講,對于每個三元組 i,需要滿足以下條件 [102]:
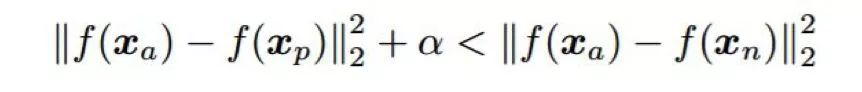
其中 x_a 是錨圖像,x_p 是同一主體的圖像,x_n 是另一個不同主體的圖像,f 是模型學習到的映射關系,α 施加在正例對和負例對距離之間的余量。在實踐中,使用三元組損失訓練的 CNN 的收斂速度比使用 softmax 的慢,這是因為需要大量三元組(或對比損失中的配對)才能覆蓋整個訓練集。盡管這個問題可以通過在訓練階段選擇困難的三元組(即違反余量條件的三元組)來緩解 [102],但常見的做法是在第一個訓練階段使用 softmax 損失訓練,在第二個訓練階段使用三元組損失來對瓶頸特征進行調整 [11,129,130]。研究者們已經提出了三元組損失的一些變體。比如 [129] 中使用了點積作為相似度度量,而不是歐幾里德距離;[130] 中提出了一種概率式三元組損失;[131,132] 中提出了一種修改版的三元組損失,它也能最小化正例和負例分數分布的標準差。用于學習判別特征的另一種損失函數是 [133] 中提出的中心損失(centre loss)。中心損失的目標是最小化瓶頸特征與它們對應類別的中心之間的距離。通過使用 softmax 損失和中心損失進行聯合訓練,結果表明 CNN 學習到的特征能夠有效增大類間差異(softmax 損失)和降低類內個體差異(中心損失)。相比于對比損失和三元組損失,中心損失的優點是更高效和更容易實現,因為它不需要在訓練過程中構建配對或三元組。另一種相關的度量學習方法是 [134] 中提出的范圍損失(range loss),這是為改善使用不平衡數據集的訓練而提出的。范圍損失有兩個組件。類內的損失組件是最小化同一類樣本之間的 k-最大距離,而類間的損失組件是最大化每個訓練批中最近的兩個類中心之間的距離。通過使用這些極端案例,范圍損失為每個類都使用同樣的信息,而不管每個類別中有多少樣本可用。類似于中心損失,范圍損失需要與 softmax 損失結合起來以避免損失降至零 [133]。
當結合不同的損失函數時,會出現一個困難,即尋找每一項之間的正確平衡。最近一段時間,已有研究者提出了幾種修改 softmax 損失的方法,這樣它無需與其它損失結合也能學習判別特征。一種已被證明可以增加瓶頸特征的判別能力的方法是特征歸一化 [115,118]。比如,[115] 提出歸一化特征以具有單位 L2 范數,[118] 提出歸一化特征以具有零均值和單位方差。一個成功的方法已經在 softmax 損失中每類之間的決策邊界中引入了一個余量 [135]。為了簡單,我們介紹一下使用 softmax 損失進行二元分類的情況。在這種情況下,每類之間的決策邊界(如果偏置為零)可由下式給定:

其中 x 是特征向量,W_1 和 W_2 是對應每類的權重,θ_1 和 θ_2 是 x 分別與 W_1 和 W_2 之間的角度。通過在上式中引入一個乘法余量,這兩個決策邊界可以變得更加嚴格:
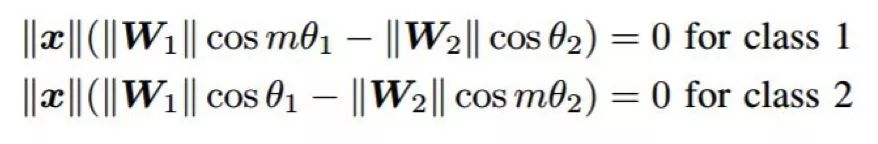
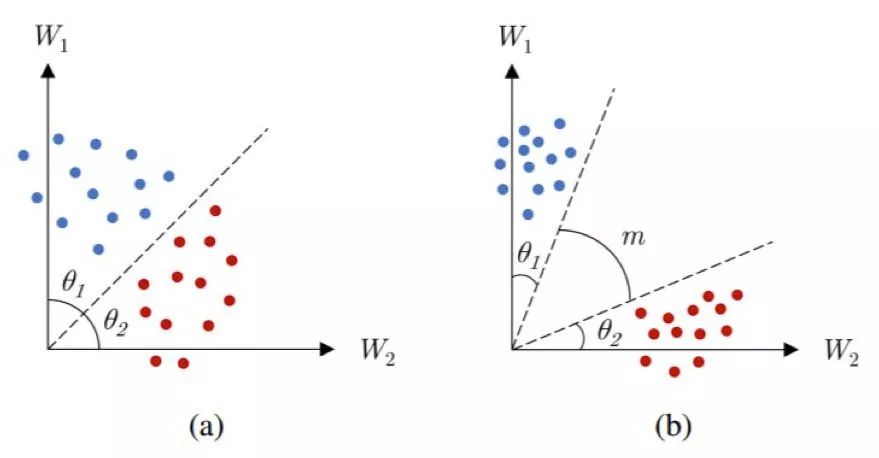
如圖 8 所示,這個余量可以有效地增大類別之間的區分程度以及各自類別之內的緊湊性。根據將該余量整合進損失的方式,研究者們已經提出了多種可用方法 [116,119-121]。比如 [116] 中對權重向量進行了歸一化以具有單位范數,這樣使得決策邊界僅取決于角度 θ_1 和 θ_2。[119,120] 中則提出了一種加性余弦余量。相比于乘法余量 [135,116],加性余量更容易實現和優化。在這項工作中,除了歸一化權重向量,特征向量也如 [115] 中一樣進行了歸一化和比例調整。[121] 中提出了另一種加性余量,它既有 [119,120] 那樣的優點,還有更好的幾何解釋方式,因為這個余量是加在角度上的,而不是余弦上。表 2 總結了有余量的 softmax 損失的不同變體的決策邊界。這些方法是人臉識別領域的當前最佳。

-
人臉識別
+關注
關注
76文章
4011瀏覽量
81860 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113
原文標題:【科普】人臉識別技術全面總結:從傳統方法到深度學習
文章出處:【微信號:TechSugar,微信公眾號:TechSugar】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AI干貨補給站 | 深度學習與機器視覺的融合探索

GPU深度學習應用案例
深度學習中的時間序列分類方法
深度學習中的無監督學習方法綜述
人臉檢測與識別的方法有哪些
深度學習與傳統機器學習的對比
深度解析深度學習下的語義SLAM






 工商網監
工商網監
評論