 AI繪畫的成長史,帶大家一同走近這位新晉畫家
AI繪畫的成長史,帶大家一同走近這位新晉畫家
【導語】近幾年,AI繪畫成為大家關注的熱點話題,從最初的簡筆畫,到動漫風格的繪畫,再到真實人臉的生成…… AI 畫家的飛速成長,似乎標志著一個繪畫界新星的冉冉升起。AI 到底是如何學會繪畫的?在本文中,營長梳理了 AI 繪畫的成長史,帶大家一同走近這位新晉畫家。
作為計算機視覺的熱點探討問題之一,AI繪畫技術在近幾年得到了飛速發展,相關模型和應用不斷引起人們的熱烈討論。如此前營長為大家報道的:吸貓人群的福音:貓臉生成器,賣出 43.2 萬美元的AI畫作,變身神筆馬良神器,使用重構網絡拯救“老婆”畫作,AI學會圖像風格遷移大法、英偉達新型GAN,可使豹子秒變沙皮狗等等。
幾年前,AI 還只會像小孩子一樣畫出一些簡單的簡筆畫,而如今,AI 已經能夠畫出逼真的人臉,甚至讓人類都難以分辨真假。那么,這位繪畫界的新星到底是如何飛速成長起來的?AI 都學會了哪些繪畫方法?今天,營長就帶大家一同走近這個神秘的畫家,探秘 AI 繪畫的成長之路。
AI 繪畫的出現
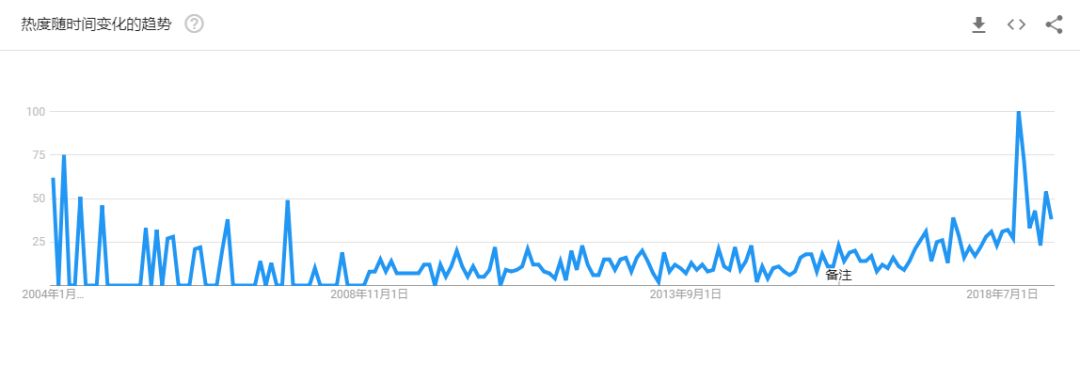
Google 上關于“AI painting”一詞的檢索熱度變化(2004-2019)
AI 繪畫實際上并不是近幾年才出現的新詞語。從 Google 趨勢提供的搜索指數來看,2004 年至 2007 年期間,“AI painting”就已經成為檢索熱詞;2008年之后,檢索熱度開始下降并進入平緩期;直到 2017 年 5 月, AI 繪畫再一次成為大眾的關注熱點。
從廣義上來講,AI 繪畫早在上個世紀就已經出現了。1973年,Harold Cohen 就已經開始嘗試和電腦程序 “AARON” 攜手進行繪畫創作。與當下 AI 繪畫不同之處在于,ARRON 使用機械手臂在畫布上進行繪畫,而非數字繪圖。進入 20 世紀 80 年代,ARRON 學會了對三維空間物體的繪畫表現方法;90 年代,它學會了使用多種顏色進行繪畫。ARRON 已經繪制出了很多不同的作品,直到今天,它仍在進行創作。
圖:ARRON 在 1992 年創作的一副繪畫作品
參考鏈接:https://newatlas.com/creative-ai-algorithmic-art-painting-fool-aaron/36106/
從 python 語言逐漸流行開始,一個名為 “turtle” 的繪圖庫逐漸進入人們的視線。turtle 繪圖庫的概念最初來自 Wally Feurzig 和 Seymour Papert 于 1966 年所創造的 Logo 編程語言,通過編寫程序,這個庫也能夠幫助我們進行一些圖像的繪畫。
我們現在所說的 AI 繪畫,實際更多指代的是基于機器學習模型進行自動數字繪圖的計算機程序。這類繪畫方式的發展要稍晚一些。2012 年,吳恩達和 Jeff Dean 使用 Google Brain 的 1.6 萬個 CPU 訓練了一個大型神經網絡,用于生成貓臉圖片。在當時的訓練中,他們使用了 1000 萬個來自 Yotube 視頻中的貓臉圖片,模型訓練用了整整三天。最終得到的模型,也只能生成一個非常模糊的貓臉。
與現在的模型相比,這個模型的訓練幾乎毫無效率可言。但對于計算機視覺領域而言,這次嘗試開啟了一個新的研究方向,也就是我們目前所討論的 AI 繪畫。
AI 學習繪畫的挑戰
對于機器學習模型而言,讓 AI 學會繪畫的過程就是一個模型的構建和參數訓練過程。在模型訓練中,每一副圖畫都使用一個大小為 mxn 的像素點矩陣表示,對于彩色圖畫,每個像素點都由 RGB(red、green、blue)三個顏色通道組成。要讓計算機學會繪畫,就相當于訓練一個可以逐個產生像素的機器學習模型。
這聽起來或許很簡單,但實際上,這一過程并沒有我們想象得那么容易。在一篇論文《Learning to Paint with Model-based Deep Reinforcement Learning》中,提到了訓練 AI 學習繪畫的三個挑戰,包括:
模型需要訓練的參數集合非常龐大。繪畫中的每一筆都涉及位置、形狀、顏色等多個方面的參數確定,對于機器學習模型來說,這將產生一個非常龐大的參數集合;
筆畫之間關系的確定,會導致更加復雜的計算。一副紋理豐富自然的畫作往往由很多筆畫完成。如何對筆畫進行組合、確定筆畫間的覆蓋關系,將是一個很重要的問題;
難以將 AI 接入一個現有的繪畫軟件。畫作的渲染等操作將導致非常高昂的數據獲取代價。
另外,如果希望 AI 除了模仿已有畫作的內容和風格以外,還能夠自創風格,模型訓練的難度會進一步加大。一個原因在于,“創造”是一個非常抽象的概念,使用模型來表達比較困難;另外,訓練數據的內容和風格終究是有限的。在上文提到的 ARRON 經過40余年的學習,仍沒能夠跳脫出其最初使用的色彩艷麗的抽象派風格,而這正是 Harold Cohen 本人的繪畫風格。
《Learning to Paint with Model-based Deep Reinforcement Learning》
論文地址:https://arxiv.org/abs/1903.04411
AI 繪畫的初步發展:學習圖片生成方式,嘗試簡筆畫
在吳恩達的貓臉生成模型之后,學界對 AI 繪畫進行了很多探索。最初的圖像生成模型為Ian J. Goodfellow 在 2014 年提出的對抗生成網絡(Generative Adverserial Network, GAN),這一模型也成為了很多 AI 繪圖模型的基礎。 GAN 包括兩個部分:生成器(generator)和判別器(discriminator),其中生成器用于圖片的生成,判別器來判斷圖片為真或假。這種方法對圖像生成領域做出了極大貢獻。
《Generative Adverserial Nets》
論文地址:http://www.cs.cmu.edu/~jeanoh/16-785/papers/goodfellow-nips2014-gans.pdf
但是使用 GAN 生成的圖片存在兩個比較明顯的問題。一是缺少控制能力。如果向 GAN 中輸入一個隨機噪聲,就會產生一副隨機圖像,而對于 AI 繪畫而言,圖像的產生過程應當是可控的。二是分辨率和質量較低。使用基礎的 GAN 網絡生成的很多圖像的分辨率較低。
針對于低分辨率的問題,2016 年 9 月,Christian Ledig 等人提出了 SRGAN 模型,該模型首次使用 GAN 網絡的架構生成了高分辨率的真實圖片。通過將 GAN 的損失函數替換為感知損失和對抗損失,模型取得了較好的生成效果。
《Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network》
論文地址:https://arxiv.org/abs/1609.04802
2016 年 12 月,Ian Goodfellow 在 NIPS 上介紹了一個使用 GAN 能夠產生動物圖片的模型。這些圖片的風格看起來比較逼真,但是由于圖片結構生成的不連續問題,有時會產生一些不合常理的內容,如:長了三只眼睛的貓,或者有好幾個頭的狗。
NIPS 2016 Tutoral
論文地址:https://arxiv.org/abs/1701.00160
圖:Ian Goodfellow 使用 GAN 模型生成的圖片,看起來有點驚悚
上述研究在學界引起了廣泛討論,但大眾真正開始了解 AI 繪畫,要推遲到 2017 年 4 月 Google 提出 Sketch-RNN 模型的時候。Sketch-RNN 基于 Seq2Seq 模型構建,并使用了變分推理方法,模型的訓練使用了一個包含幾百個種類的上千張手繪簡筆畫圖片。通過訓練,模型能夠繪制一些簡筆畫。Google 在論文《A Neural Representation of Sketch Drawings》中對這一模型進行了詳細介紹,并在之后開源了相關代碼。
Sketch-RNN 模型得到了人們的廣泛關注,一些開發者還基于該模型開發了一些有趣的應用。其中一個在線應用叫做 “Draw Together with a Neural Network” ,人們可以用鼠標隨意畫一個圖形,并選擇一個希望生成的圖形類別,該網站便能以多種方式自動幫你補充完整個圖形。例如,選擇繪畫類別為 “flower”,效果如下面的動圖所示:

圖: “Draw Together with a Neural Network” 的一個使用示例
《A Neural Representation of Sketch Drawings》
論文地址:https://arxiv.org/abs/1704.03477
“Draw Together with a Neural Network”
項目地址:https://magenta.tensorflow.org/sketch-rnn-demo
此后,研究人員對簡筆畫的繪制也在不斷探究。2018 年的 BMVC (The British Machine Vision Conference,英國計算機視覺會議)上,Tao Zhou 等人提交了一篇名為《Learning to Doodle with Deep Q-Networks and Demonstrated Strokes》的論文,該論文基于強化學習(Reinforcement Learning, RL)中的 Q-Learning 方法構建了一個機器學習模型,模型對于涂鴉類和水彩類繪畫都能產生較好的輸出。
《Learning to Doodle with Deep Q-Networks and Demonstrated Strokes》
論文地址:https://arxiv.org/abs/1810.05977
AI 繪畫的進一步發展:學習更加復雜的繪畫方法
在 Sketch-RNN 模型之后,大量的 AI 繪畫模型不斷涌現。
2017 年 7 月, Facebook 在《CAN: Creative Adversarial Networks, Generating "Art" by Learning About Styles and Deviating from Style Norms》中提出了創造性對抗網絡(Creative Adversarial Networks, CAN)模型,嘗試使 AI 繪制風格和圖片類型更加多樣的圖畫。
與傳統的 GAN 結構一樣, CAN 也包含生成器和鑒別器兩個部分。不同之處在于, CAN 在 GAN 的損失函數的基礎上加入了繪畫的時間信息,因此在進行學習后,可以讓模型產生與某一時間階段風格不同的畫作。在人工評測中,人們認為 CAN 模型的繪畫和人類藝術家繪畫的創意性不相上下。盡管創意性是一個比較主觀的評價指標,這仍是 AI 學習繪畫的重要一步。
圖:基于 CAN 模型生成的繪畫
《CAN: Creative Adversarial Networks, Generating "Art" by Learning About Styles and Deviating from Style Norms》
論文地址:https://arxiv.org/abs/1706.07068
2018 年 4 月, DeepMind 提出了一個名為 “SPIRAL” 的智能體,該智能體使用的模型基于強化對抗學習(Reinforced Adversarial Learning, RAL)方法構建,并能夠與計算機繪圖程序協作進行繪畫。該模型的基本架構類似于強化學習,但這一模型使用了一個判別器來決定基于模型輸出的獎勵,當判別器越難判斷輸出圖片的繪制者是人還是計算機,基于模型的獎勵越高。不同于以往的圖片生成模型,論文中的模型可以使用未標注的圖片集進行訓練,極大降低了獲取數據的成本,并提升了模型對圖片細節的學習效果。
《Synthesizing Programs for Images using Reinforced Adversarial Learning》
論文地址:https://arxiv.org/abs/1804.01118
2019 年 3 月,曠視科技訓練了一個名為“LearningToPaint” 的繪畫 AI ,其使用的基準算法為深度確定策略梯度算法(DDPG)。該算法基于策略梯度算法和值函數構建,并使用了演員-評論家(actor-critic)框架。為加快模型訓練速度,他們將這一方法接入到了強化學習模型中,用以輔助模型訓練。相較于之前的模型,該方法能夠適用于更加廣泛的數據集,只需修改模型繪畫時的最大筆畫數即可。
《Learning to Paint with Model-based Deep Reinforcement Learning》
論文地址:https://arxiv.org/abs/1903.04411
盡管 AI 繪畫已經得到了很多成長,在未來的研究中,如何使模型更具創造性、如何提高圖片質量效果、如何發掘更多有趣有價值的應用,還是留待討論的問題。
總結
在上文中,我們簡要回顧了 AI 繪畫的發展史,簡單總結如下:
AI 繪畫概念的提出:廣義上的 AI 繪畫并不是一個新的名詞,早在上個世紀80年代就已經出現了相關討論,在21世紀初還曾是一個熱點關注問題。從狹義上來講, AI 繪畫指的是基于機器學習模型進行自動數字繪圖的繪畫方式。自2012年吳恩達和 Jeff Dean 的貓臉生成模型開始, AI 繪畫得到了迅速發展。
AI 繪畫存在的挑戰:包括參數量龐大、計算復雜、和現有繪圖工具協作困難、難以生成具有創造性的圖片。
AI 繪畫的發展歷程:在發展最初,主要使用2014年提出的生成對抗網絡模型(GAN)進行圖片生成。在此之后,很多研究對 AI 繪畫模型都進行了探索,比較具有代表性的模型和應用包括 Google 提出的 Sketch-RNN 模型, Facebook 提出的 CAN 模型, DeepMind 搭建的 SPIRAL 智能體等。
最近幾年, AI 繪畫的成長速度是驚人的。未來,這位新晉畫家還會為我們帶來怎樣的驚喜?讓我們拭目以待。
-
AI
+關注
關注
87文章
30763瀏覽量
268917 -
機器學習
+關注
關注
66文章
8408瀏覽量
132580 -
機械手臂
+關注
關注
2文章
101瀏覽量
41676
原文標題:一文回顧AI繪畫的成長之路:從簡筆畫到真實人臉生成
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一個對于足球的狂熱者的成長史
EDA版塊和你一起成長
【514創新實驗室】WaterColor智能畫家
德信成長史:模擬IC公司如何擺脫同質化
深度學習的成長史和背后算法細節
一位軟件工程師的成長史
訓練卷積神經網絡通過繪畫3D地形識別畫家
基于深度學習的AI繪畫為何突然一下子火了?
AI繪畫爆火,它值得投資嗎?
爆火的AI繪畫為何會畫出六根手指?
誰能拒絕一個內置AI繪畫的思維導圖軟件?





 工商網監
工商網監
評論