") 激光SLAM和視覺SLAM各擅勝場,融合使用、取長補短潛力巨大
激光SLAM和視覺SLAM各擅勝場,融合使用、取長補短潛力巨大
一般來講,SLAM系統(tǒng)通常都包含多種傳感器和多種功能模塊。而按照核心的功能模塊來區(qū)分,目前常見的機器人SLAM系統(tǒng)一般具有兩種形式:基于激光雷達的SLAM(激光SLAM)和基于視覺的SLAM(Visual SLAM或VSLAM)。
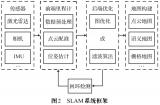
同時定位與地圖構建(Simultaneous Localization And Mapping,簡稱SLAM),通常是指在機器人或者其他載體上,通過對各種傳感器數(shù)據(jù)進行采集和計算,生成對其自身位置姿態(tài)的定位和場景地圖信息的系統(tǒng)。SLAM技術對于機器人或其他智能體的行動和交互能力至為關鍵,因為它代表了這種能力的基礎:知道自己在哪里,知道周圍環(huán)境如何,進而知道下一步該如何自主行動。它在自動駕駛、服務型機器人、無人機、AR/VR等領域有著廣泛的應用,可以說凡是擁有一定行動能力的智能體都擁有某種形式的SLAM系統(tǒng)。
一般來講,SLAM系統(tǒng)通常都包含多種傳感器和多種功能模塊。而按照核心的功能模塊來區(qū)分,目前常見的機器人SLAM系統(tǒng)一般具有兩種形式:基于激光雷達的SLAM(激光SLAM)和基于視覺的SLAM(Visual SLAM或VSLAM)。
激光SLAM簡介
激光SLAM脫胎于早期的基于測距的定位方法(如超聲和紅外單點測距)。激光雷達(Light Detection And Ranging)的出現(xiàn)和普及使得測量更快更準,信息更豐富。激光雷達采集到的物體信息呈現(xiàn)出一系列分散的、具有準確角度和距離信息的點,被稱為點云。通常,激光SLAM系統(tǒng)通過對不同時刻兩片點云的匹配與比對,計算激光雷達相對運動的距離和姿態(tài)的改變,也就完成了對機器人自身的定位。
激光雷達距離測量比較準確,誤差模型簡單,在強光直射以外的環(huán)境中運行穩(wěn)定,點云的處理也比較容易。同時,點云信息本身包含直接的幾何關系,使得機器人的路徑規(guī)劃和導航變得直觀。激光SLAM理論研究也相對成熟,落地產(chǎn)品更豐富。
圖1,激光SLAM的地圖構建(谷歌Cartographer[1])
VSLAM簡介
眼睛是人類獲取外界信息的主要來源。視覺SLAM也具有類似特點,它可以從環(huán)境中獲取海量的、富于冗余的紋理信息,擁有超強的場景辨識能力。早期的視覺SLAM基于濾波理論,其非線性的誤差模型和巨大的計算量成為了它實用落地的障礙。近年來,隨著具有稀疏性的非線性優(yōu)化理論(Bundle Adjustment)以及相機技術、計算性能的進步,實時運行的視覺SLAM已經(jīng)不再是夢想。
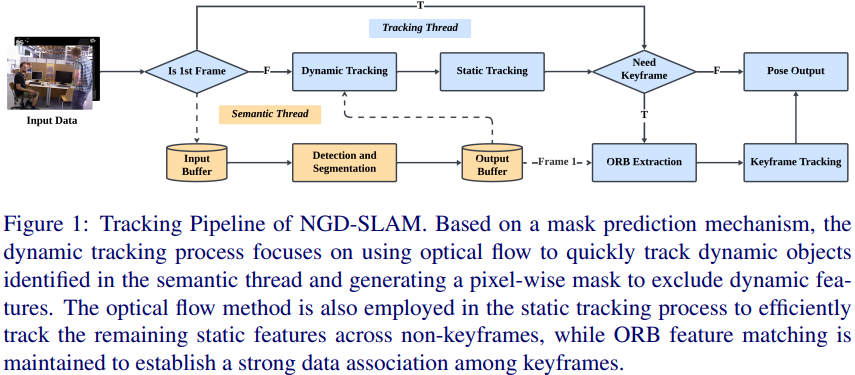
通常,一個VSLAM系統(tǒng)由前端和后端組成(圖2)。前端負責通過視覺增量式計算機器人的位姿,速度較快。后端,主要負責兩個功能:
一是在出現(xiàn)回環(huán)(即判定機器人回到了之前訪問過的地點附近)時,發(fā)現(xiàn)回環(huán)并修正兩次訪問中間各處的位置與姿態(tài);
二是當前端跟蹤丟失時,根據(jù)視覺的紋理信息對機器人進行重新定位。簡單說,前端負責快速定位,后端負責較慢的地圖維護。
VSLAM的優(yōu)點是它所利用的豐富紋理信息。例如兩塊尺寸相同內容卻不同的廣告牌,基于點云的激光SLAM算法無法區(qū)別他們,而視覺則可以輕易分辨。這帶來了重定位、場景分類上無可比擬的巨大優(yōu)勢。同時,視覺信息可以較為容易的被用來跟蹤和預測場景中的動態(tài)目標,如行人、車輛等,對于在復雜動態(tài)場景中的應用這是至關重要的。第三,視覺的投影模型理論上可以讓無限遠處的物體都進入視覺畫面中,在合理的配置下(如長基線的雙目相機)可以進行很大尺度場景的定位與地圖構建。
圖2,視覺SLAM的前端定位與后端地圖維護(ORB-SLAM2[2])
接下來我們將在細分項目上比較激光SLAM和VSLAM。
應用場景
在應用場景上,激光SLAM依據(jù)所使用的激光雷達的檔次基本被分為涇渭分明的室內應用和室外應用,而VSLAM在室內外都有豐富的應用環(huán)境。VSLAM的主要挑戰(zhàn)是光照變化,例如在室外正午和夜間的跨時間定位與地圖構建,其工作穩(wěn)定性不如高端室外多線激光雷達。近年來,光照模型修正和基于深度學習的高魯棒性特征點被廣泛應用于視覺SLAM的研究中,體現(xiàn)出良好的效果,應當說VSLAM隨著這些技術的進步將會在光照變化的環(huán)境中擁有更穩(wěn)定的表現(xiàn)。
影響穩(wěn)定工作的因素
激光SLAM不擅長動態(tài)環(huán)境中的定位,比如有大量人員遮擋其測量的環(huán)境,也不擅長在類似的幾何環(huán)境中工作,比如在一個又長又直、兩側是墻壁的環(huán)境。由于重定位能力較差,激光SLAM在追蹤丟失后很難重新回到工作狀態(tài)。而視覺SLAM在無紋理環(huán)境(比如面對整潔的白墻面),以及光照特別弱的環(huán)境中,表現(xiàn)較差。
定位和地圖構建精度
在靜態(tài)且簡單的環(huán)境中,激光SLAM定位總體來講優(yōu)于視覺SLAM;但在較大尺度且動態(tài)的環(huán)境中,視覺SLAM因為其具有的紋理信息,表現(xiàn)出更好的效果。在地圖構建上,激光SLAM的特點是單點和單次測量都更精確,但地圖信息量更小;視覺SLAM特別是通過三角測距計算距離的方法,在單點和單次測量精度上表現(xiàn)總體來講不如激光雷達,但可以通過重復觀測反復提高精度,同時擁有更豐富的地圖信息。
累計誤差問題
激光SLAM總體來講較為缺乏回環(huán)檢測的能力,累計誤差的消除較為困難。而視覺SLAM使用了大量冗余的紋理信息,回環(huán)檢測較為容易,即使在前端累計一定誤差的情況下仍能通過回環(huán)修正將誤差消除。
傳感器成本
激光雷達事實上有許多檔次,成本都高于視覺傳感器。最昂貴如Velodyne的室外遠距離多線雷達動輒數(shù)十萬元人民幣,而室外使用的高端中遠距離平面雷達如SICK和Hokuyo大約在數(shù)萬元人民幣的等級。室內應用較廣的中低端近距離平面激光雷達也需要千元級—,其價格相當于比較高端的工業(yè)級攝像頭和感光芯片。激光雷達量產(chǎn)后成本可能會大幅下降,但能否降到同檔次攝像頭的水平仍有一個大大的問號。
傳感器安裝和穩(wěn)定性
目前常見的激光雷達都是旋轉掃描式的,內部長期處于旋轉中的機械結構會給系統(tǒng)帶來不穩(wěn)定性,在顛簸震動時影響尤其明顯。而攝像頭不包含運動機械結構,對空間要求更低,可以在更多的場景下安裝使用(圖3)。不過,固態(tài)激光雷達的逐步成熟可能會為激光SLAM扳回這項劣勢。
圖3 激光雷達和視覺系統(tǒng)的安裝應用。谷歌無人車上的多線激光雷達
DJI精靈4上的視覺系統(tǒng)
算法難度
激光SLAM由于其研究的成熟以及誤差模型的相對簡單,在算法上門檻更低,部分開源算法甚至已經(jīng)被納入了ROS系統(tǒng)成為了標配。而反觀視覺SLAM,首先圖像處理本身就是一門很深的學問,而基于非線性優(yōu)化的地圖構建上也是非常復雜和耗時的計算問題。現(xiàn)在已經(jīng)有許多優(yōu)秀的開源算法(如ORB-SLAM[2]、LSD-SLAM[3]),但在實際環(huán)境中優(yōu)化和改進現(xiàn)有的視覺SLAM框架,比如加入光照模型、使用深度學習提取的特征點、以及使用單雙目及多目融合視角等技術,將是視覺SLAM進一步提升性能和實用性的必由之路。這些技術的算法門檻也遠遠高于激光SLAM。
計算需求
毫無疑問,激光SLAM的計算性能需求大大低于視覺SLAM。主流的激光SLAM可以在普通ARM CPU上實時運行,而視覺SLAM基本都需要較為強勁的準桌面級CPU或者GPU支持。但業(yè)界也看到了這其中蘊藏的巨大機會,為視覺處理定制的ASICS市場已經(jīng)蠢蠢欲動。一個很好的例子是Intel旗下的Movidius,他們設計了一種特殊的架構來進行圖像、視頻與深度神經(jīng)網(wǎng)絡的處理,在瓦級的超低功耗下達到桌面級GPU才擁有的吞吐量。DJI的精靈4系列產(chǎn)品就是使用這類專用芯片,實現(xiàn)了高速低功耗的視覺計算,為無人機避障和近地面場景導航提供根據(jù)。
多機協(xié)作
視覺主要是被動探測,不存在多機器人干擾問題。而激光雷達主動發(fā)射,在較多機器人時可能產(chǎn)生干擾。尤其是固態(tài)激光雷達的大量使用,可能使得場景中充滿了信號污染,從而影響激光SLAM的效果。
未來趨勢
激光SLAM和視覺SLAM各擅勝場,單獨使用都有其局限性,而融合使用則可能具有巨大的取長補短的潛力。例如,視覺在紋理豐富的動態(tài)環(huán)境中穩(wěn)定工作,并能為激光SLAM提供非常準確的點云匹配,而激光雷達提供的精確方向和距離信息在正確匹配的點云上會發(fā)揮更大的威力(圖4)。而在光照嚴重不足或紋理缺失的環(huán)境中,激光SLAM的定位工作使得視覺可以借助不多的信息進行場景記錄。
圖4,KITTI數(shù)據(jù)集視覺里程計。ORB-SLAM[2],雙目視覺
V-LOAM[4],視覺引導激光修正
現(xiàn)實中的激光與視覺SLAM系統(tǒng)幾乎都會配備慣性元件、輪機里程計、衛(wèi)星定位系統(tǒng)、室內基站定位系統(tǒng)等輔助定位工具,而近年來SLAM系統(tǒng)與其他傳感器的融合成為了一大熱點。不同于以往基于卡爾曼濾波的松耦合融合方法,現(xiàn)在學界的熱點是基于非線性優(yōu)化的緊耦合融合。例如與IMU的融合和實時相互標定,使得激光或視覺模塊在機動 (猛烈加減速和旋轉) 時可以保持一定的定位精度,防止跟蹤丟失,極大的提高定位與地圖構建的穩(wěn)定性。
激光點云信息本身也仍有潛力可挖。在高端的遠距離多線激光雷達上,返回的點云除了包含方向和距離信息,還可以加入目標點的反射率信息。當線數(shù)較多較密時,由反射率信息構成的數(shù)據(jù)可以視為一種紋理信息,因此可以在一定程度上享受視覺算法和紋理信息帶來的重定位等方面的優(yōu)勢。這些信息一旦融入到高精度地圖中,高精度地圖就可以在點云紋理兩種形式間無縫切換,使得利用高精度地圖的定位可以被只擁有廉價攝像頭的自動駕駛汽車分享。這也是目前國外一些團隊的研究方向([5])。
同時,視覺所依賴的投影模型,蘊含著非常豐富的“混搭”玩法。長、短基線的單雙目結合,可以在保證大尺度定位水平的同時提高中近距離的障礙探測和地圖構建精度;廣角魚眼和360度全向攝像頭與標準單雙目的結合,使得VSLAM的覆蓋范圍可以進一步提升,特別適合對場景按照距離的遠近進行不同精度不同速度的定位。被動視覺與深度相機的結合,催生了RGB-D SLAM,而深度相機量程的逐步擴大,將給這種特殊VSLAM帶來更大的應用空間。
VSLAM的另一個也許更宏大的擴展在AI端。端到端的深度學習所帶來的圖像特征,已經(jīng)在識別和分類領域大大超越了人類手工選擇的SIFT/SURF/ORB等特征。我們可以很安全的說,未來在低紋理、低光照等環(huán)境下,深度學習所訓練出的提取、匹配和定位估算等方法,也一定會超越目前VSLAM領域最先進的手工方法。更不用說,圖像本身所大量攜帶的信息,可以廣泛用于場景理解、場景分類、物體識別、行為預測等重要方面。一個很可能的情況是,未來視覺處理系統(tǒng)將直接包含定位、地圖構建、運動規(guī)劃、場景理解以及交互等多個功能模塊,更緊密的聯(lián)合帶來更加智能的機器人行動能力。
如果想深入了解SLAM技術的過去、現(xiàn)在和未來趨勢,我們推薦文獻[6]。
結語
SLAM技術將賦予為機器人和智能體前所未有的行動能力。作為當前SLAM框架的主要類型,激光SLAM與視覺SLAM必將在相互競爭和融合中發(fā)展,必將帶來機器人技術和人工智能技術的真正革命,也將使得機器人從實驗室和展示廳中走出來,真正服務和解放人類。
-
激光
+關注
關注
19文章
3185瀏覽量
64451 -
SLAM
+關注
關注
23文章
423瀏覽量
31823
原文標題:激光SLAM與視覺SLAM的現(xiàn)狀與趨勢
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
利用VLM和MLLMs實現(xiàn)SLAM語義增強


最新圖優(yōu)化框架,全面提升SLAM定位精度

激光雷達在SLAM算法中的應用綜述
MG-SLAM:融合結構化線特征優(yōu)化高斯SLAM算法

從算法角度看 SLAM(第 2 部分)

一種適用于動態(tài)環(huán)境的實時視覺SLAM系統(tǒng)
深度解析深度學習下的語義SLAM

工程實踐中VINS與ORB-SLAM的優(yōu)劣分析

什么是SLAM?SLAM算法涉及的4要素
什么是SLAM?基于3D高斯輻射場的SLAM優(yōu)勢分析
基于濾波器的激光SLAM方案
從基本原理到應用的SLAM技術深度解析
深度解析:多傳感器融合SLAM技術全景剖析

基于NeRF/Gaussian的全新SLAM算法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論