 下一代深度學習加速器:英特爾Xe
下一代深度學習加速器:英特爾Xe
在超算領域,中美之間無聲的競爭還在進行中,2018年美國憑借橡樹嶺國家實驗室的Summit超算奪回了失落5年的TOP500冠軍寶座。在HPC超算市場上,關鍵的還是下一代百億億次超算,也就是Exascale超算,目前中國有三套E級超算,而英特爾、Cray公司在2019年3月17日獲得了美國能源部5億美元的合同。
美國能源部長里克佩里說:“實現百億億次超算是必不可少的,它不僅可以提升科學計算,還要改善美國人的日常生活。”“Aurora及下一代百億億次超算將HPC、AI等技術應用于癌癥研究、氣候模擬、退伍軍人健康治療等領域,基于百億億次超算的創新將會對我們的社會產生極為重要的影響。”美國首臺百億億次超算將大量應用英特爾的最新技術,主處理器是下一代Xeon至強,還有新一代Xe加速卡、OptaneDC內存、秘密武器CXL以及英特爾的OneAI軟件,而整個系統則是基于Cray公司的Shasta系統,包括至少200個機柜、Slingshot高性能可擴展互聯架構及Shasta軟件堆棧。
該項目計劃在2021年的時間內完成,并且每秒能夠進行Quintillion的運算,即400 petaflops。從這個角度來看,這比Million浮點運算高出一百萬倍 - 而平均每個處理器的約為200 GFLOP。這筆交易價值5億美元,其中Cray將獲得1.46億美元的資金,而Intel將獲得剩余的3.54億美元。
圖一:Aurora技術革新(圖片來源:英特爾)
從上圖可以看出Xe 是加速器,但目前還不清楚Quintillionops mark的功率分布。
圖二:英特爾GPU可擴展性(來源:英特爾)
英特爾野心勃勃,Xe將從10nm節點開始,為未來幾代圖形奠定基礎,并將遵循Intel的單一堆棧軟件哲學,即希望軟件開發人員能夠利用CPU、GPU、FPGA和AI,所有這些都使用同一套API,英特爾稱之為One API,One API作為Direct3D層和GPU之間的中介(據稱他們也有Linux解決方案),并允許用戶無縫擴展多個GPU。這表明Intel也準備打造一個類似CUDA的生態系統。
圖三:英特爾Xe路線圖(圖片來源:英特爾)
不過這些都不是重點,英特爾將第一次在GPU領域使用MCM封裝形式,這正是英偉達夢寐以求的技術,而英特爾即將量產,第一批X2 GPU的暫定時間表也已經公布:2020年6月31日。隨后是2021年的X4。看起來Intel計劃每年增加兩個核心,所以到2024年應該會到X8。
Xe將是英特爾異構計算的關鍵構成,之前英特爾對GPU加速一直持懷疑態度,但自從有了Xe后,英特爾改變了態度,英特爾Xe將加強英特爾以數據為中心的廣泛產品組合,為最廣泛的計算工作負載提供領先的產品,滿足其對標量、矢量、矩陣和空間計算架構的綜合需求。但英特爾并未透露太多細節,不過從Aurora采購Xe即可看出,GPU加速已經被英特爾認同。
目前制造高性能 GPU 有一個很嚴重的限制 — 「芯片尺寸的限制」,因為目前現有技術的***受限于光刻模板、光刻光源,幾乎不可能制造出更大的 GPU 核心,極限是800平方毫米。即使英偉達的技術如何進步,核心尺寸不能無止境變大已經成為英偉達 繼續提升 GPU 性能的瓶頸。MCM 的封裝方式與 NANDFlash 的做法有點類似,容量不夠就將 Layer堆棧起來,除了制造方式簡單且具成本優勢之外,還可以提高產品的性能。
此外隨著CPU核心數逐漸從個位數提升到十位數范圍,monolithic多核心的局限越來越大,除了制造難度大、良率低的問題,也因為它不夠靈活,因為處理器除了核心數量之外,還要考慮到內存信道、PCIe信道等IO核心的搭配,英特爾的Skylake-SP架構所示,為了配合不同核心的處理器,英特爾在它上面使用了XCC、LCC、HCC三種不同的內部架構,這樣做無疑是增加了芯片的復雜性。
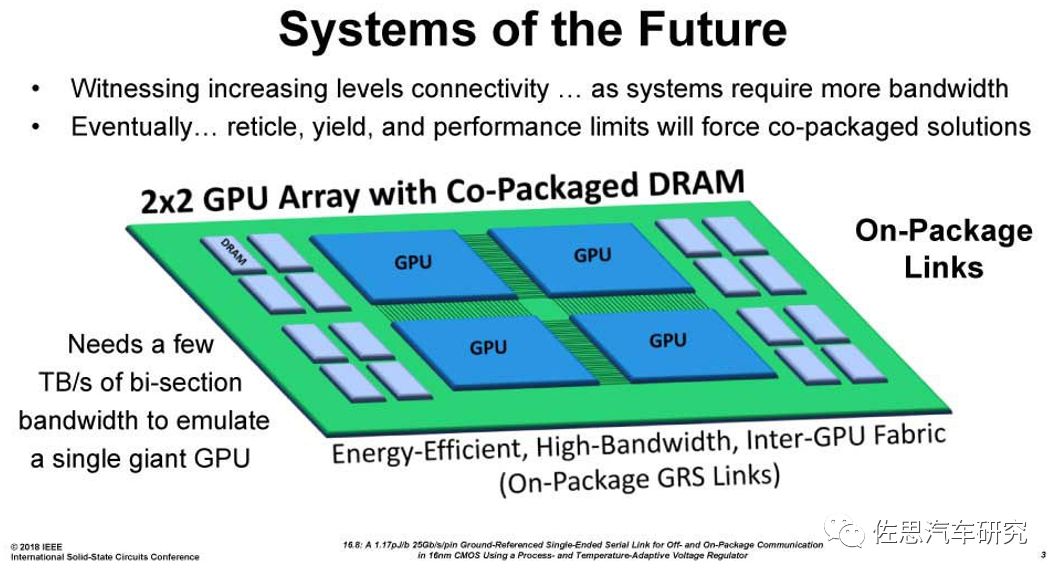
圖四:英偉達RC-18 GPU陣列(圖片來源:英偉達)
英偉達為了應付 GPU 核心面積的瓶頸,已計劃開發一個名為「RC 18」的多矩陣概念,以最優化的方式整合多個 GPU 模塊,達至最高流處理器數、減少通訊層級和鏈路長度,并可以縮小芯片面積。根據英偉達研究部主管 William J. Dally的說法,「RC-18」是為深度學習執行和實現可擴展性的實驗,每個芯片內部具有基于TSMC 16nm 工藝及承載 8700 萬個晶體管的 16 個 PE(處理組件),因此可以從非常小的尺寸中擴展。16 個 PE 用于控制 CPU Core,片上全局緩沖儲存器,并安裝了八個 GRS 鏈路。在實際芯片中,GRS 鏈路組占據相當大的面積,每芯片 GRS 的 I/O 帶寬達到 100 GB/s。
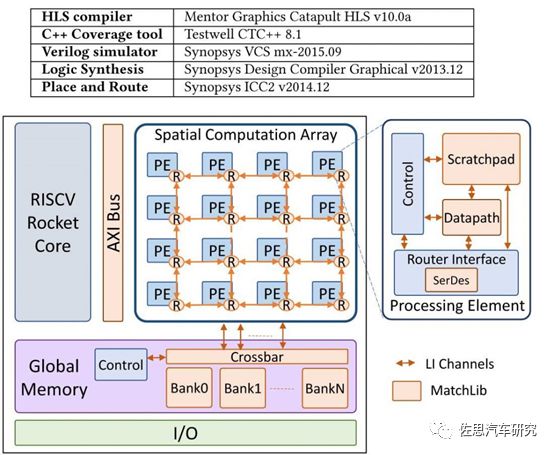
圖五:英偉達RC18內部框架圖(圖片來源:英偉達)
英偉達的RC18概念設計。英偉達目前RC18概念產品只做到了8700萬個晶體管,與GPU動輒百億級晶體管相比,差距至少有5年,目前英偉達將精力全部轉移到光線追蹤上,靠RT核來做賣點,只字不提曾經信誓旦旦的MCM。而英特爾的MCM成功了,畢竟英特爾在芯片封裝領域技術積累遠比英偉達要深厚的多。
AMD在CPU上大量運用MCM技術,但是在GPU上始終無法突破量產工藝瓶頸,理論上似乎很簡單,但就是良率太低,無法量產。這是因為AMD沒有自己的晶圓廠,從未從事過芯片封裝,芯片封裝都是交給第三方,而英特爾擁有全球最大的晶圓廠,也擁有最優秀的芯片封裝工藝,當然這背后是日本廠家新光電氣和Ibiden的鼎力支持,日本在封裝材料和工藝方面擁有絕對優勢。同時英特爾還有自己的Flash存儲器晶圓廠。可以借鑒Flash存儲器的MCM封裝經驗。
MCM不僅性能一流,同時也成本大幅度降低,AMD透露,如果將32核封裝到一塊芯片中成本是1,那它們的MCM方式只有0.59,換言之,節省了41%的成本。MCM還允許一個芯片中使用不同工藝的die(裸晶),比如I/O部分不需要那么先進的工藝,28納米足夠,CPU部分就用7納米,不僅降低成本,還復用了以前的I/O設計,降低先進制程工藝的風險,研發成果復用率高,縮短研發周期等。

圖六:單一架構和MCM對比(圖片來源:AMD)
上圖為AMD MCM與單芯片對比。
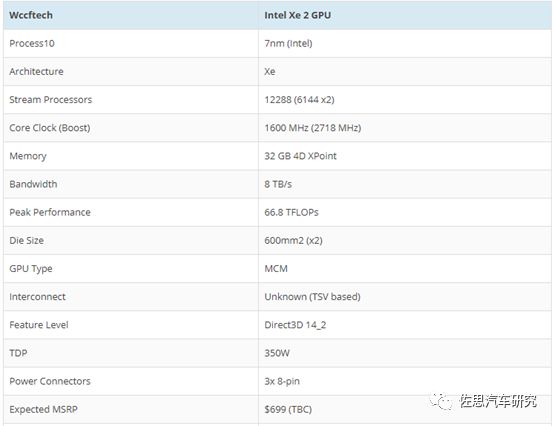
英特爾Xe 2 GPU性能見上表。性價比極高。
為配合MCM,英特爾在軟件方面也有所動作,英特爾2019年4月9日舉行了Interconnect Day 2019 ,當中詳細介紹了處理器與處理器之間的Compute Express Link(CXL)超高速互聯新標準。雖然現階段構思僅供數據中心的服務器使用,顯然這也是為GPU準備的。英特爾 CXL 標準的原意——作為 CPU 與 Accelerator 加速器(如 FPGA / GPU 顯示適配器)之間的互聯通信。
一直以來, CPU 都是透過主板上的 PCIe插槽及 PCIe 協議與顯示適配器溝通,但當英特爾 聯合阿里巴巴、 Cisco、 Dell EMC 、 Facebook 、 Google 、 HPE 、華為及微軟組成強大陣容的聯盟后,就發表了 CXL 的開放標準,以解決目前 PCIe 協議于 CPU 與顯示適配器之間的高延遲及帶寬不足的問題。透過 CXL 協議, CPU 與 GPU 之間就形同連成單一個龐大的堆棧內存池( Stacked Memory ), CPU Cache 和 GPU HBM2 內存猶如放在一起,有效降低兩者之間的延遲,故此能大幅提升數據運算效率,令AI人工智能、機器學習、媒體服務、高效能運算( HPC )及云端服務變得非常快速。
MCM沒有理論上的突破,突破的只是制造工藝,MCM在奔騰時代已經出現過了,而今monolithic多核已經走到了極限,唯有MCM能救場。而在服務器用CPU領域,MCM將可能是唯一方向,典型的如Cascade Lake-AP 48核處理器,它實際上是兩個24核的Cascade Lake處理器通過MCM方式組合出來的,也不是原生48核。如今的MCM多芯片設計在技術水平上也跟當年簡單粗暴的膠水多核不一樣了,主要擔心的延遲問題上,英特爾之前提到他們的EMIB技術相比單片電路的延遲只增加了10%,而別的技術方案中延遲甚至會增加50%之多。
monolithic多核的困境實際上是整個人類面臨的瓶頸,近百年來,人類在物理學體系理論上未有任何突破,只是在細枝末節上做修修補補,所謂人工智能不過是概率論,幾十年甚至近百年前的理論還是根基,所謂提升,不過是算力成指數倍的堆砌。
另外,供應鏈的重要性一再凸顯,那種追求短平快,強調分工,只做自己擅長的戰略長遠上必然會遇到無法超越的瓶頸,英偉達和AMD無法戰勝英特爾,不再技術層面,而是供應鏈層面。這么多年以來,AMD都是努力追趕英特爾,但AMD將工廠賣掉之后是個純粹的Fabless,需要看Foundry晶圓代工廠的臉色,晶圓代工廠自然要優先照顧大客戶,臺積電自然要優先照顧蘋果、華為和高通,遇上產能吃緊,AMD的訂單就會往后排。這就意味著AMD的供貨不夠穩定,或者說AMD無法掌控產量,對下游整機廠來說,有可能導致旺季缺貨,這是個致命的缺點,特別是淡旺季分明的筆記本電腦CPU領域,英特爾一直擁有絕對優勢。英特爾單靠全球最大的12英寸晶圓產能也足以擁有在半導體領域的霸主位置。
-
英特爾
+關注
關注
61文章
9953瀏覽量
171705 -
深度學習
+關注
關注
73文章
5500瀏覽量
121118
原文標題:下一代深度學習加速器:英特爾Xe
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
英特爾聯合中科創達構建下一代智能座艙平臺
10月29日英特爾將發布新一代酷睿Ultra Series 2處理器及圖形產品線
英特爾發布Gaudi3 AI加速器,押注低成本優勢挑戰市場
英特爾下代 CPU 還值得信任嗎?
下一代高功能新一代AI加速器(DRP-AI3):10x在高級AI系統高級AI中更快的嵌入處理

龍芯中科胡偉武:3B6600 八核桌面 CPU 性能將達到英特爾中高端酷睿 12~13 代水平
英特爾發布AI創作應用AI Playground,將于今夏正式上線!

英特爾發布新一代Lunar Lake處理器
英特爾加大玻璃基板技術布局力度
使用英特爾Agilex3和Agilex5器件構建下一代數據中心平臺管理方案

英特爾展示下一代至強處理器,助力vRAN性能顯著提升






 工商網監
工商網監
評論