") 3個(gè)神經(jīng)網(wǎng)絡(luò),讓蒙娜麗莎活起來(lái)
3個(gè)神經(jīng)網(wǎng)絡(luò),讓蒙娜麗莎活起來(lái)
還記得哈利?波特第一次來(lái)到霍格沃茨看到墻上那些既會(huì)動(dòng)又會(huì)說(shuō)話(huà)的掛畫(huà)是多么驚訝嗎?如果我們可以將掛畫(huà) “復(fù)活”,和 500 多年前的蒙娜麗莎來(lái)場(chǎng)穿越時(shí)空的對(duì)話(huà)會(huì)怎樣呢?感謝 AI 技術(shù),把畫(huà) “復(fù)活” 不再是夢(mèng)!
名畫(huà)《蒙娜麗莎的微笑》,會(huì)動(dòng)了!
夢(mèng)娜麗莎轉(zhuǎn)過(guò)頭,嘴里說(shuō)著話(huà),微微眨了眨眼,臉上帶著溫婉的微笑。
是的,《哈利·波特》世界中”會(huì)動(dòng)的畫(huà)“魔法實(shí)現(xiàn)了!來(lái)自三星AI中心(Samsung AI Center)和莫斯科斯的Skolkovo 科學(xué)技術(shù)研究所的一組研究人員,開(kāi)發(fā)了一個(gè)能將讓JPEG變GIF的AI系統(tǒng)。
《哈利·波特》中守衛(wèi)格蘭芬多學(xué)院休息室的胖夫人畫(huà)像
更牛逼的是,該技術(shù)完全無(wú)需3D建模,僅需一張圖片就能訓(xùn)練出惟妙惟肖的動(dòng)畫(huà)。研究人員稱(chēng)這種學(xué)習(xí)方式為“few-shot learning"。
當(dāng)然,如果有多幾張照片——8張或32張——?jiǎng)?chuàng)造出來(lái)動(dòng)圖效果就更逼真了。比如:
愛(ài)因斯坦給你講物理:
瑪麗蓮夢(mèng)露和你 flirt:
本周,三星AI實(shí)驗(yàn)室的研究人員發(fā)表了一篇題為 “Few-Shot Adversarial Learning of Realistic Neural Talking Head Models” 的論文,概述了這種技術(shù)。該技術(shù)基于卷積神經(jīng)網(wǎng)絡(luò),其目標(biāo)是獲得一個(gè)輸入源圖像,模擬目標(biāo)輸出視頻中某個(gè)人的運(yùn)動(dòng),從而將初始圖像轉(zhuǎn)換為人物正在說(shuō)話(huà)的短視頻。
論文一發(fā)表馬上引起轟動(dòng),畢竟這項(xiàng)技術(shù)創(chuàng)造了巨大的想象空間!
類(lèi)似這樣的項(xiàng)目有很多,所以這個(gè)想法并不特別新穎。但在這篇論文中,最有趣的是,該系統(tǒng)不需要大量的訓(xùn)練示例,而且系統(tǒng)只需要看一次圖片就可以運(yùn)行。這就是為什么它讓《蒙娜麗莎》活起來(lái)。
3個(gè)神經(jīng)網(wǎng)絡(luò),讓蒙娜麗莎活起來(lái)
這項(xiàng)技術(shù)采用“元學(xué)習(xí)”架構(gòu),如下圖所示:
圖2:“讓照片動(dòng)起來(lái)”元學(xué)習(xí)架構(gòu)
具體來(lái)說(shuō),涉及三個(gè)神經(jīng)網(wǎng)絡(luò):
首先,嵌入式網(wǎng)絡(luò)映射輸入圖像中的眼睛、鼻子、嘴巴大小等信息,并將其轉(zhuǎn)換為向量;
其次,生成式網(wǎng)絡(luò)通過(guò)繪制人像的面部地標(biāo)(face landmarks)來(lái)復(fù)制人在視頻中的面部表情;
第三,鑒別器網(wǎng)絡(luò)將來(lái)自輸入圖像的嵌入向量粘貼到目標(biāo)視頻的landmark上,使輸入圖像能夠模擬視頻中的運(yùn)動(dòng)。
最后,計(jì)算“真實(shí)性得分”。該分?jǐn)?shù)用于檢查源圖像與目標(biāo)視頻中的姿態(tài)的匹配程度。
元學(xué)習(xí)過(guò)程:只需1張輸入圖像
研究人員使用VoxCeleb2數(shù)據(jù)集對(duì)這個(gè)模型進(jìn)行了預(yù)訓(xùn)練,這是一個(gè)包含許多名人頭像的數(shù)據(jù)庫(kù)。在這個(gè)過(guò)程中,前面描述的過(guò)程是一樣的,但是這里的源圖像和目標(biāo)圖像只是同一視頻的不同幀。
因此,這個(gè)系統(tǒng)不是讓一幅畫(huà)去模仿視頻中的另一個(gè)人,而是有一個(gè)可以與之比較的ground truth。通過(guò)持續(xù)訓(xùn)練,直到生成的幀與訓(xùn)練視頻中的真實(shí)幀十分相似為止。
預(yù)訓(xùn)練階段允許模型在只有很少示例的輸入上工作。哪怕只有一張圖片可用時(shí),結(jié)果也不會(huì)太糟,但當(dāng)有更多圖片可用時(shí),結(jié)果會(huì)更加真實(shí)。
實(shí)驗(yàn)和結(jié)果
研究人員使用2個(gè)數(shù)據(jù)集分別進(jìn)行定量和定性評(píng)估:VoxCeleb1數(shù)據(jù)集用于與基準(zhǔn)模型進(jìn)行比較,VoxCeleb2用于展示他們所提出方法的效果。
研究人員在三種不同的設(shè)置中將他們的模型與基準(zhǔn)模型進(jìn)行了比較,使用fine-tuning集中的1幀、8幀和32幀。
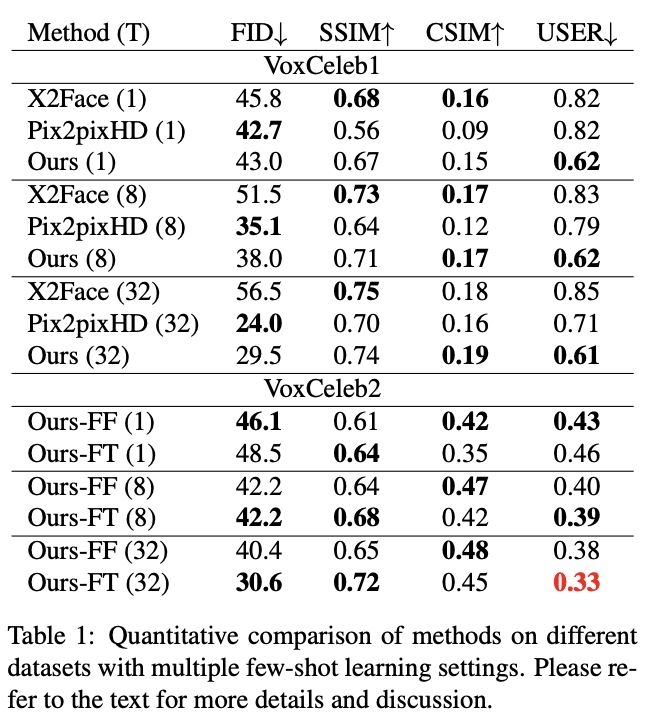
表1:few-shot learning設(shè)置下不同方法的定量比較
結(jié)果如表1上半部分所示,基線模型在兩個(gè)相似性度量上始終優(yōu)于我們的方法。
不過(guò),這些指標(biāo)不能完全代表人類(lèi)的感知,因?yàn)檫@兩種方法都會(huì)產(chǎn)生恐怖谷偽影,從圖3的定性比較和用戶(hù)研究結(jié)果可以看出。
另一方面,余弦相似度與視覺(jué)質(zhì)量有更好的相關(guān)性,但仍然傾向于模糊、不太真實(shí)的圖像,這也可以通過(guò)表1-Top與圖3中的比較結(jié)果看出。
圖3:使用1張、8張和32張訓(xùn)練圖像時(shí)的三個(gè)示例。系統(tǒng)采用一個(gè)源圖像(第1列),并嘗試將該圖像映射到ground truth幀中的相同位置(第2列)。研究人員將他們的結(jié)果與X2Face、PixtopixHD模型進(jìn)行了比較。
大規(guī)模的結(jié)果。
隨后,我們擴(kuò)展可用的數(shù)據(jù),并在更大的VoxCeleb2數(shù)據(jù)集中訓(xùn)練我們的方法。
下面是2個(gè)變體模型的結(jié)果:
圖4:在VoxCeleb2數(shù)據(jù)集中的最佳模型的結(jié)果。
同樣,訓(xùn)練幀的數(shù)量是T(左邊的數(shù)字),第1列是示例訓(xùn)練幀。第2列是ground truth圖像,后3列分別是我們的FF feed-forward 模型及微調(diào)前后的結(jié)果。雖然 feed-forward變體的學(xué)習(xí)更快速,但fine-tuning 最終提供了更好的真實(shí)感和保真度。
最后,我們展示了的照片和繪畫(huà)的結(jié)果。
圖5:讓靜態(tài)照片“活”起來(lái)
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4771瀏覽量
100718 -
圖像
+關(guān)注
關(guān)注
2文章
1083瀏覽量
40449 -
ai技術(shù)
+關(guān)注
關(guān)注
1文章
1266瀏覽量
24287
原文標(biāo)題:蒙娜麗莎一鍵“復(fù)活”!三星AI Lab:只需一張圖片就能合成動(dòng)畫(huà)
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
人工神經(jīng)網(wǎng)絡(luò)原理及下載
神經(jīng)網(wǎng)絡(luò)教程(李亞非)
【PYNQ-Z2試用體驗(yàn)】神經(jīng)網(wǎng)絡(luò)基礎(chǔ)知識(shí)
卷積神經(jīng)網(wǎng)絡(luò)如何使用
【案例分享】ART神經(jīng)網(wǎng)絡(luò)與SOM神經(jīng)網(wǎng)絡(luò)
如何構(gòu)建神經(jīng)網(wǎng)絡(luò)?
matlab實(shí)現(xiàn)神經(jīng)網(wǎng)絡(luò) 精選資料分享
神經(jīng)網(wǎng)絡(luò)移植到STM32的方法
神經(jīng)網(wǎng)絡(luò)運(yùn)用領(lǐng)域
用一張圖像合成動(dòng)圖,讓蒙娜麗莎開(kāi)口說(shuō)話(huà)
用Python從頭實(shí)現(xiàn)一個(gè)神經(jīng)網(wǎng)絡(luò)來(lái)理解神經(jīng)網(wǎng)絡(luò)的原理1

用Python從頭實(shí)現(xiàn)一個(gè)神經(jīng)網(wǎng)絡(luò)來(lái)理解神經(jīng)網(wǎng)絡(luò)的原理2

用Python從頭實(shí)現(xiàn)一個(gè)神經(jīng)網(wǎng)絡(luò)來(lái)理解神經(jīng)網(wǎng)絡(luò)的原理3

用Python從頭實(shí)現(xiàn)一個(gè)神經(jīng)網(wǎng)絡(luò)來(lái)理解神經(jīng)網(wǎng)絡(luò)的原理4

三個(gè)最流行神經(jīng)網(wǎng)絡(luò)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論