 谷歌:半監督學習其實正在悄然的進化
谷歌:半監督學習其實正在悄然的進化
谷歌首席科學家提出要想讓半監督學習實際上有用,要同時考慮低維數據和高維數據,并討論了谷歌最近的兩個研究。作者認為在實際環境中重新審視半監督學習的價值是一個激動人心的時刻。
作為一個機器學習工程師,可能平時最常打交道的就是海量數據了。這些數據只有少部分是有標注的,可以用來進行監督學習。但另外一大部分的數據是沒有標注過的。
那么接下來,我們就會順理成章的想到用這些已標注過的數據進行訓練,再利用訓練好的學習器找出未標注數據中,對性能改善最大的數據,讓機器自己的對未標注數據進行分析來提高泛化性能,
這種介于監督學習和無監督學習之間的方式,稱為半監督學習。人類的學習方法是半監督學習,我們能從大量的未標注數據和極少量的標注數據學習,迅速理解這個世界。
然而半監督學習實踐中根本沒用?
人類的半監督學習非常有效,那么我們自然的希望機器的半監督學習也能達到類似的程度。但是從歷史上來看,半監督學習的效果和我們想象的效果有很大差距。先來看一張圖:
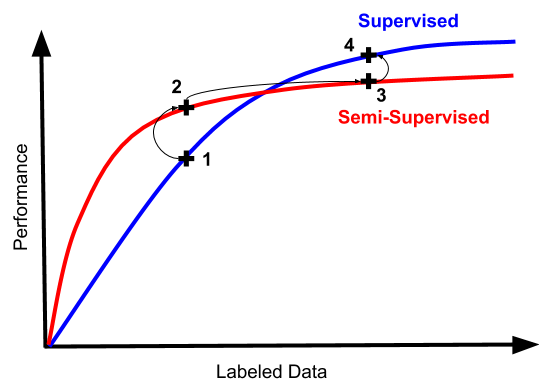
上圖可以看出來,最開始的時候,半監督學習訓練確實有種提升監督學習效果的趨勢,然而實際操作中,我們經常陷入從“可怕又不可用”的狀態,到“不那么可怕但仍然完全不可用”。
如果你突然發現你的半監督學習起效了,這意味著你的分類器單純的不行,單純的沒有實際用處。
而且面對大量的數據,半監督學習方式通常不能實現和監督學習中所實現的相同漸近性質,未標注的數據可能會引入偏差。
舉個例子,在深度學習的早期階段,一種非常流行的半監督學習方法是首先學習一個關于未標注數據的自動編碼器,然后對標注數據進行微調。
現在幾乎沒人這么做了。因為通過自動編碼學習的表示,傾向于在經驗上限制微調的漸近性能。
而且,即使是已經突飛猛進的現代生成方法,也沒有對此狀況有多大的改善。可能因為提升生成模型效果的元素,并不能很有效的提升分類器的效果。
當你在今天看到機器學習工程師對模型進行微調時,基本都是從從監督數據上學習的表示開始。而且文本是用于語言建模目的的自監督數據。
最終我們得出一個結論:實際情況下,從其他預訓練模型進行轉移學習是一個更穩健的起點,在這方面半監督方法難以超越。
所以,一位機器學習工程師在半監督學習的沼澤中艱難前行的典型路徑如下:
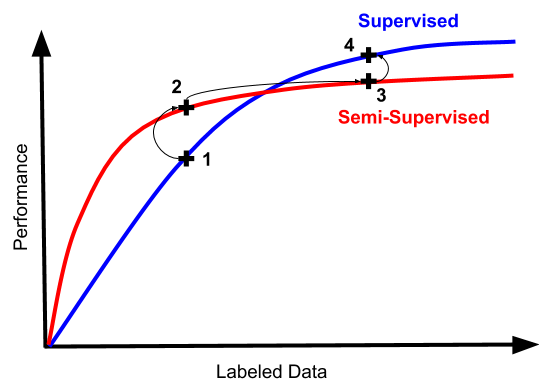
一切都很糟糕,讓我們嘗試半監督學習吧!(畢竟這是工程工作,比標注數據這種純體力活可有意思多了)
看,數字上去了!但是仍然很糟糕。看起來我們還是得去搞標注數據...
數據越多,效果越好。但是你有沒有嘗試過丟棄半監督機器會發生什么?
嘿你知道嗎,它實際上更簡單更好。我們可以通過完全跳過2和3來節省時間和大量技術債
如果你走運的話,你的問題也可能具有這樣的性能特征:
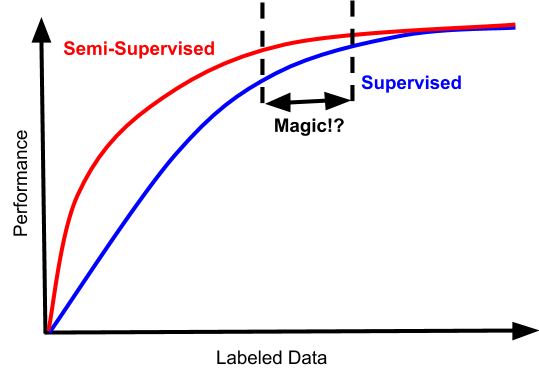
巧了,在這種情況下,存在一種狹窄的數據體系。半監督學習在其中不僅不糟糕,而且還實實在在的提高了數據效率。
但是根據過來人的經驗來看,這個點很難找到。考慮到額外復雜性的成本,標注數據量之間的鴻溝,通常不會帶來多大的效果,并且收益遞減,所以根本不值當浪費精力在這個上面,除非你想在這個領域競爭學術基準。
半監督學習其實正在悄然的進化
說了這么多半監督學習的弱項。其實本文真正想講的是在半監督學習領域,一直在悄悄發生的進化。
一個引人入勝的趨勢是,半監督學習的可能會變成看起來更像這樣的東西:
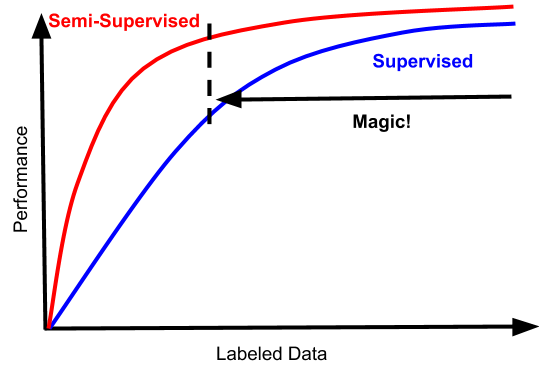
這將改變所有目前半監督學習領域的難題。
這些曲線符合我們理想中的半監督方法的情況:數據越多越好。半監督學習和監督學習之間的差距,也應該是嚴格成正比的,即使是監督學習表現的很好的領域,半監督學習也應該能表現的很好。
而且這種效果的提升伴隨著的是成本的穩定,以及很少量的額外復雜性。圖中的“magic區域”從更低的地方開始,同樣重要的是,它不受高數據制度的束縛。
其他一些新的發展包括:有更好的方式進行自我標注數據,并以這樣的方式表達損失,即它們與噪聲和自我標注的潛在偏差兼容。
最近有兩篇論文講述了半監督學習最近的進展。
MixMatch: A Holistic Approach to Semi-Supervised Learning
論文地址:
https://arxiv.org/abs/1905.02249
Mixmatch是本文中提出的新方法,它巧妙地結合了以前單獨使用的3種SSL范例。
一致性正則化:通過增加標記和未標記的數據輸入來引入
熵最小化:銳化函數減少了未標記數據的猜測標簽中的熵
傳統正則化: MixUp引入了數據點之間的線性關系

在每個batch中,每個標記的數據點被增強一次,并且每個未標記的數據點被增加K(超參數)時間。要求該模型預測所有K個增廣條目(L類的概率),并將它們的平均值作為所有K個條目的預測。
銳化該平均值以最小化熵并將其作為最終預測。將增強的標記和未標記的數據連接并混洗以獲得W.batch中的標記數據與第一個|X|“混合”。 W的條目得到X',其中|X|是batch中標記數據的大小。batch中的未標記數據與W的其余條目“混合”以獲得U'。
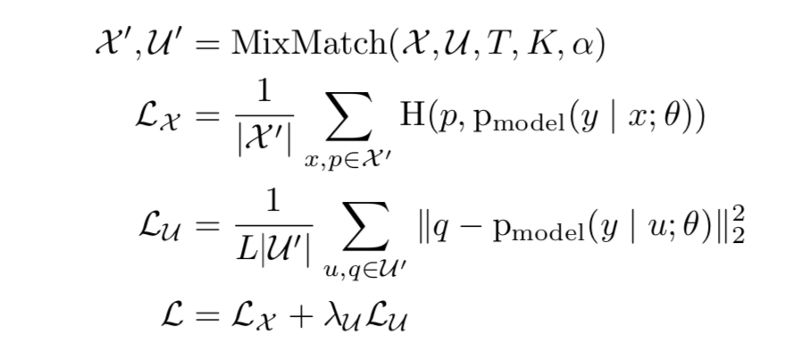
MixMatch算法結合了不同的SSL范例,通過一個重要因素實現了比所有基線數據集上所有當前方法明顯更好的性能。它確保了差異隱私的更好的準確性和隱私的權衡,因為需要比其他方法更少的數據來實現類似的性能。
Unsupervised Data Augmentation
論文地址
https://arxiv.org/abs/1904.12848
本文的重點是從(主要是啟發式的,實用的)數據增強世界中為監督學習提供進展,并將其應用于無監督設置,作為在半監督環境中引入更好性能的一種方式(具有許多未標記點,以及很少標記的)。
論文中的無監督數據增強(UDA)策略注意到兩件事:首先在監督學習領域,在生成增強數據方面存在特定于數據集的創新,這對于給定數據集特別有用。語言建模,這方面的一個例子是把一個句子翻譯成另一種語言,并通過兩個訓練有素的翻譯網絡再次返回,并使用得到的句子作為輸入。對于ImageNet,有一種稱為AutoAugment的方法,它使用驗證集上的強化學習來學習圖像操作的策略(比如旋轉,剪切,改變顏色),以提高驗證的準確性。
(2)在半監督學習中,越來越傾向于使用一致性損失作為利用未標記數據的一種方式。一致性損失的基本思想是,即使不知道給定數據點的類,如果以某種很小的方式修改它,也可以確信模型的預測應該在數據點與其擾動之間保持一致,即使你并不知道實際的ground truth是什么。通常,這樣的系統是在原始未標記圖像的基礎上使用簡單的高斯噪聲設計的。本文的關鍵提議是用更加簡化的擾動程序替代在監督學習中迭代的增強方法,因為兩者的目標幾乎相同。
除了這個核心理念之外,UDA論文還提出了一個額外的聰明的訓練策略:如果你有許多未標注的樣本和少量標注的樣本,你可能需要一個大型模型來捕獲未標注樣本中的信息,但這可能會導致過擬合。
為了避免這種情況,他們使用一種稱為“訓練信號退火”的方法,在訓練中的每個點,他們從損失計算中刪除模型特別有信心的任何樣本,比如真實類別的預測高于某個閾值等。
隨著培訓的進行,網絡逐漸被允許看到更多的訓練信號。在這種框架中,模型不能輕易過度擬合,因為一旦它開始在受監督的例子上得到正確的答案,他們就會退出損失計算。
在實證結果方面,作者發現,在UDA中,他們能夠通過極少數標記的例子來改進許多半監督基準。有一次,他們使用BERT模型作為基線,在其半監督訓練之前以無人監督的方式進行微調,并表明他們的增強方法甚至可以在無人監督的預訓練值之上增加價值。
例如,在IMDb文本分類數據集中,僅有20個標注樣本,UDA優于在25000個標注樣本上訓練的最先進模型。
在標準的半監督學習基準測試中,CIFAR-10具有4,000個樣本,SVHN具有1,000個樣本,UDA優于所有先前的方法,并且降低了超過30%的最先進方法的錯誤率:從7.66%降至5.27%,以及從3.53%降至2.46%。
UDA也適用于具有大量標記數據的數據集。例如,在ImageNet上,使用130萬額外的未標記數據,與AutoAugment相比,UDA將前1/前5精度從78.28/94.36%提高到79.04/94.45%。
半監督學習激動人心的未來
半監督學習的另一個基礎轉變,是大家認識到它可能在機器學習隱私中扮演非常重要的角色,例如Private Aggregation of Teacher Ensemble(PATE)。PATE框架通過仔細協調幾種不同機器學習模型的行為來實現隱私學習。
用于提取知識的隱私敏感方法正在成為聯合學習(Federated Learning)的關鍵推動者之一,聯合學習提供了有效的分布式學習的方式,其不依賴于具有訪問用戶數據的模型,具有強大的數學隱私保證。
在實際環境中重新審視半監督學習的價值有點激動人心,這些進步將會導致機器學習工具架構有極大可能性發生根本轉變。
-
谷歌
+關注
關注
27文章
6161瀏覽量
105304 -
機器學習
+關注
關注
66文章
8406瀏覽量
132567 -
自動編碼
+關注
關注
0文章
4瀏覽量
5834
原文標題:谷歌首席科學家:半監督學習的悄然革命
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
時空引導下的時間序列自監督學習框架

揭秘未來辦公新趨勢:樓宇自控系統的智能進化
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
神經網絡如何用無監督算法訓練
深度學習中的無監督學習方法綜述
谷歌Tensor G5芯片代工轉向臺積電,強化AI智能手機競爭力
谷歌地圖正在對隱私進行重大更改
谷歌提出大規模ICL方法
谷歌模型框架是什么軟件?谷歌模型框架怎么用?
機器學習基礎知識全攻略
DALI照明在物聯網時代的進化

2024年AI領域將會有哪些新突破呢?
谷歌MIT最新研究證明:高質量數據獲取不難,大模型就是歸途






 工商網監
工商網監
評論