 用一張圖像合成動圖,讓蒙娜麗莎開口說話
用一張圖像合成動圖,讓蒙娜麗莎開口說話
蒙娜麗莎開口說話你見過嗎?這位神秘的畫中人也能做出各種 gif 表情?來自三星莫斯科 AI 中心和 Skolkovo 科學技術研究所的研究人員創建了一個模型,利用這個模型可以從一張圖像中生成人物頭像的動圖,而且是開口說話的動圖。而且,這一模型沒有采用 3D 建模等傳統方法。
開口說話的蒙娜麗莎好像看著沒那么高冷。
除了蒙娜麗莎,研究人員還生成了風情萬種的瑪麗蓮·夢露。
他們生成的名人頭部動畫包括瑪麗蓮·夢露、愛因斯坦、蒙娜麗莎以及 Wu Tang Clan 的 RZA 等。
近年來出現了很多利用 AI 模擬人臉的研究。2018 年,華盛頓大學的研究人員分享了他們創建的 ObamaNet,它是一種基于 Pix2Pix 的唇語口型模型,以美國前總統奧巴馬的視頻進行訓練。去年秋天,加州大學伯克利分校的研究人員開發出一個模型,使用 YouTube 視頻來訓練 AI 數據集,生成的人物可以做跳舞或后空翻等雜技動作。
為了創建個性化模型,上面這些研究需要在大量個人數據上進行訓練。但是,在許多實際場景中,我們需要從個人的少量甚至是一張圖像中學習。因此在這項研究中,三星和 Skolkovo 研究所的研究人員只用少量甚至一張圖像或畫作就合成了人物開口說話狀態的頭部動畫。
研究人員利用了 Few-shot learning 等技術,主要合成頭部圖像和面部 landmark,可應用于電子游戲、視頻會議或者三星 Galaxy S10 上現在可用的數字替身(digital avatar)。這種虛擬現實項目的數字替身技術可用于創建 deepfake 圖像和視頻。
Few-shot 學習意味著該模型在僅使用幾幅甚至一幅圖像的情況下模擬人臉。研究人員使用 VoxCeleb2 視頻數據集進行元訓練(meta trainning)。在元學習過程中,系統創建了三種神經網絡:將幀映射到向量的嵌入器網絡、在合成視頻中映射面部特征點的生成器網絡以及評估生成圖像真實性和姿態的判別器網絡。
聯合三種網絡,該系統能在大型視頻數據集上執行長時間的元學習過程。待元學習收斂后,就能構建 few-shot 或 one-shot 的神經頭像特寫模型。該模型將未見過的目標任務視為對抗學習問題,這樣就能利用已學習的高質量生成器與判別器。
論文作者表示:「至關重要的一點是,盡管需要調整數千萬參數,該系統能夠因人而異地初始化生成器和判別器參數,因此訓練可以在僅借助幾幅圖像的情況下快速完成。這種方法能夠快速學習新面孔甚至是人物肖像畫和個性化的頭像特寫模型。」
該論文已被 2019 CVPR 會議接收,本屆會議將于六月份在加利福尼亞州的長灘舉行。
新穎的對抗學習架構
在這項研究中,研究者提出了一種新系統,可以只使用少量圖像(即Few shot learning)和有限的訓練時間,構建「頭像特寫」模型。實際上,研究者的模型可以基于單張圖像(one-shot learning)生成合理的結果,而且在添加少量新樣本后,模型能生成保真度更高的個性化圖像。
與很多同類工作相同,研究者的模型使用卷積神經網絡構建頭像特性,它通過一個序列的卷積運算直接合成視頻幀,而不是通過變形(warping)。研究者模型創建的頭像特寫可以實現大量不同的姿態,其性能顯著高于基于變形(warping-based)的系統。
通過在頭像特寫語料庫上的大量預訓練(meta-learning),模型能獲得 few-shot 學習的能力。當然這需要語料庫足夠大,且頭部特寫視頻對應不同的說話者與面孔。在元學習過程中,研究者的系統模擬了 few-shot 學習任務,并學習將面部 landmark 位置轉換到逼真的個性化照片。在 few-shot 學習中,他們只需要提供轉換目標的少量訓練圖像就可以。
隨后,轉換目標的少量圖像可視為一個新的對抗學習問題,其高復雜度的生成器與判別器都通過元學習完成了預訓練。新的對抗問題最終會完成收斂,即在少量訓練迭代后能生成真實和個性化的圖像。
元學習架構
下圖 2 展示了研究者方法中的元學習階段,簡單而言它需要訓練三個子網絡。注意,若我們有 M 個視頻序列,那么 x_i(t) 表示第 i 個視頻的第 t 幀。
第一個子網絡 embedder E:它會輸入視頻幀 x_i(s) 以及對應的 landmark 圖像 y_i(s),該網絡會將輸入映射到 N 維向量 e hat_i(s) 中。
第二個子網絡 generator G:它會輸入新的 landmark 圖像 y_i(t),且 embedder 看不到其對應的視頻幀;該網絡還會輸入 embedder 輸出的 e hat_i,并希望能輸出合成的新視頻幀 x hat_i(t)。
第三個子網絡 discriminator D:它會輸入視頻幀 x_i(t)、對應的 landmark 圖像 y_i(t),以及訓練序列的索引 i。該網絡希望判斷視頻幀 x_i(t) 到底是不是第 i 個視頻中的內容,以及它到底匹不匹配對應的 landmark 圖像 y_i(t)。
圖 2:元學習架構的整體結構,主要包含嵌入器(embedder)、生成器和判別器三大模塊。
嵌入器網絡希望將頭像特寫圖像與對應的人臉 landmark 映射到嵌入向量,該向量包含獨立于人臉姿態的信息。生成器網絡通過一系列卷積層將輸入的人臉 landmark 映射到輸出幀中,其生成結果會通過嵌入向量以及自適應實例歸一化進行調整。在元學習中,研究者將相同視頻一組視頻幀傳遞到嵌入器,并對嵌入向量求均值以便預測生成器的自適應參數。
隨后,研究者將不同幀的 landmark 輸入到生成器中,并對比標注圖像和生成圖像之間的差別。模型的整體優化目標包括感知和對抗兩種損失函數,后者通過條件映射判別器實現。
此外,元學習的三大子網絡在原論文中都有具體的表達式,讀者可具體查閱原論文 3.2 章。
Few-shot 學習過程
一旦元學習完成收斂,那么系統就能學習到如何合成新目標的頭像特寫序列,即使元學習中不曾見過這個人。當然,除了要提供新目標的一些圖像樣本,我們還需要提供新目標的 landmark,合成過程是以這些目標 landmark 為條件的。
很自然地,我們可以使用元學習收斂后的嵌入器(embedder),用來估計新頭像特寫序列的嵌入向量:
一種比較直觀的想法是使用上面的嵌入向量,以及預訓練的生成器生成新的視頻幀與對應 landmark 圖像。理論上這樣也能生成真實的圖像,但真實性并不是太強。為此,研究者還需要一個精調過程以生成更完美的圖像,即 few-shot 學習過程。
精調過程可視為前面元學習過程的簡化版,它只在單個視頻序列和較少的幀上完成訓練。精調過程主要包含判別器與生成器兩個模塊,這里嵌入器是不需要調整的。
其中生成器還是根據 landmark 合成視頻幀,只不過對應具體人物的生成器參數 ψ'會和原來一般人物參數ψ共同優化,以學習生成目標人物的某些特征。判別器和元學習階段也差不多,只不過會增加一個新參數以學習更好地預測真實度分數。
實驗
研究者在定性和定量評估實驗中用到了兩個數據集:VoxCeleb1 和 VoxCeleb2。后者的視頻數量大約是前者的 10 倍。VoxCeleb1 用于與基線和控制變量研究作對比,VoxCeleb2 用于展示本文中所提方法的全部潛力。實驗結果如下表所示:
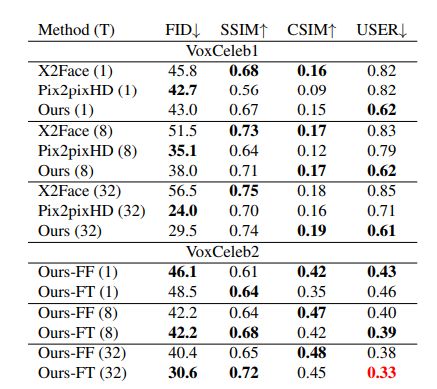
如表 1 所示,基線模型在兩個相似度度量標準上始終優于三星的方法。三星研究人員認為,這是方法本身所固有的:X2Face 在優化期間使用 L_2 損失函數,因此 SSIM 得分較高。另一方面,Pix2pixHD 只最大化了感知度量,沒有 identity preservation 損失,導致 FID 最小化,但從 CSIM 一欄中可以看出,Pix2pixHD 的 identity 不匹配更大。
此外,這些度量標準和人類的感知并沒有特別緊密的關聯,因為這些方法都會產生恐怖谷偽影(uncanny valley artifact),這從圖 3 和用戶研究結果中可以看出。另一方面,余弦相似度與視覺質量有更好的相關性,但仍然傾向于模糊、不太真實的圖像,這也可以通過表 1 與圖 3 中的結果對比來看出。
圖 3:在 VoxCeleb1 數據集上的結果。對于每一種對比方法,研究者在一個元訓練或預訓練期間未見過的人物視頻上執行 one-shot 和 few-shot 學習。他們將訓練的幀數設為 T(最左邊的數字)。Source 列顯示了訓練幀之一。
接下來,研究者擴展了可用的數據,開始在視頻數目更多的 VoxCeleb2 上訓練模型。他們訓練了兩種模型:FF(前饋)和 FT。前者訓練 150 個 epoch,沒有嵌入匹配損失 LMCH,因此用的時候不進行微調。后者訓練 75 個 epoch,但有 LMCH,支持微調。
他們對這兩種模型都進行了評估,因為它們可以在 few-shot 學習速度和結果質量之間進行權衡。與在 VoxCeleb1 上訓練的小型模型相比,二者都得到了很高的分數。值得注意的是,FT 模型在 T=32 的設定下達到了用戶研究準確率的下界,即 0.33,這是一個完美的分數。兩種模型的結果如圖 4 所示:
圖 4:三星最好的模型在 VoxCeleb2 數據集上的結果。
最后,研究者展示了模型在照片或畫像上的結果。為此,研究者評估了在 one-shot 設定下訓練的模型,任務姿態來自 VoxCeleb2 數據集的測試視頻。他們使用 CSIM 度量給這些視頻排序,并在原始圖像和生成圖像之間進行計算。這使得研究者可以發現擁有相似標志幾何特征的人臉,并將它們由靜態變為動態。結果見圖 5 和圖 1.
圖 5:使靜止的照片栩栩如生。
-
三星電子
+關注
關注
34文章
15859瀏覽量
180987 -
人工智能
+關注
關注
1791文章
47188瀏覽量
238268
原文標題:[機器人頻道|大V說]蒙娜麗莎開口說話了:三星新研究用一張圖像合成動圖,無需3D建模
文章出處:【微信號:robovideo,微信公眾號:機器人頻道】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
10張動圖:秒懂各種常用通信協議原理


如何維修一張電腦顯卡型號是amd的rx580 燒壞的部位?
用LM358P和IRF631搭建了一個恒流源,運放出來的波形失真嚴重,為什么?
安卓設備接收iPhone GIF動圖成靜態
打破壁壘,共建網絡:“一張網”理念下的IPv6部署策略







 工商網監
工商網監
評論