 小心別讓人工智能變成人工智障了
小心別讓人工智能變成人工智障了
如今,人工智能已經深入生活的方方面面,我們的社會更加依賴于算法做決策,而不是人。這些系統已經在銀行、電子商務、醫療保健以及治安等領域顯現出了強大的潛力。
然而,人們越來越擔心算法的控制權過多,尤其是當人們將決定權交給機器的時候,例如自動駕駛汽車或法庭判決等場合。如果因此而阻礙人工智能的使用,那么社會和經濟就有可能無法享受人工智能帶來的各種潛在優勢。
Hannah Fry是倫敦大學學院高級空間分析中心的數學家,多年來她一直在研究這些系統。不過人們對她的更多了解來自BBC的公開講座和紀錄片,她是一名數學和科學領域的知名人士。
在她最新的著作《Hello World》一書中,Fry女士揭開了這種技術的神秘面紗,她通過回顧歷史向我們解釋了如何采用數據驅動的決策,并提供了清晰的利弊分析。使用人工智能的好處在于,AI可以更快更準確地執行任務,而缺點是如果數據有偏差,那么輸出可能有偏差。
The Economist針對社會應當如何利用這項技術,對Fry女士進行了采訪。在本文中,首先我們會詳細報道此次采訪的內容,而后面的部分是《Hello World》一書中有關刑事司法系統和“隨機森林”算法的節選。
自動化會失誤,人類才是考慮的核心
The Economist:所有的數據都有偏差,那么我們是否應該推遲算法系統的引入,直到我們確信我們已經發現并解決了算法系統中的關鍵性問題,還是說我們應該降低標準:“盡最大努力”來發現和修正偏差,同時在發現漏洞的時候,可以隨時發布代碼和補丁?
Hannah Fry:大家在這個問題上很容易產生一種誤解。當看到算法會引發別的問題時,我們就想著完全拋棄這些算法,并認為我們應該堅持依賴人類的決策來解決問題,直到更好的算法出現。然而,實際上人類也存在偏見,而且還會受到各種問題的迷惑。
其實,這完全取決于你需要的精準度。例如,你可以在足球比賽中引入“視頻助理裁判”,但你不能不負責任地以相同的方式在醫療保健領域引入一個有問題的系統。總的來說,總體目標必須是建立最公平、最統一的系統。這意味你必須承認完美是不可能的,而且權衡利弊也在所難免。然而,同時也意味著我們應該設法鼓勵利用算法做決策,盡管它們也難免會出錯。
The Economist:刑事司法系統有時會吹噓“與其讓一個無辜的人入獄,不如釋放一個罪犯”的價值觀。我們是否應該拒絕在法庭上采用算法來做出嚴肅的決定(即宣判),因為我們永遠也不確定這是否是盲目的正義?
Hannah Fry:每個刑事司法系統都必須在保護無辜的人被誣告和保護犯罪受害者之間找到某種平衡。實現這種平衡并非易事,而且司法系統也并非完美——而且也從未嘗試做到完美。這就是為什么“合理地懷疑”和“充分的理由”之類的詞匯是基本的法律用語:這類的系統必須接受絕對的確定性是無法實現的。
然而,即使在這些約束之下,法官的決定里面仍然可能有前后矛盾和運氣的成分。人們無法保證做出公平和一致的決策。而法官與我們其他人一樣,有時也無法放下潛在的偏見。
如果你謹慎地對待這些問題,那么我認為我們有可能通過使用算法來支持法官的決定,從而將這類問題降到最少。你必須確保以一種更公平地方式使用系統,還要確保不會意外地加劇已經存在的偏差。
The Economist:你是否擔心最終人類會把生活中重要的權利交給機器,就像我們已經由于電子地圖的出現而喪失了方向感?
Hannah Fry:我認為,隨著自動化的發展,我們的確會失去一些技能。例如,現在我連自己的電話號碼都記不住,更不用說我以前知道的那一長串電話號碼了,而且我的書法也一落千丈。但我并不覺得自己非常擔心這方面的問題。
歷史上我們也曾經歷過擔心技能退化的問題。飛行員就曾有過這樣的經歷:自動駕駛越好,初級飛行員手動控制飛機的技術就越差。以前在手術室里,初級外科醫生可以通過在開放式手術中協助咨詢顧問的方式(他們的手會接觸患者,觸摸和感覺身體)進行訓練,而如今他們可以觀看咨詢顧問坐在控制臺操作的微創手術,而且還有內部的攝像機在屏幕上放映。
如果有一天我們真的進入無人駕駛汽車普及的階段,而我們卻不認真考慮如何保持我們的駕駛技術的話,那么人們在沒有輔助的情況下的駕駛能力會下降,我們仍然希望我們能夠人為介入,并在緊急情況下采取行動控制汽車。
為了避免這個問題,你可以采取一系列措施,例如時不時地故意關閉機器。但我認為,我們應該承認自動化有時也會出現失誤,而且我們應該確保人類(以及他們的需求和失誤)始終應該是我們考慮的核心。
The Economist:當算法進入醫學、法律和其他領域時,算法得出的決定只能作為“建議”,人類在這個過程中仍然有最終的決定權。然而,根據行為心理學的大多數研究表明這只是一種假象:算法對人類有著非凡的影響。我們怎樣才能從現實的角度克服這個問題呢?
Hannah Fry:通常人們都很懶惰。我們喜歡采用簡單的方法,我們喜歡推卸責任,我們喜歡走捷徑,如此一來我們就不必思考了。
如果你設計的算法可以告訴你答案,而你卻希望人們會再三檢查這個答案,提出質疑,并且還知道在適當的時候提出別的答案,那么實際上你在自掘墳墓。人類本身就不擅長做這種事情。
但是,如果你設計的算法能夠坦然地承認它們的不確定性——公開和坦誠地向你的用戶說明它們做決定的過程,以及在這個過程中經歷的所有混亂和模糊,那么我們就知道什么時候我們應該相信自己的直覺。
我認為這是IBM的沃森最好的一個功能,它參加了美國的智力競賽節目《危險邊緣》(Jeopardy)!而且還獲勝了。雖然該節目要求選擇一個答案,但該算法在此過程中還考慮了替代方案,并表明了每種方案的正確概率。
這也是最新的衛星導航的好處:它們并不會為你決定路線,而是會給你三個選擇,并告訴你利弊。你可以通過這些信息做出明智的決定,而不是盲目地交出控制權。
The Economist:有什么事情是人類能做,機器卻做不了的嗎?為了幫助人類在算法時代依然蓬勃發展,我們的社會需要做出哪些改變?
Hannah Fry:人類可以比機器更好地理解背景和細微的差別。我們的適應性更強。如果你把我們帶到一個全新的環境下,我們知道如何表現,這是最優秀的人工智能也望塵莫及的。
除此之外,這是一個人類的世界,而不是算法的世界。因此,人類始終應該居于新技術思想的前沿和中心。
這話看似顯而易見,然而實際情況卻并非如此。最近的趨勢有意將新算法迅速推向世界,并通過現實世界中的真實用戶進行現場實驗,而不是停下來思考這些算法是否弊大于利,或發現它們有問題后推遲采用這些算法。(我說的就是你:社交媒體。)
我認為社會需要堅定立場:有些新技術(例如新藥)需要謹慎使用并提前考慮最壞的情況。我認為我們構建的算法應該誠實地表明它們的弱點,并坦誠地說明完美往往都是不可能的。但最重要的是,我認為我們構建的算法應該接受人類的失誤,而不是視而不見。
面向司法的數學式
它們無法衡量辯護方和起訴方的辯論,分析證據,或決定被告是否真的有悔意。所以我們不能指望算法在近期內取代法官。然而,算法也有意想不到的用處,比如使用個人的數據來計算他們今后再次犯罪的概率。而且,由于許多法官也會根據罪犯是否會再次犯罪的概率來判決,因此這種算法非常實用。
司法系統使用數據和算法已有將近一個世紀的歷史了,第一次的使用可以追溯到20世紀20年代美國的一宗案子。當時,根據美國的制度,被定罪的罪犯將被判處最高刑期,然后在一段時間過后才有資格獲得假釋。數萬名囚犯依據此律獲準提前釋放。有些人重獲自由,而有些人則沒有。
但總的來說,他們的案例為自然實驗提供了完美的環境:你能否預測罪犯會違反他們的假釋條款嗎?
芝加哥大學的加拿大社會學家Ernest W. Burgess對預測充滿了興趣。Burgess是量化社會現象的重要支持者。在他的職業生涯中,他一直在嘗試預測退休和婚姻成功產生的影響。1928年,他成功地建立了第一個預測工具,這個工具可以根據測量的結果(而不是直覺)預測犯人再次犯罪的概率。
Burgess利用美國伊利諾伊州三所監獄中三千名囚犯的各種數據,找出了他認為對于決定某人是否會違反他們的假釋條款“可能有著重大影響”的21個因素。其中包括犯罪的類型、在監獄中服刑的月份和囚犯的社會類型——他根據二十世紀早期社會科學家所關注的話題對罪犯進行了分類:流浪漢、酒鬼、窩囊廢、鄉巴佬和移民。
Burgess從這21個因素出發為每個犯人打分(0或1)。獲得高分(16-21分)的人再次犯罪的概率最低,而那些得分很低(4分以下)的人則極有可能違反他們的假釋條款。
等到最終所有囚犯都被釋放后,有些人違反了假釋條款,于是Burgess抓緊這次機會檢驗他的預測結果。通過一個基本的分析,他發現自己預測非常準確。在他的低風險人群中有98%通過了他們的假釋,而他認定的高危人群中有三分之二沒有通過假釋。事實證明,即使是粗略的統計模型也可以比專家做出更好的預測。
但Burgess的工作也受到了批評。
持懷疑態度的旁觀者質疑,從一個地方得出的預測假釋成功的因素中有多少能夠適用于其他地方。(他們其中的一個觀點是:在預測現代化大城市內犯罪分子再次犯罪的概率時,如何確保“鄉巴佬”會有很大的幫助。)
其他學者還指出Burgess只利用了現有的信息,而沒有調查其中的相關性。關于對他對囚犯進行評分的方式也存在疑問:畢竟,他的方法只不過是根據方程式算出來的。盡管如此,這種預測能力也足以讓人震撼,1935年美國伊利諾伊州的監獄開始借助Burgess的方法支持假釋委員會做出決定。等到了世紀之交,由Burgess的方法衍生出來的其他數學方法在全世界范圍內得到了應用。
再來看看現代,目前法庭使用的最先進的風險評估算法遠比Burgess設計的基本工具復雜得多。這些算法不僅可以協助假釋決定,而且還可以幫忙為囚犯指定干預方案,決定誰應該獲得保釋,最近還開始支持法官做出判刑決定。這些算法的基本原則與以往一樣:了解被告的情況(年齡、犯罪歷史、犯罪的嚴重性等等),并預測讓他們獲得保釋的危險程度。
那么,這些算法的工作原理是什么呢?從廣義上講,表現最優秀的現代算法采用了一種名叫隨機森林的技術,其核心的概念非常簡單,就是簡單的決策樹。
征詢觀眾的意見
你可能在學生時期就聽說過決策樹。
數學老師很喜歡決策樹,他們把決策樹當成一種組織觀察的方式,例如拋硬幣或擲骰子。在構建完成后,你可以把決策樹當成一種流程圖:根據一系列的要素,逐步評估下一步該做什么,或者判斷當前情況下的事態發展。
想象一下,你正在決定是否批準某人的保釋。與假釋一樣,這個決定的根本只是一個簡單的計算。有罪與否并不要緊。你只需要做出預測:被告是否會被判入獄,是否會違反保釋協議的條款?
為了幫助你做出預測,你可以參考一些之前的罪犯數據,有些人在保釋期間逃跑,或再次犯罪,而有些人卻沒有。
你可以利用這些數據,手工構建一個簡單的決策樹,如下圖所示,利用每個罪犯的特征來構建流程圖。構建完成后,你就可以利用決策樹預測罪犯的行為方式。你只需要根據犯罪者的特征沿著相關的分支前進,直到得出預測結果。只要這些結果符合之前所有人的模式,預測就是正確的。
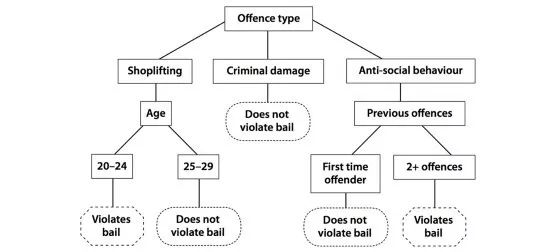
然而,我們在學校制作的這種決策樹也會出現失誤。當然,并非每個人都和之前的模式一模一樣。而且決策樹本身也會產生很多錯誤的預測。而且不僅僅是因為我們的這個例子非常簡單,即使你擁有大量之前的案例數據集,并建立極其復雜的流程圖,偏差也再所難免,最后的結果我們也只能說使用一棵決策樹總比隨便亂猜稍好一些。
然而,如果你構建了不止一棵樹,那么一切都有可能改變。這一次我們不會一次性用光所有數據,而是采用分而治之的方法。
在所謂的集合中,首先我們根據數據的隨機子集構建數千棵小樹。然后,當有新的被告時,你只需讓每棵樹投票決定是否應該批準保釋。樹木之間可能并不完全一致,而且每棵樹依舊可能做出不準的預測,但你只需要取所有答案的平均值,就可以大大提高預測的精確度。
這有點像在“誰想成為百萬富翁”的節目中征詢觀眾的意見。雖然房間里面都是陌生人,但是他們加在一起比最聰明的人更有可能得出準確的答案。(“征詢觀眾的意見”的成功率為91%,相比之下,“打電話向朋友求助”的成功率僅為65%。)
許多人所犯的錯誤可能相互抵消,所以一群人總是比一個人更聰明。
同樣的道理也適用于一大群決策樹,它們組成一個隨機森林。因為這種算法的預測是基于它從數據中學習的模式,所以隨機森林又被稱作機器學習算法,這種算法在人工智能領域的應用非常廣泛。(值得一提的是,該算法本質上就是你在上學時繪制的流程圖,只不過經過了一些數學操作,這聽起來是不是很偉大?)
事實證明,隨機森林在整個現實世界的應用程序中非常有幫助性。Netflix通過隨機森林,根據你過去的喜好,預測你想要觀看的內容; Airbnb可以檢測欺詐賬戶;而醫療界用隨機森林來診斷疾病。
在評估犯罪分子時,與人類評估相比,隨機森林擁有兩大優勢。首先,該算法可以針對相同的案例給出完全相同的答案。保證一致性的同時也不犧牲個人的司法公正。還有一個關鍵的優勢:這種算法可以得出更好的預測結果。
-
人工智能
+關注
關注
1799文章
48047瀏覽量
241944 -
大數據
+關注
關注
64文章
8925瀏覽量
138170
原文標題:忽略這一點,人工智能變人工智障!
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論