


2019 年 3 月 6 日,谷歌在 TensorFlow 開發者年度峰會上發布了最新版的 TensorFlow 框架 TensorFlow2.0 。新版本對 TensorFlow 的使用方式進行了重大改進,使其更加靈活和更具人性化。具體的改變和新增內容可以從 TensorFlow 的官網找到,本文將介紹如何使用 TensorFlow2.0 構建和部署端到端的圖像分類器,以及新版本中的新增內容,包括:
使用 TensorFlow Datasets 下載數據并進行預處理
使用 Keras 高級 API 構建和訓練圖像分類器
下載 InceptionV3 卷積神經網絡并對其進行微調
使用 TensorFlow Serving 為訓練好的模型發布服務接口
本教程的所有源代碼都已發布到 GitHub 庫中,有需要的讀者可下載使用。
項目地址:
https://github.com/himanshurawlani/practical_intro_to_tf2
在此之前,需要提前安裝 TF nightly preview,其中包含 TensorFlow 2.0 alpha 版本,代碼如下:
$pipinstall-U--pretensorflow
1. 使用 TensorFlow Datasets 下載數據并進行預處理
TensorFlow Datasets 提供了一組可直接用于 TensorFlow 的數據集,它能夠下載和準備數據,并最終將數據集構建成 tf.data.Dataset 形式。
通過 pip 安裝 TensorFlow Datasets 的 python 庫,代碼如下:
$ pip install tfds-nightly
1.1 下載數據集
TensorFlow Datasets 中包含了許多數據集,按照需求添加自己的數據集。
具體的操作方法可見:
https://github.com/tensorflow/datasets/blob/master/docs/add_dataset.md
如果我們想列出可用的數據集,可以用下面的代碼:
import tensorflow_datasets as tfdsprint(tfds.list_builders())
在下載數據集之前,我們最好先了解下該數據集的詳細信息,例如該數據集的功能信息和統計信息等。本文將使用 tf_flowers 數據集,該數據集的詳細信息可以在 TensorFlow 官網找到,具體內容如下:
數據集的總可下載大小
通過 tfds.load() 返回的數據類型/對象
數據集是否已定義了標準分割形式:訓練、驗證和測試的大小
對于本文即將使用的 tf_flowers 數據集,其大小為 218MB,返回值為 FeaturesDict 對象,尚未進行分割。由于該數據集尚未定義標準分割形式,我們將利用 subsplit 函數將數據集分割為三部分,80% 用于訓練,10% 用于驗證,10% 用于測試;然后使用 tfds.load() 函數來下載數據,該函數需要特別注意一個參數 as_supervised,該參數設置為 as_supervised=True,這樣函數就會返回一個二元組 (input, label) ,而不是返回 FeaturesDict ,因為二元組的形式更方便理解和使用;接下來,指定 with_info=True ,這樣就可以得到函數處理的信息,以便加深對數據的理解,代碼如下:
import tensorflow_datasets as tfdsSPLIT_WEIGHTS = (8, 1, 1)splits = tfds.Split.TRAIN.subsplit(weighted=SPLIT_WEIGHTS)(raw_train, raw_validation, raw_test), metadata = tfds.load(name="tf_flowers", with_info=True, split=list(splits),# specifying batch_size=-1 will load full dataset in the memory# batch_size=-1,# as_supervised: `bool`, if `True`, the returned `tf.data.Dataset`# will have a 2-tuple structure `(input, label)` as_supervised=True)
1.2 對數據集進行預處理
從 TensorFlow Datasets 中下載的數據集包含很多不同尺寸的圖片,我們需要將這些圖像的尺寸調整為固定的大小,并且將所有像素值都進行標準化,使得像素值的變化范圍都在 0~1 之間。這些操作顯得繁瑣無用,但是我們必須進行這些預處理操作,因為在訓練一個卷積神經網絡之前,我們必須指定它的輸入維度。不僅如此,網絡中最后全連接層的 shape 取決于 CNN 的輸入維度,因此這些預處理的操作是很有必要的。
如下所示,我們將構建函數 format_exmaple(),并將它傳遞給 raw_train, raw_validation 和 raw_test 的映射函數,從而完成對數據的預處理。需要指明的是,format_exmaple() 的參數和傳遞給 tfds.load() 的參數有關:如果 as_supervised=True,那么 tfds.load() 將下載二元組 (image, labels) ,該二元組將作為參數傳遞給 format_exmaple();如果 as_supervised=False,那么 tfds.load() 將下載一個字典
def format_example(image, label): image = tf.cast(image, tf.float32) # Normalize the pixel values image = image / 255.0 # Resize the image image = tf.image.resize(image, (IMG_SIZE, IMG_SIZE)) return image, labeltrain = raw_train.map(format_example)validation = raw_validation.map(format_example)test = raw_test.map(format_example)
除此之外,我們還對 train 對象調用 .shuffle(BUFFER_SIZE) ,用于打亂訓練集的順序,該操作能夠消除樣本的次序偏差。Shuffle 的緩沖區大小最后設置得和數據集一樣大,這樣能夠保證數據被充分的打亂。接下來我們要用 .batch(BATCH_SIZE) 來定義這三類數據集的 batch 大小,這里我們將 batch 的大小設置為 32 。最后我們用 .prefetch() 在后臺預加載數據,該操作能夠在模型訓練的時候進行,從而減少訓練時間,下圖直觀地描述了 .prefetch() 的作用。
不采取 prefetch 操作,CPU 和 GPU/TPU 的大部分時間都處在空閑狀態
采取 prefetch 操作后,CPU 和 GPU/TPU 的空閑時間顯著較少
在該步驟中,有幾點值得注意:
操作順序很重要。如果先執行 .shuffle() 操作,再執行 .repeat() 操作,那么將進行跨 batch 的數據打亂操作,每個 epoch 中的 batch 數據都是被提前打亂的,而不用每次加載一個 batch 就打亂依一次它的數據順序;如果先執行 .repeat() 操作,再執行 .shuffle() 操作,那么每次只有單個 batch 內的數據次序被打亂,而不會進行跨 batch 的數據打亂操作。
將 buffer_size 設置為和數據集大小一樣,這樣數據能夠被充分的打亂,但是 buffer_size 過大會導致消耗更多的內存。
在開始進行打亂操作之前,系統會分配一個緩沖區,用于存放即將進行打亂的數據,因此在數據集開始工作之前,過大的 buffer_size 會導致一定的延時。
在緩沖區沒有完全釋放之前,正在執行打亂操作的數據集不會報告數據集的結尾。而數據集會被 .repeat() 重啟,這將會又一次導致 3 中提到的延時。
上面提到的 .shuffle ()和 .repeat(),可以用 tf.data.Dataset.apply() 中的 tf.data.experimental.shuffle_and_repeat() 來代替:
ds = image_label_ds.apply( tf.data.experimental.shuffle_and_repeat(buffer_size=image_count))ds = ds.batch(BATCH_SIZE)ds = ds.prefetch(buffer_size=AUTOTUNE)
1.3 數據增廣
數據增廣是提高深度學習模型魯棒性的重要技術,它可以防止過擬合,并且能夠幫助模型理解不同數據類的獨有特征。例如,我們想要得到一個能區分“向日葵”和“郁金香”的模型,如果模型只學習了花的顏色從而進行辨別,那顯然是不夠的。我們希望模型能夠理解花瓣的形狀和相對大小,是否存在圓盤小花等等。
為了防止模型使用顏色作為主要的判別依據,可以使用黑白圖片或者改變圖片的亮度參數。為了減小圖片拍攝方向導致的偏差,可以隨機旋轉數據集中的圖片,依次類推,可以得到更多增廣的圖像。
在訓練階段,對數據進行實時增廣操作,而不是手動的將這些增廣圖像添加到數據上。用如下所示的映射函數來實現不同類型的數據增廣:
defaugment_data(image,label): print("Augment data called!") image = tf.image.random_flip_left_right(image) image = tf.image.random_contrast(image, lower=0.0, upper=1.0) # Add more augmentation of your choice return image, labeltrain = train.map(augment_data)
1.4 數據集可視化
通過可視化數據集中的一些隨機樣本,不僅可以發現其中存在的異常或者偏差,還可以發現特定類別的圖像的變化或相似程度。使用 train.take() 可以批量獲取數據集,并將其轉化為 numpy 數組, tfds.as_numpy(train) 也具有相同的作用,如下代碼所示:
plt.figure(figsize=(12,12)) for batch in train.take(1): for i in range(9): image, label = batch[0][i], batch[1][i] plt.subplot(3, 3, i+1) plt.imshow(image.numpy()) plt.title(get_label_name(label.numpy())) plt.grid(False) # ORfor batch in tfds.as_numpy(train): for i in range(9): image, label = batch[0][i], batch[1][i] plt.subplot(3, 3, i+1) plt.imshow(image) plt.title(get_label_name(label)) plt.grid(False) # We need to break the loop else the outer loop # will loop over all the batches in the training set break
運行上述代碼,我們得到了一些樣本圖像的可視化結果,如下所示:
2. 用tf.keras 搭建一個簡單的CNN模型
tf.keras 是一個符合 Keras API 標準的 TensorFlow 實現,它是一個用于構建和訓練模型的高級API,而且對 TensorFlow 特定功能的支持相當好(例如 eager execution 和 tf.data 管道)。 tf.keras 不僅讓 TensorFlow 變得更加易于使用,而且還保留了它的靈活和高效。
張量 (image_height, image_width, color_channels) 作為模型的輸入,在這里不用考慮 batch 的大小。黑白圖像只有一個顏色通道,而彩色圖像具有三個顏色通道 (R,G,B) 。在此,我們采用彩色圖像作為輸入,輸入圖像尺寸為 (128,128,3) ,將該參數傳遞給 shape,從而完成輸入層的構建。
接下來我們將用一種很常見的模式構建 CNN 的卷積部分:一系列堆疊的 Conv2D 層和 MaxPooling2D 層,如下面的代碼所示。最后,將卷積部分的輸出((28,28,64)的張量)饋送到一個或多個全連接層中,從而實現分類。
值得注意的是,全連接層的輸入必須是一維的向量,而卷積部分的輸出卻是三維的張量。因此我們需要先將三維的張量展平成一維的向量,然后再將該向量輸入到全連接層中。數據集中有 5 個類別,這些信息可以從數據集的元數據中獲取。因此,模型最后一個全連接層的輸出是一個長度為 5 的向量,再用 softmax 函數對它進行激活,至此就構建好了 CNN 模型。
from tensorflow import keras# Creating a simple CNN model in keras using functional APIdef create_model(): img_inputs = keras.Input(shape=IMG_SHAPE) conv_1 = keras.layers.Conv2D(32, (3, 3), activation='relu')(img_inputs) maxpool_1 = keras.layers.MaxPooling2D((2, 2))(conv_1) conv_2 = keras.layers.Conv2D(64, (3, 3), activation='relu')(maxpool_1) maxpool_2 = keras.layers.MaxPooling2D((2, 2))(conv_2) conv_3 = keras.layers.Conv2D(64, (3, 3), activation='relu')(maxpool_2) flatten = keras.layers.Flatten()(conv_3) dense_1 = keras.layers.Dense(64, activation='relu')(flatten) output = keras.layers.Dense(metadata.features['label'].num_classes, activation='softmax')(dense_1) model = keras.Model(inputs=img_inputs, outputs=output) return model
上面的模型是通過 Kearas 的 Functional API 構建的,在 Keras中 還有另一種構建模型的方式,即使用 Model Subclassing API,它按照面向對象的結構來構建模型并定義它的前向傳遞過程。
2.1 編譯和訓練模型
在 Keras 中,編譯模型就是為其設置訓練過程的參數,即設置優化器、損失函數和評估指標。通過調用 model 的 .fit() 函數來設置這些參數,例如可以設置訓練的 epoch 次數,再例如直接對 trian 和 validation 調用 .repeat() 功能,并傳遞給 .fit() 函數,這樣就可以保證模型在數據集上循環訓練指定的 epoch 次數。
在調用 .fit() 函數之前,我們需要先計算幾個相關的參數:
# Calculating number of images in train, val and test setsnum_train, num_val, num_test = (metadata.splits['train'].num_examples * weight/10 for weight in SPLIT_WEIGHTS)steps_per_epoch = round(num_train)//BATCH_SIZEvalidation_steps = round(num_val)//BATCH_SIZE
如上代碼所示,由于下載的數據集沒有定義標準的分割形式,我們通過設置 8:1:1 的分割比例,將數據集依次分為訓練集、驗證集和測試驗證集。
steps_per_epoch:該參數定義了訓練過程中,一個 epoch 內 batch 的數量,該參數的值等于樣本數量除以 batch 的大小。
validation_steps:該參數和 steps_per_epoch 具有相同的內涵,只是該參數用于驗證集。
def train_model(model): model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # Creating Keras callbacks tensorboard_callback = keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1) model_checkpoint_callback = keras.callbacks.ModelCheckpoint( 'training_checkpoints/weights.{epoch:02d}-{val_loss:.2f}.hdf5', period=5) os.makedirs('training_checkpoints/', exist_ok=True) early_stopping_checkpoint = keras.callbacks.EarlyStopping(patience=5) history = model.fit(train.repeat(), epochs=epochs, steps_per_epoch=steps_per_epoch, validation_data=validation.repeat(), validation_steps=validation_steps, callbacks=[tensorboard_callback, model_checkpoint_callback, early_stopping_checkpoint]) return history
2.2 可視化訓練過程中的評估指標變化
如下圖所示,我們將訓練集和驗證集上的評估指標進行了可視化,該指標為 train_model() 或者 manually_train_model() 的返回值。在這里,我們使用 Matplotlib 繪制曲線圖:
訓練集和驗證集的評估指標隨著訓練epoch的變化
這些可視化圖能讓我們更加深入了解模型的訓練程度。在模型訓練過程中,確保訓練集和驗證集的精度在逐漸增加,而損失逐漸減少,這是非常重要的。
如果訓練精度高但驗證精度低,那么模型很可能出現了過擬合。這時我們需要對數據進行增廣,或者直接從網上下載更多的圖像,從而增加訓練集。此外,還可以采用一些防止過擬合的技術,例如 Dropout 或者 BatchNormalisation 。
如果訓練精度和驗證精度都較高,但是驗證精度比訓練精度略高,那么驗證集很可能包含較多易于分類的圖像。有時我們使用 Dropout 和 BatchNorm 等技術來防止過擬合,但是這些操作會為訓練過程添加一些隨機性,使得訓練更加困難,因此模型在驗證集上表現會更好些。稍微拓展一點講,由于訓練集的評估指標是對一個 epoch 的平均估計,而驗證集的評估指標卻是在這個 epoch 結束后,再對驗證集進行評估的,因此驗證集所用的模型可以說要比訓練集的模型訓練的更久一些。
TensorFlow2.0 可以在 Jupyter notebook 中使用功能齊全的 TensorBoard 。在模型開始訓練之前,先啟動 TensorBoard ,這樣我們就可以在訓練過程中動態觀察這些評估指標的變化。如下代碼所示(注意:需要提前創建 logs/ 文件夾):
%load_ext tensorboard.notebook%tensorboard --logdir logs/
Jupyer notebook 中的TensorBoard 視圖
3. 使用預訓練的模型
在上一節中,我們訓練了一個簡單的 CNN 模型,它給出了大約 70% 的準確率。通過使用更大、更復雜的模型,獲得更高的準確率,預訓練模型是一個很好的選擇。預訓練模型通常已經在大型的數據集上進行過訓練,通常用于完成大型的圖像分類任務。直接使用預訓練模型來完成我們的分類任務,我們也可以運用遷移學習的方法,只使用預訓練模型的一部分,重新構建屬于自己的模型。
簡單來講,遷移學習可以理解為:一個在足夠大的數據集上經過訓練的模型,能夠有效地作為視覺感知的通用模型,通過使用該模型的特征映射,我們就可以構建一個魯棒性很強的模型,而不需要很多的數據去訓練。
3.1 下載預訓練模型
本次將要用到的模型是由谷歌開發的 InceptionV3 模型,該模型已經在 ImageNet 數據集上進行過預訓練,該數據集含有 1.4M 張圖像和相應的 1000 個類別。InceptionV3 已經學習了我們常見的 1000 種物體的基本特征,因此,該模型具有強大的特征提取能力。
模型下載時,需要指定參數 include_top=False,該參數使得下載的模型不包含最頂層的分類層,因為我們只想使用該模型進行特征提取,而不是直接使用該模型進行分類。預訓練模型的分類模塊通常受原始的分類任務限制,如果想將預訓練模型用在新的分類任務上,我們需要自己構建模型的分類模塊,而且需要將該模塊在新的數據集上進行訓練,這樣才能使模型適應新的分類任務。
from tensorflow import keras# Create the base model from the pre-trained model MobileNet V2base_model = keras.applications.InceptionV3(input_shape=IMG_SHAPE,# We cannot use the top classification layer of the pre-trained model as it contains 1000 classes.# It also restricts our input dimensions to that which this model is trained on (default: 299x299) include_top=False, weights='imagenet')
我們將預訓練模型當做一個特征提取器,輸入(128,128,3)的圖像,得到(2,2,2048)的輸出特征。特征提取器可以理解為一個特征映射過程,最終的輸出特征是輸入的多維表示,在新的特征空間中,更加利于圖像的分類。
3.2 添加頂層的分類層
由于指定了參數 include_top=False,下載的 InceptionV3 模型不包含最頂層的分類層,因此我們需要添加一個新的分類層,而且它是為 tf_flowers 所專門定制的。通過 Keras 的序列模型 API,將新的分類層堆疊在下載的預訓練模型之上,代碼如下:
def build_model(): # Using Sequential API to stack up the layers model = keras.Sequential([ base_model, keras.layers.GlobalAveragePooling2D(), keras.layers.Dense(metadata.features['label'].num_classes, activation='softmax') ]) # Compile the model to configure training parameters model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) return modelinception_model = build_model()
以上代碼理解如下:
對于每張圖片,使用 keras.layers.GlobalAveragePooling2D() 層對提取的特征 (2x2x2048) 進行平均池化,從而將該特征轉化為長度為 2048 的向量。
在平均池化層之上,添加一個全連接層 keras.layers.Dense(),將長度為 2048 的向量轉化為長度為 5 的向量。
值得注意的是,在模型的編譯和訓練過程中,我們使用 base_model.trainable = False 將卷積模塊進行了凍結,該操作可以防止在訓練期間更新卷積模塊的權重,接下來就可以在 tf_flowers 數據集上進行模型訓練了。
3.3 訓練頂層的分類層
訓練的步驟和上文中 CNN 的訓練步驟相同,如下圖所示,我們繪制了訓練集和驗證集的判據指標隨訓練過程變化的曲線圖:
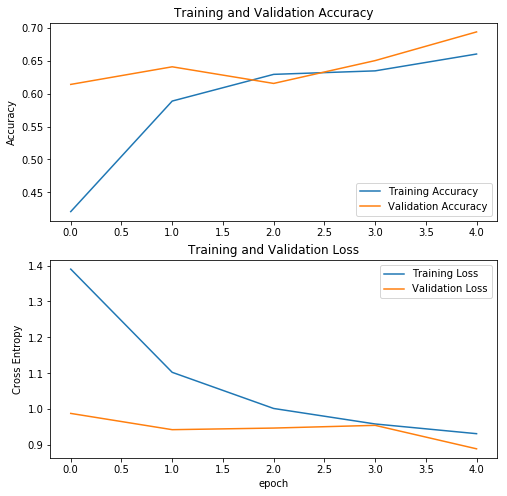
開始訓練預訓練模型后,訓練集和驗證集的評估指標隨著訓練epoch的變化
從圖中可以看到,驗證集的精度高略高于訓練集的精度。這是一個好兆頭,說明該模型的泛化能力較好,使用測試集來評估模型可以進一步驗證模型的泛化能力。如果想讓模型取得更好的效果,對模型進行微調。
3.4 對預訓練網絡進行微調
在上面的步驟中,我們僅在 InceptionV3 模型的基礎上簡單訓練了幾層網絡,而且在訓練期間并沒有更新其卷積模塊的網絡權重。為了進一步提高模型的性能,對卷積模塊的頂層進行微調。在此過程中,卷積模塊的頂層和我們自定義的分類層聯系了起來,它們都將為 tf_flowers 數據集提供定制化的服務。具體的內容可以參見 TensorFlow 的官網解釋。
鏈接:
https://www.tensorflow.org/alpha/tutorials/images/transfer_learning#fine_tuning
下面的代碼將 InceptionV3 的卷積模塊頂層進行了解凍,使得它的權重可以跟隨訓練過程進行改變。由于模型已經發生了改變,不再是上一步的模型了,因此在訓練新的模型之前,我們需要對模型重新編譯一遍。
# Un-freeze the top layers of the modelbase_model.trainable = True# Let's take a look to see how many layers are in the base modelprint("Number of layers in the base model: ", len(base_model.layers))# Fine tune from this layer onwardsfine_tune_at = 249# Freeze all the layers before the `fine_tune_at` layerfor layer in base_model.layers[:fine_tune_at]: layer.trainable = False# Compile the model using a much lower learning rate.inception_model.compile(optimizer = tf.keras.optimizers.RMSprop(lr=0.0001), loss='sparse_categorical_crossentropy', metrics=['accuracy'])history_fine = inception_model.fit(train.repeat(), steps_per_epoch = steps_per_epoch, epochs = finetune_epochs, initial_epoch = initial_epoch, validation_data = validation.repeat(), validation_steps = validation_steps)
微調的目的是使得模型提取的特征更加適應新的數據集,因此,微調后的模型可以讓準確度提高好幾個百分點。但是如果我們的訓練數據集非常小,并且和 InceptionV3 原始的預訓練集非常相似,那么微調可能會導致模型過擬合。如下圖所示,在微調之后,我們再次繪制了訓練集和驗證集的評估指標的變化。
注意:本節中的微調操作是針對預訓練模型中的少量頂層卷積層進行的,所需要調節的參數量較少。如果我們將預訓練模型中所有的卷積層都解凍了,直接將該模型和自定義的分類層聯合,通過訓練算法對所有圖層進行訓練,那么梯度更新的量級是非常巨大的,而且預訓練模型將會忘記它曾經學會的東西,那么預訓練就沒有太大的意義了。
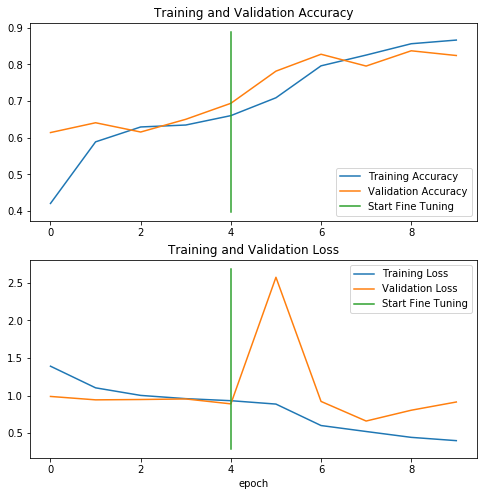
微調模型后,訓練集和驗證集的評估指標隨著訓練epoch的變化
從圖中可以看到,訓練集和驗證集的精度都有所提升。我們觀察到,在從微調開始的第一個 epoch 結束后,驗證集的誤差開始上升,但它最終還是隨著訓練過程而下降了。這可能是因為權重更新得過快,從而導致了震蕩。因此,相比于上一步中的模型,微調更加適合較低的學習率。
4. 使用 TensorFlow Serving 為模型發布服務
TensorFlow Serving 能夠將模型發布,從而使得我們能夠便捷地調用該模型,完成特定環境下的任務。TensorFlow Serving 將提供一個 URL 端點,我們只需要向該端點發送 POST 請求,就可以得到一個JSON 響應,該響應包含了模型的預測結果。可以看到,我們根本就不用擔心硬件配置的問題,一個簡單的 POST 請求就可以解決復雜的分類問題。
4.1 安裝 TensorFlow Serving
1、添加 TensorFlow Serving的源(一次性設置)
$ echo "deb [arch=amd64] http://storage.googleapis.com/tensorflow-serving-apt stable tensorflow-model-server tensorflow-model-server-universal" | sudo tee /etc/apt/sources.list.d/tensorflow-serving.list && $ curl https://storage.googleapis.com/tensorflow-serving-apt/tensorflow-serving.release.pub.gpg | sudo apt-key add -
2、安裝并更新 TensorFlow ModelServer
$ apt-get update && apt-get install tensorflow-model-server
一旦安裝完成,就可以使用如下命令開啟 TensorFlow Serving 服務。
$tensorflow_model_server
4.2 將 Keras 模型導出為 SavedModel 格式
為了將訓練好的模型加載到 TensorFlow Serving 服務器中,首先我們需要將模型保存為 SavedModel 格式。TensorFlow 提供了 SavedModel 格式的導出方法,該方法簡單易用,很快地導出 SavedModel 格式。
下面的代碼會在指定的目錄中創建一個 protobuf 文件,通過該文件,查詢模型的版本號。在實際的使用中,請求服務的版本號,TensorFlow Serving 將會為我們選擇相應版本的模型進行服務。每個版本的模型都會導出到相應的子目錄下。
from tensorflow import keras# '/1' specifies the version of a model, or "servable" we want to exportpath_to_saved_model = 'SavedModel/inceptionv3_128_tf_flowers/1'# Saving the keras model in SavedModel formatkeras.experimental.export_saved_model(inception_model, path_to_saved_model)# Load the saved keras model backrestored_saved_model = keras.experimental.load_from_saved_model(path_to_saved_model)
4.3 啟動 TensorFlow Serving 服務器
在本地啟動 TensorFlow Serving 服務器,可以使用如下代碼:
$ tensorflow_model_server --model_base_path=/home/ubuntu/Desktop/Medium/TF2.0/SavedModel/inceptionv3_128_tf_flowers/ --rest_api_port=9000 --model_name=FlowerClassifier
--model_base_path:該路徑必須指定為絕對路徑,否則就會報如下的錯誤:
Failed to start server. Error: Invalid argument: Expected model ImageClassifier to have an absolute path or URI; got base_path()=./inceptionv3_128_tf_flowers
--rest_api_port:Tensorflow Serving 將會在 8500 端口上啟動一個 gRPC ModelServer 服務,而 REST API 會在 9000 端口開啟。
--model_name:用于指定 Tensorflow Serving 服務器的名字,當我們發送 POST 請求的時候,將會用到服務器的名字。服務器的名字可以按照我們的喜好來指定。
4.4 向TensorFlow服務器發送 REST請求
TensorFlow ModelServer 支持 RESTful API。我們需要將預測請求作為一個 POST,發送到服務器的 REST 端點。在發送 POST 請求之前,先加載示例圖像,并對它做一些預處理。
TensorFlow Serving服務器的期望輸入為(1,128,128,3)的圖像,其中,"1" 代表 batch 的大小。通過使用 Keras 庫中的圖像預處理工具,能夠加載圖像并將其轉化為指定的大小。
服務器 REST 端點的 URL 遵循以下格式:
http://host:port/v1/models/${MODEL_NAME}[/versions/${MODEL_VERSION}]:predict
其中,/versions/${MODEL_VERSION} 是一個可選項,用于選擇服務的版本號。下面的代碼先加載了輸入圖像,并對其進行了預處理,然后使用上面的 REST 端點發送 POST 請求:
import json, requestsfrom tensorflow.keras.preprocessing.image import img_to_array, load_imgimport numpy as npimage_path = 'sunflower.jpg'# Loading and pre-processing our input imageimg = image.img_to_array(image.load_img(image_path, target_size=(128, 128))) / 255.img = np.expand_dims(img, axis=0)payload = {"instances": img.tolist()}# sending post request to TensorFlow Serving serverjson_response = requests.post('http://localhost:9000/v1/models/FlowerClassifier:predict', json=payload)pred = json.loads(json_response.content.decode('utf-8'))# Decoding the response using decode_predictions() helper function# You can pass "k=5" to get top 5 predicitonsget_top_k_predictions(pred, k=3)
代碼的輸出如下:
Top 3 predictions:[('sunflowers', 0.978735), ('tulips', 0.0145516), ('roses', 0.00366251)]
5. 總結
最后對本文的要點簡單總結如下:
利用 TensorFlow Datasets ,我們只需要幾行代碼,就可以下載公開可用的數據集。不僅如此, TensorFlow Datasets 還能有效構建數據集,對模型訓練有很大的幫助。
tf.keras 不僅能夠讓我們從頭開始構建一個 CNN 模型,它還能幫助我們利用預訓練的模型,在短時間內訓練一個有效的花卉分類模型,并且獲得更高的準確率。
使用 TensorFlow Serving 服務器能夠將訓練好的模型發布。我們只需要調用 URL 端點,就可以輕松將訓練好的模型集成到網站或者其他應用程序中。
-
數據集
+關注
關注
4文章
1225瀏覽量
25618 -
cnn
+關注
關注
3文章
354瀏覽量
22811 -
tensorflow
+關注
關注
13文章
330瀏覽量
61286
原文標題:掌聲送給TensorFlow 2.0!用Keras搭建一個CNN | 入門教程
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
高階API構建模型和數據集使用
如何使用pycoral、tensorflow-lite和edgetpu構建核心最小圖像?
使用MobilenetV2、ARM NN和TensorFlow Lite Delegate預建二進制文件進行圖像分類教程
為WiMAX構建端到端的網絡架構
基于WiMAX接入技術的端到端網絡架構
TensorFlow2.0終于問世,Alpha版可以搶先體驗

tensorflow能做什么_tensorflow2.0和1.0區別

基于生成式對抗網絡的端到端圖像去霧模型

一種對紅細胞和白細胞圖像分類任務的主動學習端到端工作流程

HDR Vivid端到端產業鏈加速構建
華為IPv6+端到端解決方案通過信通院IPv6+ 2.0 Advanced測試評估






 工商網監
工商網監

評論