 一種敏捷數據中臺的建設思路,以供參考和探討
一種敏捷數據中臺的建設思路,以供參考和探討
導讀:宜信于2017年推出了一系列大數據開源工具,包括DBus、Wormhole、Moonbox、Davinci等,這些工具是如何在宜信內部應用的?它們和宜信數據中臺是怎樣的關系?又是如何驅動各種日常數據業務場景的?
本次分享對這些問題進行了回答,同時重點分享了宜信敏捷數據中臺的設計、架構以及應用場景,提出一種敏捷數據中臺的建設思路,以供參考和探討。以下是本次分享的實錄。
分享實錄
一、導語
目前“中臺”的概念很火,包括數據中臺、AI中臺、業務中臺、技術中臺等。宜信技術學院第一期技術沙龍,井玉欣博士分享了宜信的AI中臺,本期技術沙龍,由我來為大家分享《宜信敏捷數據中臺建設實踐》。
本次分享分為三個部分:
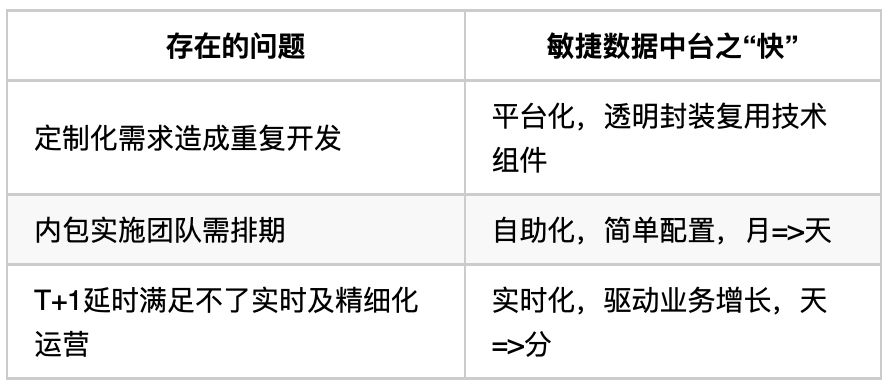
宜信敏捷數據中臺的頂層設計。數據中臺是一個公司級的平臺系統,所以不能只從技術層面去設計,還要考慮包括流程、標準化等在內的頂層設計。
從中間件工具到平臺介紹宜信是如何設計建設敏捷數據中臺的。
結合典型案例介紹宜信敏捷數據中臺支持哪些數據方面的應用和實踐。
二、宜信數據中臺頂層設計
2.1 特點和需求
關于數據中臺的建設,目前并沒有一個標準的解決方案,也沒有一個數據中臺能適用于所有的公司,每個公司都應該結合自己的業務規模及數據需求現狀來研發適合自己公司的數據中臺。
在介紹宜信敏捷數據中臺的頂層設計之前,我們先來了解其背景:
業務板塊和業務條線眾多。宜信的業務大體可分為四大板塊:普惠金融板塊、財富管理板塊、資產管理板塊、金融科技板塊,擁有近百條業務線和產品線。
技術選型眾多。不同業務方有不同的數據需求,技術選型時依據這些客觀需求及主觀偏好,會選擇不同的數據組件,包括 :MySQL、Oracle、HBase、KUDU、Cassandra、Elasticsearch、MongoDB、Hive、Spark、Presto、Impala、Clickhouse等。
數據需求多樣。業務線多樣,導致數據需求多樣,包括:報表、可視化、服務、推送、遷移、同步、數據應用等。
數據需求多變。為順應互聯網的快速變化,業務方的數據需求也是多變的,經常有周級產出數據需求和數據應用。
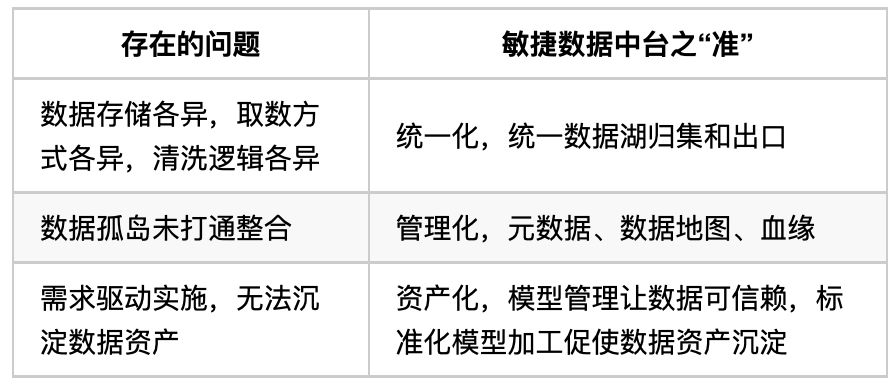
數據管理考慮。要求數據元信息可查,數據定義和流程標準化,數據管理可控等。
數據安全考慮。宜信作為一家同時擁有互聯網屬性和金融屬性的公司,對數據安全和權限的要求很高,我們在數據安全方面做了很多工作,包括:多級數據安全策略、數據鏈路可追溯、敏感數據不可泄露等。
數據權限考慮。在數據權限方面的工作包括:表級、列級、行級數據權限,組織架構、角色、權限策略自動化。
數據成本考慮。包括集群成本、運維成本、人力成本、時間成本、風險成本等。
2.2 定位
關于數據中臺的定位,每個公司都不太一樣。有的公司業務比較專注,只有一條業務線,那它在建設數據中臺的時候,可能需要一個垂直的平臺,直達前線,更好地支持前線的運作。
前文提到宜信業務線很多,且在眾多業務中沒有一個主體業務,這就相當于所有業務線都是主體。基于這樣的背景,我們需要一個平臺化的數據中臺,來支撐所有業務線的需求和運作。
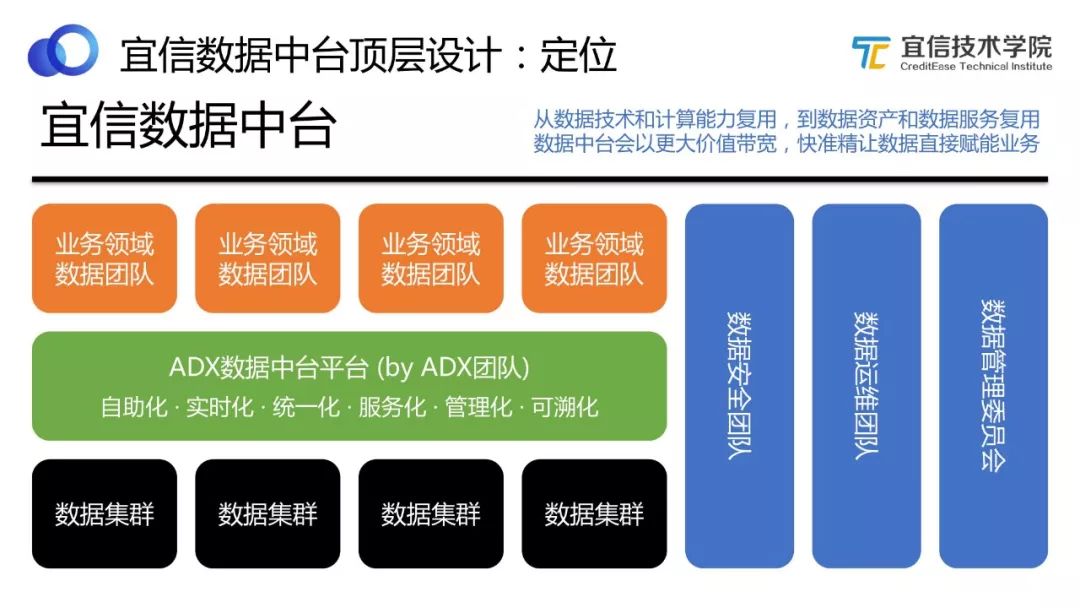
圖1 定位
如上圖所示,綠色的部分是宜信敏捷數據中臺,我們稱之為“ADX數據中臺平臺”,“A”即“Agile(敏捷)”,之所以稱為“平臺”,是因為我們希望將其打造成一個服務于全業務線的平臺系統,助力業務發展。
敏捷數據中臺處于中間位置,最底下是各種數據集群,最上端是各個業務領域數據團隊。數據中臺通過整合處理數據集群的數據,為業務領域數據團隊提供自助化、實時化、統一化、服務化、管理化、可溯化的數據服務。
右邊三個藍色的板塊分別是數據管理委員會、數據運維團隊和數據安全團隊。前文提到宜信對數據安全的要求非常高,所以設置了專門的數據安全團隊來規劃公司數據安全的流程和策略;數據管理委員會負責數據的標準化、流程化,補齊技術型驅動的數據中臺的推動效率,保證有效沉淀和呈現數據資產。
我們對宜信敏捷數據中臺的定位是:從數據技術和計算能力復用,到數據資產和數據服務復用,敏捷數據中臺會以更大價值帶寬,快、準、精讓數據直接賦能業務。
2.3 價值
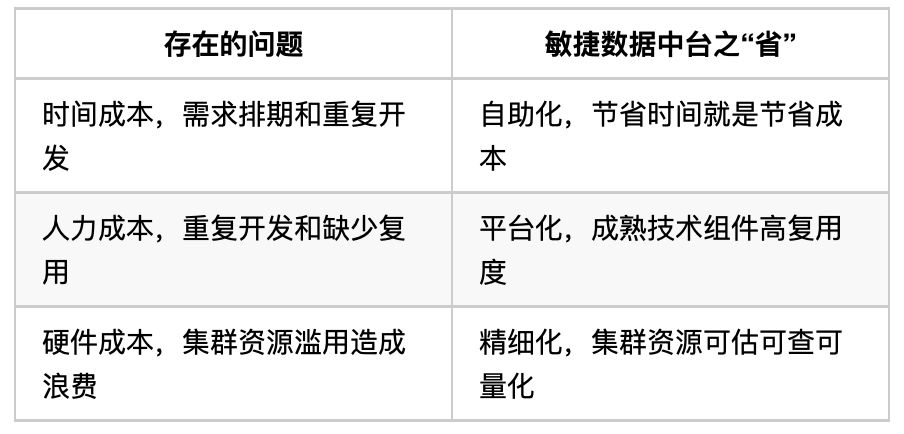
宜信敏捷數據中臺的價值集中表現為三個方面:快、準、省。
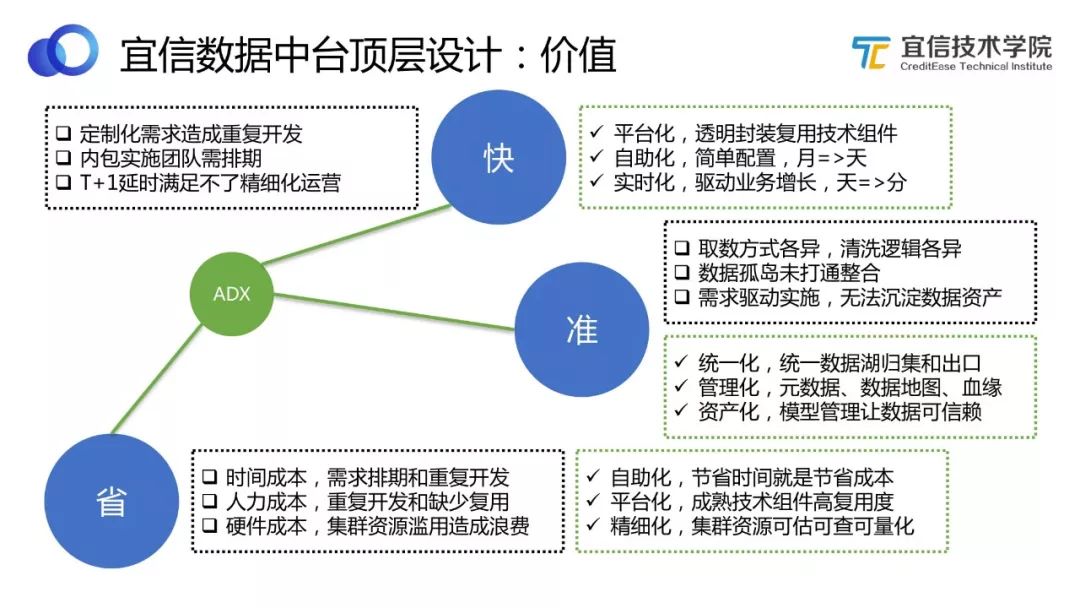
圖2 價值
2.4 模塊架構維度
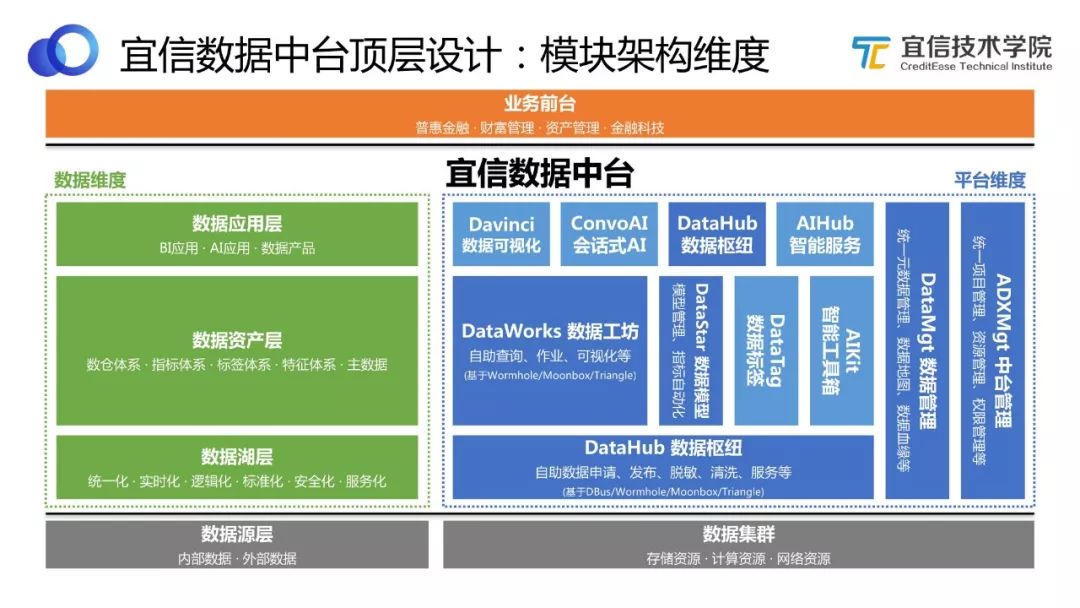
圖3 模塊架構維度
如圖所示,宜信敏捷數據中臺的建設也是基于“小前臺,大中臺”的共識。整個中間部分都屬于敏捷數據中臺包含的內容,左邊綠色部分是基于數據維度來看整個中臺,右邊藍色部分則是基于平臺維度來看中臺。
數據維度。各種內部數據、外部數據先歸集到數據源層,再以統一化、實時化、標準化、安全化等方式存儲起來形成數據湖層,數據湖對這些原始數據進行處理和體系化歸類,轉化為數據資產;數據資產層包括數倉體系、指標體系、標簽體系、特征體系、主數據等;最后將沉淀的這些可復用的數據資產提供給數據應用層,供BI、AI、數據產品應用。
平臺維度。每個藍色的方框都代表一個技術模塊,整個宜信敏捷數據中臺就是由這些技術模塊組合而成。其中DataHub數據樞紐,可以幫助用戶完成自助數據申請、發布、脫敏、清洗和服務等;DataWorks數據工坊,可以對數據進行自助查詢、作業、可視化等處理;還有DataStar數據模型、DataTag數據標簽、DataMgt 數據管理、ADXMgt 中臺管理等。
值得一提的是,這些模塊都不是從0開發的,而是基于我們已有的開源工具。首先,基于成熟的中間件工具來進行開發,可以節約開發的時間和成本;其次,開源工具成為引擎,可以共同合力支撐更大的一站式平臺。
2.5 數據能力維度
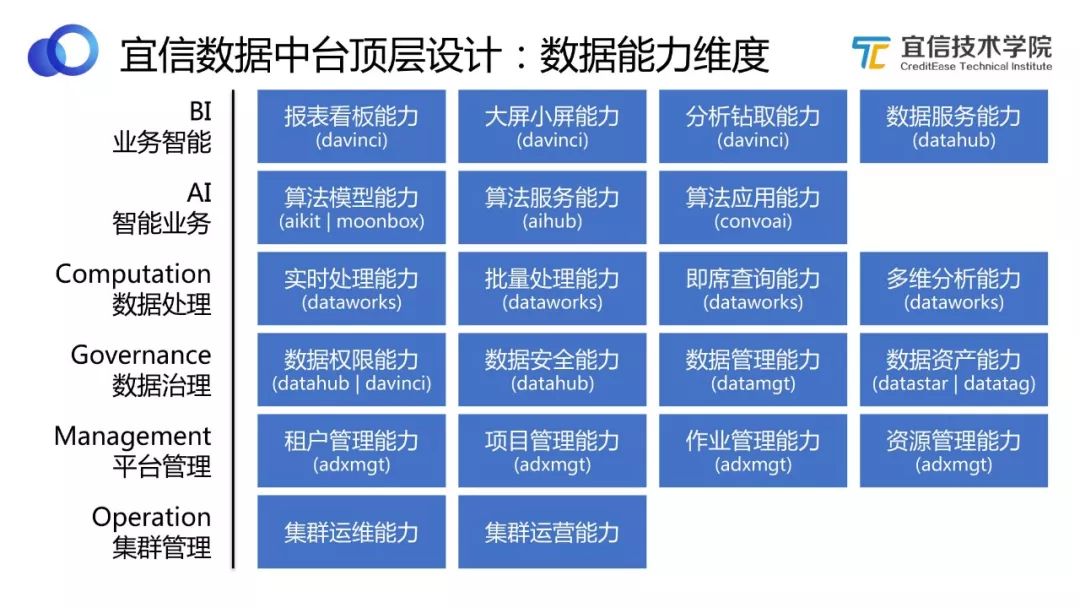
圖4 數據能力維度
將上述架構模塊重新按照能力維度劃分,可以分成若干層,每一層都包含若干能力。如圖所示,可以清晰地看到建設數據中臺需要具備哪些數據能力,這些能力都對應哪些功能模塊,分別能解決什么問題。此處不再展開贅述。
三、從中間件工具到平臺
3.1 ABD總覽
圖5 ABD總覽
中間件工具指DBus、Wormhole、Moonbox、Davinci四大開源平臺,它們從敏捷大數據(ABD,Agile BigData)理念中抽象而出,組成ABD平臺棧,敏捷數據中臺則被我們稱為ADX(Agile Data X Platform)。也就是說我們經歷了從ABD到ADX的過程。
一開始,基于對業務需求共性的抽象和總結,我們孵化出若干個通用的中間件,去解決各種各樣的問題。當出現更為復雜的需求,我們嘗試將這些通用的中間件進行組合運用。實踐中,我們發現經常會使用到某些特定的組合,同時,從用戶角度來看,他們更希望能實現自助化,直接拿過來就能用,而不是每次都要自己去選擇和組合。基于這兩點,我們對這幾個開源工具進行了封裝。
3.1.1 ABD-DBus
DBus(數據總線平臺),是一個DBaaS(Data Bus as a Service)平臺解決方案。
DBus面向大數據項目開發和管理運維人員,致力于提供數據實時采集和分發解決方案。平臺采用高可用流式計算框架,提供海量數據實時傳輸,可靠多路消息訂閱分發,通過簡單靈活的配置,無侵入接入源端數據,對各個IT系統在業務流程中產生的數據進行匯集,并統一處理轉換成通過JSON描述的UMS格式,提供給不同下游客戶訂閱和消費。DBus可充當數倉平臺、大數據分析平臺、實時報表和實時營銷等業務的數據源。
開源地址:https://github.com/BriData
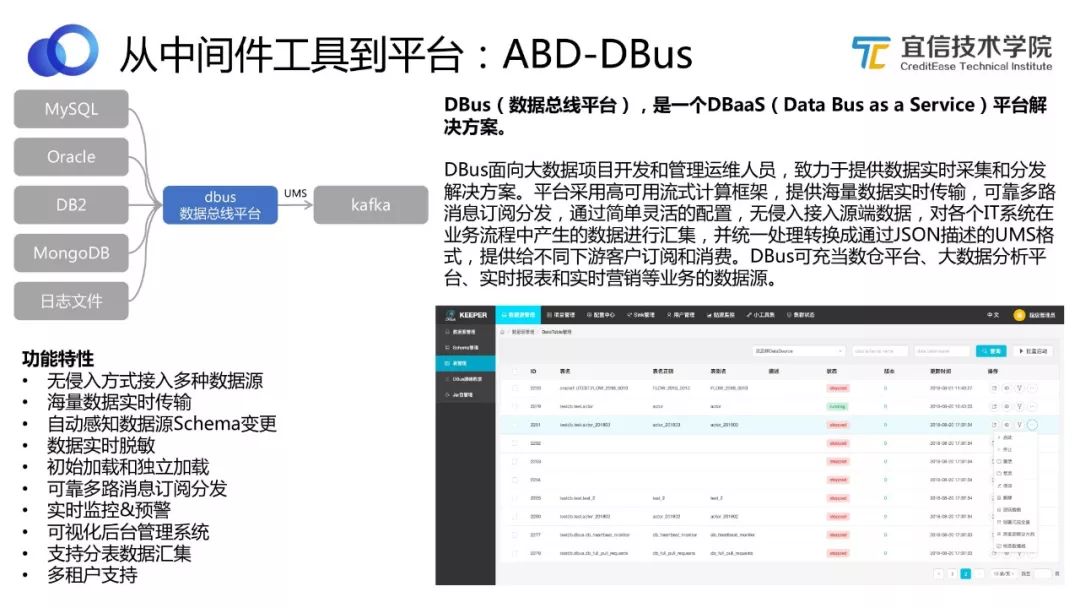
圖6 DBus功能及定位
如圖所示,DBus可以無侵入地對接各種數據庫的數據源,實時抽取增量數據,做統一清洗和處理,并以UMS的格式存儲到Kafka中。
DBus的功能還包括批量抽取、監控、分發、多租戶,以及配置清晰規則等,具體功能特性如圖所示。
上圖右下角展示的是DBus的一個截圖,用戶在DBus上可以通過一個可視化頁面,拉取增量數據,配置日志和清洗方式,完成實時數據抽取等工作。
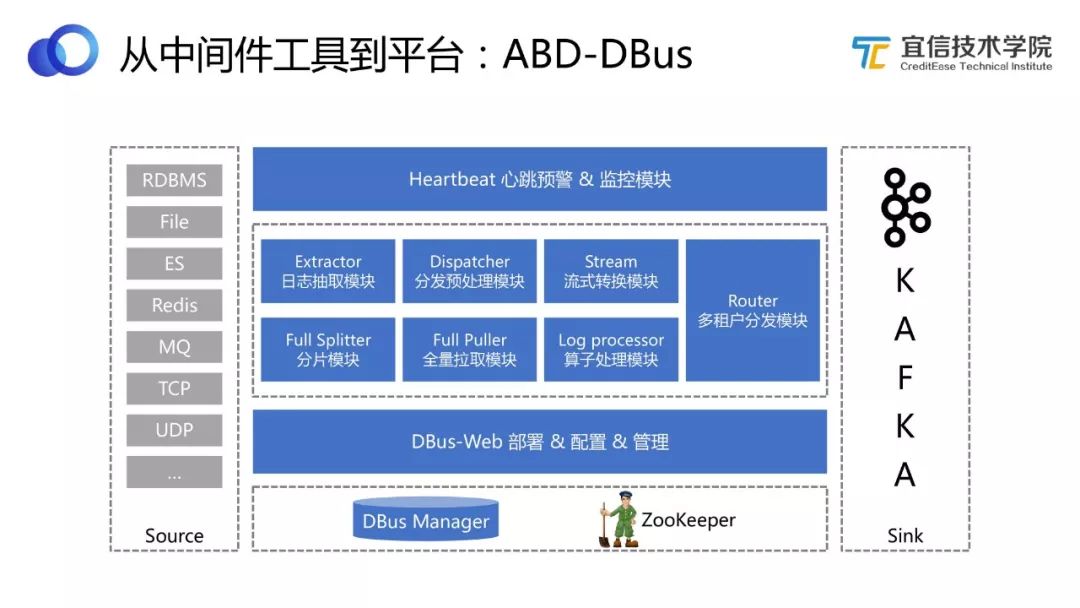
圖7 DBus架構
從如上架構圖可以看到DBus包括若干不同的處理模塊,支持不同的功能。(GitHub有具體介紹,此處不作展開。)
3.1.2 ABD-Wormhole
Wormhole(流式處理平臺),是一個SPaaS(Stream Processing as a Service)平臺解決方案。
Wormhole面向大數據項目開發和管理運維人員,致力于提供數據流式化處理解決方案。平臺專注于簡化和統一開發管理流程,提供可視化的操作界面,基于配置和SQL的業務開發方式,屏蔽底層技術實現細節,極大的降低了開發門檻,使得大數據流式處理項目的開發和管理變得更加輕量敏捷、可控可靠。
開源地址:?https://github.com/edp963/wormhole
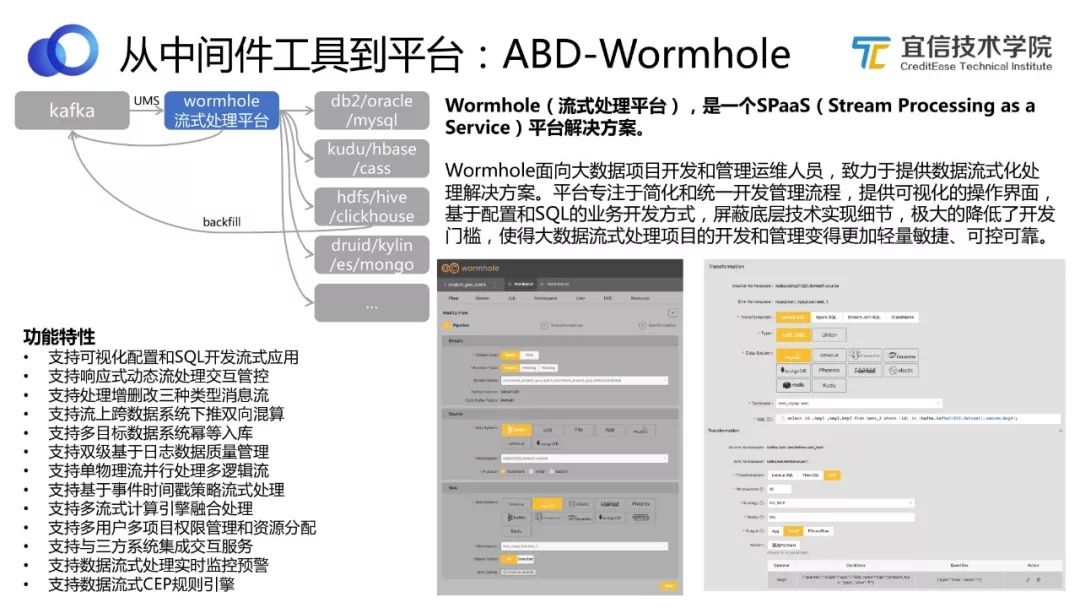
圖8 Wormhole功能及定位
DBus將實時數據以UMS的格式存儲到Kafka中,我們要使用這些實時的流式數據,就要用到Wormhole這個工具。
Wormhole支持配置流式化的處理邏輯,同時可以把處理完之后的數據寫到不同的數據存儲中。上圖中展示了很多Wormhole的功能特性,我們還在開發更多新的功能。
上圖右下角是Wormhole的一個工作截圖,Wormhole作為流式平臺,自己不重新開發流式處理引擎,它主要依賴Spark Streaming 和Flink Streaming 這兩種流式計算引擎。用戶可以選擇其中一個流式計算引擎,比如Spark,配置流式處理邏輯,確定Lookup庫的方式,并通過寫SQL來表達這個邏輯。如果涉及CEP,當然就是基于Flink。
由此可以看出,使用Wormhole的門檻就是配置加上SQL。這也符合我們一直秉承的理念,即用敏捷化的方式支持用戶自助玩轉大數據。
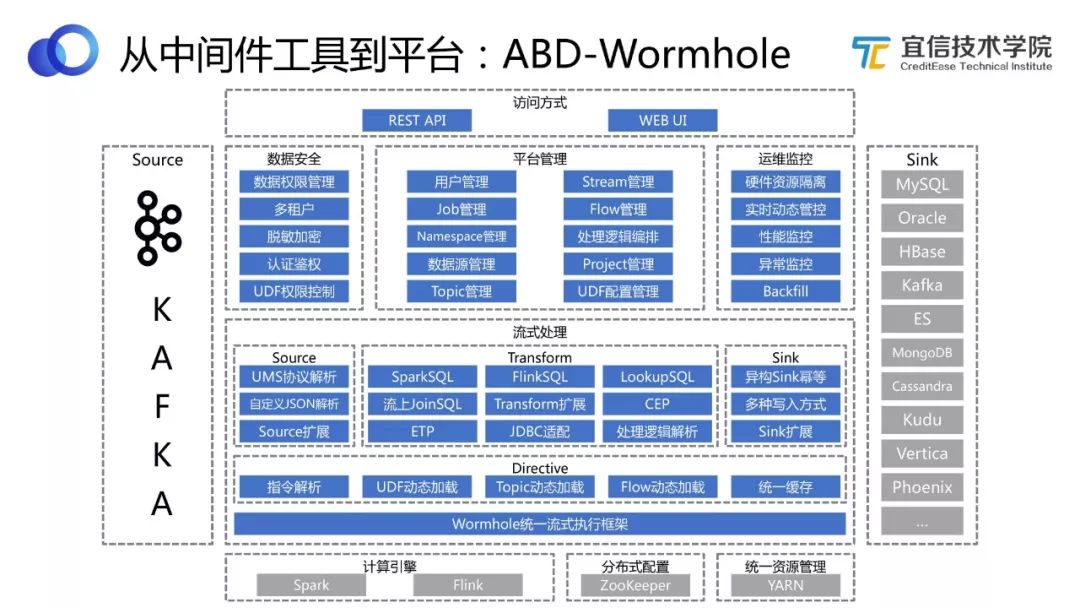
圖9 Wormhole架構
上圖展示的是Wormhole的架構圖,包含很多功能模塊。介紹其中的幾個功能:
Wormhole支持異構 Sink冪等,能幫助用戶解決數據一致性的問題。
用過 Spark Streaming的人都知道,發起一個 Spark Streaming可能只做一件事情。Wormhole在 Spark Streaming的物理計算管道中抽象出一層“邏輯的Flow”的概念,就是從什么地方到什么地方、中間做什么事,這是一個“邏輯的Flow”。做了這種解耦和抽象之后,Wormhole支持在一個物理的 Spark Streaming管道中同時跑多個不同業務邏輯的Flow。所以理論上講,比如有1000個不同的 Source表,經過1000個不同的流式處理,最后要得出1000個不同的結果表,可以只在Wormhole中發起一個Spark Streaming ,在里面跑1000個邏輯的Flow來實現。當然這樣做的話可能會導致每個Flow延遲加大,因為都擠在同一個管道里,但這里的設置是很靈活的,我可以讓某一個Flow獨占一個VIP的 Stream,如果有些Flow流量很小,或者延遲對其影響不那么大的話,可以讓它們共享一個Stream。靈活性是Wormhole一個很大的特點。
Wormhole有自己的一套指令和反饋體系,用戶不用重啟或停止流,就可以動態地在線更改邏輯,并且實時拿到作業和反饋結果等。
3.1.3 ABD-Moonbox
Moonbox(計算服務平臺),是一個DVtaaS(Data Virtualization as a Service)平臺解決方案。
Moonbox面向數據倉庫工程師/數據分析師/數據科學家等, 基于數據虛擬化設計思想,致力于提供批量計算服務解決方案。Moonbox負責屏蔽底層數據源的物理和使用細節,為用戶帶來虛擬數據庫般使用體驗,用戶只需通過統一SQL語言,即可透明實現跨異構數據系統混算和寫出。此外Moonbox還提供數據服務、數據管理、數據工具、數據開發等基礎支持,可支撐更加敏捷和靈活的數據應用架構和邏輯數倉實踐。
開源地址:?https://github.com/edp963/moonbox

圖10 Moonbox功能及定位
數據從DBus過來,經過Wormhole的流式處理,可能落到不同的數據存儲中,我們需要對這些數據進行混算,Moonbox支持多源異構系統無縫混算。上圖展示了Moonbox的功能特性。
平時所說的即席查詢并沒有真正做到“即席”,因為需要用戶先手工地把數據導到Hive再做計算,這是一個預置的工作。Moonbox不需要事先把數據導到一個地方去,做到了真正的即席查詢。數據可以散落到不同的存儲中,當用戶有需求時, 只需寫一個SQL,Moonbox可以自動拆分這個SQL,從而得知哪些表在哪里,然后規劃SQL的執行計劃,最終拿到結果。
Moonbox對外提供標準的REST、API、JDBC、ODBC等,因此也可以將之看成一個虛擬數據庫。
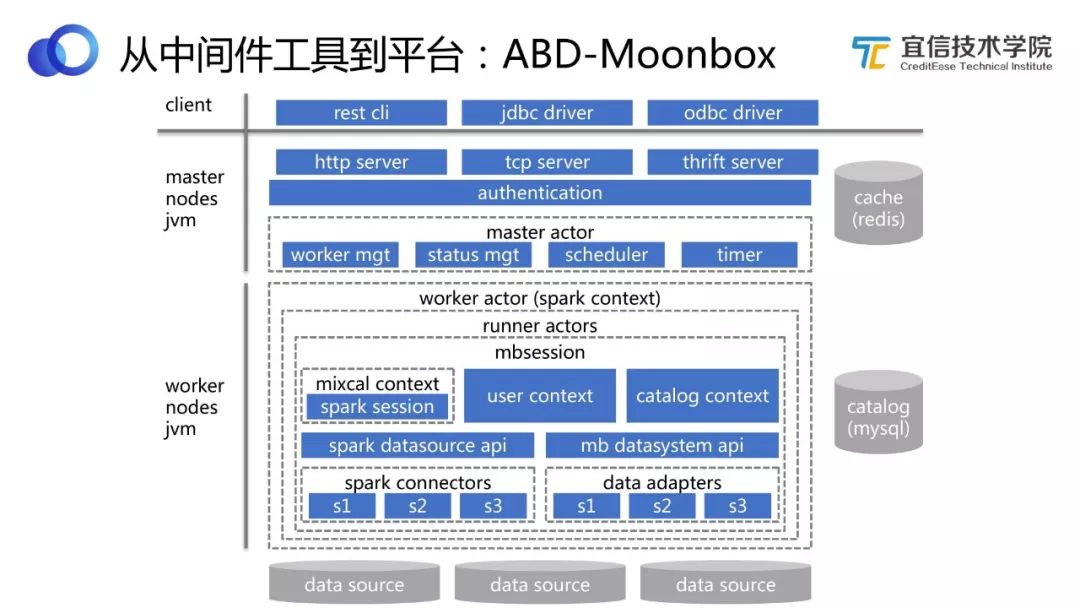
圖11 Moonbox架構
上圖展示的是Moonbox的架構圖。可以看到Moonbox的計算引擎部分也是基于Spark引擎做的,并沒有自研。Moonbox對Spark進行擴展和優化,增加了很多企業級的數據庫能力,比如用戶、租戶、權限、 類存儲過程等。
從上圖看,Moonbox整個服務端是一個分布式的架構,所以它也是高可用的。
3.1.4 ABD-Davinci
Davinci(可視應用平臺),是一個DVaaS(Data Visualization as a Service)平臺解決方案。
Davinci面向業務人員/數據工程師/數據分析師/數據科學家,致力于提供一站式數據可視化解決方案。既可作為公有云/私有云獨立部署使用,也可作為可視化插件集成到三方系統。用戶只需在可視化UI上簡單配置即可服務多種數據可視化應用,并支持高級交互/行業分析/模式探索/社交智能等可視化功能。
開源地址:https://github.com/edp963/davinci

圖12 Davinci功能及定位
Davinci是一個可視化工具,所具備的功能特性如圖所示。
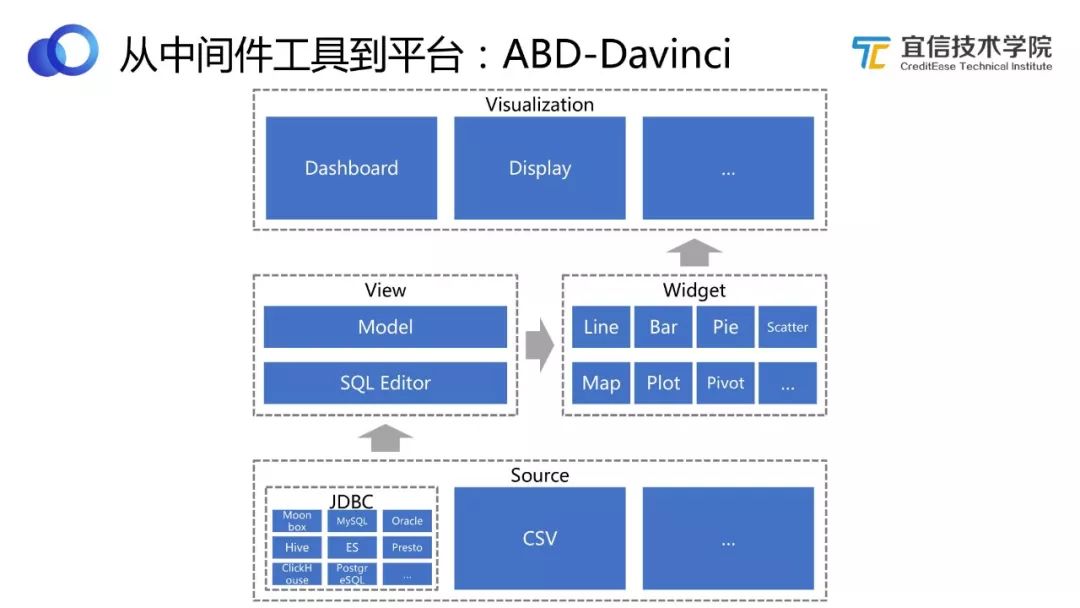
圖13 Davinci架構
從設計層面來看,Davinci有自己的完備和一致性的內在邏輯。包括Source、View、Widget,支持各種數據可視化應用。
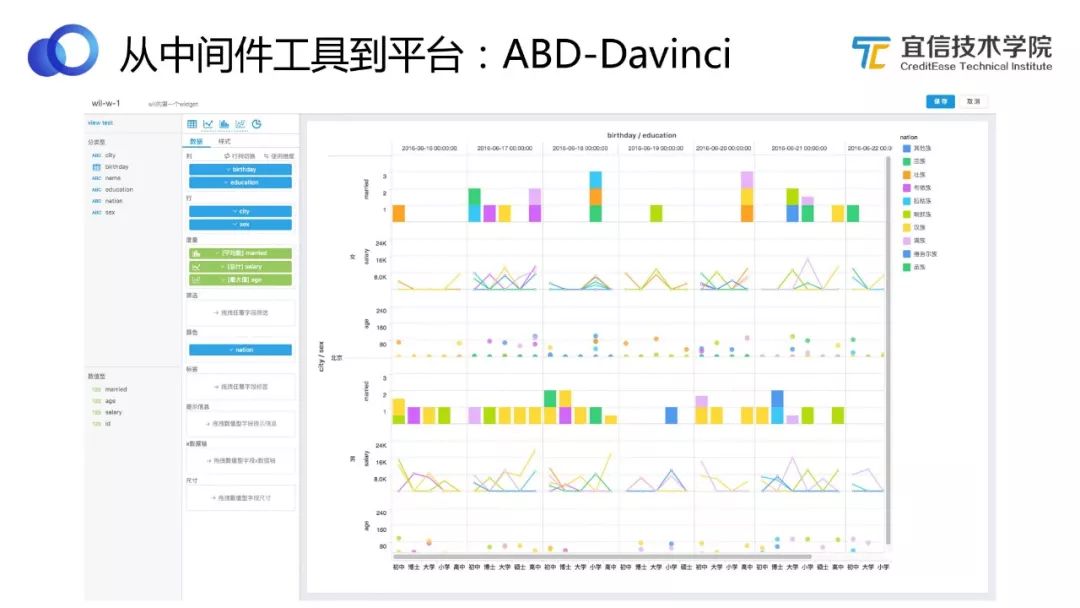
圖14 Davinci富客戶端應用
Davinci是一個富客戶端的應用,所以主要還是看它前端的使用體驗、豐富性和易用性等。Davinci支持圖表驅動和透視驅動兩種模式編輯Widget。上圖是一個透視驅動的效果樣例,可以看到橫縱坐標都是透視的,它們會將整個圖切成不同的單元格,每個單元格里可以選擇不同的圖。
3.2 ABD架構
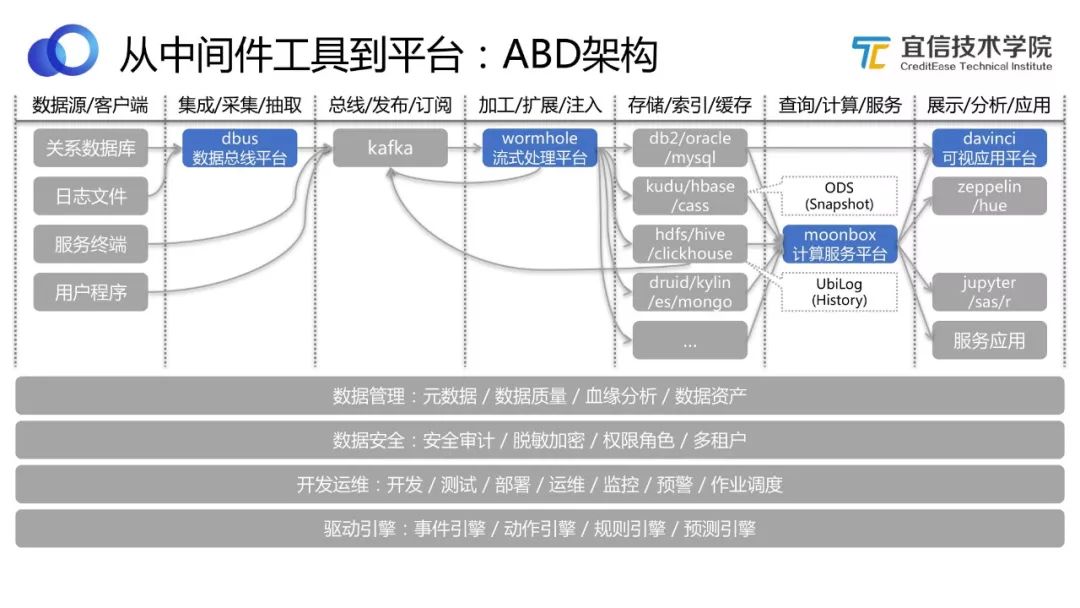
圖15 ABD架構
在ABD時代,我們通過DIY組合四個開源工具來支持各種各樣的數據應用需求。如上圖所示,將整個端到端的流程串起來,這個架構圖展示了我們“有收有放把整個鏈路打通”的理念。
收。比如采集、架構、流轉、注入、計算服務查詢等功能,需要收斂集合成一個平臺。
放。面對復雜的業務環境,數據源也是各種各樣的無法統一,很難有一個存儲或數據系統可以滿足所有的需求,使得大家不再需要選型。因此這一塊的實踐是開放的,大家可以自主選擇開源工具和組件來適配和兼容。
3.3 ADX總覽
發展到一定階段時,我們需要一個一站式的平臺,把基礎組件封裝起來,使得用戶可以在這個平臺上更簡單地完成數據相關的工作,于是進入了ADX數據中臺建設階段。
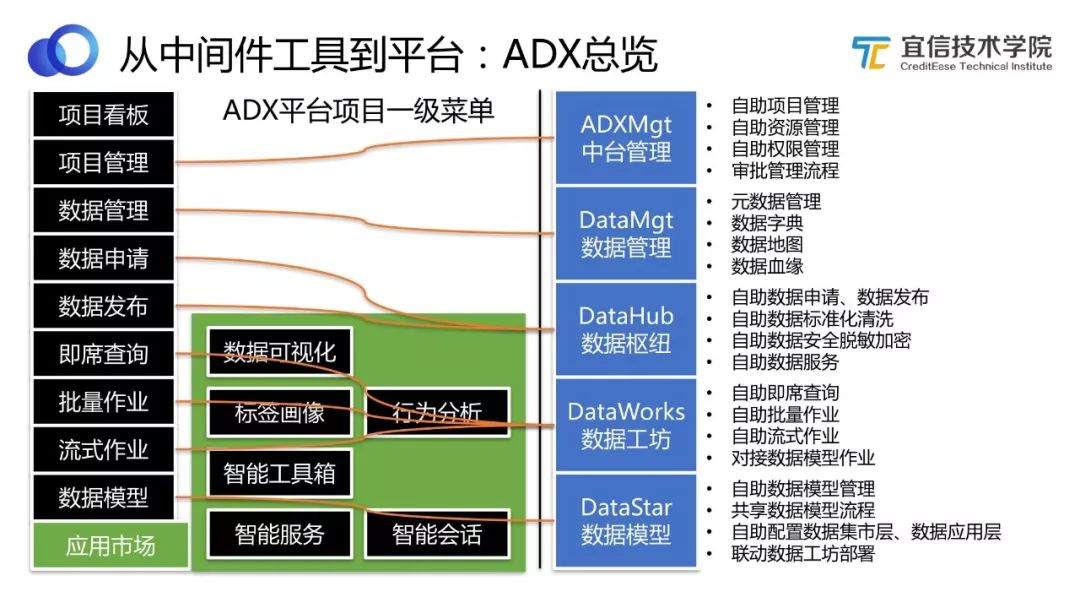
圖16 ADX 總覽
上圖是ADX 總覽,相當于一個一級功能菜單。用戶登錄到平臺,可以做以下事情:
項目看板:可以看到所在項目的看板,包括健康情況等各方面的統計情況。
項目管理:可以做項目相關的管理,包括資產管理、權限管理、審批管理等。
數據管理:可以做數據方面的管理,比如查看元數據,查看數據血緣等。
數據申請:項目配置好了,數據也了解了,可以做實際工作了。基于安全和權限考慮,并不是誰都可以去用放在里面的數據,因此首先要做數據申請。右邊藍色模塊是本次分享將重點介紹的ADX數據中臺的五大功能模塊。數據申請更多是由DataHub數據樞紐來實現的,它支持自助申請、發布、標準化、清洗、脫敏等。
即席查詢、批量作業、流式作業是基于DataWorks數據工坊實現的。
數據模型是基于DataStar這個模型管理平臺來實現的。
應用市場,包括數據可視化(數據加工完之后可以配置最終展現樣式為圖或儀表板等,這里可能用到Davinci);標簽畫像、行為分析等常見分析方法;智能工具箱(幫助數據科學家更好地做數據集分析、挖掘和算法模型的工作)以及智能服務、智能對話(比如智能聊天機器人)等。
3.3.1 ADX-DataHub數據樞紐
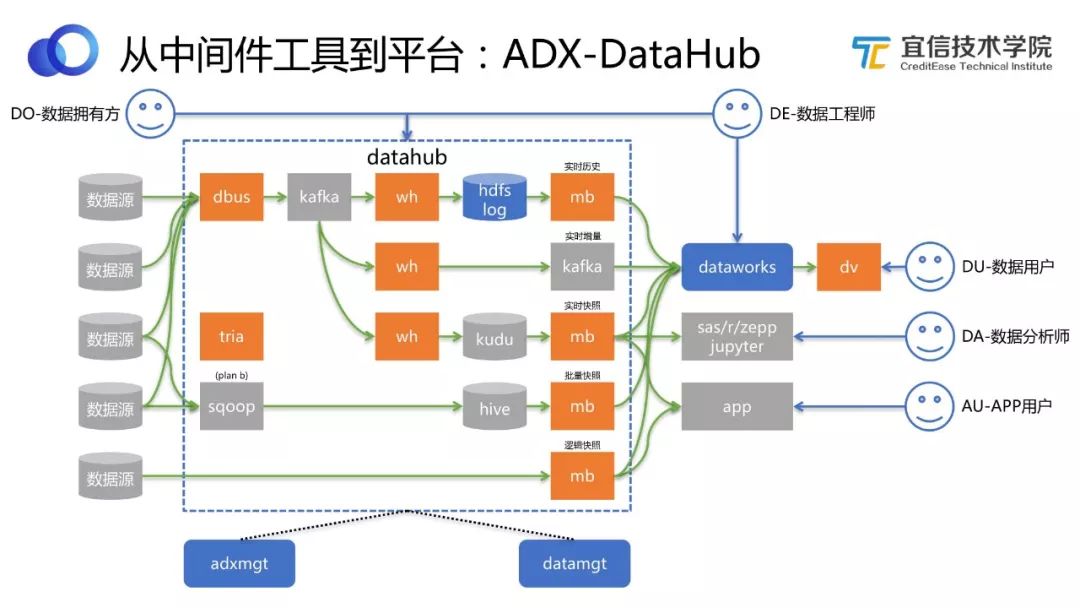
圖17 DataHub工作流程
上圖藍色虛線框顯示的是 DataHub的流程架構,橙色方塊是我們的開源工具,其中“tria”代表Triangle,是宜信另一個團隊研發的作業調度工具。 DataHub不是簡單地封裝了鏈路,而是使得用戶可以在一個更高的level上得到更好的服務。比如用戶需要某一歷史時刻精確到秒的快照,或者希望拿到一個實時增量數據去做流式處理,DataHub都可以提供。
它是怎么做到的呢?通過將開源工具引擎化,然后進行整合。舉個例子:不同數據源,通過DBus實時抽取出來,經過Wormhole流式處理后落到 HDFS Log數據湖中,我們把所有實時增量數據都存儲在這里面,這就意味著我們可以從中拿到所有的歷史變更數據,而且這些數據還是實時同步的。再通過Moonbox在上面定義一些邏輯,當用戶提出想要某一歷史時刻的快照或者增量數據,就可以即時計算并提供。如果想做實時報表,需要把數據實時快照維護到一個存儲里,這里我們選擇Kudu。
流式處理有很多好處,同時也有短板,比如運維成本較高、穩定性較差等。考慮到這些問題,我們在DataHub中設置了Sqoop作為Plan B。如果實時這條線晚上出現問題,可以自動切換到Plan B,通過傳統的Sqoop去支持第二天T+1的報表。等我們找到并解決問題之后,Plan B就會切換到暫停狀態。
假設用戶自己有數據源,放在Elasticsearch 或者Mongo里,也希望通過DataHub發布出去共享給其他人使用。我們不應該把Elasticsearch 數據或Mongo數據物理地拷貝到一個地方,因為首先這些數據是NoSQL的,數據量比較大;其次用戶可能希望別人通過模糊查詢的方式去使用Elasticsearch 數據,那可能繼續將數據放在Elasticsearch 里更好。這時我們做的是通過Moonbox進行一個邏輯的發布,但用戶不感知這個過程。
綜上可以看出,DataHub是在內部把幾個開源平臺常用的模式進行有機整合和封裝,對外提供一致性、便捷的數據獲取、發布等服務。其使用方也可以是各種不同的角色:
數據擁有方可以在這里做數據審批;
數據工程師可以申請數據,申請完后可以在這里對數據進行加工;
APP用戶可以查看Davinci報表;
數據分析師可以直接用自己的工具去接DataHub出來的數據,然后做數據分析;
數據用戶可能希望自己做一個數據產品,DataHub可以為他提供接口。
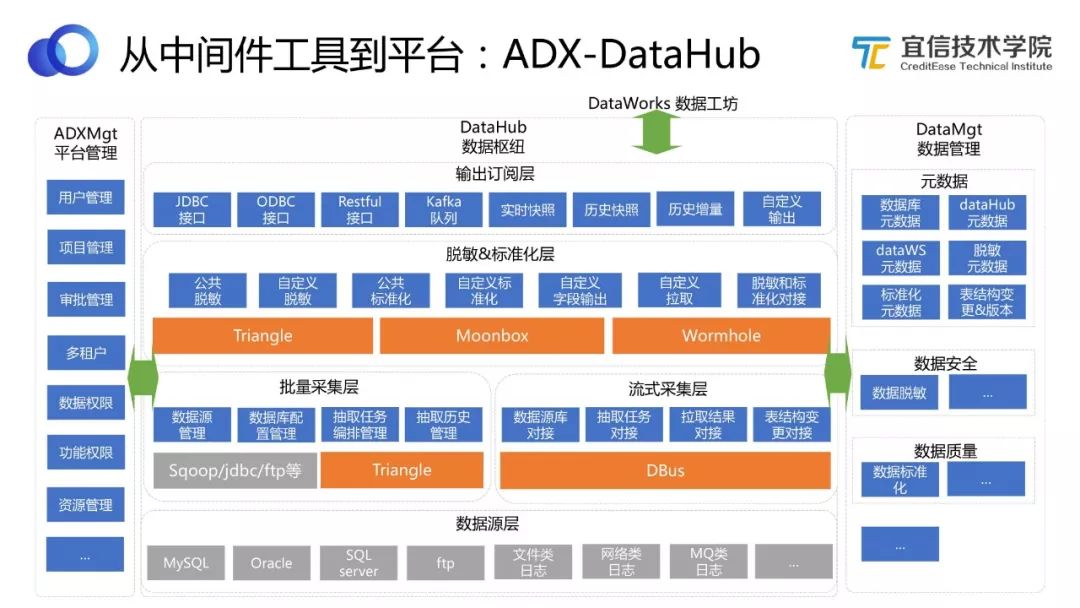
圖18 DataHub架構
如圖,將DataHub打開,來看其架構設計。從功能模塊角度來看,DataHub基于不同開源組件,實現不同功能。包括批量采集、流式采集、脫敏、標準化等,還可以基于不同的協議輸出訂閱。
DataHub與其他幾個組件之間的關系也是非常緊密的。它輸出的數據給DataWorks使用,同時它又依賴中臺管理、數據管理來滿足其需求。
3.3.2 ADX-DataLake實時數據湖
廣義的數據湖,就是把所有數據都放在一起,先以存儲和歸集為主,使用的時候再根據不同數據提供不同使用方式。
我們這里提到的是一個狹義的數據湖,只支持結構化數據源和自然語言文本這兩種類型的數據歸集,并且有統一的方式存儲。

圖19 DataLake
也就是說我們的實時數據湖加了限制,公司所有結構化數據源和自然語言文本會統一實時匯總為UbiLog,并由ADX-DataHub統一對外提供訪問。UbiLog的訪問和使用只能通過ADX提供的能力輸出,因此確保了多租戶、安全、權限管控。
3.3.3 ADX-DataWorks數據工坊
主要的數據加工都是在DataWorks自助完成的。
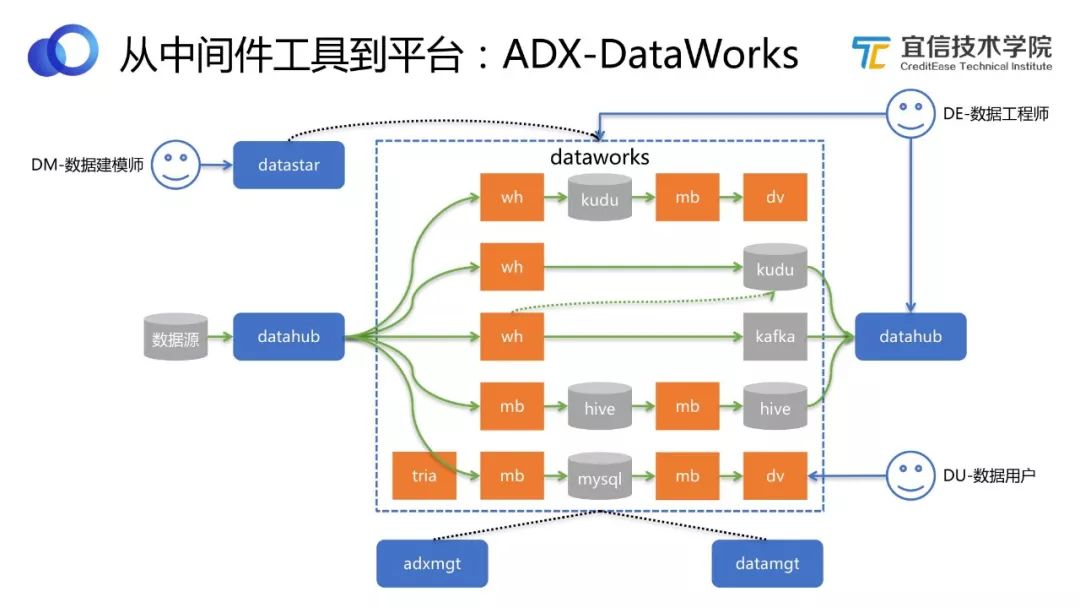
圖20 DataWorks工作流程
如圖來看DataWorks的工作流程。首先DataHub數據出來之后,DataWorks必須去接DataHub的數據。DataWorks支持實時報表,我們內部使用的是Kudu,所以把這個模式固化下來,用戶就不用自己去選型,直接在上面寫自己的邏輯就可以了。比如有一個實時DM或批量DM,我們覺得這是一個很好的數據資產,有復用價值,希望別的業務能復用這個數據,我們就可以通過DataHub把它發布出去,別的業務就可以申請使用。
所以DataHub和DataWorks等組件封裝而成的數據中臺可以達到數據共享和數據運營的效果。中臺內部包含Kudu、Kafka、Hive、MySQL等數據庫組件,但是用戶不需要自己去選型,我們已經做出了最佳選擇,并將其封裝成一個可直接使用的平臺。
上圖左側有一個數據建模師的角色,他在DataStar中做模型管理和開發建設,在DataWorks中主要是負責邏輯和模型的創建;數據工程師不用多說,是最常見的使用DataWorks的角色;終端用戶可以直接使用Davinci。
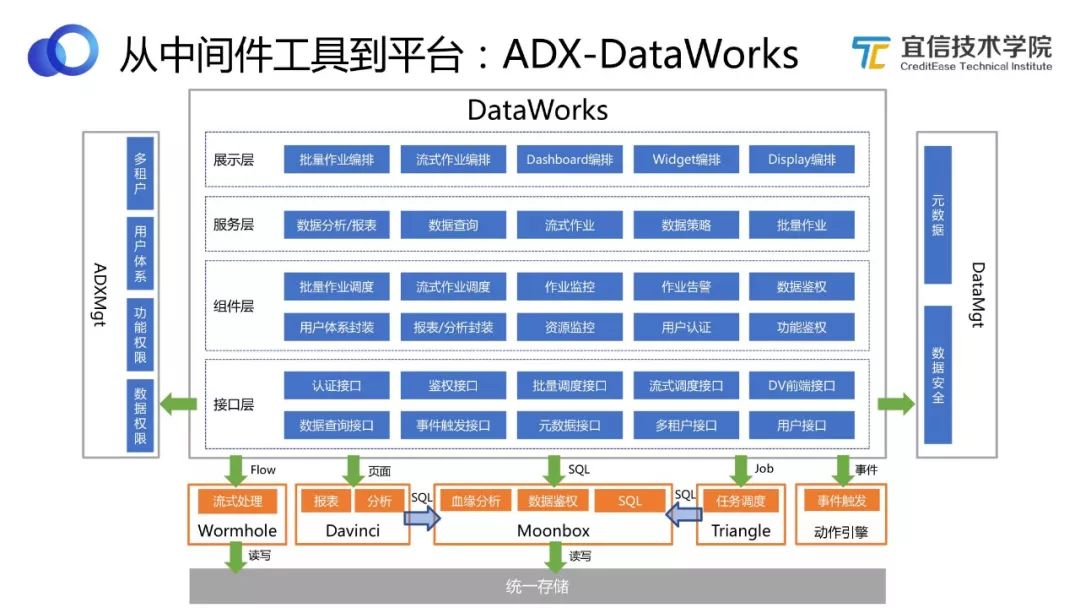
圖21 DataWorks架構
如圖,將DataWorks打開來看它的架構,同樣DataWorks也是通過不同的模塊來支持各種不同的功能。關于這部分內容以后會有更多的文章和分享,此處不詳細介紹。
3.3.4 ADX-DataStar數據模型
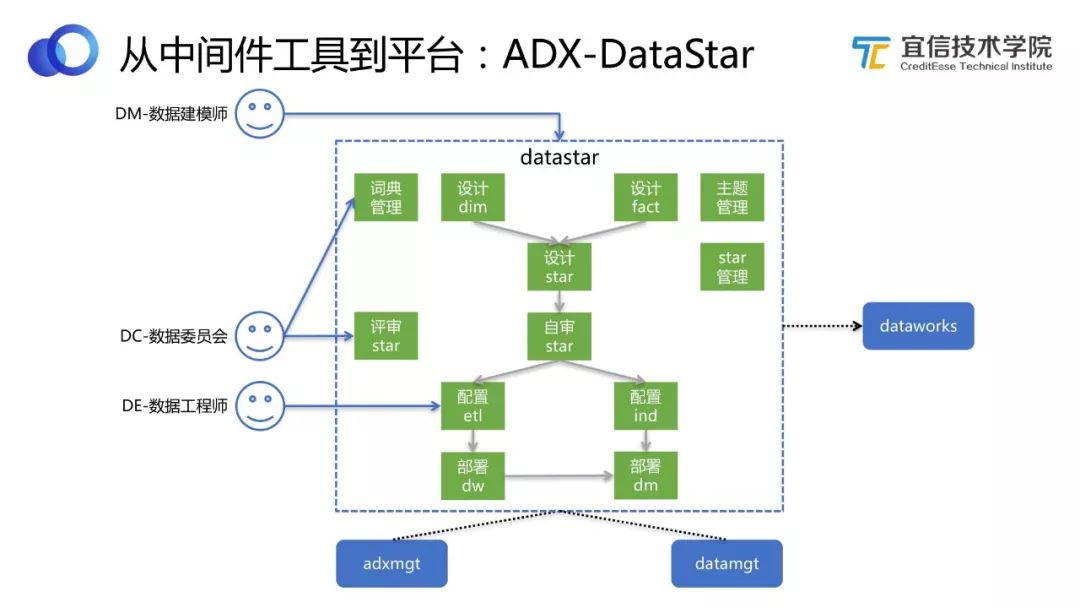
圖22 DataStar工作流程
DataStar跟數據指標模型或數據資產相關,每個公司都有自己內部的數據建模流程和工具。DataStar可以分為兩個部分:
模型設計、管理創建。對模型生命周期的管理和工藝流程的沉淀。
從DW(數倉)層到DM(數據集市)層,支持配置化的方式,自動在底下生成對應SQL邏輯,而不需要用戶自己去寫。
DataStar是DW層的事實和維度表組成的星型模型,可以最后沉淀下來。但我們認為,從DW層到DM層或APP層,不需要寫SQL開發了,只需要通過選維度和配置指標的方式,就可以自動可視化配置出來。
這樣的話對使用人的要求就發生了改變,需要一個建模師或者業務人員來做這個事情,給他一個基礎數據層,他根據自己的需求來配置想要的指標。整個過程,數據實施人員只需要關注ODS層到DW層就可以了。
3.3.5 ADXMgt/DataMgt中臺管理/數據管理
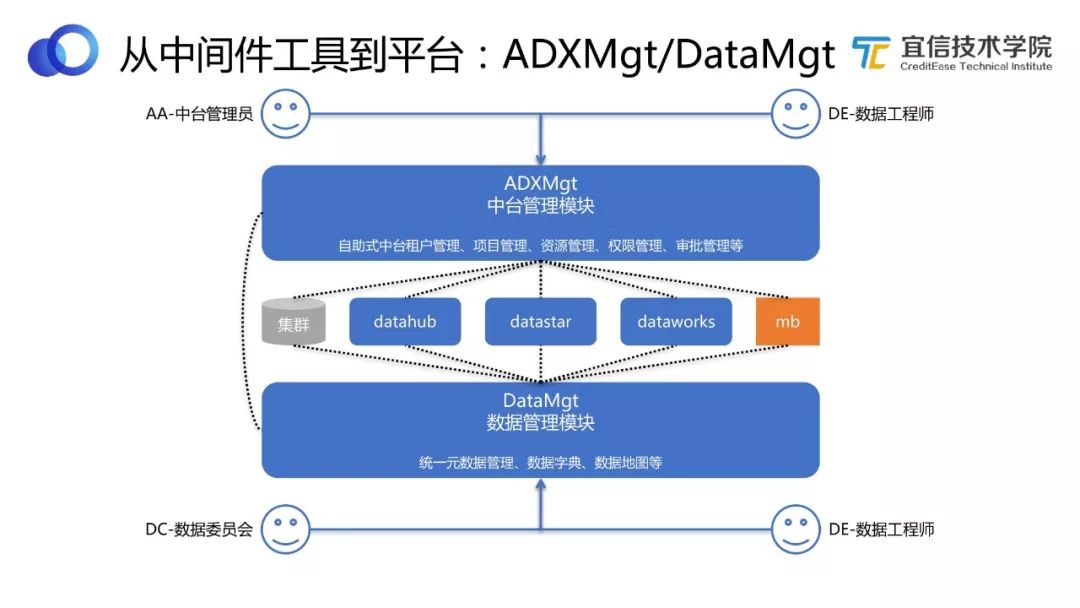
圖23 ADXMgt/DataMgt
中臺管理模塊主要關注租戶管理、項目管理、資源管理、權限管理、審批管理等。數據管理模塊主要關注數據管理層或數據治理層的話題。這兩個模塊從不同的維度對中間的三個主要組件提供支持和產生規則制約。
3.4 ADX架構
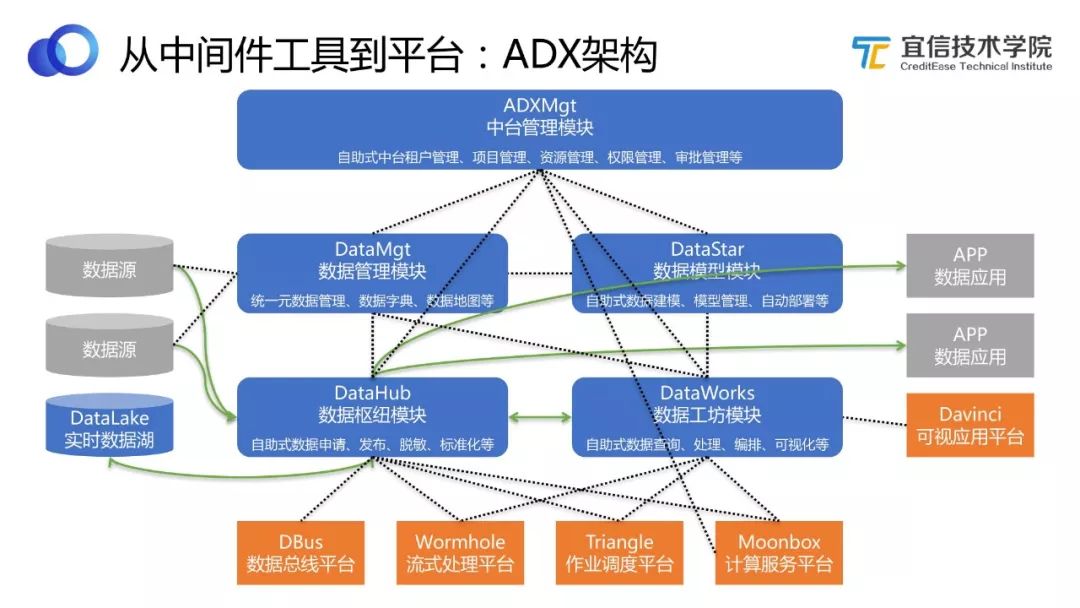
圖24 ADX架構
ADX數據中臺平臺幾個模塊之間的關聯如圖所示。最底下是五個開源工具,每個模塊都是對這五個開源工具的有機整合和封裝。從圖中可以看出各組件之間的關聯非常緊密,其中黑色虛線代表的是依賴關系,綠色線條代表的是數據流轉的關系。
四、典型案例分析
如上所述,我們基于幾個開源工具進行有機整合和封裝,打造了一個更加現代化、自助化、完備的一站式數據中臺平臺。那這個平臺是如何發揮其作用,為業務提供服務的呢?本節將列舉五個典型案例。
4.1 案例1 — 自助實時報表
【場景】
業務領域組數據團隊需要緊急制作一批報表,不希望排期,希望可以自助完成,并且部分報表需要T+0時效性。
【挑戰】
業務組數據團隊工程能力有限,只會簡單SQL,之前要么轉給BI排期,要么通過工具直連業務備庫制作報表,要么通過Excel制作。
數據來源可能來自異構數據庫,沒有很好的平臺支持自助導數。
對數據時效性要求很高,需要流上做數據處理邏輯。
【方案】
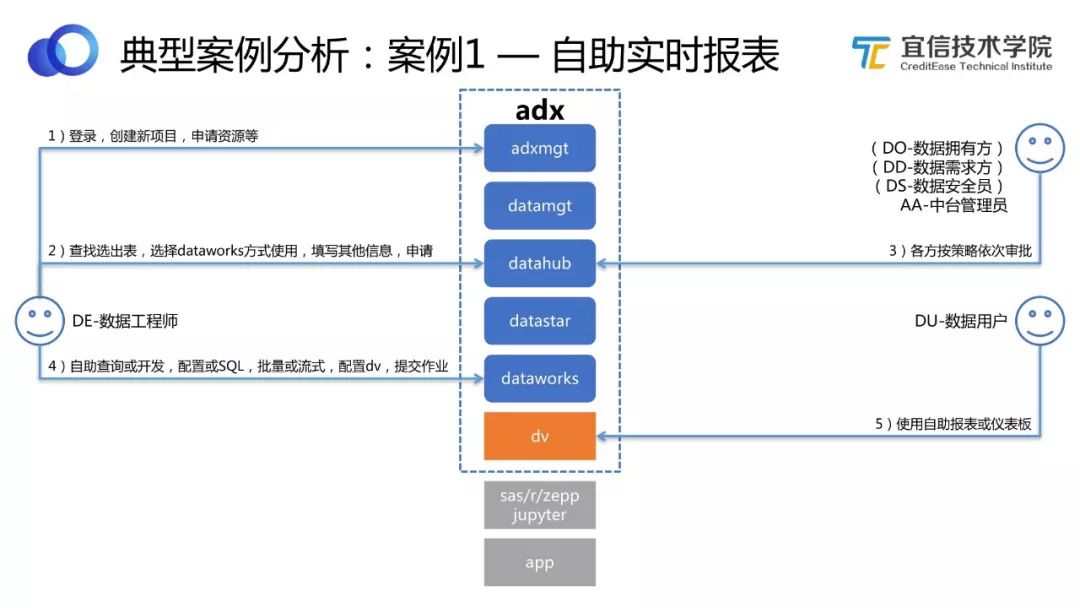
圖25 自助實時報表工作流程
用ADX數據中臺解決自助實時報表的問題。
數據工程師登錄平臺,創建新的項目,申請數據資源。
數據工程師通過元數據查找選出表,選擇DataWorks方式使用,填寫其他信息,申請這些需要用到的表。比如我需要用到100張表,其中70張是通過T+1的方式使用,30張是通過實時方式使用。
默認中臺會做標準化脫敏加密策略,收到這些申請之后,中臺管理員會按策略依次進行審批。
審批通過后,中臺會自動準備和輸出所申請的數據資源,數據工程師可以運用拿到的數據資源進行自助查詢、開發、配置、SQL編排、批量或流式處理、配置DV等。
最后將自助報表或儀表板提交給用戶使用。
【總結】
各個角色通過一站式數據中臺交互,統一流程,所有動作都記錄在案,可查詢。
平臺全自助能力,大大提高了業務數字化驅動進程,無需排期等待,經過短暫培訓,人均 3-5日可以自助完成一張實時報表,實時報表不再求人。
平臺支持人員也無需過多參與,不再成為進度瓶頸。
【能力】
這個場景需要用到很多數據能力,包括:即席查詢能力、批量處理能力、實時處理能力、報表看板能力、數據權限能力、數據安全能力、數據管理能力、租戶管理能力、項目管理能力、作業管理能力、資源管理能力。
4.2 案例2 — 協作模型指標
【場景】
業務線需要打造自己的基礎數據集市,以共享給其他業務或者前線系統使用。
【挑戰】
如何有效建設數據模型和管理數據模型。
如何既支持自己領域內數據模型建設,同時也支持數據模型的共享。
數據的共享發布如何從流程上固化、并實現技術安全統一管控。
如何運營數據以確保有效數據資產沉淀和管理。
【方案】
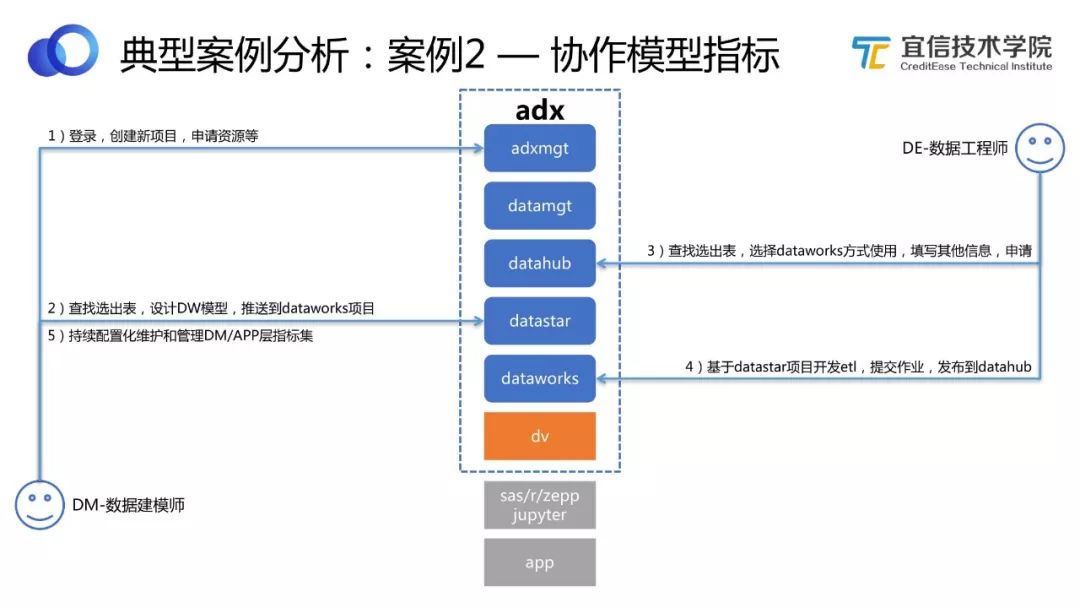
圖26 協作模型指標工作流程
用ADX數據中臺解決協作模型指標的問題。
數據建模師登錄平臺,創建新項目,申請資源。然后查找選出表,設計一個或若干個維度表的DW模型,推送到DataWorks項目。
數據工程師選擇需要的Source表,基于DataStar項目完成從ODS到DW之前的ETL 開發,然后提交作業,發布到DataHub跑起來。
數據建模師持續可視化配置維護和管理DW/APP層指標集,包括維度的聚合、計算等。
【總結】
這是一個典型的數據資產管理、數據資產運營的案例,通過統一的協作化的模型指標管理,確保了模型可維護、指標可配置、質量可追溯。
DataStar也支持一致性維度共享、數據詞典標準化、業務線梳理等,可以進一步柔性支持公司統一數據基礎層的建設和沉淀。
【能力】
本案例需要的能力包括:數據服務能力、即席查詢能力、批量處理能力、數據權限能力、數據安全能力、數據管理能力、數據資產能力、租戶管理能力、項目管理能力、作業管理能力、資源管理能力。
4.3 案例3 — 敏捷分析挖掘
【場景】
業務領域組數據分析團隊需要自助的進行快速數據分析挖掘。
【挑戰】
分析團隊使用工具各異,如SAS、R、Python、SQL等。
分析團隊往往需要原始數據進行分析(非脫敏),并且需要全歷史數據。
分析團隊希望可以快速拿到所需數據(往往并不知道需要什么數據),并敏捷高效專注于數據分析本身。
【方案】
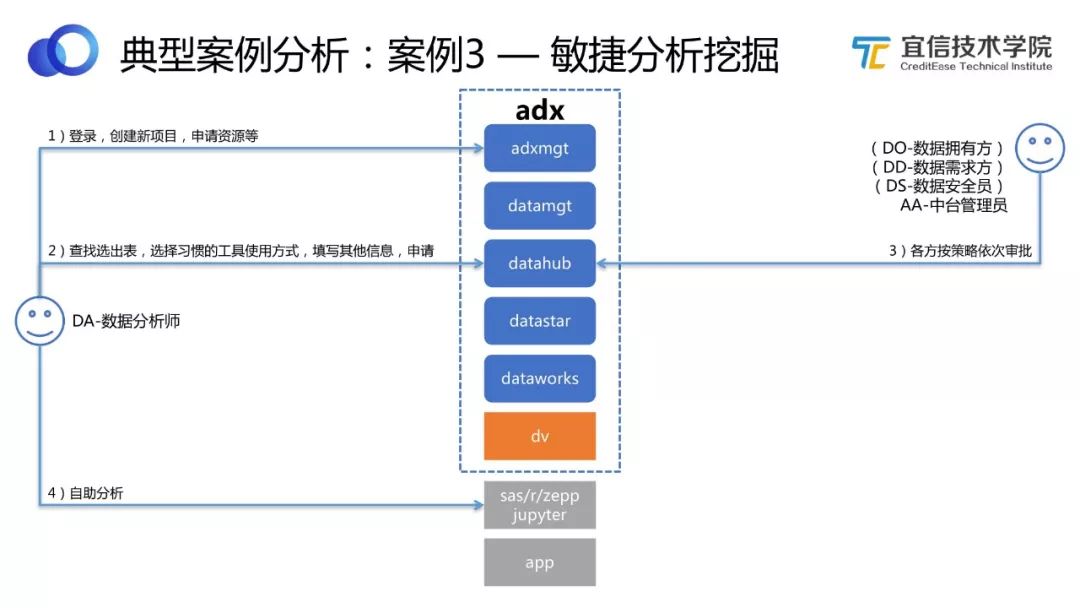
圖27 敏捷分析挖掘工作流程
用ADX數據中臺解決敏捷分析挖掘的問題。
數據分析師登錄平臺,創建新項目,申請資源。根據需求查找選出表,選擇習慣的工具使用方法,填寫其他信息,申請使用。
各方按照策略依次審批。
審批通過后,數據分析師獲得資源,利用工具進行自助分析。
【總結】
Moonbox本身是數據虛擬化解決方案,很適合進行各種異構數據源的即席數據讀取和計算,可以節省數據分析師很多數據工程方面的工作。
Datahub/DataLake提供了實時同步的全增量數據湖,還可以進行配置化脫敏加密等安全策略,為數據分析場景提供了安全可靠全面的數據支持。
Moonbox還專門提供了 mbpy(Moonbox Python)庫,以支持Python用戶更容易的在安全管控下進行快速無縫地數據查看、即席計算和常用算法運算工作。
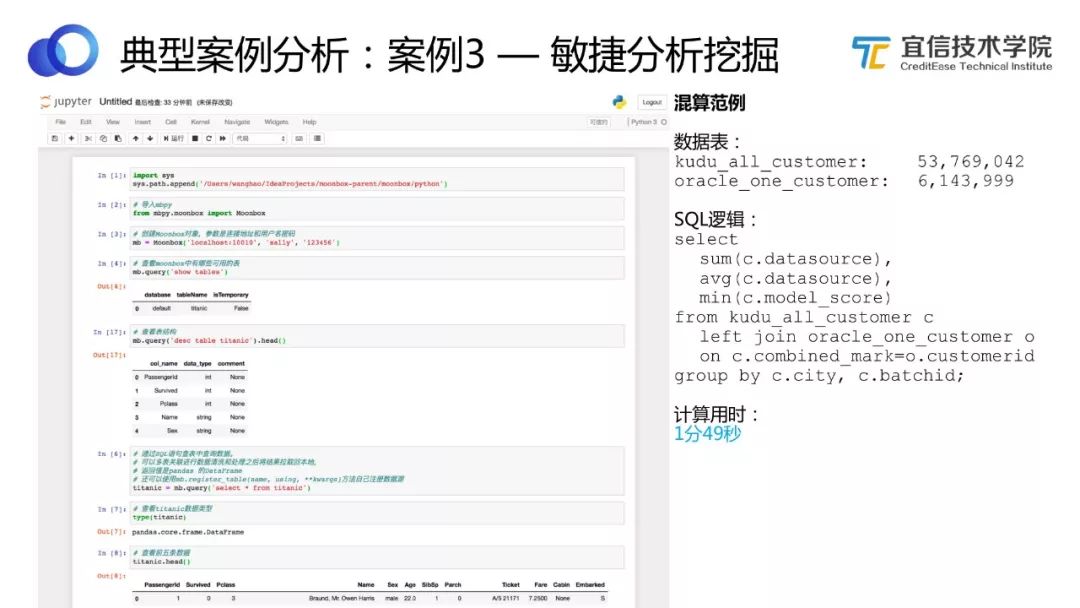
圖28 敏捷分析挖掘示例
舉個例子,一個用戶打開Jupyter,import一個mbpy的庫包,并以用戶身份登錄Moonbox,就可以查看管理員授權給他的表。他可以運用拿到的數據和表進行分析、計算等,而不需要關注這些數據來自哪里,這對用戶來說是一個無縫的體驗。
如上圖,有兩張表,一張表是5000多萬條數據,存儲在Kudu里;另一張表是600萬多條數據,存儲在Oracle里。數據存儲在異構的系統中,且kudu本身不支持SQL。我們通過Moonbox制定邏輯,認為數據都在一個虛擬數據庫中, 只用了1分40秒就計算出結果。
【能力】
本案例需要的能力包括:分析鉆取能力、數據服務能力、算法模型能力、即席查詢能力、多維分析能力、數據權限能力、數據安全能力、數據管理能力、租戶管理能力、項目管理能力、資源管理能力。
4.4 案例4 — 情景多屏聯動
【場景】
為了支持全方位的場景化和數字化驅動,有時會需要大中小智多屏聯動,大屏即為放映大屏,中屏即為電腦屏幕,小屏即為手機屏幕,智屏即為聊天客戶端屏幕。
【挑戰】
多屏由于定位不同,展示大小不同,操作不同,可以要求不同程度的可視化和定制化,帶來一定開發量。
多屏也需要在數據權限層面保持高度一致。
其中智屏更需要NLP、聊天機器人和任務機器人等智能能力,還需要有動態生成圖表能力。
【方案】
通過Davinci的Display功能,可以很好支持配置化滿足大小屏定制化需求。
通過Davinci統一數據權限體系,可以在多屏之間保持一致的數據權限條件。
通過ConvoAI的Chatbot/NLP能力,可以支持智能微BI能力,即為智屏。
圖29 Davinci的Display編輯頁面
上圖展示的是Davinci的Display編輯頁面,可以通過挑選不同的組件、調整透明度、任意擺放位置、調前景背景、顏色縮放比例等,自由地定義想要的展示樣式。
圖30 Davinci配置大屏
上圖是Davinci配置大屏的例子,(圖片來源于Davinci開源社區網友的實踐,數據經過處理),可以看到通過Davinci可以自己配置大屏,不需要開發。
圖31 Davinci配置小屏
上圖展示的是Davinci配置小屏的示例。
圖32 智屏
上圖展示的是智屏的示例。我們公司內部有一個基于ConvoAI的聊天機器人,可以通過一個聊天窗口,跟用戶互動,針對用戶需求返回結果,包括圖表等。
4.5 案例5 — 數據安全、管理
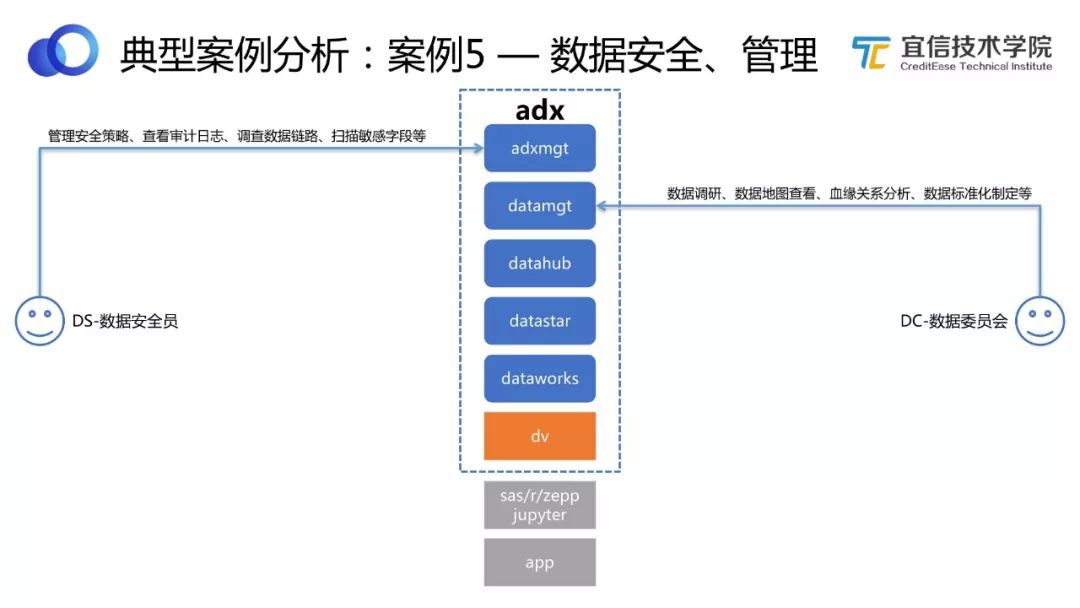
圖33 數據安全管理工作流程
這個案例比較簡單,一個完備的數據中臺,不僅有應用客戶場景,還有管理客戶場景,管理客戶典型的比如數據安全團隊和數據委員會。
數據安全團隊需要管理安全策略、掃描敏感字段、審批數據資源申請等。宜信敏捷數據中臺提供自動掃描功能,及時將掃描結果返回給安全團隊人員確認。安全團隊也可以定義幾層不同的安全策略、查看審計日志、調查數據流轉鏈路等。
數據委員會需要做數據調研、數據地圖查看、血緣分析、制定標準化和流程化的清洗規則等。他們同樣可以登錄數據中臺,完成這些工作。
五、總結
本次分享主要介紹了宜信敏捷數據中臺的頂層設計和定位、內部的模塊架構和功能、以及典型應用場景與案例。我們立足于宜信業務需求現狀與數據平臺發展背景,基于五大開源工具進行有機組合和封裝,結合敏捷大數據的理念,打造適合宜信自己業務的一站式敏捷數據中臺,并在業務及管理中得以應用與落地,希望能為大家帶來啟發和借鑒。
Q & A
Q:企業能純粹依靠開源社區的開源工具來搭建數據中臺嗎?
A:數據中臺是要切合企業實際情況和目標去建設的,有些好的開源工具本身已經很成熟,不需要重復造輪子,同時也有一些企業根據自身環境和需求,需要定制化開發。所以一般數據中臺都會既有開源工具選型,也會有結合自身情況的企業內通用組件的開發。
Q:數據中臺建設中,需要避免哪些彎路、哪些坑?
A:數據中臺比純技術平臺要求更多直接賦能業務的能力建設,如數據資產沉淀、數據服務建設、數據加工流程工藝抽象、企業數據標準化安全化管理等,這些可能都無法依靠純技術驅動自下而上地推動,而是需要公司層面和業務層面達成一致認識和支持,并且由業務實際需求驅動數據中臺迭代建設的。這樣的自上而下和自下而上相結合的迭代方式,可以有效避免不必要的短視和過度設計。
Q:數據中臺建設完畢,其成熟度和效果如何評估?
A:數據中臺的價值由驅動的業務目標來衡量。定性來說,就是是否真正做到了快、準、省的效果;定量來說,可以通過平臺組件復用度、數據資產復用度、數據服務復用度等指標來評估成熟度。
Q:平臺的元數據是怎樣管理的?
A:元數據是一個獨立的大話題,從元數據類目劃分,到如何采集維護各種元數據,再到如何基于元數據信息打造各種元數據應用等,是可以單獨拿出一個完整的分享來探討的。具體到宜信ADX的元數據管理,我們也是按照上述思路進行,先是整理出全景元數據類目劃分,然后很重要的一點是“業務痛點驅動元數據體系建設“,我們會根據目前公司對元數據最迫切的需求圈定優先級,然后在技術層面可以通過Moonbox進行各種數據源的基礎技術元數據采集,基于Moonbox的SQL解析能力來生成執行血緣關系等,最后根據業務的實際痛點,比如上游源數據表結構變更會如何影響下游數據應用(血緣影響度分析),下游數據問題如何追溯上游數據流轉鏈路(數據質量診斷分析)等,迭代的開發一個個元數據應用模塊。
Q:數據建模師建模的方法論是什么?和數倉的維度建模有什么區別?
A:我們的建模方法論也是基于著名的《數據倉庫工具箱》來指導建設的,并且根據宜信實際情況,對Kimball的維度建模進行了一定的簡化、標準化、通用化設計,同時也參考了阿里的OneData體系的經驗,這塊我們并無太多獨創性。DataStar更重要的目標,還是如何易用、有效的吸引和幫到數據建模師,從流程上能夠讓模型建設統一化、線上化、管理化,同時力求減少ETL開發人員負擔,將DW到DM/APP層的個性化指標工作通過配置化下放給非數據開發人員自助完成。所以DataStar整體上還是以管理和提效為主要目標的。
Q:Triangle任務調度系統是開源的么?
A:Triangle是另一個團隊研發維護的,他們有開源計劃,具體何時開源我們還太確定。
Q:Davinci 何時發版?
A:這是個永恒的問題,感謝大家對Davinci的持續關注和認可,我們有計劃將Davinci推到Apache孵化,所以希望大家可以一如既往地支持Davinci,讓Davinci成為最好的開源可視化工具選擇。
Q:數據服務是管控了所有的數據讀取寫入嗎?最好的情況是所有業務方都可通過數據服務訪問數據,這樣的話數據管理、鏈路、地圖就比較容易做。問題是很多情況下知道連接信息的話,業務方是可以直連的,怎么避免業務方自己使用API直連?
A:是的,DataHub的目標就是統一收口數據歸集、數據申請、數據發布、數據服務,這樣像數據安全管理、鏈路管理、標準化管理等都更容易實現了。如何避免業務方繞過DataHub直連源庫,這個恐怕要在管理流程上管控了,對于DataHub本身,由于DataHub封裝了實時數據湖,使得DataHub擁有了直連業務備庫所有不具備的能力特性,加上持續提升DataHub使用體驗和功能,相信業務方會更加愿意從DataHub對接數據的。
Q:DBus支持Postgres數據源嗎?
A:DBus目前支持MySQL、Oracle、DB2、日志、Mongo數據源,其中Mongo由于本身日志的特點使得DBus只能接出非完整增量日志(只有更新的列會輸出),這樣對強順序消費就提出了很高要求,內部來說沒有太多DBus接Mongo的場景。社區有提出DBus對接PostgreSQL和SQLServer的需求,理論上都是可以擴展對接的,但目前團隊都投入在數據中臺建設上,更多數據源類型的對接,如果有需要的話,可以直接聯系我們團隊討論。
Q:Moonbox的底層是用Spark SQL實現的這種混合計算,需要消耗很多資源,是怎么優化的呢?
A:Moonbox的混算引擎是基于Spark的,并對Spark做了一些優化工作,其中最大的一塊優化就是支持了更多計算下推(Pushdown),Spark本身也具備數據聯邦混算能力,但Spark只支持部分算子下推,如Projection和Predict,Moonbox對Spark做了旁路擴展,支持更多如Aggregation、Join、Union等算子下推,并且在解析SQL時會根據數據源計算特點進行有策略的下推執行計劃,盡量讓數據源做更適合的計算工作,減少在Spark里混算的計算成本。
Moonbox還支持如果SQL本身沒有混算邏輯,且數據源適合整個SQL計算,Moonbox可以繞過Spark直接將全SQL做整體下推到數據源。另外,Moonbox支持Batch計算、分布式Interactive計算和Local Interactive計算模式,每種都做了不同的優化和策略。
Q:離線計算和實時計算是怎么配合的,離線計算可以做分層存儲,實時計算怎么實現分層存儲?
A:實時計算分層,有一種做法是通過Kafka來做,當然如果對實時分層數據的時效性要求不太高(如分鐘級)的話,也可以選擇一些實時NoSQL存儲,如Kudu。“離線計算和實時計算怎么配合“,有了Moonbox,其實不管批量計算和流式計算的數據存儲在哪里,都可以通過Moonbox做無縫混算的,可以說Moonbox簡化并抹平了很多數據流轉架構的復雜性。
Q:中臺的定位是什么,會不會又是一個buzzword?在宜信內部,數據中臺跟傳統后臺的關系是怎樣的?
A:宜信數據中臺的定位在演講開頭已經談到了,簡單來說就是對下層做統一化管理化透明化,對中層做通用化標準化流程化,對上層做資產化服務化自助化。Buzzword這個也是要一分為二的看,有些浪潮留下的更多是教訓,有些浪潮帶來的更多是進步。“數據中臺跟傳統后臺的關系“,這里傳統后臺我理解是指業務后臺吧,好的業務后臺可以更好配合和支持數據中臺,不好的業務后臺會把更多數據層面的挑戰留待數據中臺去面對和解決。
Q:數據異構存儲在如此多的存儲組件中,如何保證個性化查詢的效率?
A:這個問題應該是指Moonbox這種體系架構,如何保證即席查詢效率。純即席查詢(源數據直接計算出結果),查詢效率怎樣都不會拼過內存型MPP查詢引擎的。對于我們來講,Moonbox主要用于統一批量計算入口、統一即席查詢入口、統一數據服務、統一元數據歸集、統一數據權限、統一血緣關系生成、統一數據工具箱等。如果追求毫秒級/秒級查詢效率,要么采用預計算引擎如Kylin、Druid等、要么ES、Clickhouse等,但這些都有個前提,就是基礎數據都已經準備好。因此我們的數據中臺鏈路,是支持ETL之后將DW/DM數據物理寫入ES、Clickhouse并統一DataHub發布的,這樣可以一定程度上保證“個性化“查詢效率。單純從Moonbox角度而言,在異構存儲上進行分鐘級/小時級的預計算并將結果寫入Clickhouse,可以支持分鐘級/小時級數據延遲,毫秒級/秒級查詢延遲。
Q:如果有新的數據進入系統,整個數據采集到進入存儲的過程是由開發人員控制,還是專門的數據管理人員通過界面組合各個組件Pattern來控制?
A:如果新數據源來自業務數據庫備庫,DBus已經對接了此備庫前提下,會有專門的數據中臺管理員在數據中臺管理界面上配置發布新的ODS,以供下游使用方在DataHub上申請并使用;如果新數據源來自業務自有NoSQL庫,業務人員可以自助地在DataHub上發起發布數據流程,然后下游使用方可以在元數據上看到并在DataHub上申請并使用。
所謂“數據采集到存儲“,也是分為實時采集、批量采集、邏輯采集等的,這些常用數據源類型、數據對接方式、用戶使用方式等都被DataHub封裝整合在內,不管是數據擁有方還是數據使用方面對的都是一站式的DataHub用戶界面,所有的數據鏈路Pattern、自動化流程和最佳技術選型和實踐都被透明化封裝在DataHub里,這也是工具化到平臺化的價值所在。
-
模塊
+關注
關注
7文章
2722瀏覽量
47568 -
數據安全
+關注
關注
2文章
682瀏覽量
29961 -
大數據
+關注
關注
64文章
8897瀏覽量
137526
原文標題:數據中臺:宜信敏捷數據中臺建設實踐|分享實錄(附視頻+PPT)
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一種UPS漏電保護探討
一種64色VGA的設計思路
一種異步FIFO的設計方法


一種新猜想為黑洞能量的提取提供了一種全新思路
肝 | 一種串口高效收發思路及方案

一種結合敏捷方法和V模型的汽車軟件開發方法
一種高效的串口收發思路及方案






 工商網監
工商網監
評論