 淘金記:如何尋找未開墾的Bert應用領域
淘金記:如何尋找未開墾的Bert應用領域
Bert 給人們帶來了大驚喜,不過轉眼過去大約半年時間了,這半年來,陸續出現了與Bert相關的不少新工作。
最近幾個月,在主業做推薦算法之外的時間,我其實一直比較好奇下面兩個問題:
問題一:Bert原始的論文證明了:在GLUE這種綜合的NLP數據集合下,Bert預訓練對幾乎所有類型的NLP任務(生成模型除外)都有明顯促進作用。但是,畢竟GLUE的各種任務有一定比例的數據集合規模偏小,領域也還是相對有限,在更多領域、更大規模的數據情況下,是否真的像Bert原始論文里的實驗展示的那樣,預訓練技術對于很多應用領域有了很大的促進作用?如果有,作用有多大?這種作用的大小與領域相關嗎?這是我關心的第一個問題。
問題二:Bert作為一項新技術,肯定還有很多不成熟或者需要改進的地方,那么,Bert目前面臨的問題是什么?后面有哪些值得改進的方向?這是我關心的第二個問題。
陸陸續續地,我收集到了截止到19年5月底為止發表的,大約70-80篇與Bert相關的工作,剛開始我是準備把關于這兩個問題的答案寫在一篇文章里的,寫著寫著發現太長,而兩個主題確實也可以獨立分開,所以就改成了兩篇。這一篇是回答第一個問題的,主題集中在各個NLP領域的Bert應用,一般這種應用不涉及對Bert本身能力的改進,就是單純的應用并發揮Bert預訓練模型的能力,相對比較簡單;至于對Bert本身能力的增強或者改進,技術性會更強些,我歸納了大約10個Bert的未來改進方向,放在第二篇文章里,過陣子會把第二篇再改改發出來,在那篇內容里,會歸納梳理Bert未來可能的發展方向。
這兩篇文章對讀者的知識結構有一定要求,建議在看之前,先熟悉下Bert的工作機制,可以參考之前介紹Bert的文章:從Word Embedding到Bert模型—自然語言處理中的預訓練技術發展史
百花齊放:Bert在NLP各領域的應用進展
本篇文章主要回答第一個問題,除此外,從應用的角度看,Bert比較擅長處理具備什么特性的任務?不擅長處理哪些類型的應用?哪些NLP應用領域是Bert擅長但是還未開墾的處女地?Bert的出現對NLP各個領域的傳統技術會造成怎樣的沖擊?未來會形成統一的技術方案嗎?包括Bert時代我們應該如何創新?……。。這些問題也會有所涉及,并給出我個人的看法。
在回答這些問題之前,我先講講我對Bert的一些務虛的看法,原先的內容本來在本文的這個位置,因為太長,之前已經摘出單獨發了,如果感興趣的話,可以參考這篇文章:Bert時代的創新:Bert應用模式比較及其它 | 技術頭條
萬象歸宗:事實,其實和你想的也許不一樣
自從Bert誕生,到目前轉眼半年過去了,如果歸納一下,目前出現了大量使用Bert來在NLP各個領域進行直接應用的工作,方法都很簡單直接,效果總體而言比較好,當然也需要分具體的領域,不同領域受益于Bert的程度不太相同。
本節對這些工作分領域介紹及做一些帶我個人主觀色彩的判斷和分析。
應用領域:Question Answer(QA,問答系統)與閱讀理解
QA中文一般叫做問答系統,是NLP的一個重要應用領域,也是個具有很長歷史的子領域了,我記得我讀書的時候,差一點就選了這個方向做博士開題方向……好險……當時的技術發展水準,我記得是各種trick齊飛, 靠譜共不靠譜技術一色…。。當然,其實我最終還是選擇了一個更糟糕的博士開題方向 ……。這應該是墨菲定律的一個具體例子?“選擇大于努力”,這個金句,一直被證明,從未被顛覆。在讀博士們請留心下這句肺腑之言,一定選好開題方向。當然,有時候能夠選什么方向也由不得你,上面是說在你有選擇自由的時候需要注意的地方。
QA的核心問題是:給定用戶的自然語言查詢問句Q,比如問“美國歷史上最像2B鉛筆的總統是誰?”,希望系統從大量候選文檔里面找到一個語言片段,這個語言片段能夠正確回答用戶提出的問題,最好是能夠直接把答案A返回給用戶,比如上面問題的正確答案:“特·不靠譜·間歇腦抽風·朗普”。
很明顯,這是個很有實用價值的方向,其實搜索引擎的未來,很可能就是QA+閱讀理解,機器學會閱讀理解,理解了每篇文章,然后對于用戶的問題,直接返回答案。
QA領域是目前Bert應用效果最好的領域之一,甚至有可能把“之一”都能拿掉。我個人認為,可能的原因是QA問題比較純粹。所謂的“純粹”,是說這是個比較純粹的自然語言或者語義問題,所需要的答案就在文本內容里,頂多還需要一些知識圖譜,所以只要NLP技術有提升,這種領域就會直接受益。當然,可能也跟QA問題的表現形式正好比較吻合Bert的優勢有關。那么Bert特別適合解決怎樣的問題?在本文后面專門會分析這個事情。
目前不同的QA領域利用Bert的技術方案大同小異,一般遵循如下流程:

應用Bert,從流程角度,一般分為兩個階段:檢索+QA問答判斷。首先往往會把比較長的文檔切割成段落或者句子n-gram構成的語言片段,這些片段俗稱Passage,然后利用搜索里的倒排索引建立快速查詢機制。第一個階段是檢索階段,這個和常規的搜索過程相同,一般是使用BM25模型(或者BM25+RM3等技術)根據問句查詢可能的答案所在候選段落或者句子;第二個階段是問答判斷。在訓練模型的時候,一般使用SQuAD等比較大的問答數據集合,或者手上的任務數據,對Bert模型進行 Fine-tuning;在應用階段,對于第一階段返回的得分靠前的Top K候選Passage,將用戶問句和候選passage作為Bert的輸入,Bert做個分類,指出當前的Passage是否包括問句的正確答案,或者輸出答案的起始終止位置。這是一個比較通用的利用Bert優化QA問題的解決思路,不同方案大同小異,可能不同點僅僅在于Fine-tuning使用的數據集合不同。
QA和閱讀理解,在應用Bert的時候,在某種程度上是基本類似的任務,如果你簡化理解的話,其實可以把上述QA流程的第一階段扔掉,只保留第二階段,就是閱讀理解任務應用Bert的過程。當然,上面是簡化地理解,就任務本身來說,其實兩者有很大的共性,但是也有些細微的區別;一般普通QA問題在找答案的時候,依賴的上下文更短小,參考的信息更局部一些,答案更表面化一些;而閱讀理解任務,要正確定位答案,所參考的上下文范圍可能會更長一些,部分高難度的閱讀理解問題可能需要機器進行適當程度的推理。總體感覺是閱讀理解像是平常QA任務的難度加大版本任務。但是從Bert應用角度,兩者流程近似,所以我直接把這兩個任務并在一起了。我知道,上面的話估計會有爭議,不過這個純屬個人看法,謹慎參考。
前面提過,QA領域可能是應用Bert最成功的一個應用領域,很多研究都證明了:應用Bert的預訓練模型后,往往任務都有大幅度的提升。下面列出一些具體實例。


而閱讀理解任務,應用Bert后,對原先的各種紛繁復雜的技術也有巨大的沖擊作用,前幾年,我個人覺得盡管閱讀理解領域提出了很多新技術,但是方法過于復雜了,而且有越來越復雜化的趨向,這絕對不是一個正常的或者說好的技術發展路線,我覺得路子有可能走歪了,而且我個人一直對過于復雜的技術有心理排斥感,也許是我智商有限理解不了復雜技術背后的深奧玄機?不論什么原因,反正就沒再跟進這個方向,當然,方向是個好方向。而Bert的出現,相信會讓這個領域的技術回歸本質,模型簡化這一點會做得更徹底,也許現在還沒有,但是我相信將來一定會,閱讀理解的技術方案應該是個簡潔統一的模式。至于在閱讀理解里面應用Bert的效果,你去看SQuAD競賽排行榜,排在前列的都是Bert模型,基本閱讀理解領域已經被Bert屠榜了,由這個也可以看出Bert在閱讀理解領域的巨大影響力。
應用領域:搜索與信息檢索(IR)
對于應用Bert,搜索或IR的問題模式及解決方案流程和QA任務是非常相近的,但是因為任務不同,所以還是有些區別。
搜索任務和QA任務的區別,我綜合各方面信息,列一下,主要有三點:
首先,盡管兩個任務都是在做Query和Document的匹配,但是匹配時側重于哪些因素,這兩個任務是不同的。兩個文本的“相關性”和“語義相似性”代表的內涵是有差異的;所謂“相關性”,更強調字面內容的精確匹配,而“語義相似性”則多涵蓋了另外一個意思:就是盡管字面不匹配,但是深層語義方面的相近。QA任務對于這兩者都是重視的,可能偏向語義相似性更多一些,而搜索任務更偏重文本匹配的相關性方面。這是兩個任務的第一個不同。
其次,文檔長度的差異。QA任務往往是要查找問題Q的答案,而答案很可能只是一小段語言片段,在Passage這個較短的范圍內,一般會包含正確答案,所以QA任務的答案一般比較短,或者說搜索對象比較短就可以覆蓋正確答案,即QA任務的處理對象傾向于短文本;而對搜索任務來說,文檔普遍比較長。盡管在判斷文檔是否與查詢相關時,也許只依賴長文檔中的幾個關鍵Passage或者幾個關鍵句子,但是關鍵片段有可能散落在文檔的不同地方。在應用Bert的時候,因為Bert對于輸入長度有限制,最長輸入允許512個單位。于是,如何處理長文檔,對于搜索來說比較重要;
再次,對于QA這種任務來說,可能文本內包含的信息足夠作出判斷,所以不需要額外的特征信息;而對于搜索這種任務,尤其是現實生活中的實用化的搜索,而非性質比較單純的評測中的Ad hoc檢索任務。在很多時候,僅僅靠文本可能無法特別有效地判斷查詢和文檔的相關性,其它很多因素也嚴重影響搜索質量,比如鏈接分析,網頁質量,用戶行為數據等各種其它特征也對于最終的判斷也起到重要作用。而對于非文本類的信息,Bert貌似不能很好地融合并體現這些信息。推薦領域其實也跟搜索一樣,面臨類似的問題。
盡管講了這么多領域間的區別,但是其實也沒什么用,如果你看目前見到的用Bert改進檢索領域的工作,尤其是Passage級別的信息檢索問題,可能你無法分辨現在在做的是搜索問題還是QA問題。當然,對于長文搜索,搜索還是有單獨的問題需要處理。為何會出現這種無法分辨QA及搜索任務的現象呢?這是因為目前出現的利用Bert改進檢索的工作,一方面比較集中在Passage級別;另外一方面通常任務是Ad Hoc檢索,以內容匹配為主,與真實搜索引擎利用的主要特征差異比較明顯。主要應該是這兩個原因造成的。
我們再歸納下在Ad Hoc檢索任務中一般如何應用Bert:一般也是分成兩個階段,首先利用BM25等經典文本匹配模型或者其它簡單快速的模型對文檔進行初步排序,取得分前列Top K文檔,然后用復雜的機器學習模型來對Top K返回結果進行重排序。應用Bert的地方明顯在搜索重排序階段,應用模式與QA也是類似的,就是把Query和Document輸入Bert,利用Bert的深層語言處理能力,作出兩者是否相關的判斷。如果是Passage級別的短文檔檢索,其實流程基本和QA是一樣的;而如果是長文檔檢索,則需要增加一個如何處理長文檔的技術方案,然后再走Bert去做相關性判斷。
所以,對于如何在信息檢索領域應用Bert,我們從兩個不同的角度來說:短文檔檢索和長文檔檢索。
對于短文檔檢索而言,你把它看成QA任務,其實問題也不大。所以這里不細說了,直接上結果。幾個工作在Passage級別文檔檢索任務中的效果,可以參考這個PPT所列內容:

從上面各種實驗數據可以看出:對于短文檔檢索來說,使用Bert后,性能一般都有大幅度的提升。
對于長文檔檢索任務,因為Bert在輸入端無法接受太長的輸入,則面臨一個如何將長文檔縮短的問題。其它過程和短文檔檢索基本雷同。那么怎么解決搜索中的長文檔問題呢?可以參考下列論文的思路。
論文《Simple Applications of BERT for Ad Hoc Document Retrieval》
這篇論文首次在信息檢索領域應用Bert,并且證明了Bert對于搜索應用能有效提升效果。它同時做了短文檔和長文檔的實驗。短文檔利用TREC 2014的微博數據。引入Bert后,在微博搜索任務上,相對目前最好的檢索模型,在不同的微博搜索任務中有5%到18%的效果提升,相對基準方法(BM25+RM3,這是一個強基準,超過大多數其它改進方法)有20%到30%的效果提升。
第二個數據集是TREC長文檔檢索任務,這里就體現出搜索和QA任務的不同了。因為要搜索的文檔比較長,在重排序階段,很難把整個文檔輸入到Bert中,所以這個工作采取了一個簡單的方法:把文檔分割成句子,利用Bert判斷每個句子和查詢Q的相關性,然后累加得分最高的Top N句子(結論是取得分最高的3個句子就夠了,再多性能會下降),獲得文檔和查詢Q的相關性得分,這樣就將長文檔問題轉化成了文檔部分句子的得分累加的模式。實驗表明相對強基準BM25+RM3,使用Bert會有大約10%的效果提升。
一種搜索領域長文檔的解決思路
從上面這篇文章對搜索長文檔的處理過程,我們可以進一步對此問題進行深入思考。考慮到搜索任務的特殊性:文檔和用戶查詢的相關性,并不體現在文章中的所有句子中,而是集中體現在文檔中的部分句子中。如果這個事實成立,那么一種直觀地解決搜索任務中長文檔問題的通用思路可以如下:先通過一定方法,根據查詢和文檔中的句子,判斷兩者的相關性,即產生判斷函數Score=F(Q,S),根據Score得分篩選出一個較小的句子子集合Sub_Set(Sentences),由這些句子來代表文檔內容。這樣即可將長文有針對性地縮短。從和查詢相關性的角度來說,這樣做也不會損失太多信息。關鍵是這個F(Q,S)函數如何定義,不同的定義方法可能產生表現不同的效果。這個F函數,可以被稱為搜索領域文檔的句子選擇函數,這個函數同樣可以使用不同的DNN模型來實現。這里是有很多文章可做的,有心的同學可以關注一下。
如果歸納一下的話:在搜索領域應用Bert,如果是Passage這種短文檔搜索,往往效果有非常巨大的提升;而目前長文檔的搜索,使用Bert也能有一定幅度的提升,但是效果不如短文檔那么明顯,很可能原因在于搜索的長文檔處理方式有它自己的特點,還需要繼續摸索更合理的更能體現搜索中長文檔特性的方法,以進一步發揮Bert的效果。
應用領域:對話系統/聊天機器人(Dialog System or Chatbot)
聊天機器人或者對話系統最近幾年也非常活躍,這與市面上出現大量的聊天機器人產品有關系。個人私見,這個方向是符合未來發展趨勢的方向,但是目前的技術不夠成熟,難以支撐一個能夠滿足人們心目中期望的好用產品,所以我個人不是太看好這個方向近期內的產品形態,主要還是目前技術發展階段所限,支撐不起一個好的用戶體驗。這是題外話。
聊天機器人從任務類型劃分的話,常見的有日常聊天以及任務解決型。日常聊天好理解,就是漫無目的地閑聊,幫你打發時間,當然前提是你得有空閑時間需要被它打發掉。我發現低齡兒童很可能是這個任務類型的目標受眾,兩年前我家閨女能興致勃勃地跟Siri聊半個小時,聊到Siri都嫌她煩了。當然,Siri收到的最后一句話往往是這樣的:“Siri,你太笨了!”
任務解決就是幫著用戶解決一些日常事務,解決日常碰到的實際問題。比如,99%的直男,一年中會因為忘記一些節假日被女友或者老婆噴得患上節假日恐懼癥,有了聊天機器人,你就再也不用怕了。你可以跟聊天機器人說:“以后但凡是節假日,你記得提醒我,幫我給XX訂束花。”于是,你在一年的365天里,有364天會收到聊天機器人的500多個提醒,這樣你再也不用怕被噴了,生活會變得越來越美好。而且假如萬一你中年失業,因為對送花這個事情特別熟悉,所以估計去開個連鎖花店,說不定過幾年就上市了,也許比瑞幸咖啡上市速度還快……這就是任務解決型聊天機器人帶給你的切實的好處,不湊巧還能推著你意外地走向人生巔峰。
上面開個玩笑,如果從技術角度看的話,聊天機器人主要面臨兩種技術挑戰。
其一:對于單輪對話來說,就是一問一答場景,任務解決型聊天需要從用戶的話語中解析出用戶的意圖。比如到底用戶是想要訂餐還是點歌,一般這是個分類問題,叫用戶意圖分類,就是把用戶的意圖分到各種服務類型里面;另外如果用戶意圖敲定,那么根據意圖要抽取出一些關鍵元素,比如訂機票,需要抽取出出發地、目的地、出發時間、返程時間等信息。目前一般采用槽填充(Slot Filling)的技術來做,一個關鍵元素就是一個槽位(Slot),從用戶交互中抽取出的這個槽位對應的取值,就是Filling過程。比如點歌場景下,有一個槽位就是“歌手”,而如果用戶說“播放TFBoys的歌”,那么經過槽位填充,會得到“歌手”槽位對應的取值“歌手=TFBoys”,這就是典型的槽位填充過程。

論文“BERT for Joint Intent Classification and Slot Filling”即是利用Bert解決單輪會話的會話意圖分類以及槽位填充任務的。解決方法也很直觀,輸入一個會話句子,Transformer的[CLS]輸入位置對應高層Transformer位置輸出句子的意圖分類,這是一個典型地應用Bert進行文本分類的方法;另外一方面,對于會話句中的每個單詞,都當作一個序列標注問題,每個單詞在Transformer最高層對應位置,分類輸出結果,將單詞標注為是哪類槽的槽值的IOE標記即可。這是典型的用Bert解決序列標注的思路。而這個方法則通過Bert同時做了這兩件事情,這點還是挺好的。通過采用Bert預訓練過程,在兩個數據集合上,在意圖分類任務上效果提升不太明顯,可能是基準方法本身已經把指標做得比較高了;槽值填充方面,與RNN+Attention等基準方法相比,兩個數據集合表現不一,一個數據集合效果提升2%,另外一個提升12%左右。總體而言,表現還行,但是不突出。
其二:對于多輪會話來說,就是說用戶和聊天機器人交互問答好幾個回合的場景下,如何改進模型,讓聊天機器人記住歷史的用戶交互信息,并在后面的應答中正確地使用歷史信息,就是個比較重要的問題,這也很大程度上影響用戶對于聊天機器人到底有多智能的體驗。所以,如何有效融入更多的歷史信息,并在上下文中正確地場合正確地使用歷史信息,就是模型改進的關鍵。
那么如果把Bert應用在多輪會話問題上,會是什么效果呢?論文Comparison of Transfer-Learning Approaches for Response Selection in Multi-Turn Conversations給出了實驗結果。它利用GPT及Bert等預訓練模型改進多輪對話中如何融入歷史信息,來對下一句選擇的問題。效果提升明顯,Bert效果優于GPT,GPT效果明顯優于基準方法。Bert相對基準方法,在不同數據集合下,效果提升幅度在11%到 41%之間。
總之,Bert應用在聊天機器人領域,潛力應該還是比較大的。單輪會話的問題相對比較簡單;多輪會話中,如何融入上下文這個問題,還是比較復雜,我相信Bert在這里能夠發揮較大的作用。
應用領域:文本摘要
文本摘要有兩種類型,一種是生成式的(Abstractive Summarization),輸入是較長的原始文檔,輸出的內容不局限于在原文出現的句子,而是自主生成能夠體現文章主要思想的較短的摘要;另外一種是抽取式的(Extractive Summarization),意思是從原始文檔中選擇部分能夠體現主題思想的句子,摘要是由文中抽出的幾個原始句子構成的。
下面分述兩種不同類型的摘要任務,在應用Bert時的要點。
生成式文本摘要

很明顯,生成式摘要任務,從技術體系來說,符合典型的Encoder-Decoder技術框架:原始文章從Encoder輸入,Decoder生成語句作為摘要結果。既然是這樣,要想利用Bert的預訓練成果,無非體現在兩個地方,一個地方是Encoder端,這個好解決,只需要用預訓練好的Bert模型初始化Encoder端Transformer參數即可,簡單直觀無疑義;另外一個地方是在Decoder端,這個地方要應用Bert就比較麻煩,主要的問題在于:盡管也可以用Bert的預訓練參數初始化Decoder對應的Transformer參數,但是目前各種實驗證明這么做效果不好,主要是因為:Bert在預訓練的時候,采用的是雙向語言模型的模式。而一般的NLP任務在Decoder階段的生成過程,是從左到右一個單詞一個單詞逐步生成的。所以,這與Bert的雙向語言模型訓練模式不同,無法有效利用Bert在預訓練階段學習好的下文的信息提示作用。于是,造成了Bert的預訓練模型無法在Decoder端充分發揮作用。
所以,如果采取Encoder-Decoder框架做生成式的文本摘要,要想發揮出Bert的威力,并不容易。因為它面臨與Bert做NLP生成類任務完全相同的問題,而Bert目前在生成模型方面是個難題,盡管最近出了幾個方案,但是實際上,這個問題貌似仍然并沒有被很好地解決,所以它是嚴重依賴Bert生成模型的技術進展的。
至于如何在生成類任務中發揮Bert的潛力,這是Bert模型改進的一個重要方向,關于目前的解決方案及效果評價,我會放在下一篇“模型篇”里分析,所以這里暫時略過不表。
抽取式文本摘要
抽取式文本摘要則是個典型的句子分類問題。意思是模型輸入文章整體的文本內容,給定文中某個指定的句子,模型需要做個二分類任務,來判斷這個句子是不是應該作為本文的摘要。所以,抽取式文本摘要本質上是個句子分類任務,但是與常規文本分類任務相比,它有自己獨特的特點,這個特點是:輸入端需要輸入整個文章內容,而分類的判斷對象僅僅是當前要做判斷的某個句子,整個文章只是對當前句子進行判斷的一個上下文,但是又必須輸入。而一般的文本或者句子分類,輸入的整體就是判斷對象,不存在多出來的這個上下文的問題。這是它和普通的文本分類任務的最主要區別。
所以說,對于抽取式文本摘要任務,盡管可以把它看成個句子分類任務,但是它的輸入內容和輸出對象不太匹配,這個是關鍵差異。于是,在模型輸入部分如何表達這種句子和文章的隸屬關系方面,需要花些心思。
如果要用Bert做抽取式摘要,也就是用Transformer作為特征抽取器,并用Bert的預訓練模型初始化Transformer參數,以這種方式構建一個句子的二分類任務。從模型角度,Bert肯定是可以支持做這個事情的,只需要用Bert的預訓練模型初始化Transformer參數即可。問題的關鍵是:如何設計并構建Transformer的輸入部分?要求是:輸入部分同時要輸入文章整體的內容,并指出當前要判斷的句子是哪個句子。所以,這里的關鍵是Transformer模型的輸入和輸出如何構造的問題,而模型本身應用Bert成果則沒什么問題,算是一種常規的Bert應用。
現在可以套用一下這個方法,也就是在沒看到別人怎么做之前,自己想想你會怎么做。所以,在沒有看到用Bert做抽取式摘要的論文前,我自己拍腦袋想了想,發現比較容易想到的有下面兩種方法:

方法一:把Transformer的輸入分為兩個部分,第一個部分是文章原文。當然,目前Bert支持的最大輸入長度512,所以原文也不能太長;第二個部分是當前要判斷的句子。兩者之間加個分隔符《SEP》;輸出部分則要求最開始的[CLS]輸入位置對應的Transformer最高層輸出0/1兩種分類結果,如果結果是1,則意味著這個句子可以作為摘要句,0則意味著此句不會作為摘要句。只要依次對文中每個句子都如此判斷一下,把分類為1的句子按照句中順序拼接,就可以得到文本摘要。這是一種可能的方法;目前我尚未看到如此做的模型,當然,我自己也覺得這個方式繁瑣了些。
方法二:Transformer的輸入部分只有一個部分,就是文章本身的完整的內容,由多個句子構成。如果是這種輸入,那么帶來的新的問題是:我們怎么知道當前要判斷哪個句子是否適合作為摘要句呢?可以這么做:在Transformer的輸入部分,在每個句子頭加入一個句子起始標記《BOS》,或者把這個分隔符號理解為是句子之間的分隔符也可以;或者也可以在句子的對應Embedding里加入句子編號,用來區分不同句子的界限應該也可以(Bert的輸入部分除了常規的單詞embedding,對于多句子類型任務,還有句子的embedding,屬于相同句子的單詞共享相同的句子embedding)。盡管可以有不同的具體做法,但是核心思想是相近的:就是在輸入端明確加入一些標記符號,用來區分不同的句子。
輸入部分的問題解決了,于是,剩下的問題就是Transformer的輸出部分怎么設計了。同樣的,這里可能有幾種不同的做法。拍下腦袋,比如可以模仿閱讀理解的輸出,要求Transformer的輸出部分輸出若干個句子的《起始Position,終止Position》,這是一種可能做法;比如也可以在最開始的輸入[CLS]符號對應的Transformer最高層Embedding上面上面綁定K個輸出頭,每個輸出頭輸出被選為摘要的句子編號,指定最多輸出K個摘要句子,這是另外一種可能做法;除此外,還有其它的可能做法,比如也可以在Transformer的最高層各個單詞的embedding序列里,找出輸入側對應的句子頭位置《BOS》的相應位置的高層Embedding信息,每個《BOS》對應的輸入位置對應高層embedding作為這個句子的信息集成,在這個句子信息Embeddding基礎上設計分類層,這樣等于給每個句子進行分類。
還有其它做法嗎?應該還有。比如還可以把摘要看成一個類似分詞或者POS的單字/單詞分類問題,每個輸入單詞對應的Transformer高層節點,要求對每個單詞進行分類,而輸出的類別可以設計為[BOS(摘要句子起始單詞標記),MOS(摘要句子句中單詞標記),EOS(摘要句子結束單詞標記),OOS(非摘要句單詞標記)],這也是一種可能的做法,這是把摘要看成序列標注問題來做的。當然,你也可以拍拍腦袋,估計還有很多其它做法。
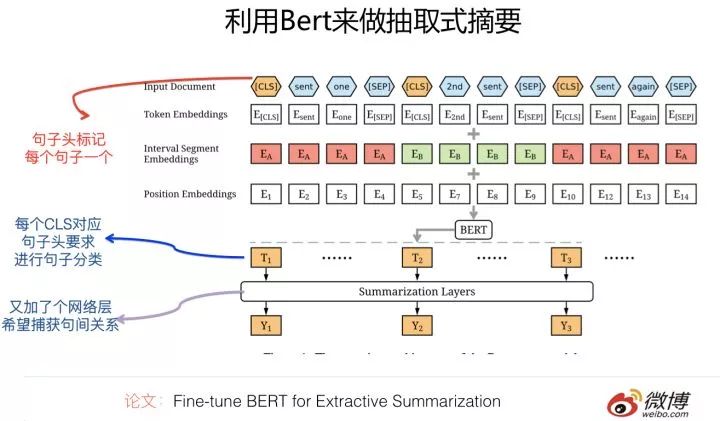
目前有個論文(Fine-tune BERT for Extractive Summarization)是做抽取式文本摘要的。它的具體做法基本遵循上面講的方法二的框架,在輸入部分用特殊分隔符分隔開不同的句子,每個句子加入句子頭標記《CLS》,在輸出部分則要求在輸入為《CLS》位置對應的Transformer最高層embedding之上,構建輸出層,用來判斷這個句子是否會被選為摘要句子。和上面的敘述方法不同的地方是:它在《CLS》輸出層和真正的分類層之間又多加入了一個網絡層,用來集成文章中不同句子之間的關系,比如用線性分類/transformer/RNN等模型來集成句子間的信息,然后在此基礎上,再輸出真正的句子分類結果。不過,從試驗結果看,其實這個新加入的中間網絡層,使用不同模型效果差不太多,這說明在這里加入新的網絡層并沒有捕獲新的信息,我個人覺得這塊是可以拿掉簡化一下模型的。至于用上述思路引入Bert預訓練模型的摘要系統,從效果上看,雖然優于目前的SOTA模型,但是并沒有超過太多。而這說明了什么呢?這是值得思考的一個問題。
應用領域:NLP中的數據增強
我們知道,在CV領域中,圖像數據增強對于效果有非常重要的作用,比如圖像旋轉或者摳出一部分圖片作為新增的圖像訓練實例。其實,NLP任務也面臨類似的需求,之所以會有這種需求,是因為:如果訓練數據越充分,能夠覆蓋更多的情形,那么模型效果越好,這個道理好理解。問題是怎么才能低成本地拓展任務地新訓練數據。
當然,你可以選擇人工標注更多的訓練數據,但無奈人工標注訓練數據成本太高,能否借助一些模型來輔助作出新的訓練數據實例,以此來增強模型性能呢?NLP數據增強就是干這個事情的。
回到我們的主題上來:能否利用Bert模型來擴充人工標注好的訓練數據?這是在數據增強領域應用Bert的核心目標。目標很明確,剩下的問題是具體的方法而已。這個領域算是比較有新意的Bert應用領域。
論文《Conditional BERT Contextual Augmentation》
這是個比較有趣的應用,來自中科院信工所。它的目的是通過改造Bert預訓練模型,來產生新增的訓練數據,以此來增強任務分類效果。就是說對于某個任務,輸入訓練數據a,通過Bert,產生訓練數據b,利用b來增強分類器性能。
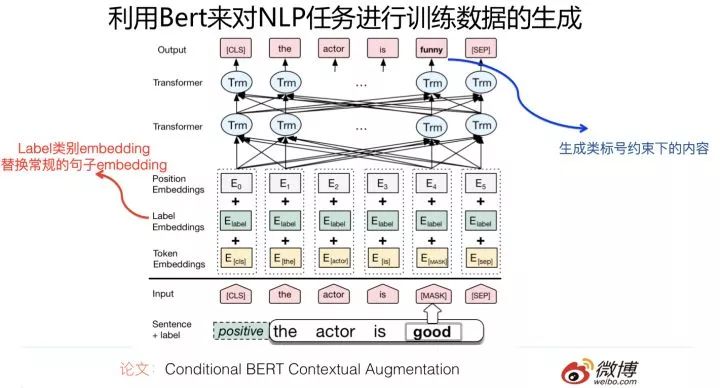
它的改造方法如下:將Bert的雙向語言模型,改造成條件語言模型。所謂“條件”,意思是對于訓練數據a,Mask掉其中的某些單詞,要求Bert預測這些被Mask掉的單詞,但是與通常的Bert預訓練不同的是:它在預測被Mask掉的單詞的時候,在輸入端附加了一個條件,就是這個訓練數據a的類標號,假設訓練數據的類標號已知,要求根據訓練數據a的類標號以及上下文,通過Bert去預測某些單詞。之所以這樣,是為了能夠產生更有意義的訓練數據。比如對于情感計算任務來說,某個具備正向情感的訓練實例S,mask掉S中的情感詞“good”,要求Bert生成新的訓練實例N,如果不做條件約束,那么Bert可能產生預測單詞“bad”,這也是合理的,但是作為情感計算來說,類別的含義就完全反轉了,而這不是我們想要的。我們想要的是:新產生的訓練例子N,也是表達正向情感的,比如可以是“funny”,而如果加上類標號的約束,就可以做到這一點。具體增加約束的方式,則是將原先Bert中輸入部分的Sentence embedding部分,替換成輸入句子的對應類標號的embedding,這樣就可以用來生成滿足類條件約束的新的訓練數據。這個做法還是很有意思的。
如果將通過Bert產生的新訓練數據增加到原有的訓練數據中,論文證明了能夠給CNN和RNN分類器帶來穩定的性能提升。
論文《Data Augmentation for BERT Fine-Tuning in Open-Domain Question Answering》
這篇論文也涉及到了NLP中的數據增強,不過這個數據增強不像上面的文章一樣,訓練數據通過Bert產生,貌似是在QA問題里面采用規則的方式擴充正例和負例,做例子本身沒什么特別的技術含量,跟Bert也沒啥關系。它探討的主要是在Bert模型下的QA任務中,如何使用這些增強的訓練數據。有價值的結論是:如果同時增加通過增強產生的正例和負例,有助于增加Bert的應用效果;而且Stage-wise方式增加增強數據(就是原始訓練數據和增強訓練數據分多個階段依次進行訓練,而且距原始訓練數據越遠的應該越先進行Fine-tuning),效果好于把增強數據和原始數據混合起來單階段訓練的模式。
所以,上面兩個文章結合著看,算是用Bert產生新的訓練實例以及如何應用這種增強實例的完整過程。
應用領域:文本分類
文本分類是個NLP中歷史悠久,源遠流長…。。總之比較成熟的應用領域。它的意思是給定一個文檔,模型告訴這是哪個類別,是講的“體育”還是“娛樂”,總之就是這個意思。
那么,Bert應用在這個領域效果如何呢?目前也有工作。
論文《DocBERT: BERT for Document Classification》
在四個常用的標準文本分類數據集合上,利用Bert的預訓練模型進行了效果測試,應該說效果能夠達到以及超過之前的各種方法,但是總體而言,相對之前的常用方法比如LSTM或者CNN模型,提升幅度不算太大,基本提升幅度在3%到6%之間。
對于文本分類,Bert并未能夠獲得非常大的效果提升,這個結果其實是可以理解的。因為把一個還比較長的文檔分到一個類別里,這種任務偏語言淺層特征的利用,而且指示性的單詞也比較多,應該算是一種比較好解決的任務,任務難度偏簡單,Bert的潛力感覺不太容易發揮出來。
應用領域:序列標注
嚴格地說,序列標注并非一個具體地應用領域,而是NLP中一種問題解決模式。很多NLP任務都可以映射為序列標注問題,比如分詞,詞性標注,語義角色標注等等,非常多。它的一個特點是:對于句子中任意一個單詞,都會有一個對應的分類輸出結果。在原始的Bert論文里面也給出了序列標注任務如何使用Bert的預訓練過程,實際應用的時候,應用模式就是那種模式。
如果不考慮具體應用場景,把不同應用場景映射到序列標注這種問題解決模式的話,目前也有一些工作使用Bert來增強應用效果。
論文《Toward Fast and Accurate Neural Chinese Word Segmentation with Multi-Criteria Learning》

這個工作使用Bert作為多標準分詞的特征抽取器。所謂多標準,是指的同一個語言片段,在不同場景下可能有不同粒度的分詞結果。它使用Bert預訓練的Transformer作為主要特征抽取器,針對不同數據集合可能分詞標準不同,所以在Transformer之上,為每個分詞數據集合構建一個獨有的參數頭,用來學習各自的標準。同時增加一個共享的參數頭,用來捕捉共性的信息。在此之上,再用CRF來做全局最優規劃。這個模型在多個分詞數據集合上取得了最高的分詞效果。不過總體而言,效果提升不太明顯。這也可能與之前的技術方法已經把分詞解決的還比較好,所以基準比較高有關系。
論文《BERT Post-Training for Review Reading Comprehension and Aspect-based Sentiment Analysis》
這個工作做了兩個事情,一個是閱讀理解,另外一個是情感計算。其中情感計算的Aspect Extract任務是采用序列標注的方式做的,利用Bert的預訓練過程后,與之前的最好方法比,效果提升不明顯。
論文《Multi-Head Multi-Layer Attention to Deep Language Representations for Grammatical Error Detection》
這個工作主要解決的應用問題是句法錯誤檢測。把這個問題映射成了序列標注問題,使用Bert預訓練后,效果提升明顯,與基準方法比,性能有大幅度地提高;
上文在談對話系統應用領域時,還提到過一個單輪對話系統利用Bert進行槽位填充的工作,也是映射成序列標注問題來解決的,那個工作結論是兩個數據集合,一個提升2%,一個提升12%。
綜合看,大部分序列標注任務在利用了Bert后,盡管把任務效果都能做到當前最好,但是效果提升幅度,與很多其它領域比,不算大。這可能跟具體的應用領域有關系。
應用領域:其它
除了上面我進行了歸類的Bert應用外,還有零星一些其它領域的Bert應用工作,這里簡單提幾句。
論文《Assessing BERT’s Syntactic Abilities》
這個工作對Bert的句法分析能力做了測試,使用主語-謂語一致性任務做為測試任務。與傳統表現較好的LSTM模型做了對比,測試數據表現Bert效果大幅超過LSTM的效果,當然作者強調因為一些原因這個數據不可直接對比。不過至少說明Bert在句法方面是不弱于或者強于LSTM的。
另外,還有兩篇做NLP to SQL的工作(Achieving 90% accuracy in WikiSQL/ Table2answer: Read the database and answer without SQL),意思是不用你寫SQL語句,而是用自然語言發出命令,系統自動轉化成可執行的SQL語句,使用Bert后,也取得了一定幅度的性能提升。我理解這種任務因為是領域受限的,所以相對容易些,我個人對這個方向也沒啥興趣,所以這里不展開了,感興趣的可以找論文看。
除此外,還有兩篇做信息抽取的工作,使用Bert后,效果也比較一般,這個領域其實是值得深入關注的。
目前已經發表的Bert應用,絕大部分基本都已經被我歸類到上面各個領域里了。這里明確提到的論文,都是我認為有一定參考價值的一部分,并不是全部,我篩掉了一批我認為質量不是太高,或者參考價值不大,或者我認為方法過于復雜的工作,這點還請注意。當然,一定也有一部分有價值的工作,因為沒有進入我狹窄的視野,所以沒有被列入,這也是有可能的。
看我72變:對應用問題的重構
上面介紹了不少NLP領域如何應用Bert提升效果,方法眾多,效果各異,容易讓人看起來眼花繚亂,不太能摸著頭腦。也許你在沒看這些內容之前,腦子里就一個印象:Bert大法好,對NLP各種應用都能有很大性能提升作用。事實是這樣嗎?其實并不是。在你看完上面的內容后,看到了五彩繽紛絢爛多彩的各種方法,可能更容易犯暈,感覺沒啥結論可下,此刻眼里正閃耀著迷茫的光芒……。
其實,這都是表面現象。我在這里總結一下。純個人分析,不保證正確性,猜對算碰巧,猜錯也正常。
盡管看上去有各種各樣不同的NLP任務,其實如何應用Bert,一切答案在原始的Bert論文里,大部分都講到了。其利用Bert的過程是基本一樣的,核心過程都是用Transformer作為特征抽取器,用Bert預訓練模型初始化Transformer的參數,然后再用當前任務Fine-tuning一下,僅此而已。
如果我們再細致一些,分任務類型來看的話,歸納下,結論很可能會是這樣的:
如果應用問題能夠轉化成標準的序列標注問題(分詞/詞性標注/語義角色標注/對話槽位填充/信息抽取等,很多NLP任務可以轉化為序列標注的問題解決形式),或者單句或文檔分類問題(文本分類/抽取式文本摘要可以看成一種帶上下文的單句分類問題),那么可以直接利用Bert的預訓練過程,任務無需特殊改造;目前已有實驗結果,貌似說明在這兩類任務中,使用Bert應該能夠達到最好的效果,但是與之前未采納Bert的最好模型比,多數任務性能提升似乎相對有限。這其中有什么深層的原因嗎?我有個判斷,后面會說;
如果是短文檔的雙句關系判斷任務,比如典型的就是QA/閱讀理解/短文檔搜索/對話等任務,一般利用Bert的方式也是直觀的,就是Bert原始論文中提出的兩個句子間加分隔符輸入的方式,不需要特殊改造。目前看,這類任務,利用Bert后往往性能有大幅度的提升。
但是,為什么你在看上文的時候,會覺得看上去有很多不同的各異的模型呢?主要是因為有些NLP領域,盡管利用Bert的過程其實就是上面的過程,但是需要單獨解決自己任務的一些特點問題,比如搜索領域的長文檔輸入問題怎么解決,搜索領域的粗排序需要有其它方法;對于抽取式摘要來說,輸入輸出如何設計是個問題,因為它和普通的文本分類不太一樣;比如多輪對話系統的歷史信息如何利用,需要有個歷史信息融合或者選擇的方法存在……諸如此類。其實關鍵的應用Bert的部分,并無特殊之處。這一切冥冥中,早已經在原始的Bert論文里講過了。“被酒莫驚春睡重,賭書消得潑茶香,當時只道是尋常。”很多事,不過如此。
經過我此番任性的解釋,此刻,您眼中迷茫的光芒,熄滅了嗎?還是更熾熱了?
貍貓換太子:Fine-tuning 階段的 In Domain 和 Out Domain 問題
如果上面的判斷正確的話,你應該問自己一個問題:“既然看上去貌似Bert更適合處理句子對關系判斷問題。而對于單句分類,或者序列標注問題,盡管有效,但是貌似效果沒那么好。于是,能不能利用下Bert的這一點,怎么利用呢?比如說能不能把單句分類問題,或者序列標注問題,轉化下問題的表達形式,讓它以雙句關系判斷的表現形態出現呢?”
如果你真能問出這個問題,這意味著,你真是挺適合搞前沿研究的。
事實上,已經有些工作是這么做了,而且事實證明,如果能夠對應用問題進行重構的話,其它事情都不用做,就能直接提升這些任務的效果,有些任務效果提升還非常明顯。怎么重構呢?對于某些具備一定特性的NLP任務,如果它看上去是單句分類問題,那么可以通過問題重構,比如引入虛擬句,把單句輸入問題改造成句間關系判斷問題,這樣就能充分發揮Bert的這個特性,直接提升效果。就是這么重構。
論文《 BERT for Aspect-Based Sentiment Analysis via Constructing Auxiliary Sentence》
這個工作來自復旦大學。它利用Bert來優化細粒度的情感分類任務。所謂細粒度的情感分類任務,指的是不僅僅對某個句子或者某個實體的整體情感傾向做個整體判斷,而是對實體的不同方面作出不同的判斷,比如例子“LOCATION1 is often considered the coolest area of London.”,就是說某個實體(這里的例子是某個地點LOCATION 1)的A方面(比如價格price)是怎樣的情感傾向,B方面(比如安全性safety)是怎樣的情感傾向等,細粒度到某個實體的某個方面的情感傾向。
這個工作做得非常聰明,它把本來情感計算的常規的單句分類問題,通過加入輔助句子,改造成了句子對匹配任務(比如上面的例子,可以增加輔助句:“what do you think of the safety of LOCATION 1”)。我們前面說過,很多實驗證明了:Bert是特別適合做句子對匹配類的工作的,所以這種轉換無疑能更充分地發揮Bert的應用優勢。而實驗也證明,經過這種問題轉換,性能有大幅度地提升。
Salesforce也有個類似想法的工作(Unifying Question Answering and Text Classification via Span Extraction),它的部分實驗結果也表明,單句分類任務,通過加入輔助句,轉化成雙句關系判斷任務,也能提升任務效果。
為什么對于Bert應用來說,同樣的數據,同樣的任務,只需要把單句任務轉成句子對匹配任務,效果就突然變好了呢?這個問題其實是個好問題,在后面我會給兩個可能的解釋。
這個方向是值得進一步深入拓展的,目前工作還不多,我預感這里還有很大的潛力可以挖掘,無論是探索還是應用角度,應該都是這樣的。
競爭優勢:Bert擅長做什么?
我們知道,在應用Bert的時候,真正使用某個應用的數據,是在第二階段Fine-tuning階段,通過用手頭任務的訓練數據對Transformer進行訓練,調整參數,將Transformer的參數針對手頭任務進行Fine-tune,之后一般會獲得明顯的應用提升。
這里所謂的In-Domain和Out-Domain問題,指的是:Out-Domain意思是你手頭任務有個數據集合A,但是在Bert的Fine-tuning階段,用的是其它數據集合B。知道了Out-Domain,也就知道In-Domain的意思了,就是說用手頭任務數據集合A去Fine-tune參數,不引入其它數據。
那么問題是:為什么手頭任務是A,要引入數據集合B呢?這個在做具體應用的時候,其實還是比較常見的。如果你手頭任務A的訓練數據足夠大,其實完全可以走In-Domain的路線就夠了。但是如果你手上的任務A訓練數據太小,一般而言,盡管也可以用它去做Bert的Fine-tuning,但是無疑,效果可能有限,因為對于參數規模這么大的Bert來講,太少的Fine-tuning數據,可能無法充分體現任務特點。于是,我們就期待通過引入和手頭任務A有一定相近性的數據集合B,用B或者A+B去Fine-tune Bert的參數,期待能夠從數據集合B Transfer些共性知識給當前的任務A,以提高任務A的效果。某種角度上,這有點像Multi-Task任務的目標。
那么新的問題是:既然我們期待數據集合B能夠遷移些知識給當前任務A,那么這兩個任務或者訓練數據之間必然應該有些共性存在。于是,哪些因素決定了不同性質的數據集合B對當前任務A的影響呢?這個其實是個很實用也很有意思的問題。
目前針對這些問題,也有一些工作和初步的結論。
論文《This Is Competition at SemEval-2019 Task 9: BERT is unstable for out-of-domain samples》
研究了Out-Domain對Target 任務的影響,使用了不同領域的數據,在Fine-tuning階段使用了大約數量為9千左右的電子領域的訓練數據,而Target任務是Hotel領域的。可以看出來,這兩個領域差異還是很大。通過實驗對比,結論是:如果是Out-Domain這種情況,Target任務表現非常不穩定,10輪測試中,Hotel任務的性能最低是0,最高71,方差31。可以看出來,這效果簡直是在蹦極和坐火箭之間頻繁切換。為什么會這樣?目前還沒有解釋。這里是值得深入探討一下的。
從這個工作反向推導,我們可以認為,即使數據B相對手頭任務A來說是Out-Domain的,如果它在領域相似性與手頭任務A越接近,效果理應越好,這個貌似比較直觀好理解,但是這是我的反向推論,并沒看到一些具體研究對此進行對比,這個事情是值得做一下的。
另一個工作是《Simple Applications of BERT for Ad Hoc Document Retrieval》
盡管它是研究信息檢索的,但是也設計了一些跟Out-domain有關的實驗。它驗證了Bert的Fine-tuning階段使用數據的一些特性:在Fine-tuning階段的訓練數據B,與下游任務的數據集合A相比,兩者的任務相關性,相比兩者的文本的外在表現形式的相似性來說,對于下游任務更重要。實驗結論是:對于微博這種下游短文本檢索任務(手頭任務A),盡管它在表現形式上和Trec檢索(Out-Domain數據B)這種新聞文本形式上差異較大,但是因為都是檢索任務,所以相對用QA任務(另外一個Out-Domain數據B)來Finetune Bert來說,效果好,而且好得很明顯。這說明了,對于Out-Domain情況來說,Fine-tuning任務B和下游任務A的任務相似性對于效果影響巨大,我們盡可能找相同或者相近任務的數據來做Fine-tuning,哪怕形式上看上去有差異。
還有一個工作《Data Augmentation for BERT Fine-Tuning in Open-Domain Question Answering》。
它本身是做數據增強的,不過實驗部分的結果,我相信結論也應該能夠遷移到Out-Domain情形,它的結論是:假設有幾個新增的訓練集合,比如B,C,D三個新數據集合,每個和Target任務A的數據差異遠近不同,假設B最遠,C次之,D和A最像。那么如果是這樣的數據,一種做法是把A+B+C+D放到一起去Fine-tune 模型,另外一種是由遠及近地分幾個階段Fine-tune模型,比如先用最遠的B,然后用C,再然后用最近的D,再然后用A,這種叫Stage-wise的方式。結論是Stage-wise模式是明顯效果好于前一種方式的。
另外一點,我相信對于Out-Domain情況來說,如果Fine-tuning任務和下游任務在有相關性的基礎上,無疑應該是數據量越大,對下游任務的正面影響越大。
所以,如果歸納一下目前的研究結論,以及我自己在現有數據基礎上隨意推理的結論,那么結論很可能是這樣子的:對于Out-Domain情況,首選和手頭任務A相同或者相近的任務B來做Fine-tuning,而至于這兩個數據的領域相似性,當然越高越好,而數據規模,也應該是越多越好。如果有多個不同的數據可以用,那么根據它們和手頭任務的相似性,由遠及近地分Stage去Fine-tune模型比較好。當然,這里面有些因素是我個人無依據的推論,實際情況需要實驗證明,所以還請謹慎參考。
這個方向其實是非常有價值的方向,感覺目前的相關工作還是太少,有些問題也沒說清,這里是值得深入摸索找到好的經驗的,因為我們平常經常會遇到任務數據不夠的問題,那么想利用好Bert就比較困難,而如果把這個問題研究透徹,對于很多實際應用會有巨大的參考價值。
淘金記:如何尋找未開墾的Bert應用領域
在看完目前幾乎所有已發表的Bert應用工作后,事實表明,盡管Bert在很多應用領域取得了進展,但是在不同方向上,看上去Bert的引入對于應用效果促進作用是不同的,有些表現突出的領域會有甚至100%的效果提升,有些領域的提升就表現相對平平。于是,我問了自己一個新的問題:為什么會出現這個現象呢?這說明了Bert還是有比較適合它的應用場景的,如果找到特別適合Bert發揮的場景,則性能往往會有極大地提升,但是如果應用場景不能充分發揮Bert的優勢,則雖然也會有些改進,但是改進效果不會特別明顯。
于是,新的問題就產生了:Bert擅長解決具備什么樣特性的NLP任務呢?什么樣的場景更適合Bert去解決?
為了回答這個問題,我對目前的各種工作做了任務對比,并試圖歸納和推理一些結論,目的是希望找出:具備哪些特性的任務是能夠發揮Bert模型的優勢的。分析結果如下,純屬個人判斷,錯誤難免,還請批判性地謹慎參考,以免對您造成誤導。
第一,如果NLP任務偏向在語言本身中就包含答案,而不特別依賴文本外的其它特征,往往應用Bert能夠極大提升應用效果。典型的任務比如QA和閱讀理解,正確答案更偏向對語言的理解程度,理解能力越強,解決得越好,不太依賴語言之外的一些判斷因素,所以效果提升就特別明顯。反過來說,對于某些任務,除了文本類特征外,其它特征也很關鍵,比如搜索的用戶行為/鏈接分析/內容質量等也非常重要,所以Bert的優勢可能就不太容易發揮出來。再比如,推薦系統也是類似的道理,Bert可能只能對于文本內容編碼有幫助,其它的用戶行為類特征,不太容易融入Bert中。
第二,Bert特別適合解決句子或者段落的匹配類任務。就是說,Bert特別適合用來解決判斷句子關系類問題,這是相對單文本分類任務和序列標注等其它典型NLP任務來說的,很多實驗結果表明了這一點。而其中的原因,我覺得很可能主要有兩個,一個原因是:很可能是因為Bert在預訓練階段增加了Next Sentence Prediction任務,所以能夠在預訓練階段學會一些句間關系的知識,而如果下游任務正好涉及到句間關系判斷,就特別吻合Bert本身的長處,于是效果就特別明顯。第二個可能的原因是:因為Self Attention機制自帶句子A中單詞和句子B中任意單詞的Attention效果,而這種細粒度的匹配對于句子匹配類的任務尤其重要,所以Transformer的本質特性也決定了它特別適合解決這類任務。
從上面這個Bert的擅長處理句間關系類任務的特性,我們可以繼續推理出以下觀點:
既然預訓練階段增加了Next Sentence Prediction任務,就能對下游類似性質任務有較好促進作用,那么是否可以繼續在預訓練階段加入其它的新的輔助任務?而這個輔助任務如果具備一定通用性,可能會對一類的下游任務效果有直接促進作用。這也是一個很有意思的探索方向,當然,這種方向因為要動Bert的第一個預訓練階段,所以屬于NLP屆土豪們的工作范疇,窮人們還是散退、旁觀、鼓掌、叫好為妙。
第三,Bert的適用場景,與NLP任務對深層語義特征的需求程度有關。感覺越是需要深層語義特征的任務,越適合利用Bert來解決;而對有些NLP任務來說,淺層的特征即可解決問題,典型的淺層特征性任務比如分詞,POS詞性標注,NER,文本分類等任務,這種類型的任務,只需要較短的上下文,以及淺層的非語義的特征,貌似就可以較好地解決問題,所以Bert能夠發揮作用的余地就不太大,有點殺雞用牛刀,有力使不出來的感覺。
這很可能是因為Transformer層深比較深,所以可以逐層捕獲不同層級不同深度的特征。于是,對于需要語義特征的問題和任務,Bert這種深度捕獲各種特征的能力越容易發揮出來,而淺層的任務,比如分詞/文本分類這種任務,也許傳統方法就能解決得比較好,因為任務特性決定了,要解決好它,不太需要深層特征。
第四,Bert比較適合解決輸入長度不太長的NLP任務,而輸入比較長的任務,典型的比如文檔級別的任務,Bert解決起來可能就不太好。主要原因在于:Transformer的self attention機制因為要對任意兩個單詞做attention計算,所以時間復雜度是n平方,n是輸入的長度。如果輸入長度比較長,Transformer的訓練和推理速度掉得比較厲害,于是,這點約束了Bert的輸入長度不能太長。所以對于輸入長一些的文檔級別的任務,Bert就不容易解決好。結論是:Bert更適合解決句子級別或者段落級別的NLP任務。
也許還有其它因素,不過貌似不如上面四條表現得這么明顯,所以,我先歸納這四項基本原則吧。
新趨勢:Bert能一統NLP的天下嗎
既然我們歸納出Bert擅長做的事情的特點,那么下一步,我們可以按圖索驥,尋找一些目前還沒有人做,但是又特別適合Bert來做的應用領域,然后你可以大施拳腳,拳打腳踢,拳腳相向地去施展自己的才智…。
怎么找這些領域呢?你可以去找找看,哪些應用領域同時符合下面幾個條件中的一個或者幾個,同時符合的條件越多,理論上越適合用Bert去做:
1. 輸入不太長,最好是句子或者段落,避免Bert長文檔的問題;
2.語言本身就能夠很好的解決問題,不依賴其它類型的特征;
3.非生成類任務,避開目前Bert做生成類任務效果不夠好的雷點;
4. 最好是能夠涉及到多句子關系判斷類任務,充分利用Bert 善于做句子匹配任務的特點;
5.最好是能夠牽扯到語義層級的任務,充分利用Bert能夠編碼深層語言知識的優點;
6.如果是單輸入問題,你想想能不能加入輔助句,把它改造成句子匹配型雙輸入任務;
看到這,您可能開始假裝冒充有好奇心地問我了:那到底哪些應用領域符合這些特點呢?……。。嗯,兄弟,你這不是個好奇心問題,實際是個懶漢問題。我請您吃飯,醋都給你準備好了,現在就差餃子了,就看你的了,麻煩您有問這種問題的時間,還是自己去整餃子吧…。。臨淵羨魚不如退而包餃子……。
結語
在Bert出現之前,NLP中不同的應用領域,往往各自使用這個領域有特色的不同的模型,看上去五花八門,差別還是比較大的。例如閱讀理解就是各種花樣的Attention漫天在飛;搜索領域雖然也進入DNN時代了,但是依托的很多還是Learning to rank的框架;文本分類就是典型的LSTM的主戰場……。。
但是隨著Bert的出現,我相信以后這種不同應用領域中,技術手段軍閥混戰,群雄割據的局面不會太持久了,Bert攜預訓練模型之天子令而號諸侯,應該會逐步用一個相對統一的解決方案,統一掉各個NLP應用領域割據的局面,收拾舊山河,朝天闕。這很可能意味著一種NLP新時代的開始,因為歷史上貌似還沒有這么大一統的一個NLP模型存在過。
為什么這么說呢?其實在本文第一個小節的內容你已經應該可以看出這種端倪了,上面涉及了NLP的很多應用領域,雖然說Bert在不同應用領域的促進效果不同,有的大,有的小些,但是幾乎沒有例外的是,都已經比之前各個領域的SOTA方法效果好了,問題無非是好多少而已,而不是好不好的問題。而之前不同領域的SOTA方法,差異是非常大的,尤其是跨領域的時候,你會看到五花八門的技術方案。而這意味著什么呢?意味著起碼在上述領域里,完全可以用Bert的架構和模型,替代掉那個領域的其它所有SOTA方法。而這又意味著什么?意味著“分久必合,合久必分”的歷史規律中,分久必合的時代到了,而引領這個潮流的,就是Bert。這對你來說又意味著什么呢?這意味著你要學的東西比之前少太多了,學習NLP的投入產出性價比急劇提高。你自己拍著胸脯說,這是不是好事?哎,沒讓你拍別人胸脯啊,兄弟……。。
而隨著逐漸對Bert本身能力的各種增強,很可能這種統一的步伐會越來越快。我估計這個時間應該在未來1年到2年,很可能大多數NLP子領域都會被統一到Bert兩階段+Transformer特征抽取器的方案框架上來。而我認為這是非常好的事情,因為大家可以把精力投入到增強基礎模型的能力,只要基礎模型能力有提升,意味著大多數應用領域的應用效果會直接獲得提升,而不用一個領域一個領域個性化地想方案去啃,那樣效率有點低。
是否真的會發生這一幕?NLP覆蓋這么廣泛子方向的科研范圍,它允許這么牛X模型的存在嗎?讓我們拭目以待。
當然,對此我個人持樂觀態度。
這次先這樣吧,連我自己都覺得太長了,看到最后一句的同學,我為你的好學和耐心點個贊……。不過請你換位思考一下,你用看完這篇文章的時間估算一下,我寫這篇文章要花多少時間?……另外,其實最近一陣子我心情并不是太好,不過,還是得想法設法編些段子來逗您笑……。寫完這些AI的文章,我技術水平沒見提高,不過轉型段子手的可能性確實大多了 ……。李誕,你給我等著……。
說起來都是淚,其實也無所謂。很多事,不過如此。
-
nlp
+關注
關注
1文章
489瀏覽量
22049
原文標題:Bert時代的創新:Bert在NLP各領域的應用進展 | 技術頭條
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
柔性測試技術的應用領域
光耦的應用領域
LLM模型的應用領域
虛擬現實技術的應用領域有哪些
超級電容器應用領域有哪些?








 工商網監
工商網監
評論