 TensorFlow再填新功能!谷歌宣布推出TensorFlow.Text
TensorFlow再填新功能!谷歌宣布推出TensorFlow.Text
谷歌發布TensorFlow優化新功能TF.Text庫,可對語言文本AI模型進行周期性預處理,大大節約了AI開發者對文本模型的訓練時間,簡化訓練流程。
TensorFlow再填新功能!
谷歌宣布推出TensorFlow.Text,這是一個利用TensorFlow對語言文本模型進行預處理的庫。TF官博第一時間發布了更新消息,并對TF.Text的新功能和特性進行了簡要介紹。
TensorFlow一直以來致力于為用戶提供更廣泛的選擇,幫助用戶利用圖像和視頻數據構建模型。但是,許多模型是以文本開頭的,從這些模型構建的語言模型需要進行一些預處理,才能將文本輸入到模型中。比如關于使用IMDB數據集的文本分類教程,就是從已經轉換為整數ID的文本數據開始入手的。
如果模型訓練和推理的時間不一樣,在訓練過程以外完成的預處理可能會和模型產生偏差,這就需要額外投入更多的時間和精力對預處理的過程進行協調。
TensorFlow本次推出的TF.Text就是為了解決這個問題,TF.Text是一個TensorFlow 2.0庫,可以使用PIP命令輕松安裝。它可以在基于文本的模型中定期執行這些預處理過程,并提供TensorFlow核心組件中并未提供的、關于語言建模的更多功能和操作。
其中最常見的功能就是文本的詞條化(tokenization)。詞條化是將字符串分解為token的過程。這些token可能是單詞、數字和標點符號,或是上述幾種元素的組合。
TF.Text的Tokenizer使用RaggedTensors,這是一種用于識別文本的新型張量。
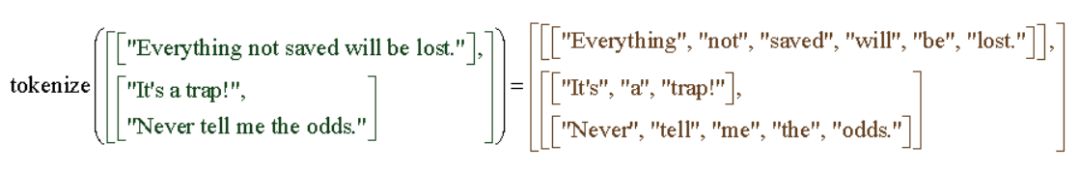
三個新的Tokenizer,系統解決文本AI模型預訓練問題
TF.Text提供了三個新的tokenizer。其中最基本的是空白tokenizer,可以在ICU定義的空白字符(例如空格,制表符,換行符)上拆分UTF-8字符串。
tokenizer=tensorflow_text.WhitespaceTokenizer()tokens = tokenizer.tokenize(['everything not saved will be lost.', u'Sad?'.encode('UTF-8')])print(tokens.to_list())
[['everything', 'not', 'saved', 'will', 'be', 'lost.'], ['Sadxe2x98xb9']]
此次發布的初始版本還包括一個面向unicode腳本的tokenizer,可以根據Unicode腳本邊界拆分UTF-8字符串。值得注意的是,它和空白tokenizer很類似,最明顯的區別在于后者可以從標準文本(如USCRIPT_LATIN,USCRIPT_CYRILLIC等)中分割出標點符號。
tokenizer = tensorflow_text.UnicodeScriptTokenizer()tokens = tokenizer.tokenize(['everything not saved will be lost.', u'Sad?'.encode('UTF-8')])print(tokens.to_list())
[['everything', 'not', 'saved', 'will', 'be', 'lost', '.'], ['Sad', 'xe2x98xb9']]
TF.Text中提供的最后一個tokenizer是一個Wordpiece tokenizer。這是一個無監督的tokenizer,需要一個預先確定的詞匯表,進一步將token分成子詞(前綴和后綴)。Wordpiece常用于谷歌的BERT模型。
def_CreateTable(vocab,num_oov=1): init = tf.lookup.KeyValueTensorInitializer( vocab, tf.range(tf.size(vocab, out_type=tf.int64), dtype=tf.int64), key_dtype=tf.string, value_dtype=tf.int64) return tf.lookup.StaticVocabularyTable( init, num_oov, lookup_key_dtype=tf.string)vocab_table = _CreateTable(["great", "they", "the", "##'", "##re", "##est"])tokens = [["they're", "the", "greatest"]]tokenizer = tensorflow_text.WordpieceTokenizer( vocab_table, token_out_type=tf.string)result = tokenizer.tokenize(tokens)print(result.to_list())
[[['they', "##'", '##re'], ['the'], ['great', '##est']]]
每個Tokenizer都在UTF-8編碼的字符串上進行標記,并提供了將字節偏移量轉換為原始字符串的選項。調用者可以了解創建的token的原始字符串中的字節對齊。
此外,TF.Text庫還包括歸一化、n-gram和標記序列約束等功能。
新功能組件密集發布,TensorFlow大家庭日益完善
有關更深入的實例,可以查看Colab notebook內容,其中包含許多本文中未討論的新的可用操作的各種代碼段。未來計劃繼續提供更多新工具,讓使用TensorFlow構建語言模型變得更加方便。
今年上半年,谷歌陸續發布了多個基于TensorFlow的新功能和新組件。5月,谷歌發布TensorFlow Graphics,讓機器學習與圖形和3D模型的關系更加密切。今年3月,谷歌發布旨在增強隱私保護的終端設備機器學習方法TensorFlow Federated。此外,TensorFlow框架面向JavaScript和iOS開發者的版本TensorFlow.js和TensorFlow Swift也于今年春天發布。
-
谷歌
+關注
關注
27文章
6171瀏覽量
105496 -
模型
+關注
關注
1文章
3254瀏覽量
48894 -
tensorflow
+關注
關注
13文章
329瀏覽量
60537
原文標題:TensorFlow官宣新功能TF.Text:攻克語言AI模型預處理偏差難題
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
第四章:在 PC 交叉編譯 aarch64 的 tensorflow 開發環境并測試
如何在Tensorflow中實現反卷積
TensorFlow是什么?TensorFlow怎么用?
使用TensorFlow進行神經網絡模型更新
tensorflow和pytorch哪個更簡單?
tensorflow和pytorch哪個好
tensorflow簡單的模型訓練
keras模型轉tensorflow session
如何使用Tensorflow保存或加載模型
TensorFlow的定義和使用方法
TensorFlow與PyTorch深度學習框架的比較與選擇
谷歌模型框架是什么軟件?谷歌模型框架怎么用?
基于TensorFlow和Keras的圖像識別







 工商網監
工商網監
評論