 如何使用50行Python代碼實現AI的動作平衡
如何使用50行Python代碼實現AI的動作平衡
本文將為大家展示如何通過 Numpy 庫和 50行 Python 代碼,使用標準的 OpenAI Gym平臺創建智能體 (agent),就教會機器處理推車桿問題 (cart pole problem),保持平衡。
推車桿問題 (cart pole problem),大家可以類比好像在手指尖上垂直平衡鉛筆一樣,需要通過左右推動來平衡車頂部的桿,這是個非常具有挑戰性的問題!
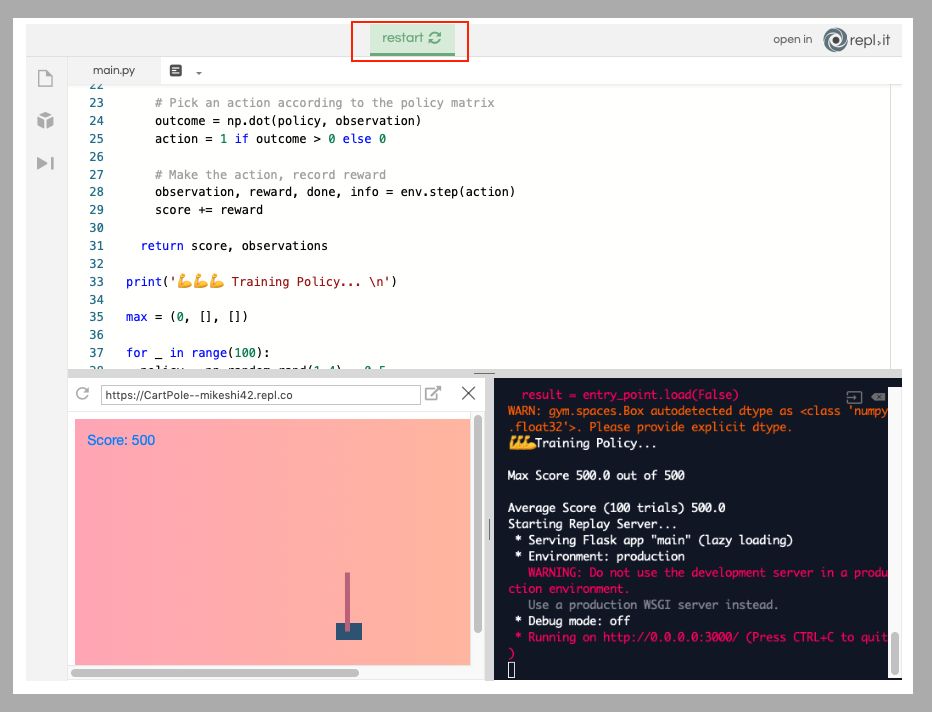
今天,我們不過多的討論強化學習的基礎理論,希望大家在下面的編譯器里,不斷嘗試,體會這個項目。一開始,大家只需要點擊“Start”,開始配置需要的環境即可。
快速入門強化學習 (RL)
如果你是機器學習或強化學習領域的新人,先了解一下下面的一些基礎知識和術語,為后面做鋪墊。如果你已經掌握了基礎知識,那可以跳過這部分內容。
強化學習
強化學習旨在教會我們的智能體 (算法或機器) 執行特定的任務或動作,而無需顯式地告訴它該如何做。想象一個嬰兒在隨機抬動自己的腿,當站立起來時就給予他一個獎勵。同樣地,智能體的目標是在其生命周內最大化獎勵值,而獎勵取決于特定的任務。比如寶寶站立這個例子,站立時給予獎勵記為1,否則記為0。
AlphaGo 就是一個典型的強化學習智能體例子,教會智能體如何玩游戲并最大化其獎勵 (即贏得游戲)。而在本文中就將創建一個智能體,教它如何通過左右推動推車來解決推車上的桿平衡問題。
狀態
狀態即當前游戲的樣子,通常用數字來表示。在乒乓球比賽中,它可能是每個球拍與x、y坐標軸的垂直位置或者是乒乓球的速度。在推車桿的情況下,這里的狀態由4個數字組成:即推車的位置,推車的速度,桿的位置 (作為角度) 和桿的角速度。這4個數字作為向量 (或數組) 提供給智能體,這非常重要:將狀態作為一組數字意味著智能體能夠對它進行一些數學運算,以便決定如何根據狀態來采取什么行動。
策略
策略是一種可以處理游戲狀態的函數 (例如棋盤的位置或者推車和桿的位置), 并輸出智能體在該位置應該采取的動作 (例如移動或將推車推到左邊)。在智能體采取相應的操作后,游戲將以下一個狀態更新,此時將再次根據其輸入策略做出決策,這個過程一直持續到游戲達到某個終止條件時結束。策略同樣是個非常關鍵的因素,因為它反映了是智能體背后的決策能力,這也是我們所需要認真考慮的。
點積 (dot product)
兩個數組 (向量) 之間的點積可以簡單理解為,將第一個數組的每個元素乘以第二個數組的對應元素,并將它們全部加在一起。假設想要計算數組 A 和 B 的點積,形如 A[0]*B[0]+A[1]*B[1] ......隨后將使用此運算結果再乘以一個狀態 (同樣是一個向量) 和一個策略值 (同樣也是一個向量)。這部分內容將在下一節詳細介紹。
制定策略
為了解決推車游戲,我們希望所設計的機器學習策略能夠贏得游戲或最大化游戲獎勵。對于智能體而言,這里將接收4維數組所表示策略,每一維代表每個組成的重要性 (推車的位置,桿位等四個組成)。隨后,再將點積的結果與策略、狀態向量進行處理并輸出最終的結果。根據結果的正負值決定是向左還是向右推動推車。這聽起來可能有點抽象,下面就通過一個具體的例子,來看看整個過程將發生什么。
假設推車在游戲中靜止地處在中間位置,當桿向右傾斜時車也將向右傾斜,如下圖這樣:
所對應的的狀態如下圖所示:
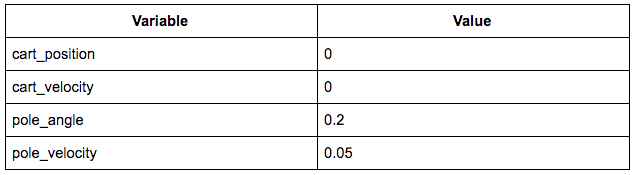
此時的狀態向量為 [0, 0, 0.2, 0.05]。直觀地說,現在我們想要將推車推向右側,并將桿拉直。這里通過訓練中得到了一個很好的策略,即 [-0.116, 0.332, 0.207, 0.352]。將上面的狀態向量與策略向量進行點積處理,如果得到的結果為正,則將推車向右推動;反之則向左推動。

顯然,這里的輸出是個正數,這意味著在這種策略下智能體將推車向右推動,這也正是我們想要的結果。那么,該如何得到這個策略向量呢,以便智能體能夠朝著我們希望的方向推動?或者說如果隨機選擇一個策略,那么智能體又該如何行動呢?
開始編輯
在該項目主頁 repl.it 上彈出一個 Python 實例。repl.it允許用戶快速啟動大量不同編程環境的云實例環境并在強大云編譯器 (IDE) 中編輯代碼,這個強大的 IDE 能在任何地方訪問,如下圖所示。

安裝所需的包
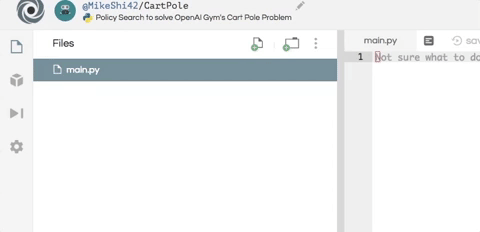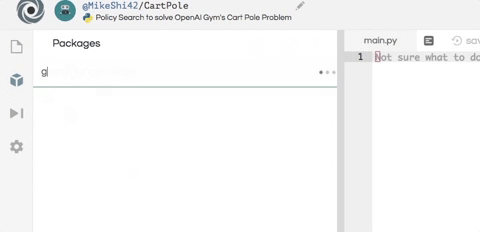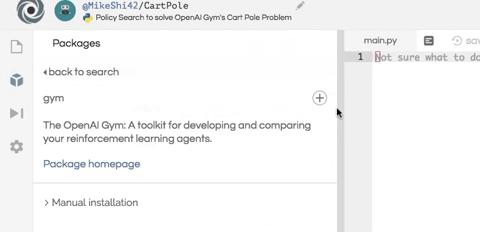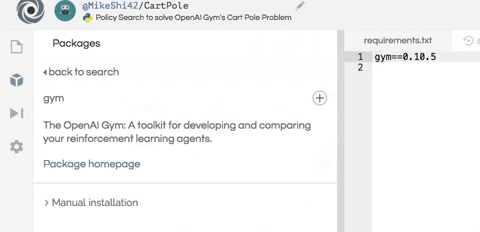
安裝這個項目所需的兩個軟件包:numpy 用于幫助數值計算,而 OpenAI Gym 則作為智能體的模擬器。如下圖所示,只需在編輯器左側的包搜索工具中輸入 gym 和 numpy,然后單擊加號按鈕即可安裝這兩個包。
創建基礎環境
這里首先將剛安裝的兩個依賴包導入到 main.py 腳本中并設置一個新的 gym環境。隨后定義一個名為 play 的函數,該函數將被賦予一個環境和一個策略向量,在環境中執行策略向量并返回分數以及每個時間步的游戲觀測值。最后,將通過分數高低來反映策略的效果好壞,以及在單次游戲中策略的表現。如此,就可以測試不同的策略,查看他們在游戲中的表現!
import gymimport numpy as npenv = gym.make('CartPole-v1')
下面從函數定義開始,將游戲重置為開始狀態,如下所示。
defplay(env,policy): observation = env.reset()
接著初始化一些變量,用來跟蹤游戲是否達到終止條件,策略得分以及游戲中每個步驟的觀測值,如下所示。
done = False score = 0observations=[]
現在,只需要一些時間步來開始游戲,直到 gym 提示游戲結束為止。
for _ in range(5000): observations += [observation.tolist()] # Record the observations for normalization and replay if done: # If the simulation was over last iteration, exit loop break # Pick an action according to the policy matrix outcome = np.dot(policy, observation) action = 1 if outcome > 0 else 0 # Make the action, record reward observation, reward, done, info = env.step(action) score += rewardreturnscore,observations
如下,這部分的代碼主要是用于開始游戲并記錄結果,而與策略相關的代碼就是這兩行:
outcome=np.dot(policy,observation) action = 1 if outcome > 0 else 0
在這里所做的只是對策略向量和狀態 (觀測) 數組之間進行點積運算,就像在之前具體例子中所展現的那樣。隨后根據結果的正負,選擇1或0 (向左或右) 的動作。到這里為止,main.py 腳本如下所示:
import gymimport numpy as npenv = gym.make('CartPole-v1')def play(env, policy): observation = env.reset() done = False score = 0 observations = [] for _ in range(5000): observations += [observation.tolist()] # Record the observations for normalization and replay if done: # If the simulation was over last iteration, exit loop break # Pick an action according to the policy matrix outcome = np.dot(policy, observation) action = 1 if outcome > 0 else 0 # Make the action, record reward observation, reward, done, info = env.step(action) score += reward return score, observations
下面開始尋找該游戲的最優策略!
第一次游戲
現在已經有了一個函數,用來反映策略的好壞。因此,接下來要做的事開始制定一些策略,并查看他們的表現如何。如果一開始你想嘗試一些隨機的策略,那么這些策略的結果將會怎樣呢?這里使用 numpy 來隨機生成一些的策略,這些策略都是4維數組或1x4矩陣,即選擇4個0到1之間的數字作為游戲的策略,如下所示。
policy = np.random.rand(1,4)
有了這些策略以及上面所創建的環境,下面就可以開始游戲并獲得策略分數:
score, observations = play(env, policy)print('Policy Score', score)
只需點擊運行即可開始游戲,它將輸出每個策略所對應的得分,如下所示。
最后,所有的策略獲得的最高得分為500,在這里隨機生成的策略可能并不能得到太好的結果,而且通過隨機生成的方式,很難解釋智能體是如何進行游戲的。下一步將介紹如何選擇并設置游戲的策略,來查看智能體的游戲表現。
觀察我們的智能體
這里使用 Flask 來設置輕量級服務器,以便可以在瀏覽器中查看智能體的表現。 Flask 是一個輕量級的 Python HTTP 服務器框架,可以為 HTML UI 和數據提供服務。由于渲染和 HTTP 服務器背后的細節對智能體的訓練并不重要,在這里只是簡單介紹下。首先需要將 Flask 安裝為 Python 包,就像上面安裝 gym 和 numpy 包一樣,如下所示。
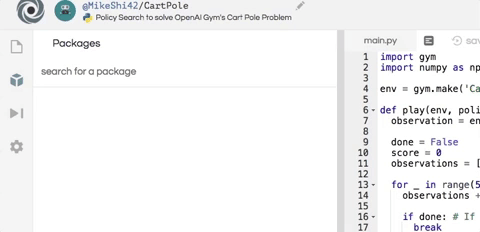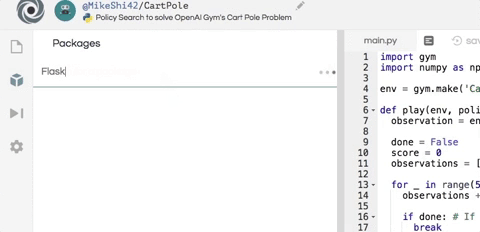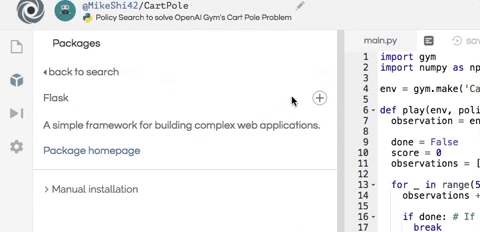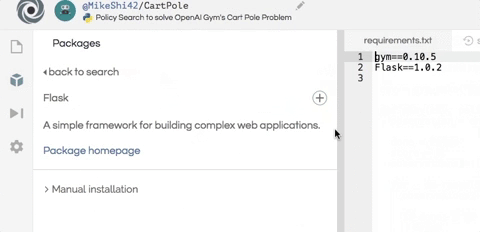
接下來,在腳本的底部創建一個 flask 服務器,它將在 /data 端點上公開游戲的每個幀的記錄,并在 / 上托管 UI,如下所示。
from flask import Flaskimport jsonapp = Flask(__name__, static_folder='.')@app.route("/data")def data(): return json.dumps(observations)@app.route('/')def root(): return app.send_static_file('./index.html')app.run(host='0.0.0.0', port='3000')
此外,還需要添加兩個文件:一個是項目的空白 Python 文件,這是 repl.it 用于檢測 repl 是處于評估模式還是項目模式的關鍵。這里只需使用新文件按鈕添加空白的 Python 腳本即可。隨后,還需要創建一個將承載渲染 UI 的 index.html 文件。在此不需要深入了解這部分的內容,只需將此 index.html 上傳到 repl.it 項目即可。
好了,現在的項目目錄應該像這樣,如下所示:
有了這兩個新文件,當運行 repl 時它將回放所選擇的游戲策略,便于我們尋找一個最優的策略。

策略搜索
在第一次游戲中只是通過 numpy 為智能體隨機生成一些策略并開始游戲。那么,如何選擇一些游戲策略,并在游戲結束時只保留那個結果最好的策略呢?在這里,制定游戲時并不只是生成一個策略,而是通過編寫一個循環來生成一些策略,跟蹤每個策略的執行情況并在最后保存最佳的策略。
首先創建一個名為 max 的元組,它將存儲游戲過程所出現的最佳策略得分、觀測和策略數組,如下所示。
max = (0, [], [])
接下來將生成并評估10個策略,并將得分最大值的策略保存。此外,這里還需要在 /data 端點返回最佳策略的重放,如下所示。
for _ in range(10): policy = np.random.rand(1,4) score, observations = play(env, policy) if score > max[0]: max = (score, observations, policy)print('Max Score', max[0])
此外,這個端點:
@app.route("/data")def data(): return json.dumps(observations)
應改為:
@app.route("/data")def data(): return json.dumps(max[1])
最后 main.py 腳本應像這樣,如下圖所示:
import gymimport numpy as npenv = gym.make('CartPole-v1')def play(env, policy): observation = env.reset() done = False score = 0 observations = [] for _ in range(5000): observations += [observation.tolist()] # Record the observations for normalization and replay if done: # If the simulation was over last iteration, exit loop break # Pick an action according to the policy matrix outcome = np.dot(policy, observation) action = 1 if outcome > 0 else 0 # Make the action, record reward observation, reward, done, info = env.step(action) score += reward return score, observationsmax = (0, [], [])for _ in range(10): policy = np.random.rand(1,4) score, observations = play(env, policy) if score > max[0]: max = (score, observations, policy)print('Max Score', max[0])from flask import Flaskimport jsonapp = Flask(__name__, static_folder='.')@app.route("/data")def data(): return json.dumps(max[1])@app.route('/')def root(): return app.send_static_file('./index.html')app.run(host='0.0.0.0', port='3000')
如果現在運行 repl,正常情況所得到的最大分數應為500。如果沒有的話,請再次嘗試運行 repl! 通過這種方式,能夠完美地觀察游戲策略是如何讓桿達到平衡的!
如何加速?
(1)這里智能體達到平衡的速度并不夠塊。回想前面制定策略時,首先只是在0到1范圍內隨機創建了策略數組,這恰好是有效的。但如果這里智能體翻轉大于運算符所設定的那樣,那么可能將看到災難性的失敗結果。可以嘗試將 action> 0 if outcome>0 else 0 改為 action=1 if outcome<0 else 0。
效果似乎并沒有很明顯,這可能是因為如果恰好選擇少于而不是大于,那么可能永遠也找不到解決游戲的策略。為了緩解這種情況,在實際操作時也應該生成一些帶負數的策略。雖然這將使得搜索一個好策略的過程變得更加困難 (因為包含許多負的策略并不好),但所帶來的好處是不再需要通過特定算法來匹配特定游戲。如果嘗試在 OpenAI gym 的其他環境中這樣做,那么算法肯定會失敗。
要做到這一點,不能使用 policy = np.random.rand(1,4),需要將改為 policy = np.random.rand(1,4) -0.5。如此,所生成的策略中每個數字都在-0.5到0.5之間,而不是0到1。但是由于這樣做會使得最優策略的搜索過程變得困難,因此在上面的 for 循環中,不要迭代10個策略,更改這部分的代碼嘗試搜索100個策略 (for _ in range (100):)。當然,你也可以先嘗試迭代10次,看看用負的策略獲得最優策略的困難性。
好了,現在的 main.py 腳本可參考
https://gist.github.com/MikeShi42/e1c5551bbf2cb2064da962ad8b198c1b
如果現在運行 repl,無論使用的是否大于或小于,仍然可以找到一個好的游戲策略。
(2)不僅如此,即使所生成的策略可能能夠在一次游戲中得到最高分500的結果,那它能夠在每次游戲中都有這樣的表現呢?當生成100個策略并選擇在單次運行中表現最佳的策略時,該策略可能只是單次最佳策略,或者它可能是一個非常糟糕的策略,只是恰好在一次游戲中有非常好的性能。因為游戲本身具有隨機性 (如起始位置每次都不同),因此策略可以只是在一個起始位置表現良好,而不是在其他位置。
因此,為了解決這個問題,需要評估一個策略在多次實驗中的表現。現在就采取之前實驗得到的最佳政策,查看它在100次游戲實驗中的表現。在這里對最優策略進行100次游戲 (最大索引值為2) 并記錄每次的游戲得分。隨后使用 numpy 計算該策略的平均分數并將其打印到終端。你可能會注意到,最佳的游戲策略實際上并不一定是最優秀的。
總結
好了,以上已經成功創建了一個能夠非常有效地解決推車桿問題的 AI 智能體。當然它還有很大的改進空間,這將是后續系列文章的一部分。此外,后續的工作還可以對一些問題展開研究:
尋找“真正的”最優策略 (即在100次獨立游戲中表現良好)
優化最佳策略搜索所需的次數 (即樣本效率問題)
選擇正確搜索策略,而不是嘗試隨機地選擇。
在其他的環境中創建。
-
AI
+關注
關注
87文章
30728瀏覽量
268891 -
編譯器
+關注
關注
1文章
1623瀏覽量
49108 -
python
+關注
關注
56文章
4792瀏覽量
84628
原文標題:50行代碼教AI實現動作平衡 | 附完整代碼
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
分享50條經典的Python一行代碼
淺談SMOTE算法 如何利用Python解決非平衡數據問題
python代碼示例之基于Python的日歷api調用代碼實例







 工商網監
工商網監
評論