") 深度學(xué)習(xí)的最大短板原來是它!
深度學(xué)習(xí)的最大短板原來是它!
上文用簡單的小學(xué)數(shù)學(xué)算了一下Alexnet的參數(shù)說需要的內(nèi)存空間,但對于運(yùn)行的神經(jīng)網(wǎng)絡(luò),還有一個(gè)運(yùn)行時(shí)的資源的問題。在github上的convnet-burden上有一個(gè)feature memory[1]的概念,這個(gè)和輸入的圖片的大小和運(yùn)算的batch的size 都有關(guān)。
因此,Nvida的GPU上的HBM和GDDR對于大部分神經(jīng)網(wǎng)絡(luò)的煉丹師都是非常重要,能夠在一個(gè)GPU的內(nèi)存里完成模型的運(yùn)算而不用考慮換進(jìn)換出是大有裨益的。
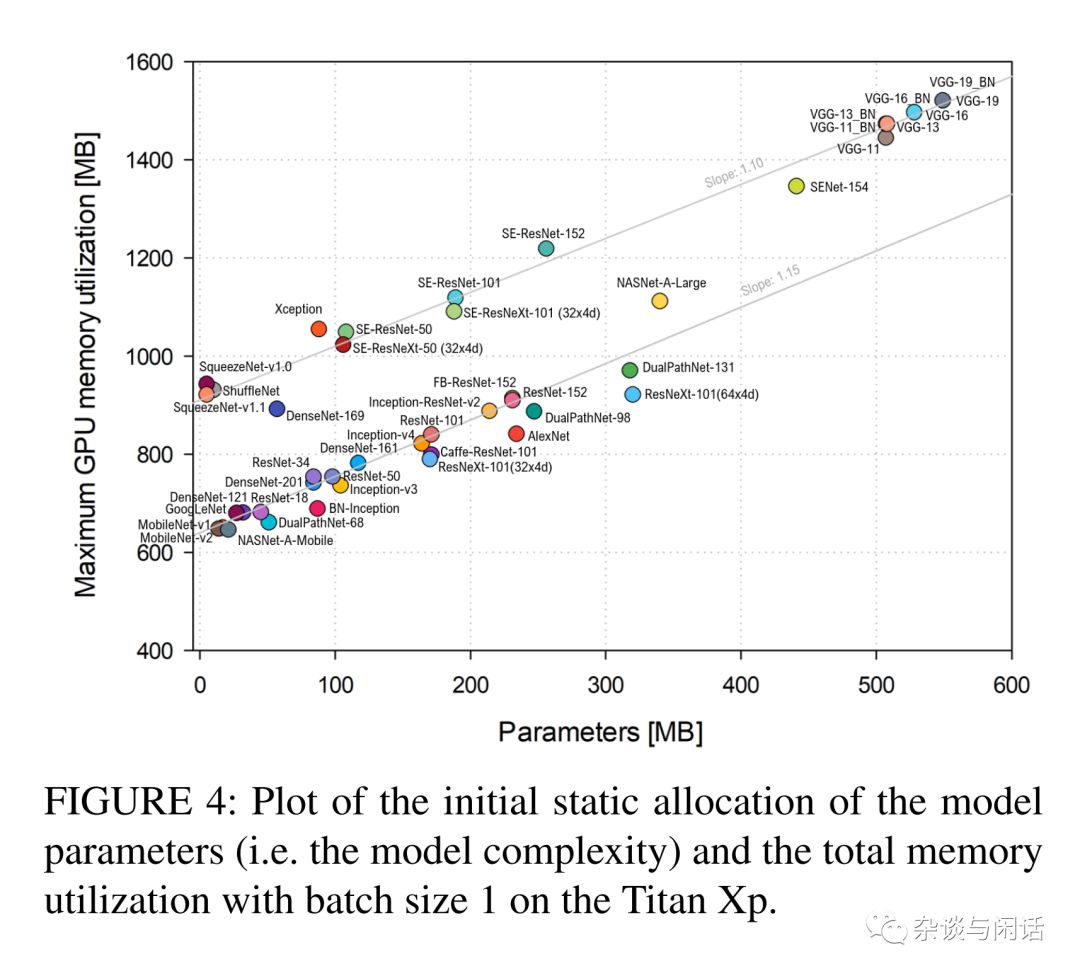
總體來說,這個(gè)統(tǒng)計(jì)還是很直觀的[2],就是網(wǎng)絡(luò)模型越復(fù)雜,參數(shù)的規(guī)模越大,資源的占用也就越多,對GPU的整體內(nèi)存占用也是越多。因此如何在有限的GPU上完成模型的訓(xùn)練也成了一個(gè)非常有用的技巧。
在我們考慮計(jì)算對于內(nèi)存帶寬的需求之前,我們需要復(fù)習(xí)一下作為一個(gè)神經(jīng)網(wǎng)絡(luò),每一層對于計(jì)算的需求,這個(gè)還是可以用小學(xué)數(shù)學(xué)搞定的東西。還是用標(biāo)準(zhǔn)的Alexnet為例。
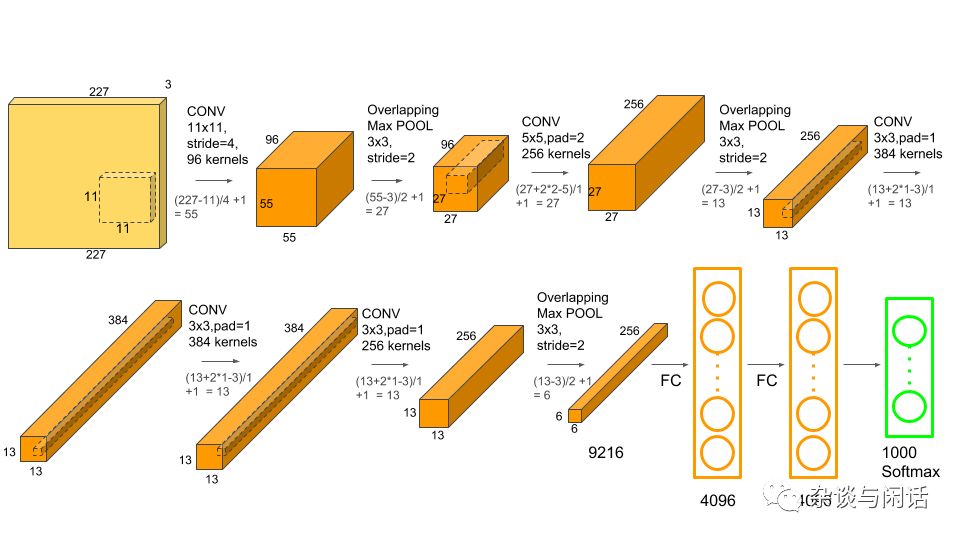
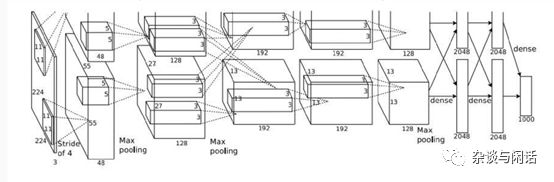
對于計(jì)算來講,卷積層應(yīng)該是主要,對于Pooling來講,應(yīng)該是沒有的,對于FC來講,也是比較簡單的。基本上是乘法.
Conv Layer的計(jì)算復(fù)雜度:
1. 當(dāng)前的層的圖片的width
2. 當(dāng)前的層的圖片的height
3.上一層的深度
4。當(dāng)前層的深度
5. 當(dāng)前kernel的大小
的乘積就是這一層卷積的計(jì)算復(fù)雜度。以Alexnet的conv1為例:
Conv-1:第一層的卷積有96個(gè)kernel。kernel的大小是11X11,卷積的stride是4,padding是0
當(dāng)前的輸出的是55X55,上一層的input的深度是3, 當(dāng)前的kernel是11X11,當(dāng)前的深度是96.因此
55X55X3X11X11X96=105,415,200次MAC的計(jì)算。
對于Alexnet來講,需要注意的是conv2,4 ,5三個(gè)層的計(jì)算沒有和上一層直接跨GPU,因此需要的計(jì)算規(guī)模上/2.
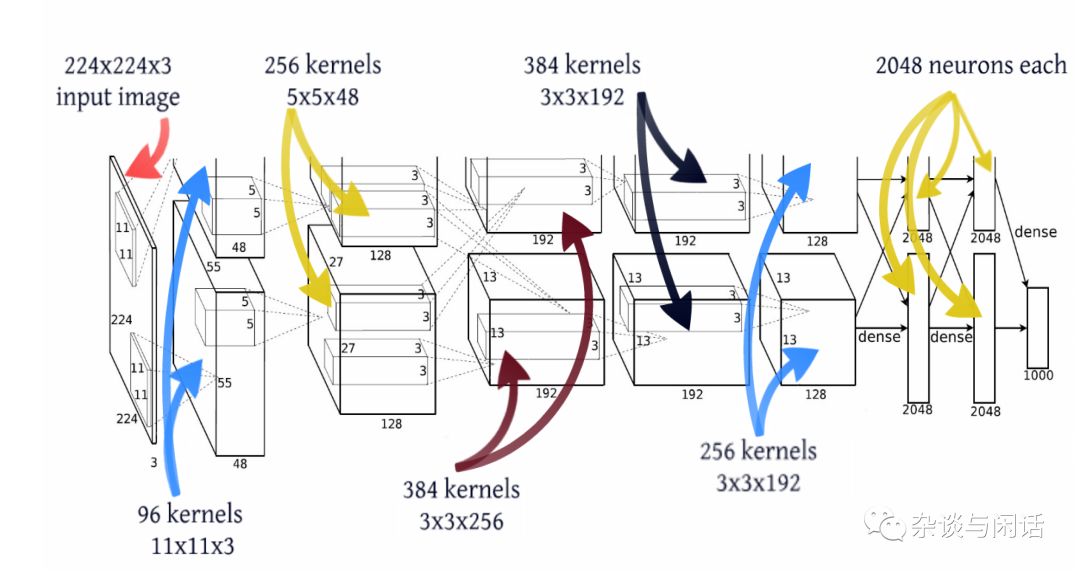
對于FC來講,比較粗略的計(jì)算就是 輸入和當(dāng)前層的規(guī)模的乘積。
MaxPool-3:第五層卷積的最大值,Pooling是3X3, stride是2,
FC-1:第一個(gè)全連接層,有4096個(gè)神經(jīng)元
因此FC-1 的計(jì)算就是:
6X6X256X4096=37,748,736
因此,總結(jié)一下之前的參數(shù)信息和計(jì)算量, Alexnet的圖如下:

這個(gè)通過統(tǒng)計(jì)每一層的計(jì)算的復(fù)雜度,就可以得到整個(gè)網(wǎng)絡(luò)的計(jì)算復(fù)雜度,也就是訓(xùn)練一次網(wǎng)絡(luò)需要多少的MACC資源。對于alexnet 來講就是:724,406,816 次操作。
這個(gè)時(shí)候,有一個(gè)關(guān)鍵的信息就出來了。就是芯片的能力,大家都是用TFLOPs來表示芯片的浮點(diǎn)處理能力。對于Nvida的芯片,有了TFLOPS,有個(gè)一個(gè)網(wǎng)絡(luò)需要的計(jì)算量,我們就可以很快計(jì)算出每一層計(jì)算需要的時(shí)間了。
對于Alexnet 的conv1 來講,在Nivida 最新的V100的120TFLOPs的GPU上,進(jìn)行訓(xùn)練的執(zhí)行時(shí)間差不多是105,415,200X2/(120X1,000,000,000,000), 約等于1.75us (微秒)。
對于Pooling這一層來講,因?yàn)闆]有MACC的計(jì)算量,但是因?yàn)橐狹ax Pooling,也需要大小比較的計(jì)算。因此,它的計(jì)算基本就是算是數(shù)據(jù)讀取。因此它的數(shù)據(jù)讀取是 conv-1 的55X55X96=290,440. 因此在同樣的GPU下,它的執(zhí)行時(shí)間就是 2.42ns.
好了,有了計(jì)算時(shí)間,現(xiàn)在需要來計(jì)算數(shù)據(jù)量了。對于Conv1來講,它包含了對一下數(shù)據(jù)的讀寫:
對于輸入數(shù)據(jù)的讀取 227X227X3 =154,587
對于輸出數(shù)據(jù)的寫入55x55x96=290,400
對于參數(shù)的讀取34848+96=34944
因此,就可以算出對于120TFLOP的GPU的要求:因?yàn)樵诤芏?a target="_blank">ASIC芯片中,輸入輸出可能在DDR中,但是參數(shù)可能放在SRAM中,因此我們就分開計(jì)算了。
對于輸入數(shù)據(jù)的讀取 (154,587/1.75)X1000,000X4=351.95GB/s
對于輸出數(shù)據(jù)的寫入 (290,400/1.75)X1000,000X4=661.16GB/s
對于參數(shù)的讀取 (34944 /1.75)X1,000,000X4=79.34GB/s
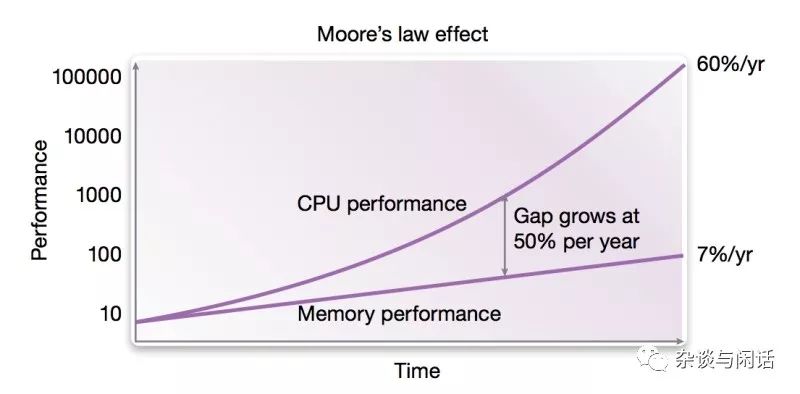
提個(gè)醒,我們現(xiàn)在的PC服務(wù)器上性能最高的DDR4的帶寬基本上在19GB/s左右。看到壓力了吧。現(xiàn)在的memory連很慢的CPU都跟不上。更何況老黃家的核彈。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4994瀏覽量
103153 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5504瀏覽量
121221
原文標(biāo)題:芯片架構(gòu)師終于證明:深度學(xué)習(xí)的最大短板原來是它!
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
NPU在深度學(xué)習(xí)中的應(yīng)用
GPU深度學(xué)習(xí)應(yīng)用案例
激光雷達(dá)技術(shù)的基于深度學(xué)習(xí)的進(jìn)步
AI大模型與深度學(xué)習(xí)的關(guān)系
深度學(xué)習(xí)中的時(shí)間序列分類方法
深度學(xué)習(xí)中的無監(jiān)督學(xué)習(xí)方法綜述
深度學(xué)習(xí)與nlp的區(qū)別在哪
深度學(xué)習(xí)中的模型權(quán)重
深度學(xué)習(xí)常用的Python庫
深度學(xué)習(xí)模型訓(xùn)練過程詳解
深度學(xué)習(xí)與傳統(tǒng)機(jī)器學(xué)習(xí)的對比
深度解析深度學(xué)習(xí)下的語義SLAM

為什么深度學(xué)習(xí)的效果更好?

【技術(shù)科普】主流的深度學(xué)習(xí)模型有哪些?AI開發(fā)工程師必備!

什么是深度學(xué)習(xí)?機(jī)器學(xué)習(xí)和深度學(xué)習(xí)的主要差異






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論