 深度學習不是萬靈藥 神經網絡3D建模其實只是圖像識別
深度學習不是萬靈藥 神經網絡3D建模其實只是圖像識別
隨著深度學習的大熱,許多研究都致力于如何從單張圖片生成3D模型。但近期一項研究表明,幾乎所有基于深度神經網絡的3D中重建工作,實際上并不是重建,而是圖像分類。深度學習并不是萬能的!
深度學習并不是萬靈藥。
近幾年,隨著深度學習的大熱,許多研究攻克了如何從單張圖片生成3D模型。從某些方面似乎再次驗證了深度學習的神奇——doing almost the impossible。
但是,最近一篇文章卻對此提出了質疑:幾乎所有這些基于深度神經網絡的3D重建的工作,實際上并不是進行重建,而是進行圖像分類。
arXiv地址:
https://arxiv.org/pdf/1905.03678.pdf
在這項工作中,研究人員建立了兩種不同的方法分別執行圖像分類和檢索。這些簡單的基線方法在定性和定量上都比最先進的方法產生的結果要更好。
正如伯克利馬毅教授評價:
幾乎所有這些基于深度神經網絡的3D重建的工作(層出不窮令人眼花繚亂的State of the Art top conferences 論文),其實還比不上稍微認真一點的nearest neighbor baselines。沒有任何工具或算法是萬靈藥。
至少在三維重建問題上,沒有把幾何關系條件嚴格用到位的算法,都是不科學的——根本談不上可靠和準確。
并非3D重建,而只是圖像分類?
基于對象(object-based)的單視圖3D重建任務是指,在給定單個圖像的情況下生成對象的3D模型。
如上圖所示,推斷一輛摩托車的3D結構需要一個復雜的過程,它結合了低層次的圖像線索、有關部件結構排列的知識和高層次的語義信息。
研究人員將這種情況稱為重建和識別:
重構意味著使用紋理、陰影和透視效果等線索對輸入圖像的3D結構進行推理。
識別相當于對輸入圖像進行分類,并從數據庫中檢索最合適的3D模型。
雖然在其它文獻中已經提出了各種體系結構和3D表示,但是用于單視圖3D理解的現有方法都使用編碼器——解碼器結構,其中編碼器將輸入圖像映射到潛在表示,而解碼器執行關于3D的非平凡(nontrivial)推理,并輸出空間的結構。
為了解決這一任務,整個網絡既要包含高級信息,也要包含低級信息。
而在這項工作中,研究人員對目前最先進的編解碼器方法的結果進行了分析,發現它們主要依靠識別來解決單視圖3D重建任務,同時僅顯示有限的重建能力。
為了支持這一觀點,研究人員設計了兩個純識別基線:一個結合了3D形狀聚類和圖像分類,另一個執行基于圖像的3D形狀檢索。
在此基礎上,研究人員還證明了即使不需要明確地推斷出物體的3D結構,現代卷積網絡在單視圖3D重建中的性能是可以超越的。
在許多情況下,識別基線的預測不僅在數量上更好,而且在視覺上看起來更有吸引力。
研究人員認為,卷積網絡在單視圖3D重建任務中是主流實驗程序的某些方面的結果,包括數據集的組成和評估協議。它們允許網絡找到一個快捷的解決方案,這恰好是圖像識別。
純粹的識別方法,性能優于先進的神經網絡
實驗基于現代卷積網絡,它可以從一張圖像預測出高分辨率的3D模型。
方法的分類是根據它們的輸出表示對它們進行分類:體素網格(voxel grids)、網格(meshes)、點云和深度圖。為此,研究人員選擇了最先進的方法來覆蓋主要的輸出表示,或者在評估中已經清楚地顯示出優于其他相關表示。
研究人員使用八叉樹生成網絡(Octree Generating Networks,OGN)作為直接在體素網格上預測輸出的代表性方法。
與早期使用這種輸出表示的方法相比,OGN通過使用八叉樹有效地表示所占用的空間,可以預測更高分辨率的形狀。
還評估了AtlasNet作為基于表面的方法的代表性方法。AtlasNet預測了一組參數曲面,并在操作這種輸出表示的方法中構成了最先進的方法。它被證明優于直接生成點云作為輸出的唯一方法,以及另一種基于八叉樹的方法。
最后,研究人員評估了該領域目前最先進的Matryoshka Networks。該網絡使用由多個嵌套深度圖組成的形狀表示,,這些深度圖以體積方式融合到單個輸出對象中。
對于來自AtlasNet的基于IoU的表面預測評估,研究人員將它們投影到深度圖,并進一步融合到體積表示。 對于基于表面的評估指標,使用移動立方體算法從體積表示中提取網格。
研究人員實現了兩個簡單的基線,僅從識別的角度來處理問題。
第一種方法是結合圖像分類器對訓練形狀進行聚類;第二個是執行數據庫檢索。
在聚類方面的基線中,使用K-means算法將訓練形狀聚類為K個子類別。
在檢索基線方面,嵌入空間由訓練集中所有3D形狀的兩兩相似矩陣構造,通過多維尺度將矩陣的每一行壓縮為一個低維描述符。
研究人員根據平均IoU分數對所有方法進行標準比較。
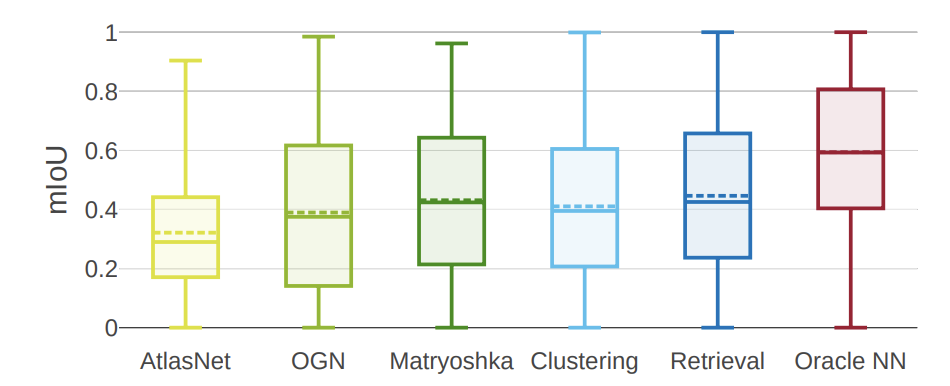
研究人員發現,雖然最先進的方法有不同體系結構的支持,但在執行的時候卻非常相似。
有趣的是,檢索基線是一種純粹的識別方法,在均值和中位數IoU方面都優于所有其他方法。簡單的聚類基線具有競爭力,性能優于AtlasNet和OGN。
但研究人員進一步觀察到,一個完美的檢索方法(Oracle NN)的性能明顯優于所有其他方法。值得注意的是,所有方法的結果差異都非常大(在35%到50%之間)。
這意味著僅依賴于平均IoU的定量比較不能提供這種性能水平的全貌。 為了更清楚地了解這些方法的行為,研究人員進行了更詳細的分析。
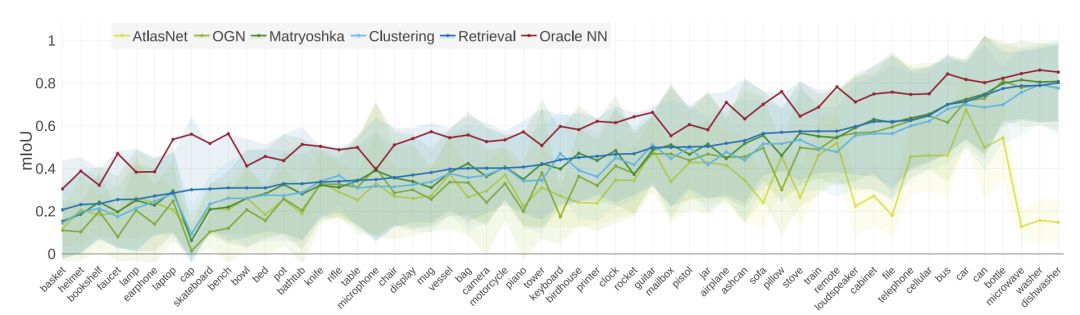
每類mIoU比較。
總的來說,這些方法在不同的類之間表現出一致的相對性能。檢索基線為大多數類生成最佳重構。所有類和方法的方差都很大。
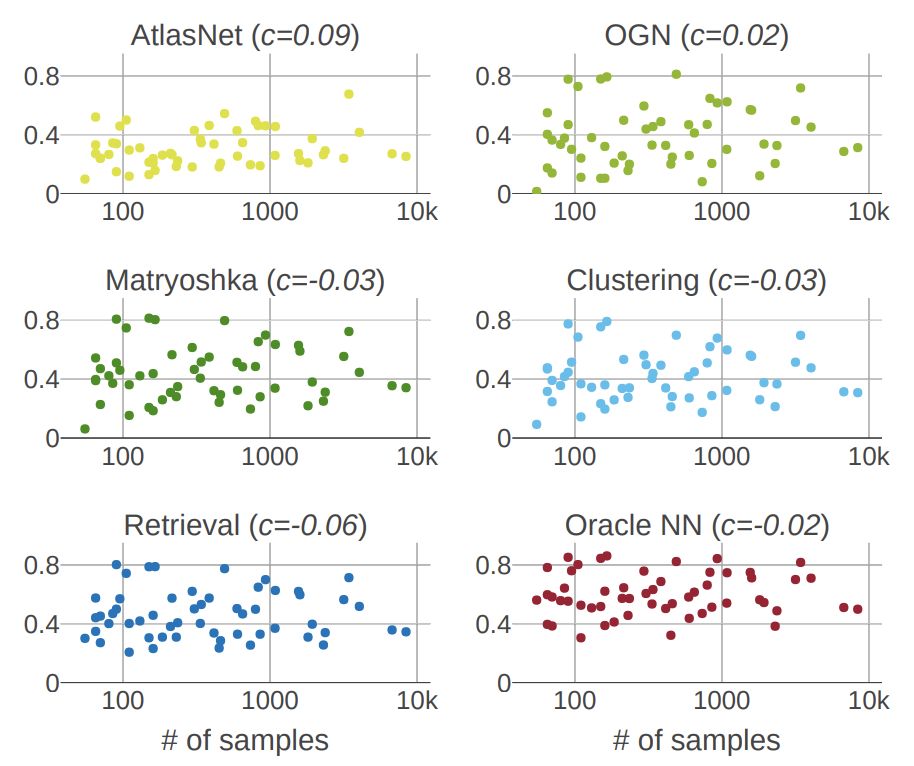
mIoU與每個類的訓練樣本數量。
研究人員發現一個類的樣本數量和這個類的mIoU分數之間沒有相關性。所有方法的相關系數c均接近于零。
定性的結果
聚類基線產生的形狀質量與最先進的方法相當。 檢索基線通過設計返回高保真形狀,但細節可能不正確。 每個樣本右下角的數字表示IoU。

左:為所選類分配IoU。 基于解碼器的方法和顯式識別基線的類內分布是類似的。 Oracle NN的發行版在大多數類中都有所不同。 右圖:成對Kolmogorov-Smirnov檢驗未能拒絕兩個分布的無效假設的類數的熱圖。
研究中的一些問題
參照系的選擇
我們嘗試使用視角預測網絡對聚類基線方法進行擴展,該方法將重點回歸攝像頭的方位角和仰角等規范框架,結果失敗了,因為規范框架對每個對象類都有不同的含義,即視角網絡需要使用類信息來解決任務。我們對檢索基線方法進行了重新訓練,將每個訓練視圖作為單獨樣本來處理,從而為每個單獨的對象提供空間。
量度標準
平均IoU通常在基準測試中被用作衡量單視圖圖像重建方法的主要量化指標。如果將其作為最優解的唯一衡量指標,就可能會出現問題,因為它在對象形狀的質量值足夠高時才能有效預測。如果該值處于中低水平,表明兩個對象的形狀存在顯著差異。
如上圖所示,將一個汽車模型與數據集中的不同形狀的對象進行了比較,只有 IoU分數比較高(最右兩張圖)時才有意義,即使IoU=0.59,兩個目標可能都是完全不同的物體,比較相似度失去了意義。
倒角距離(Chamfer distance)
如上圖所示,兩者目標椅子與下方的椅子的下半部分完美匹配,但上半部分完全不同。但是根據得分,第二個目標要好于第一個。由此來看,倒角距離這個量度會被空間幾何布局顯著干擾。為了可靠地反映真正的模型重建性能,好的量度應該具備對幾何結構變化的高魯棒性。
F-score
我們繪制了以觀察者為中心的重建方式的F分數的不同距離閾值d(左)。在 d =重建體積邊長的2%的條件下,F分數絕對值與當前范圍的 mIoU分數相同,這并不能有效反映模型的預測質量。
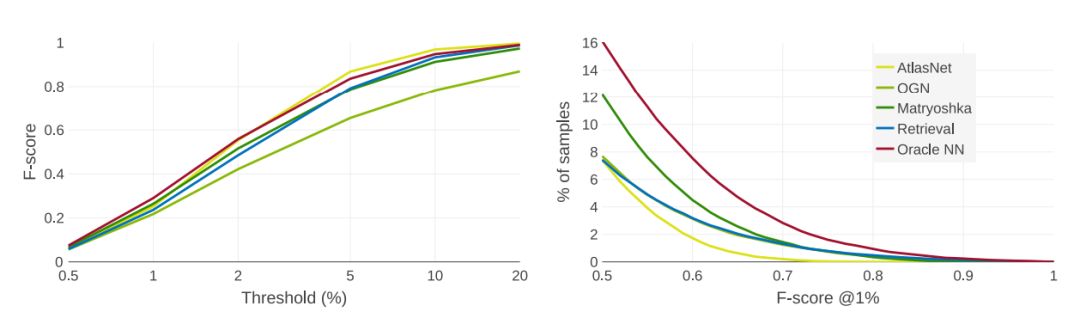
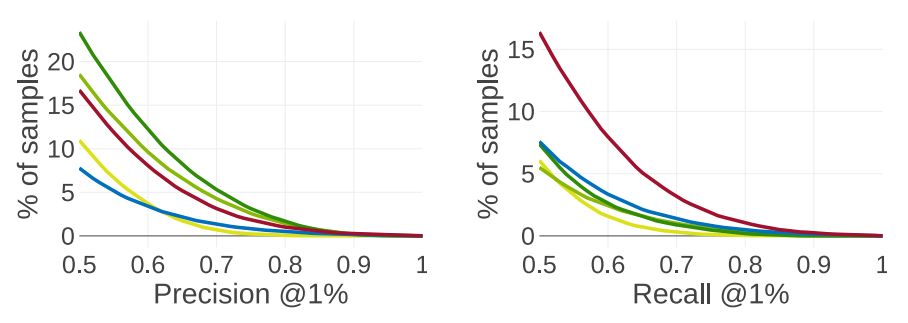
因此,我們建議將距離閾值設為重建模型體積邊長的1%以下來考察F值。如上圖(右)中所示,在閾值d = 1%時,F分數為0.5以上。只有一小部分模型的形狀被精確構建出來,預設任務仍然遠未解決。我們的檢索基線方法不再具有明顯的優勢,進一步表明使用純粹的識別方法很難解決這個問題。
現有的基于CNN的方法在精度上表現良好,但丟失了目標的部分結構
未來展望
在這項研究中,研究人員通過重建和識別來推斷單視圖3D重建方法的范圍。
工作展示了簡單的檢索基線優于最新、最先進的方法。分析表明,目前最先進的單視圖3D重建方法主要用于識別,而不是重建。
研究人員確定了引起這種問題的一些因素,并提出了一些建議,包括使用以視圖為中心的坐標系和魯棒且信息量大的評估度量(F-score)。
另一個關鍵問題是數據集組合,雖然問題已經確定,但沒有處理。研究人員正努力在以后的工作中糾正這一點。
-
圖像識別
+關注
關注
9文章
520瀏覽量
38268 -
3D建模
+關注
關注
0文章
35瀏覽量
9768 -
深度學習
+關注
關注
73文章
5500瀏覽量
121117
原文標題:深度學習不是萬靈藥!神經網絡3D建模其實只是圖像識別?
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
卷積神經網絡有何用途 卷積神經網絡通常運用在哪里
pytorch中有神經網絡模型嗎
如何利用CNN實現圖像識別
bp神經網絡是深度神經網絡嗎
卷積神經網絡的基本結構和工作原理
深度學習與卷積神經網絡的應用
卷積神經網絡的基本結構及其功能
卷積神經網絡在圖像識別中的應用
深度神經網絡模型cnn的基本概念、結構及原理
神經網絡在圖像識別中的應用
神經網絡架構有哪些
詳解深度學習、神經網絡與卷積神經網絡的應用






 工商網監
工商網監
評論