 什么是AI芯片“存儲墻”的解決方案?
什么是AI芯片“存儲墻”的解決方案?
最近剛剛看了唐杉博士的《AI芯片的“冷”與“熱”》,第一句就是“ 參加過去年硅谷的AI Hardware Summit的朋友,普遍反映這次在北京的會議沒有那么火了”。記得,自己在2016年威海參加中國體系結構年會的時候,孫所也說了一句調侃的話:“現在的AI很火,大家都往那邊去,沒有人太關心體系結構了,我要告訴那些追AI熱點的,它都死了三回了!” 的確,作為從小學馬列的中國人,我們最熟悉螺旋式上升的概念。對于計算和I/O來講,和中國經濟調控一樣,都是“ 水多了加面,面多了加水”螺旋式上升。
Google在2017年發布了TPU V1之后,現在已經有越來越多的AI startup的芯片出現,大家基本上都是用標準的Resnet50,Googlenetv3 等網絡為benchmark, 一次一次地刷新性能和功耗比,個人覺得很有可能在一天,AI芯片的性能和功耗比在特定的imagenet的任務上超過人腦,現在AI在準確率和性能上都超過了。對于AI的芯片來講,有一個指標也是大家討論比較多的。Roofline model
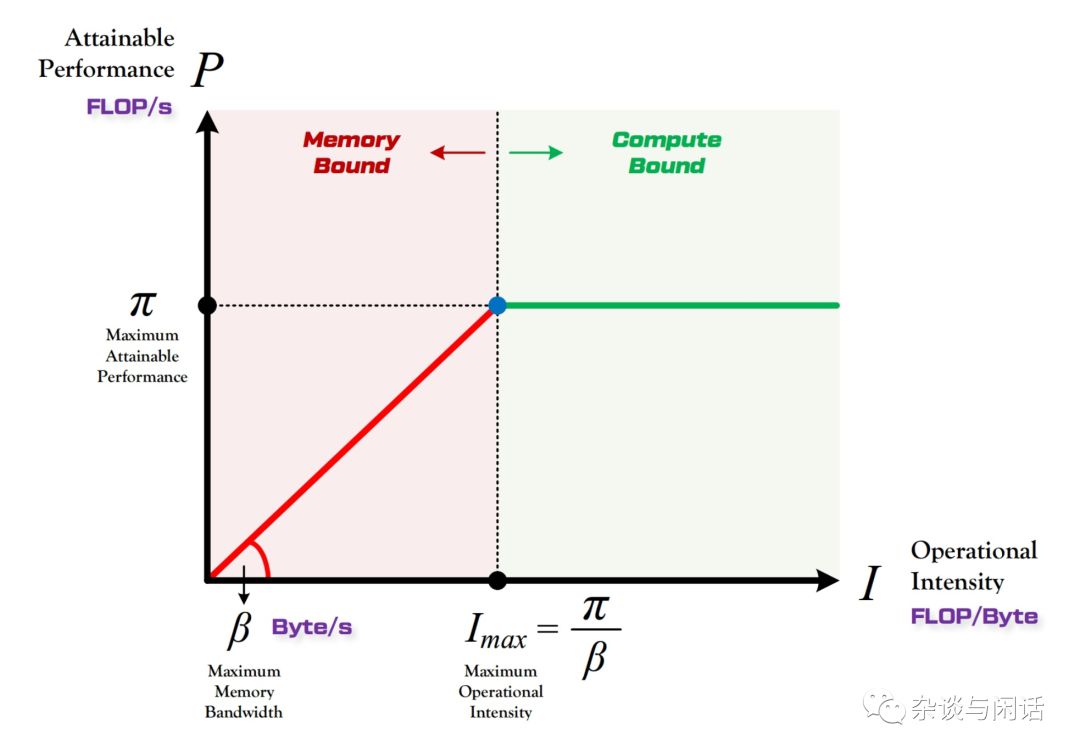
Y軸是P,代表算力,用來FLOP/s來表示,現在新出的AI ASIC往往在FLOP/s并不發力,因為從功耗比的角度上,算力肯定不是越高越好,而且大家都很難高過老黃的核彈。
代表了一個特定的計算平臺的peak performance,就是最大算力。
就是特定的計算平臺的I內存/O帶寬,這個和該計算平臺使用的DDR類型有關。
X軸是I,代表計算強度,就是在一個Byte上的計算量。因為對于一個特定的平臺,我可以知道它的最大算力和帶寬,我們就可以知道它的最大的計算強度。
因此,和圖上顯示的一樣,在點(Imax,),這個計算平臺達到了完美。在它的左邊,說明memory受限,在它的右邊說明計算受限。
因為對于每一次訪存都是32位的Float Point,因此整個內存的占用就是 260MB左右,而計算量是724MFLOPs,因此Alexnet的計算強度就是724/260=2.7 operation/byte。
對于一個特定的平臺,比如老黃家的新的GTX2080Ti 系列來講:
對于計算性能,先不管老黃加各種Tensor Core,RTcore,從CUDA Core本身來講,他是100TLOP/s,
它的內存帶寬如下:
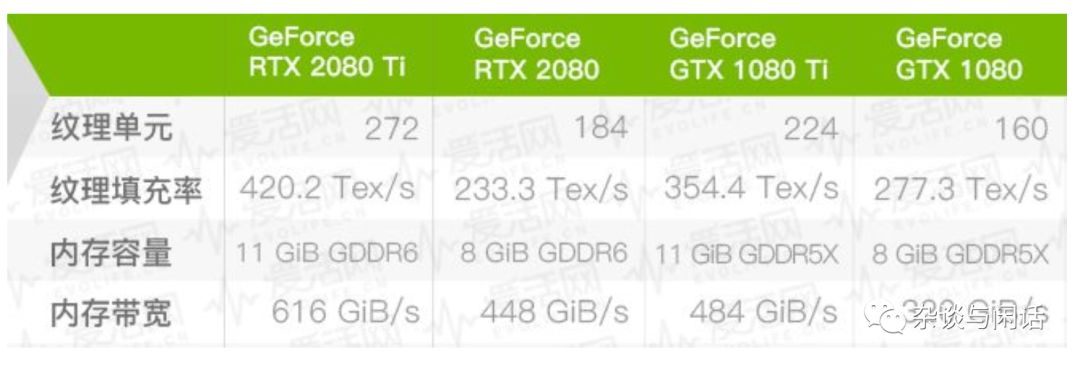
因此,作為2080Ti, 它的Imax就是166Operation/Byte.
可能到這個,就可以看出,對于Alex的2.7 來講,遠遠沒有達到2080ti的計算強度,主要是受限于內存帶寬了。
在Google的TPU中,有一個圖經常被大家引用。
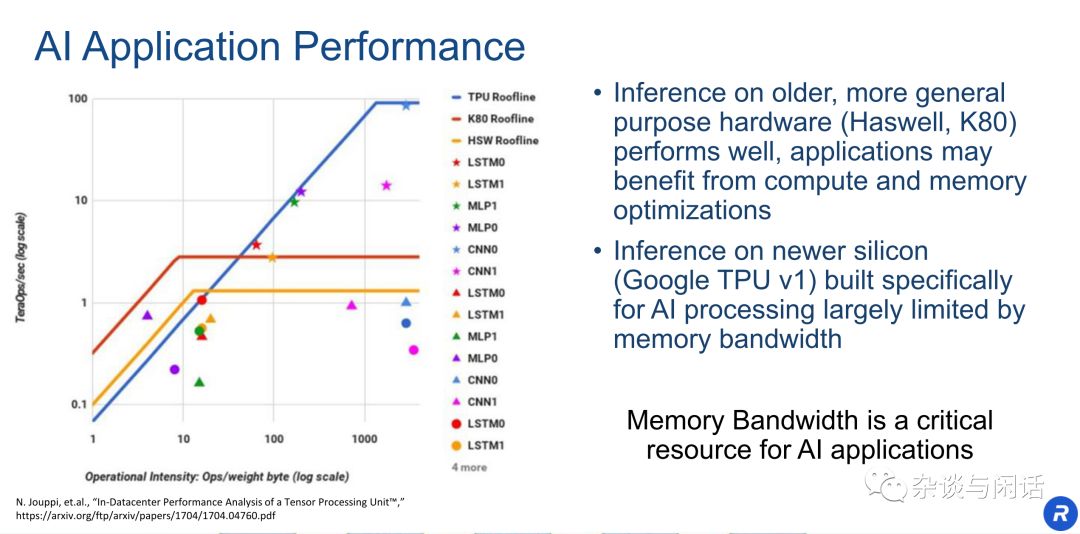
大家基本上可以看到,google的Imax差不多在1000左右,基本上沒有什么網絡可以完全用滿TPU的peak performance。
怎么辦,內存帶寬的解決方案就是HBM,HBM2, HBM3不斷加大帶寬。記得在2017年的CNCC上,謝源教授講,他在2010年左右提出了HBM的概念,他很快就看到了AMD,Nvidia以及Xilinx和Intel都在芯片上使用了HBM,證明了這條道路的正確性。他認為目前應該在AI芯片上擺脫這種”水多了加面,面多了加水“,in-memory 計算應該是下一個方向。
這個就引出了在Memory+會議上來自平頭哥的段立德博士的topic,”Processing Near or In memory for deep learning".
-
芯片
+關注
關注
455文章
50731瀏覽量
423197 -
存儲
+關注
關注
13文章
4298瀏覽量
85807 -
AI
+關注
關注
87文章
30761瀏覽量
268905
發布評論請先 登錄
相關推薦
AI時代的存儲墻,哪種存算方案才能打破?
emc存儲解決方案的優勢

ai煙火檢測解決方案

低壓線性恒流LED恒流驅動芯片:用于洗墻燈和線條燈
憶聯SSD存儲解決方案亮相2024中國國際金融展

瑞薩電子推出Reality AI Explorer Tier,用于開發AI與TinyML解決方案
EVASH Ultra EEPROM:助力ChatGPT等AI應用的嵌入式存儲解決方案

MK米客方德的AI智能存儲解決方案

risc-v多核芯片在AI方面的應用
得一微電子:AI時代重新定義存儲主控芯片






 工商網監
工商網監
評論