 為什么我們需要機器學習?
為什么我們需要機器學習?
最近深度學習技術實現方面取得的突破表明,頂級算法和復雜的結構可以將類人的能力傳授給執行特定任務的機器。但我們也會發現,大量的訓練數據對深度學習模型的成功起著至關重要的作用。就拿Resnet來說,這種圖像分類結構在2015年的ILSVRC分類競賽中獲得了第一名,比先前的技術水平提高了約50%。
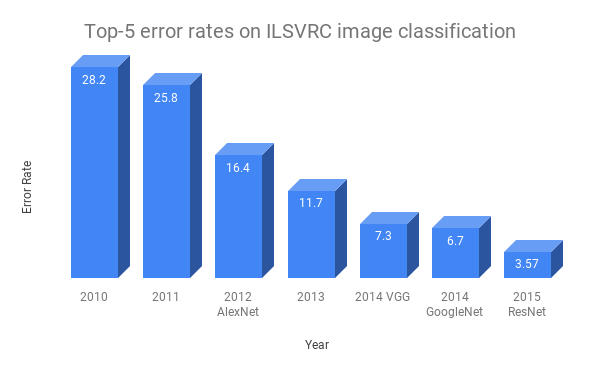
圖1:近年來ILSVRC的頂級模型表現
Resnet不僅具有非常復雜艱深的結構,而且還有足夠多的數據。不同的算法其性能可能是相同的,這個問題已經在工業界和學術界得到了很好的證實。
但需要注意的是,大數據應該是有意義的信息,而不是雜亂無章的,這樣,模型才能從中學習。這也是谷歌、Facebook、亞馬遜、Twitter、百度等公司在人工智能研究和產品開發領域占據主導地位的主要原因之一。
雖然與深度學習相比,傳統的機器學習會需要更少的數據,但即使是大規模的數據量,也會以類似的方式影響模型性能。下圖清楚地描述了傳統機器學習和深度學習模型的性能如何隨著數據規模的提高而提高。
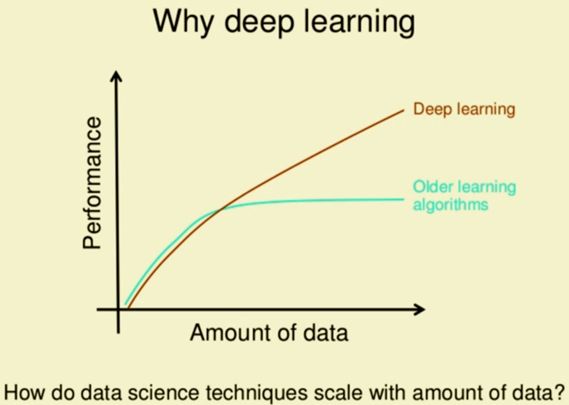
圖2:數據量與模型性能的函數關系
為什么我們需要機器學習?
圖3:彈丸運動公式
讓我們用一個例子來回答這個問題。假設我們有一個速度為v,按一定角度θ投擲出去的球,我們想要算出球能拋多遠。根據高中物理知識,我們知道球做一個拋物線運動,我們可以使用圖中所示的公式算出距離。
上述公式可被視為任務的模型或表示,公式中涉及的各種術語可被視為重要特征,即v、θ和g(重力加速度)。在上述模型下,我們的特征很少,我們可以很好地理解它們對我們任務的影響。因此,我們能夠提出一個好的數學模型。讓我們考慮一下另一種情況:我們希望在2018年12月30日預測蘋果公司的股價。在這個任務中,我們無法完全了解各種因素是如何影響股票價格的。
在缺乏真實模型的情況下,我們利用歷史股價和標普500指數、其他股票價格、市場情緒等多種特征,利用機器學習算法來找出它們潛在的關系。這就是一個例子,即在某些情況下,人類很難掌握大量特征之間的復雜關系,但是機器可以通過大規模的數據輕松地捕捉到它。
另一個同樣復雜的任務是:將電子郵件標記為垃圾郵件。作為一個人,我們可能要想許多規則和啟式的方法,但它們很難編寫、維護。而另一方面,機器學習算法可以很容易地獲得這些關系,還可以做得更好,并且更容易維護和擴展。既然我們不需要清晰地制定這些規則,而數據可以幫助我們獲得這些關系,可以說機器學習已經徹底改變了不同的領域和行業。
大數據集是怎樣幫助構建更好的機器學習模型的?
在我們開始討論大規模數據是如何提高模型性能之前,我們需要了解偏差(Bias)和方差(Variance)。
偏差:讓我們來看這樣一個數據集:它的因變量和自變量之間是二次方關系。然而,我們不知道他們真實的關系,只能稱它們近似為線性關系。在這種情況下,我們將會發現我們的預測與實際數據之間的明顯的差異。觀測值和預測值之間的這種差異稱為偏差。這種模型,我們會說它功能小,欠擬合。
方差:在同一個例子中,如果我們將關系近似為三次方或任何更高階,就會出現一個高方差的情況。方差能夠反映訓練集與測試集的性能差異。高方差的主要問題是:模型能很好地擬合訓練數據,但在訓練外數據集上表現得不好。這是驗證確認測試集在模型構建過程中非常重要的一個主要原因。
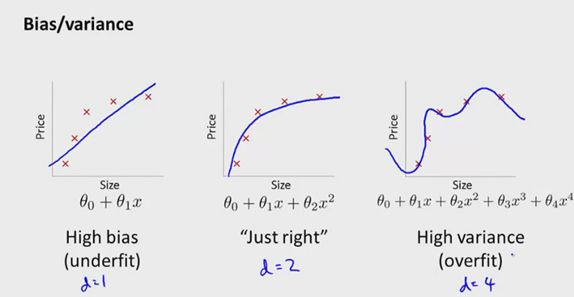
圖4:偏差 vs方差
我們通常希望將偏差和方差最小化。即建立一個模型,它不僅能很好地適用訓練數據,而且能很好地概括測試/驗證數據。實現這一點有很多方法,但使用更多數據進行訓練是實現這一點的最佳途徑之一。我們可以通過下圖了解這一點:
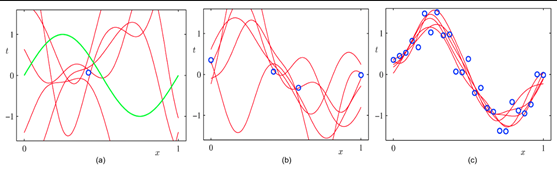
圖5:大數據產生了更好的泛化
假設我們有一個類似于正弦分布的數據。圖(5a)描述了多個模型在擬合數據點方面同樣良好。這些模型中有很多都過擬合,并且在整個數據集上產出不是很好。當我們增加數據時,從圖(5b)可以看出可以容納數據的模型數量減少。隨著我們進一步增加數據點的數量,我們成功地捕獲了數據的真實分布,如圖(5C)所示。這個例子幫助我們清楚地了解數據數量是如何幫助模型揭示真實關系的。接下來,我們將嘗試了解一些機器學習算法的這種現象,并找出模型參數是如何受到數據大小影響的。
線性回歸:在線性回歸中,我們假設預測變量(特征)和因變量(目標)之間存在線性關系,關系式如下:
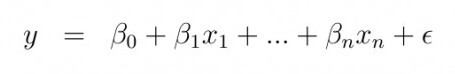
其中y是因變量,x(i)是自變量。β(i)為真實系數,?為模型未解釋的誤差。對于單變量情況,基于觀測數據的預測系數如下:
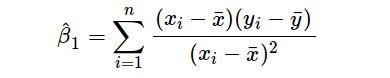
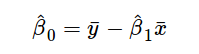
上述公式給出了斜率和截距的估測點,但這些估值總是存在一些不確定性,這些不確定性可由方差方程量化:
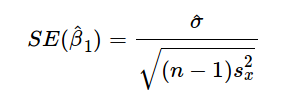
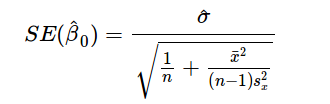
因此,隨著數據數量的增加,分母會變大,就是我們估測點的方差變小。因此,我們的模型對潛在關系會更加自信,并能給出穩定的系數估計。通過以下代碼,我們可以看到上述現象的實際作用:
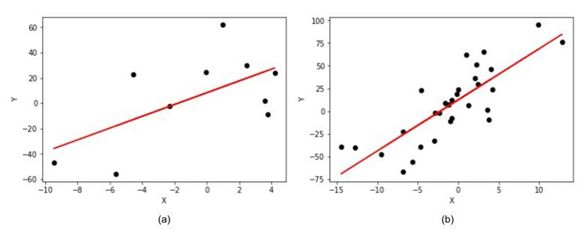
圖6:在線性回歸中增加數據量對估測點位置估測的提升
我們模擬了一個線性回歸模型,其斜率(b)=5,截距(a)=10。從圖6(a)(數據量小)到圖6(b)(數據量大),我們建立了一個衰退模型,此時我們可以清楚地看到斜率和截距之間的區別。在圖6(a)中,模型的斜率為4.65,截距為8.2,而圖6(b)中模型的斜率為5.1,截距為10.2相比,可以明顯看出,圖6(b)更接近真實值。
k近鄰(k-NN):k-NN是一種用于回歸和分類里最簡單但功能強大的算法。k-NN不需要任何特定的訓練階段,顧名思義,預測是基于k-最近鄰到測試點。由于k-NN是非參數模型,模型性能取決于數據的分布。在下面的例子中,我們正在研究iris數據集,以了解數據點的數量如何影響k-NN表現。為了更好表現結果,我們只考慮了這組數據的四個特性中的兩個:萼片長度和萼片寬度。
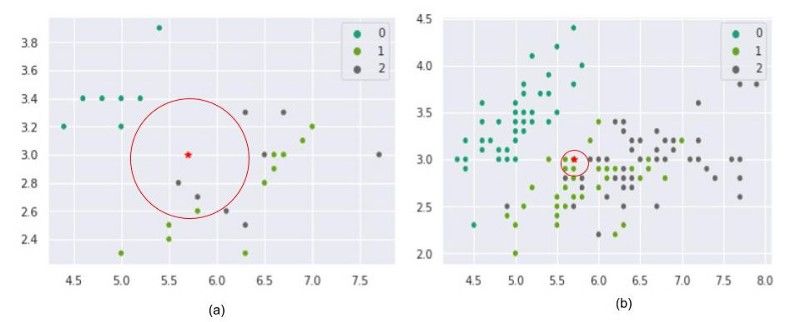
圖7:KNN中預測類隨數據大小的變化
后面的實驗中我們隨機從分類1中選取一個點作為試驗數據(用紅色星星表示),同時假設k=3并用多數投票方式來預測試驗數據的分類。圖7(a)是用了少量數據做的試驗,我們發現這個模型把試驗點錯誤分在分類2中。當數據點越來越多,模型會把數據點正確預測到分類1中。從上面圖中我們可以知道,KNN與數據質量成正相關,數據越多可以讓模型更一致、更精確。
決策樹算法:與線性回歸和KNN類似,也受數據數量的影響。
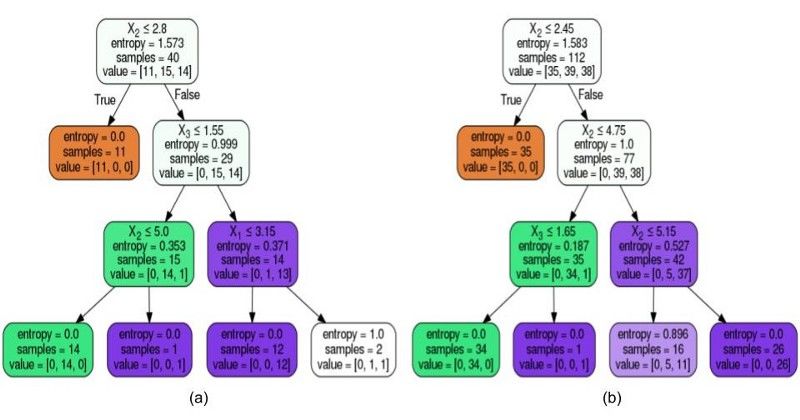
圖8:根據數據的大小形成不同的樹狀結構
決策樹也是一種非參數模型,它試圖最好地擬合數據的底層分布。拆分是對特性值執行的,目的是在子級創建不同的類。由于模型試圖最好地擬合可用的訓練數據,因此數據的數量直接決定了分割級別和最終類。從上面的圖中我們可以清楚的看到,數據集的大小對分割點和最終的類預測有很大的影響。更多的數據有助于找到最佳分割點,避免過度擬合。
如何解決數據量少的問題?
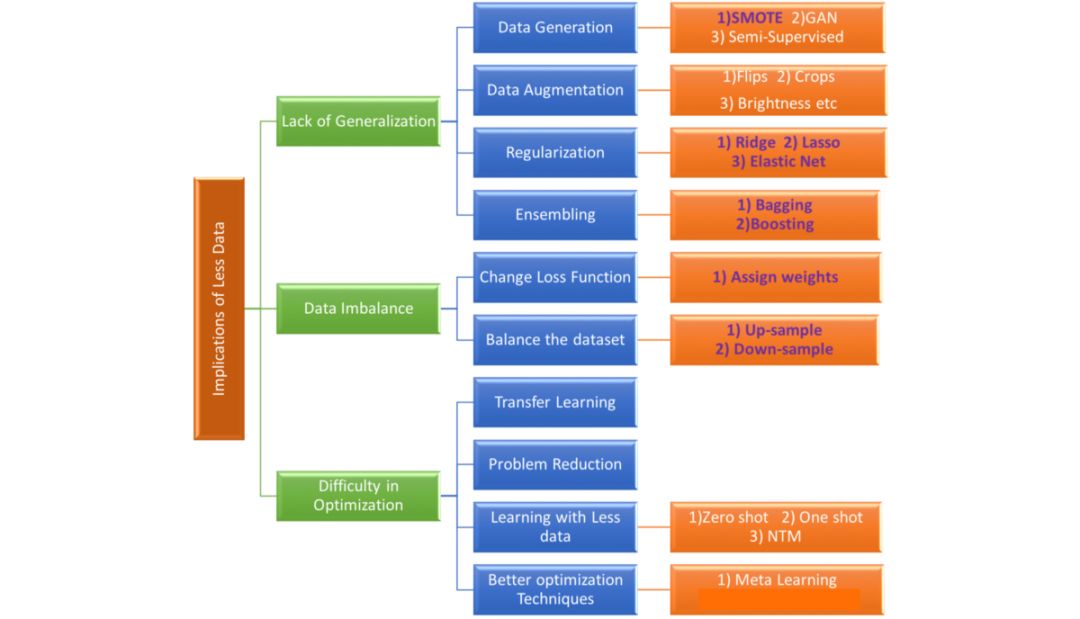
圖9:數據量少的基本含義和解決它的可能方法和技術
上圖試圖捕捉處理小數據集時所面臨的核心問題,以及解決這些問題的可能方法和技術。在本部分中,我們將只關注傳統機器學習中使用的技術。
改變損失函數:對于分類問題,我們經常使用交叉熵損失,很少使用平均絕對誤差或平均平方誤差來訓練和優化我們的模型。在數據不平衡的情況下,由于模型對最終損失值的影響較大,使得模型更加偏向于多數類,使得我們的模型變得不那么有用。
在這種情況下,我們可以對不同類對應的損失增加權重,以平衡這種數據偏差。例如,如果我們有兩個按比例4:1計算數據的類,我們可以將比例1:4的權重應用到損失函數計算中,使數據平衡。這種技術可以幫助我們輕松地緩解不平衡數據的問題,并改進跨不同類的模型泛化。我們可以很容易地找到R和Python中的庫,它們可以幫助在損失計算和優化過程中為類分配權重。Scikit-learn有一個方便的實用函數來計算基于類頻率的權重:
我們可以用class_weight=‘balanced’來代替上面的計算量,并且與class_weights計算結果一樣。我們同樣可以依據我們的需求來定義分類權重。
異常/變更檢測:在欺詐或機器故障等高度不平衡的數據集的情況下,是否可以將這些例子視為異常值得思考。如果給定的問題滿足異常判據,我們可以使用OneClassSVM、聚類方法或高斯異常檢測方法等模型。這些技術要求我們改變思維方式,將次要類視為異常類,這可能幫助我們找到分離和分類的新方法。變化檢測類似于異常檢測,只是我們尋找的是變化或差異,而不是異常。這些可能是根據使用模式或銀行事務觀察到的用戶行為的變化。
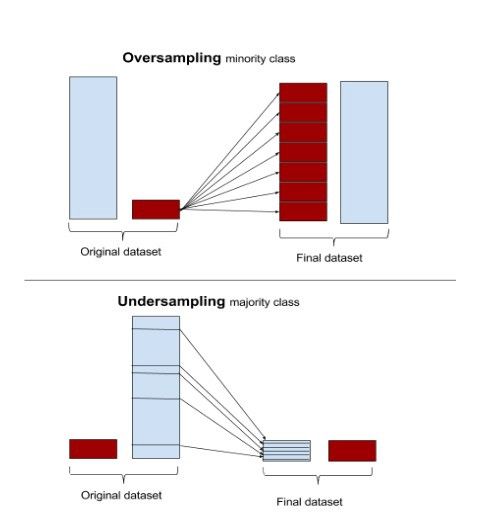
圖10:過采和欠采樣的情況
上采樣還是下采樣:由于不平衡的數據本質上是以不同的權重懲罰多數類,所以解決這個問題的一個方法是使數據平衡。這可以通過增加少數類的頻率或通過隨機或集群抽樣技術減少多數類的頻率來實現。過度抽樣與欠抽樣以及隨機抽樣與集群抽樣的選擇取決于業務上下文和數據大小。一般來說,當總體數據大小較小時,上采樣是首選的,而當我們有大量數據時,下采樣是有用的。類似地,隨機抽樣和聚集抽樣是由數據分布的好壞決定的。
生成合成數據:盡管上采樣或下采樣有助于使數據平衡,但是重復的數據增加了過度擬合的機會。解決此問題的另一種方法是在少數類數據的幫助下生成合成數據。合成少數過采樣技術(SMOTE)和改進過采樣技術是產生合成數據的兩種技術。簡單地說,合成少數過采樣技術接受少數類數據點并創建新的數據點,這些數據點位于由直線連接的任意兩個最近的數據點之間。為此,該算法計算特征空間中兩個數據點之間的距離,將距離乘以0到1之間的一個隨機數,并將新數據點放在距離計算所用數據點之一的新距離上。注意,用于數據生成的最近鄰的數量也是一個超參數,可以根據需要進行更改。
圖11:基于K=3,合成少數過采樣技術過程
M-SMOTE是一個改進版的SMOTE,它考慮了數據中少數分類的底層分布。該算法將少數類的樣本分為安全/安全樣本、邊界樣本和潛在噪聲樣本三大類。這是通過計算少數類樣本與訓練數據樣本之間的距離來實現的。與SMOTE不同的是,該算法從k個最近鄰中隨機選擇一個數據點作為安全樣本,從邊界樣本中選擇最近鄰,對潛在噪聲不做任何處理。
集成技術:聚合多個弱學習者/不同模型在處理不平衡的數據集時顯示出了很好的效果。裝袋和增壓技術在各種各樣的問題上都顯示出了很好的效果,應該與上面討論的方法一起探索,以獲得更好的效果。但是為了更詳細地了解各種集成技術以及如何將它們用于不平衡的數據,請參考下面的博客。
總結
在這段中,我們看到數據的大小可能會體現出泛化、數據不平衡以及難以達到全局最優等問題。我們已經介紹了一些最常用的技術來解決傳統機器學習算法中的這些問題。根據手頭的業務問題,上述一種或多種技術可以作為一個很好的起點。
-
機器學習
+關注
關注
66文章
8424瀏覽量
132765 -
大數據
+關注
關注
64文章
8896瀏覽量
137517
原文標題:打破機器學習中的小數據集詛咒
文章出處:【微信號:BigDataDigest,微信公眾號:大數據文摘】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

如何選擇云原生機器學習平臺
zeta在機器學習中的應用 zeta的優缺點分析
什么是機器學習?通過機器學習方法能解決哪些問題?

NPU與機器學習算法的關系
eda在機器學習中的應用
【「時間序列與機器學習」閱讀體驗】+ 簡單建議
我們需要怎樣的大模型?

機器學習算法原理詳解
深度學習與傳統機器學習的對比
機器學習的經典算法與應用
請問PSoC? Creator IDE可以支持IMAGIMOB機器學習嗎?
圖機器學習入門:基本概念介紹
機器學習8大調參技巧





 工商網監
工商網監
評論